
基于改进YOLOv3-tiny的道路车辆检测算法
2022-01-07 09:59:32邢镇委张梦龙
洛阳理工学院学报(自然科学版) 2021年4期
邢镇委, 伋 淼, 张梦龙
(安徽理工大学 电气与信息工程学院, 安徽 淮南 232001)
随着自动驾驶、实时监控系统和智能交通系统等技术的快速发展,对于道路车辆检测的研究也越来越广泛。现有的车辆检测算法主要分为基于运动模型的算法、基于特征模型的算法和基于卷积神经网络的算法3种,其中基于卷积神经网络的道路车辆检测算法实用性最强[1]。基于卷积神经网络的车辆检测算法可以分为两类:一类检测精度高,但计算量大,导致检测速度慢,典型的有RCNN、Fast RCNN、Faster RCNN等;另一类通过对边界框进行回归,将图像中目标所在的位置进行框选,这类算法复杂性低,能够在更短的时间内检测出目标,但检测准确率会有所下降,典型的有YOLO系列、SSD等[2]。
目前,对于车辆检测效果的影响主要是光照条件和视频质量。在白天,车辆的边缘和角落等特征很容易被检测到,但是在光照条件差的环境下,这些特征是不容易被检测到的。此外,一些距离很远的车辆在图像中占据的区域很小,检测过程中经常容易被漏检[3]。针对以上问题,提出了一种改进YOLOv3-tiny的道路车辆检测算法,设计一种鲁棒性强更加轻量化的车辆检测模型。同时,使用k-means++聚类算法选取锚点预测边界框,可以有效地解决道路车辆检测过程中检测速率和检测精度不能同时满足的问题。
1 YOLOv3-tiny网络模型
1.1 网络结构
YOLOv3-tiny是YOLOv3目标检测网络的简化版本,网络复杂性更低,检测速度更快。YOLOv3和YOLOv3-tiny都能够同时检测多个类别的物体,并且在MS COCO数据集上进行测试都取得较好的效果[4]。原始YOLOv3-tiny通过卷积层对车辆特征进行提取,在每一个卷积层后都会有一个最大池化层,由此构成了该网络的特征提取部分。最大池化层中,前5个层中的步长为2,最后一个层的步长为1。输入不同尺寸的图像,经过7个不同卷积层的处理之后输出的大小也不一样[5],模型中特征提取网络最后输出的特征图尺寸为13×13。YOLOv3-tiny网络结构如图1所示。
1.2 车辆检测的评价指标
目标检测技术在实际应用中,容易受复杂环境影响,导致各种检测算法的性能都不一样。因此,需要相关的参数来评价检测算法的性能。本文主要选用检测速率和均值平均精度(mAP)这两种指标来评价算法性能。
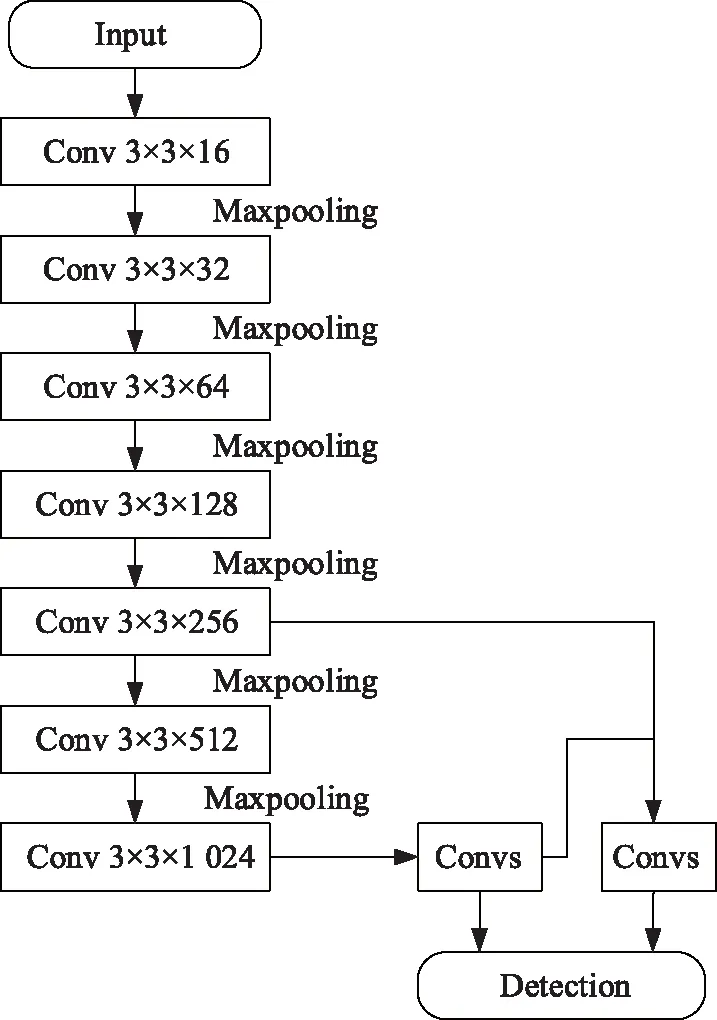
