
直链淀粉的傅里叶衰减全反射中红外特征光谱筛选与定量分析
2022-01-06 05:01:32夏兰欣
食品科学 2021年24期
王 广,刘 宇,夏兰欣,李 伟,程 超,
(1.生物资源与利用湖北省重点实验室(湖北民族大学),湖北 恩施 445000;2.湖北民族大学生物科学与技术学院,湖北 恩施 445000)
淀粉由直链淀粉和支链淀粉两大主要部分构成,这两种淀粉在理化性质、分子结构和相对分子质量等方面存在一定差异,直链淀粉含量是影响淀粉产品加工品质的重要指标之一,如稻米中直链淀粉含量高则米质松散,而支链淀粉含量高的米质较黏稠[1],因此能及时快速掌握原料中直链淀粉的含量对其加工产品种类具有一定指导作用。近年来发展起来的测定支链淀粉和直链淀粉含量的方法有单标单波长法、单标双波长法、双标单波长法、双标双波长法、自动分析检测法、伴刀豆球蛋白法及排阻色谱分析法,这些方法需要将产品进行复杂的前处理才能测得直链淀粉含量,且此过程易导致淀粉损失,这不仅使得研究数据不准确,还限制了某些领域的生产速度[2]。
近年来快速、无损红外定量检测技术发展迅速,如利用近红外和中红外光谱定量分析肉制品、乳制品等产品中掺假成分[3-8]、米酒和巧克力的抗氧化能力[9-10]、脂肪酸、淀粉结晶度等指标测定[11-14]等。有资料报道中红外定量分析效果略优于近红外,如向伶俐等[15]用近、中红外光谱仪采集中国4 个不同葡萄主栽产地153 个葡萄酒样品的近红外透射光谱和中红外衰减全反射光谱,建模后发现4 个产区葡萄酒判别模型建模集的平均准确率为78.21%(近红外)和82.57%(中红外),检验集平均准确率为82.50%(近红外)和81.98%(中红外),但二者融合后均优于单独采用一种光谱技术。邹小波等[16]发现中红外光谱建立的玉米淀粉回生模型较近红外光谱更佳。熊艳梅等[17]用近红外和中红外法测定氰戊菊酯、马拉硫磷定量模型的相关系数分别为0.998 1、0.999 4和0.994 6、0.999 8,外部验证集标准差分别为0.082、0.081和0.092、0.075,中红外的定量方法略优于近红外。Musingarabwi等[18]利用傅里叶变换近红外和衰减全反射中红外光谱技术对不同发育阶段的白苏维翁葡萄浆果进行了定性和定量分析,结果发现中红外光谱分析结果更可靠。
多组分样品红外光谱数据相对较大,很难辨析目标成分的特征分析光谱,需要选择合理的光谱区间进行分析,合适、准确的波段区间能减少计算量,同时提高精度[19],因此区间选择法和变量筛选法等在优化红外光谱模型方面得到了广泛的应用,如肖朝耿等[20]利用区间偏最小二乘(partial least squares,PLS)法,向后PLS法、向前PLS法进行波谱区间选择,结果发现向后PLS法模型效果最优。此外詹雪艳等[21]利用MATLAB软件的移动窗口PLS、组合间隔PLS和竞争自适应抽样方法进行建模的变量筛选,发现竞争自适应抽样方法能实现目标成分红外特征大部分化学特征的解析,有利于增强模型的解释性。
鉴于此,本实验以马铃薯直链淀粉与支链淀粉标准品为原材料,在iD7ATR Transmission衰减全反射附件上对样品进行扫描,获取其红外图谱,尝试利用Simca软件的主成分分析(principal component analysis,PCA)和正交偏最小二乘(orthogonal partial least squares,OPLS)回归分析筛选影响直链淀粉含量的全反射中红外光谱的特征波段,而后结合TQ analyst软件对比分析以此波段建立的直链淀粉含量定量分析预测模型的可行性和准确性。
1 材料与方法
1.1 材料与试剂
马铃薯直链淀粉标准品、马铃薯支链淀粉标准品美国Sigma公司。
1.2 仪器与设备
PTY-224/323电子天平 福州华志科学仪器有限公司;iS5傅里叶红外光谱仪、iD7 ART Transmission衰减全反射附件 美国Thermo公司。
1.3 方法
1.3.1 样品制备
