
战斗机机载雷达视频识别与分析方法研究*
2022-01-06 08:35邢宝峻彭晓明
舰船电子工程 2021年12期
邢宝峻 彭晓明 殷 哲
(空军预警学院 武汉 430014)
1 引言
近年来,随着军事科技的不断发展,越来越多的高技术装备列装部队,这些装备技术集成度高,操作难度大,对部队训练水平提出了更高的要求,尤其是对于航空兵部队,随着战斗机的不断更新,如何正确评估飞行员的训练水平、制定科学高效的训练计划成为制约半部队实战化水平提升的关键。而随着视频与图像识别技术的发展,视频的识别与分析与军事训练结合的越来越紧密,通过对战斗机机载雷达视频进行分析,不仅可以准确评估飞行员对机载雷达的操纵水平,还可以为查找飞行员飞行训练短板弱项,针对性制定飞行训练计划提供有力的数据支撑,提升飞行部队实战化训练水平。
现代主流视频分析的设计模式分为前端视频分析和后端视频分析,由于战场环境瞬息万变,且前端视频分析具有对硬件资源要求高和缓存难度大的特点[1],而战斗机机载雷达视频分析,更多地是为飞行训练计划制定、飞行员雷达操纵评估等方面提供可靠依据,所以主要采用后端视频分析的方式,即将视频采集和视频分析分离进行,对实时性要求不高。本文主要通过对已有的战斗机机载雷达视频特点进行分析,提出了视频识别的方法手段,为利用雷达视频为下步飞行相关训练进行评估和计划制定提升了可能。
2 机载雷达视频的特点
1)分辨率较低。由于战斗机在作战过程中机动性强、电信通道低的特点,所以机载雷达视频通常采用H.263编码模式进行,H.263是由ITU-T制定的应用低码率的视频编码标准,它采用混合的视频编码体系,可以保证视频信息在易误码、易丢包的异构网络环境下的传输,同时采用高精度的运动补偿来实现更加精确的预测[2],但是由于H.263模式是面向低码率的视频编码而设定的,所以得到的视频分辨率较低。
2)视频画面呈现二值化。为方便飞行员战斗时快速寻找并锁定目标,战斗机机载雷达视频普遍简捷易懂,视频画面以黑白两色为主,以几何图形、字符为主要形式,在进行视频处理时无需对视频画面进行灰度处理,有利于提升视频处理的效率。
3 机载雷达视频的预处理
由于现代机载视频的分辨率较低、视频画面二值化等特点,所以为准确分析战斗机机载雷达视频,首先要对视频进行预处理,通过视频的压缩、按帧截取成图像、图像的拼接融合等工作,将视频信息转化为图像信息,再通过对拼接的图像进行腐蚀与膨胀的操作,降低原机载雷达视频分辨率低以及在图像拼接过程中对图像造成的损坏的影响,为下步识别做准备。
3.1 视频的压缩
由于战斗机机载视频占用空间较大,在进行视频分析过程中会占用大量的时长,导致分析效率降低。针对这一情况,在对视频进行预处理时,可先对视频进行有损压缩,即舍弃视频中不影响原含义的数据[3],由于视频中的数据信息实际由信息量和冗余数据量两部分组成,通过视频的压缩算法,可以对视频原始数据进行变换、量化、编码,保留信息量,把实际存在的冗余信息去掉,从而减少它的数据量,既保证了视频图像质量,又达到了减小占用容量的目的。通常重新进行编码后的视频会完成视频文件格式的转换,由AVI视频文件格式转换为占用空间较小的flv、mp4等格式,这些格式的特点是自身空间占有率低、视频画面质量良好,有利于缩短视频分析过程中的时长,提高分析效率。
3.2 图像截取与拼接
由于是对已有的战斗机机载雷达视频进行分析,实时性要求不高,所以采用将视频信息转化为图像信息而后进行识别的方法进行,利用python语言和OpenCV将视频按帧截取成图像进行保存,而后利用Tesseract引擎对图像信息进行OCR识别,提取出关键信息。
由于对视频流进行按帧截取操作得到的图像较多,为提高识别效率,适当采用图像拼接技术将截取的图像进行拼接,再对拼接后的图像进行识别。图像的拼接技术通常包括特征点提取与匹配、图像配准、图像融合等三大部分。首先,进行特征点提取,由于SURF算法[4]具有良好的精度和鲁棒性,同时又具有较好的实时性,所以采用SURF算法完成图像序列特征点的提取。其次,图像配准是一种确定待拼接图像间的重叠区域以及重叠位置的技术,是整个图像拼接的核心,可以采用基于特征点的图像配准方法,即通过匹配点对构建图像序列之间的变换矩阵完成全景图像的拼接。最后,根据图像间变换矩阵,对相应图像进行变换以确定图像间的重叠区域,并将待融合图像映射到到一幅新的空白图像中形成拼接图。