图1 YOLOv3-tiny网络结构
检测速率计算公式:
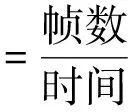
均值平均精度计算公式:
其中:Pclass是对每张图像进行检测,检测出来图像所属类别的精度;Ntotal为全部测试集图像里面含有车辆图像的张数;PclassAve代表对于不同车辆类型检测的平均精度;Nclasses代表车辆类型个数;mAP大小在[0,1]区间内,数值越大,分类器性能越好,检测算法精度越高[6]。
2 改进的YOLOv3-tiny算法
2.1 改进特征提取网络
YOLOv3-tiny算法在目标检测方面有较好的性能,但对于复杂道路环境的车辆检测并不完全适用,需要对YOLOv3-tiny网络的特征提取部分进行改进,以建立更加精确的车辆检测模型。改进后的的YOLOv3-tiny算法由13个卷积层和4个shortcut层组成,特征图每经过一次shortcut层相当于经历了一次下采样,shortcut层在网络中起到残差连接的作用。将最大池化层从原始的YOLOv3-tiny网络中移除,在特征提取网络部分后面加入空间金字塔池化(SPP)。改进后的网络在保持检测速度的同时,能够提取丰富的特征进行检测;SPP不用反复处理卷积层的特征,可以在整张图片的单个通道内提取特征,能够降低计算的复杂程度,因此在使用SPP之后特征提取速度能够改善。改进后的网络结构如图2所示。
2.2 利用k-means++聚类算法选择锚点框
k-means聚类算法通过对检测对象的距离属性进行划分聚类,算法简单易懂,被许多网络模型广泛采用。YOLOv3-tiny使用k-means算法来选择锚点框(anchor boxes),必须提前指定k个聚类,在有噪声的图像中表现效果差。本文采用k-means++算法来计算anchor[7],算法步骤如下:
(1)打乱数据选择聚类中心;
(2)计算最近聚类中心与每个样本的距离;
(3)选择距离较大的样本作为新的聚类中心;
(4)重复步骤(2)和步骤(3),直到选出k个聚类中心;
(5)根据这k个中心进行标准k-means聚类。
本文输入图像的尺寸大小为416×416,用k-means++算法计算出来的6个锚点分别(16×15)、(42×40)、(95×73)、(115×165)、(256×168)、(329×14)。图像中的每个单元格通过3个锚点框预测边界框,前3个锚点用于最后的YOLO层检测较小的车辆,后3个锚点用于在第一个YOLO检测层检测较大的车辆。