准确称取马铃薯直链淀粉、马铃薯支链淀粉两种标准品,使其直链淀粉质量分数分别为0%、2%、4%、6%、8%、10%、12%、14%、16%、18%、20%、22%、24%、26%、28%、30%、32%、34%、36%、38%、40%、42%、44%、46%、48%、50%、52%、54%、56%、58%、60%、62%、64%、66%、68%、70%、72%、74%、76%、78%、80%、82%、84%、86%、88%、90%、92%、94%、96%、98%、100%,将上述称取的样品装入PE管中,拧紧管盖,旋涡振荡混合均匀,备用。
1.3.2 中红外光谱数据的采集
用药匙取少量1.3.1节制备的淀粉样品,置于傅里叶红外光谱仪的iD7 Transmission衰减全反射附件上,进行红外扫描,波数范围为400~4 000 cm-1,扫描次数共32 次,分辨率为8 cm-1,扫描间隔为2 cm-1[22]。每个直链淀粉含量的样品做2 次平行实验。
1.4 数据及图形处理
利用Simca14.1软件对不同直链淀粉含量的中红外图谱进行PCA和OPLS回归分析[23],而后采用TQ analyst 8软件对光谱数据进行处理,使用PLS建立定量模型并验证。所有图形均利用Origin2018作图。
2 结果与分析
2.1 直链淀粉和支链淀粉的傅里叶中红外全反射图谱
一般认为红外光谱中4 000~1 500 cm-1区域为官能团区;1 500~400 cm-1为指纹区[24],当分子结构略有变化时即可在指纹区的吸收峰上表现出细微差异。纯直链淀粉和支链淀粉及二者混合样品的衰减全反射中红外图谱见图1。
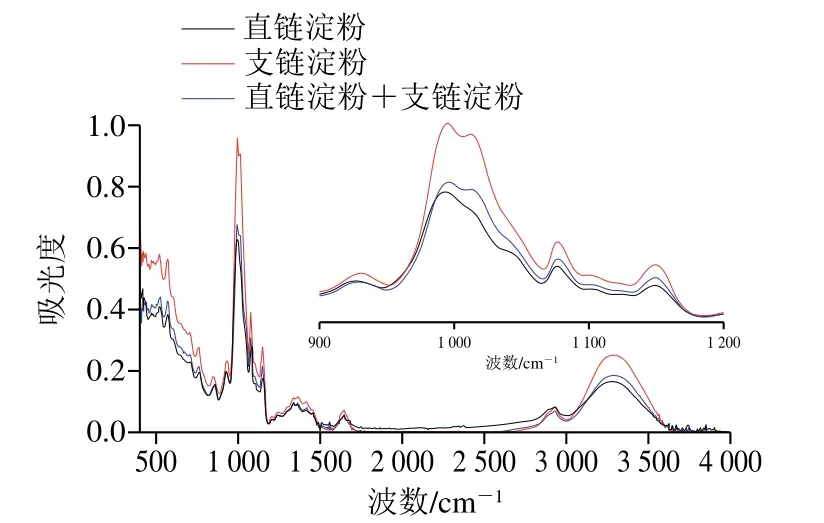
图1 直链淀粉和支链淀粉及其混合样品的傅里叶全反射中红外图谱Fig.1 FT-MIR spectra of amylose, amylopectin and their mixed samples
由图1可看出,在指纹区含有两种淀粉的特征结构,该区间含有淀粉基本结构α-D-吡喃葡萄糖环、淀粉晶体和无定形结构的特征振动,将图谱进行解卷积处理后发现,1 047 cm-1和1 022 cm-1分别具有淀粉结晶区和非结晶区域的特征振动,这与文献[16,25]的研究结果一致,同时测定发现同等浓度时由于不同样品结晶度不同,这两个波段的吸收峰也有差异。此外在900~1 000 cm-1为α-1,4-糖苷键的C—O—C伸缩振动等[26-28],因此可以利用这些振动信息与直链淀粉含量相关联建立预测模型。
2.2 傅里叶中红外光谱定量分析直链淀粉含量的特征波段的选择
每种化合物都具有特征红外吸收光谱,因此才得以进行定性和定量分析。由于样品组分众多,其获取的红外光谱分析数据集相对较大,因此要选择合适的波段,减少计算量、提高计算精度。
2.2.1 直链淀粉含量与其中红外图谱相关性确定
利用Simca软件对所有不同含量直链淀粉的中红外光谱数据进行PCA,为降低噪音的影响,对中红外光谱数据进行Ctr中心化处理后进行PCA,结果发现可以分为4 个PC,其中R2X为0.986,Q2为0.982,表明4 个PC包含了样品的大部分信息,能代表样品中直链淀粉含量的主要光谱特征,PCA的scoreplot见图2。由图2可看出,PCA结果可以客观地分析中红外光谱数据和直链淀粉含量的分布态势,随着PC1在-10~8、PC2在-2.5~1.5范围的迁移,直链淀粉的含量逐渐增加,说明傅里叶中红外图谱数据与直链淀粉含量具有一定的相关性。
2.2.2 直链淀粉含量与中红外图谱回归模型分析
为进一步探索傅里叶中红外光谱数据是否能足够预测直链淀粉含量,利用Simca软件进行OPLS回归模型分析。
OPLS是一种新型的多元统计数据分析方法,可研究Y变量和多元X变量之间的关系,最大特点是可去除自变量中与分类变量无关的数据变异,使分类信息主要集中在一个或几个PC中,模型变得简单和易于解释,其判别效果及PC得分图可视化效果更明显[29],因此利用Simca软件建立直链淀粉含量与中红外图谱的OPLS回归模型,模型的R2X为0.979,R2Y为0.958,Q2为0.940,说明此回归模型较好,为进一步考察此回归模型的可靠性,对此OPLS模型进行拟合和置换检验,结果见图3和图4。