图2 改进后的网络结构
2.3 利用k-means++聚类算法选择锚点框
车辆检测的准确性主要依赖于边界框回归,选择一种合适的损失函数用于边界框回归是一项十分重要的任务。本文使用目标定位损失、目标类别损失以及目标置信度损失来构成改进后网络总体损失函数[8]。其中,目标定位损失Lloc采用DIoU损失代替原有的均方差损失,能够优化总损失,改善回归精度。改进后网络总体损失函数公式:
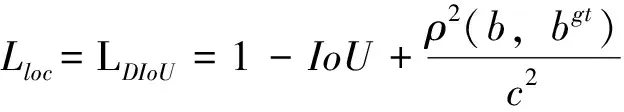
其中:ρ2(b,bgt)是真实框和预测框中心点之间的欧氏距离;IoU是真实框和预测框面积的交并比;c是覆盖真实框和预测框的最小封闭区域的对角线长度。


3 实验结果与分析
3.1 数据集和实验平台
实验中制作的数据集是从3个公开数据集PASCAL VOC2007、PASCAL VOC2012、MS COCO2014中抽取出来的,主要包括3类car、bus和truck,包含训练样本4 000张、测试样本1 000张。实验计算机配置如表1所示。

表1 实验计算机配置
3.2 模型训练
模型训练时的网络配置参数如表2所示。模型训练过程中总共迭代50 200次,损失函数的变化曲线如图3所示。从图3可以看出,网络迭代在2 500次之前,Loss值下降迅速;网络迭代到4 500次左右时收敛曲线慢慢变平缓[9]。

表2 实验网络配置
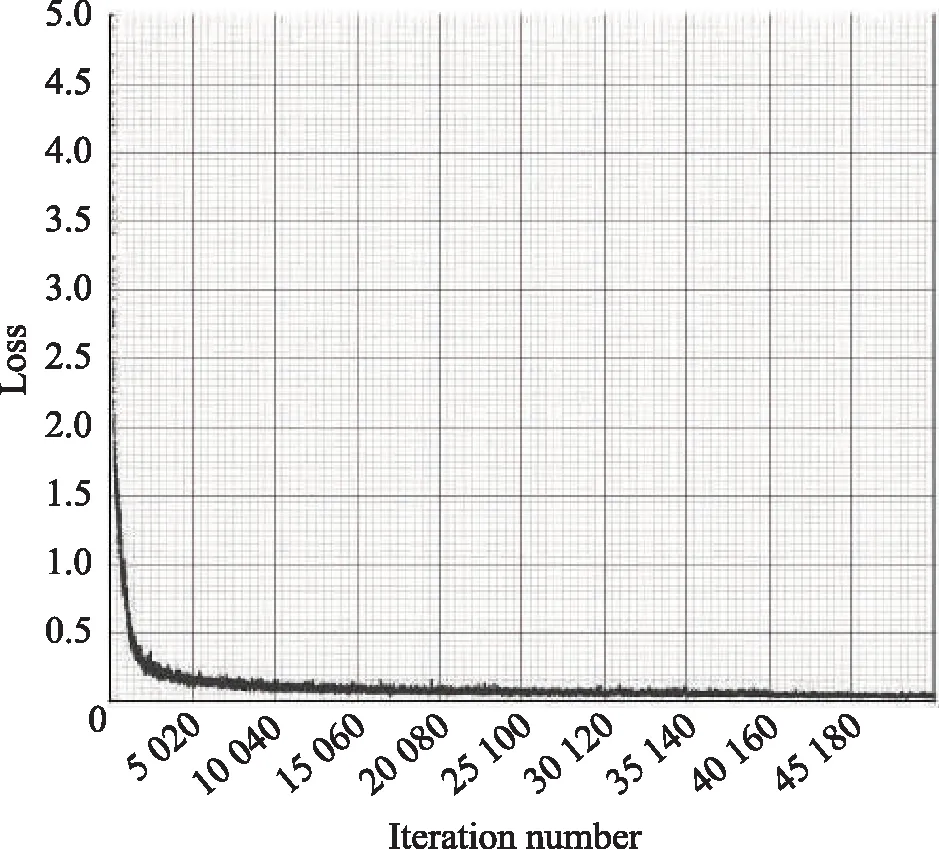
图3 损失函数收敛曲线
3.3 实验结果分析
为了验证改进后算法的检测性能,将改进后的YOLOv3-tiny算法与改进前的算法、SSD算法、Faster-RCNN算法进行比较。4种算法模型使用同一个数据集进行训练,训练完成之后使用检测速率和均值平均精度(mAP)来对比分析其检测性能。实验结果如表3所示。
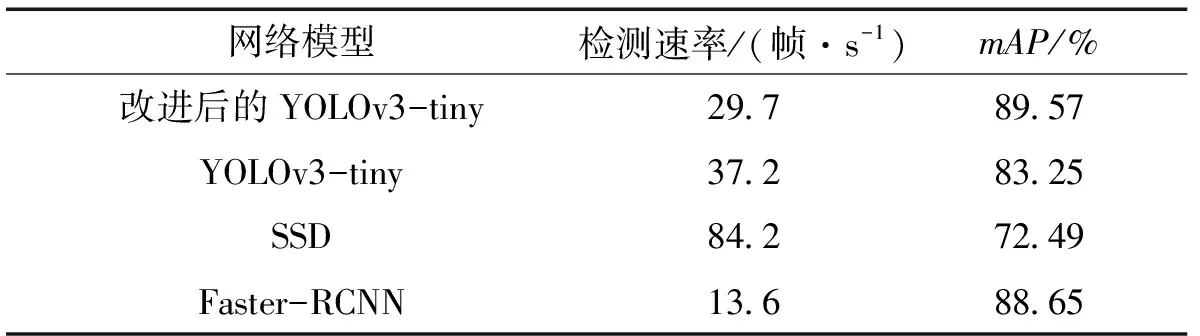
表3 4种算法的性能对比
由表3可以看出:改进后YOLOv3-tiny算法的mAP为89.57%,相比于原YOLOv3-tiny算法的mAP提升了6.32%,网络对车辆识别的精度有所提升;当模型的检测速率保持在25帧/s以上时,能够满足目标检测实时性的要求。改进后YOLOv3-tiny网络在检测速率上相比于原网络稍微有所下降,这是由于改进后算法网络层数增加所导致的,但改进后的算法对车辆的检测速度可以保持在29.7帧/s,能够满足需求。综合各方面来看,改进后YOLOv3-tiny算法可以在保证检测速率的基础上,提高识别的精度,所以本文提出改进后YOLOv3-tiny算法适用于道路车辆检测的场景中[10]。