图3 基于OPLS法回归模型的直链淀粉含量拟合效果Fig.3 Fitting of actual amylose contents to predicted values from OPLS regression model
由图3可以看出,R2为0.958 1,说明此回归方程拟合程度较高。从图4的R2和Q2可以看出,随机数据产生的模型比现有模型差很多,说明现有OPLS模型可靠。为深入了解在400~4 000 cm-1中对直链淀粉含量影响最显著的波段,对OPLS模型进行变量重要度投影[30](variable importance for the projection,VIP)分析,结果见图5。

图4 基于OPLS回归模型的置换检验图Fig.4 Permutation plot based on OPLS regression model

图5 基于OPLS回归模型VIP图Fig.5 VIP plot based on OPLS regression model
由图5可看出,直链淀粉含量模型拟合贡献比较大波段主要有400~765、969~1 158、3 250~3 329 cm-1,这3 个波段区间的VIP大于1,因此可以认为此波段可作为影响直链淀粉含量预测的特征波段。
2.3 不同直链淀粉含量的中红外图谱模型建立及验证
鉴于400~765 cm-1的噪音干扰过大,3 250~3 329 cm-1受羟基影响大,因此只选择VIP大于1的969~1 158 cm-1作为不同直链淀粉含量的中红外图谱检测的分析波段。利用TQ analyst软件对傅里叶中红外的全波段和此分析波段分别进行建模预测和验证。使用TQ analyst8软件进行数据分析,选择原始光谱数据、一阶导数、二阶导数的处理方法,在PLS法的基础上建模。
2.3.1 直链淀粉混合样品定量模型的建立
分别用随机数生成器,在淀粉红外图谱中随机选择2/3为建模集,1/3为验证集,验证集为随机选择包含高中低浓度的样品图谱,依次选用400~2 000 cm-1、主要指纹峰波段800~1 200 cm-1、OPLS分析的VIP大于1的969~1 158 cm-1三大波段为建模波段,在PLS方法基础上,每个波段分别以原始图谱数据、一阶导数和二阶导数处理的光谱数据建立两个模型,模型内部采用交叉验证的方法。表1为400~4 000、800~1 200、969~1 158 cm-1建模和交叉验证的结果。

表1 不同分析波段PLS建模的模型参数Table 1 Parameters of PLS models within different bands
所构建的模型,其内部稳健性和拟合效果是根据决定系数(RC2)和校正集均方根误差(root mean square error for calibration,RMSEC)为指标进行综合评定。模型内部预测能力以决定系数(RV2)和交互验证均方根误差(root mean squares error of cross-validation,RMSECV)为评价指标。其中决定系数越大,其均方差越小,对应的模型拟合效果就越好。
比较表1的3 个波段的PLS建模参数可知,选用400~4 000 cm-1建模时,在两个模型中,原始光谱的建模效果均显著优于一阶导数、二阶导数处理后,这可能是由于全光谱建模会将很多噪声信息纳入,这些噪音信息和反映直链淀粉含量的光谱信息混合,而光谱导数处理同时也放大了噪声信息,进而对模型造成严重干扰[31]。以800~1 200 cm-1和969~1 158 cm-1两个波段的光谱数据的建模效果显著优于400~4 000 cm-1,这两个波段建模的RC2和RV2基本上均大于0.97,说明模型的拟合效果和内部预测能力均较好,通过比较可以看出这两个波段建模效果的顺序均为二阶导数>一阶导数>原始光谱,尤其是以Simca软件筛选VIP大于1的969~1 158 cm-1RC2显著优于800~1 200 cm-1,达到了0.999 8;这可能是由于Simca筛选的分析变量去除光谱中噪音变量和冗余变量,从而提高模型的稳定性,此外对原始光谱数据经一阶导数和二阶导数处理后,反映直链淀粉的信息量得到放大,使光谱之间的差异更加明显,能将重叠的峰分开,提供了比原光谱更高的分辨率和更清晰的光谱轮廓变化,因此二阶导数处理的建模效果最优。