为了更直观的展示改进后算法的检测性能并验证其在实际场景中的应用效果,选取包含小目标、目标相互遮挡、雾天环境等情况的图像,不同检测算法得到的检测结果如图4和图5所示。从图4和图5可以看出,原始YOLOv3-tiny和SSD算法对于小目标车辆、车辆相互遮挡以及雾天环境下车辆特征不突出这几种情况下的检测效果不太理想,很容易产生漏检,甚至还会出现误检现象,如图4(c)中SSD算法误将卡车检测为公交车。改进后的YOLOv3-tiny算法对于以上几种情况的车辆检测效果可以与Faster-RCNN算法相媲美,由于Faster-RCNN算法对车辆的检测速率过于低下,根本无法满足对于车辆实时性检测的需求。因此,在道路车辆检测的任务中综合各方面情况来看,改进后的YOLOv3-tiny算法的整体性能高于Faster-RCNN、原始YOLOv3-tiny以及SSD算法。

(a)改进后的YOLOv3-tiny (b)YOLOv3-tiny

(c)SSD (d)Faster-RCNN

(a)改进后的YOLOv3-tiny (b)YOLOv3-tiny

(c)SSD (d)Faster-RCNN
4 结 语
在YOLOv3-tiny目标检测算法的基础上,笔者提出了一种改进YOLOv3-tiny车辆检测算法。将空间金字塔池化添加到网络结构中的特征提取部分,使网络能够提取更加完善的图像特征;使用k-means++聚类算法实现锚点预测车辆的边界框,能够大大提升网络检测速率;在损失函数中,用DIoU损失和均方差损失,减少边界框回归的误差,增强网络模型的性能。实验结果表明,本文提出的改进YOLOv3-tiny车辆检测算法平均精度均值达到89.57%,在一些复杂道路环境下能取得不错的检测效果。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
通信电源技术(2021年2期)2021-05-21 02:33:46
电子技术与软件工程(2020年22期)2021-01-30 05:29:42
数字技术与应用(2020年12期)2021-01-22 13:40:40
移动通信(2020年5期)2020-06-08 15:39:51
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