2.3.2 模型验证结果
进一步用验证集对模型进行外部验证,由于400~4 000 cm-1建模效果较差,同时800~1 200、969~1 168 cm-1的原始数据建模效果也较差,因而验证时舍弃。验证集数据预测结果如表2所示。为更直观地比较预测效果,将模型中验证效果良好的800~1 200 cm-1波段和969~1 158 cm-1的一阶导数和二阶导数建模的预测值与真实值进行拟合作图,结果见图6。

表2 全波长验证数据预测效果Table 2 Validation of prediction models based on full-band spectra

图6 验证集验证效果Fig.6 Validation with validation set in the region of 800 -1 200 cm-1 and 969-1 158 cm-1
所构建好的模型,根据验证样品的预测能力,以线性相关系数(RP2)和预测集均方根误差(root mean square error for prediction,RMSEP)作为评价指标观测实验结果,相关系数越接近1,RMSEP越小,则其所对应模型的预测效果就越好。此外,相对分析误差(relative percent deviation,RPD)也是评价模型预测能力的关键指标之一,RPD可以对不同样本集造成的影响进行有效消除,并能够提高实验预测的准确性,使其更加标准化。RPD越大,表征其相对应模型的预测能力越好。当RPD>3时,表明模型有很好的预测效果。
由表2可以看出,验证集的RPD都大于3,线性相关系数在0.93以上,说明这两个波段模型1、2具有很好的预测效果。但通过对比发现,以969~1 158 cm-1为分析波段经二阶导数数据处理后建模验证时,其预测相关系数最高可达到0.962 7,而预测均方差也相对较低,同时图6B的验证结果也说明中红外光谱模型预测值与真实值接近,具有较好的线性关系。
3 结 论
本实验利用傅里叶衰减全反射中红外光谱建模定量分析直链淀粉含量,为提高预测模型的准确性,利用Simca软件的PCA和OPLS分析筛选了中红外定量分析的特征波段,结果发现969~1 158 cm-1特征波段,主要对应直链淀粉的结晶区和非结晶区,同时也是α-1,4-糖苷键C—O—C伸缩振动的特征波段,基于此特征波段、全波段等,利用TQ analyst软件采用PLS法使用原始光谱、一阶导数、二阶导数的处理方法建模验证时发现,969~1 158 cm-1光谱数据进行二阶导数处理后建模的效果最优,模型的预测性能较全波段等得到了提高,模型相关系数为0.999 8,RMSEC和RMSEP分别为0.587%和6.26%,RPD为5.177 8,预测值和真实值相关系数为0.962 7。因此OPLS筛选的变量能实现直链淀粉中红外区大部分化学特征的解析,可增强预测模型的解析性。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:48
中国粮油学报(2019年4期)2019-07-12 09:06:32
数学大世界·中旬刊(2017年3期)2017-05-14 17:41:25
中国塑料(2016年2期)2016-06-15 20:29:57
高师理科学刊(2016年8期)2016-06-15 20:27:45
高中生学习·高三版(2016年9期)2016-05-14 14:05:08
西藏科技(2015年4期)2015-09-26 12:12:58
新高考·高二数学(2014年7期)2014-09-18 17:56:35
河南科技(2014年18期)2014-02-27 14:14:53