图1 拼接后的图像
3.3 腐蚀与膨胀
在进行战斗机机载雷达视频预处理时,由于视频具有分辨率低的特点,且在经过对视频进行压缩和图像的拼接后,得到的图像中个别字符会变得模糊不清,同时会出现一些孤立的“白点”,这些“白点”的存在会影响识别的准确率,所以要对图像进行腐蚀与膨胀的处理,以消除“白点”的影响。
图像形状学中膨胀运算实质是采用向量加法对两个集合进行合并,达到将目标区域的外边界变成对象,使目标区域得以扩展,即将图像的边缘进行扩大的目的,实现将目标的边缘或者是内部的坑填掉的效果[5]。其表达式如下:

其中膨胀A⊕B是两个向量之和的集合,而向量加法的两个操作数分别取自向量A和B。
而腐蚀运算的实质则是通过向量减法实现对两个集合元素的合并,通过运算,寻找线段的内点段并将它们保存下来,起到将目标区域的内边界变成背景,以此来缩小目标区域的目的,实现将图像边缘的“毛刺”踢除掉的效果。腐蚀算法是膨胀算法的对偶运算,其表达式:

在对图像进行处理时,本文通过进行形态学梯度计算,即膨胀图像与腐蚀图像的作差得到的差值图像,来刻画目标边界或边缘位于图像灰度级剧烈变化的区域,以此突出图像中处于高亮区域的字符的外围,从而使字符的外轮廓更加突出,方便进行字符的识别。

图2 原图

图3 膨胀图像
图4 腐蚀图像

图5 形态学梯度图像
4 机载雷达视频的识别
对战斗机机载雷达视频的识别主要通过调用Tesseract引擎进行。Tesseract是惠普实验室在1985到1995年间开发的一个开源的OCR(Optical Character Recognition,光学字符识别)引擎[6]。2005年,惠普将Tesseract的源代码对外开放并放弃对其的维护,2006年Google继续对Tesseract进行改进、消除Bug以及优化工作[7]。由于Tessseract引擎具有开源性和提供自定义字符库训练方法的特殊性,所以其可以通过不断进行训练,增加字符库,不断增强其图像转换为文本的能力,最终使Tesseract成为目前公认最优秀、最精确的开源OCR系统。
4.1 Tesseract的识别架构
Tesseract识别字符过程通常由五个部分构成:页面布局分析、查找目标块区域、定位文本行和单词并进行分割、分析识别、模糊区域改进。
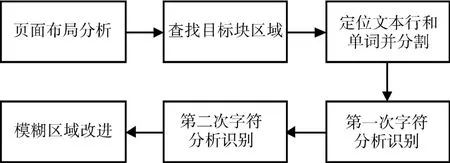
图6 Tesseract的架构
1)页面布局分析。对文本进行页面布局分析,通过页面布局分析,可以将图像中的文本和非文本区分开,同时提取出文本区域,得到图像中文本区域的排列布局和分布方式,并检测出文本区域中的字符的轮廓。
2)查找目标块区域。在Tesseract中,通过对文本区域中的排列布局进行分析,可以得到一个或多个相互关联的“块”,这个“块”被称为Blob,在计算机视觉中的Blob是指图像中的具有相似颜色、纹理等特征所组成的一块连通区域,这些“块”组合形成目标块区域。
3)定位文本行和单词并进行分割。在找到目标块区域后,通过对区域中相邻字符之间的垂直重叠关系进行检测,可以得到处于水平状态的文本行。对字符间的水平关系进行检测可得到字符的间隔,根据字符间隔对文本行进行分割方可得到单词。通常文本中的字符连通区域的间隔可分为固定字符间隔、按比例排列的字符间隔和模糊字符间隔,对于固定间隔的文本可通过字符单元分割出单个字符,而对按比例排列的文本和模糊间隔的文本以协作关系共同分割得到单个字符。
4)分析识别。Tesseract会采用自适应分类器依次对每个单词进行分析,分类器会对每个单词进行分类,并将结果在相对应的字典中进行搜索,并与样本图像进行对比,在字典中找到相似度最高的样本图片对应的单词则进行确认[9]。自适应分类器本身具有“学习能力”,可以将先分析得到的满足条件的单词作为训练样本,增加后面字符识别的准确率。而对于识别不准的单词,则通过利用A*算法搜索最优的字符组合,直到得到满意的识别结果。
5)模糊区域改进。对于粘连的字符形成的模糊区域,可以将字体形状的几何体顶点作为备选分割点进行分割,之后根据识别置信度来判别字符。如果都失败,就认为字符破损不全,则对字符进行修补,而后利用A*算法搜索最优的字符组合,得到识别结果。
4.2 建立字符库
虽然Tesseract引擎提供了相应字符库以满足字符识别的需要,但是通过实验发现直接调用Tesseract引擎中的字符库进行识别准确率不高,会影响相关数据的分析效果,所以利用Tesseract引擎可自行训练字符库的特点,结合战斗机机载雷达视频中字符的特点,训练出自己的字符库。具体方法如下:

图7 Tesseract训练字符过程
1)选取样本图像。在战斗机机载雷达视频截取的图像中选取一定数量有代表性的图片作为样本图像,根据机载雷达视频的记录特点,主要识别内容有三项内容,一是作战时间,二是雷达所处的工作状态,三是雷达中记录的飞机的飞行状态、搜索到的目标等相关参数,根据这三项内容选取样本,样本内容要包含全部需要识别的字符,其中对于经常出现的字符,每个字符至少选取10次以上的样本数量,保证样本数量充足,有利于提高训练的质量,提升识别的准确率。此外,在训练字库时,对视频中出现的不同字体的字符分成不同的字库进行训练,保证同一个字库内的字体的统一。
2)合并样本图像,生成Tiff图片集。Tiff(Taggen Image File Format,标记位图文件格式)是为跨平台储存扫描图像而设计的一种图像文件格式,由于它采用无损压缩的形式,所以以tiff格式存储的图像信息多、质量高,具有拓展性强、存储方便、可改性的特点,基于这些特点,在进行字符训练时,多采用tiff格式的图像进行。因此,将准备好的战斗机机载雷达视频字符的样本图片统一转换成tiff格式文件,并整合到同一个Tiff图片集里,供后面训练使用。
3)文本检测,生成Box文件。文本检测是一种特殊的目标检测,可以对图像中的文本进行定位,正确检测出需要覆盖的文本的长度,并在文本四周生成矩形边界框[10]。通过文本检测可以按顺序地列出训练图像中的字符,并通过边界框将每个字符分开,同时显示出每个字符在图像中的定位信息和边界框的长宽、大小,其中Box文件是一个文本文件,是Tesseract引擎中识别出的文字和其坐标的集合。
4)文字校正。对文本检测后的文本进行校正,调整在文本检测中标记边界框时出现的偏差。在对新字符进行训练时,由于Tesseract对新字体的识别正确率有限,所以文本检测时会出现一些错误,可以通过合并、分离、添加、删除等手段对矩形边界框进行调整,使边界框刚好框住每个字符,通过校正可以使Tesseract引擎在识别时正确分割出每个字符并进行识别,以此形成的字库才可以有效提升识别的准确率。

图8 文字校正
5)计算字符集,生成字符集文件:Unicharset文件。Unicharset文件是Tesseract中的字符集文件,它包含了Tesseract引擎训练后可以识别的每个字符的信息,是Tesseract新字库语言的一部分,其中Unicharset文件的第一行显示了文件中所包含的字符数,后面的每一行则是所有单个字符的信息。
6)生成字体特征文件。由于在现实生活中,同一种语言中往往存在很多种不同的字体,所以字库文件中也包含了记录字体属性的文件,这类文件就是字体特征文件,而字体特征则是用来识别文字的关键信息,每个不同的文字都能通过特征来和其他文字进行区分。而常用的特征提取方法是HOG(Histogram of Oriented Gridients)方向梯度直方图[11]。方向梯度直方图是目前计算机视觉、模式识别领域中常用的一种描述图像局部纹理特征的一种方法。首先将文本图像分成小的连通区域,这些连通区域也被叫做细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图累积组合起来,构成特征描述符,并作为特征,可以输入Tesseract分类器中完成字符的识别。
7)合并训练文件,生成字符库。将box文件、Unicharset文件、字体特征文件等文件进行合并,生成字符库。
4.3 优化与提高
对于Tesseract引擎而言,虽然其可以通过改变图像尺度、二值化、旋转和抗扭斜等方法来提升识别的质量,但是基于战斗机机载雷达视频的特点,通过不断完善字符库提升识别的准确率无疑是最有效的途径,在后期进行训练时,可以字库中添加模糊字文件[12]来提升识别质量。模糊字文件不是字库中所必需的文件,它是对识别过程中容易出错的字符的汇总,通过调用模糊文件,可以帮助修正识别中的错误,以提高最终准确率。在后期进行识别时,对容易出错的字符进行整理与汇总,形成模糊字文件,并对这些字符进行多次训练与识别,最终形成词典。再次调用Tesseract引擎对类似字符进行识别时,可以通过A*算法搜索最优的字符组合,自动调用形成的词典,得到正确的识别结果,达到提升识别准确率的效果。
5 识别结果分析
为检验方法的有效性,本文将收集到的战斗机机载雷达视频分为样本集和测试集两部分,其中,对样本集中的视频主要进行字符样本的收集和字符库的训练,通过大量的样本字符建立起完整可靠的字符库。测试集中的视频主要用来检测视频识别的可靠性,通过调用利用样本集训练的字符库,对测试集中的视频进行识别,检测出识别的准确率。通过测试发现,利用本文研究的视频关键信息识别方法准确率为90.72%。

图9 字符重叠图
其中,绝大部分内容识别正确。少数内容在识别过程中会出现符号识别错误,主要原因在视频运行过程中部分非符号部分会与符号部分在个别时段会产生重叠(如图9所示),产生交叉后的字符与原本字符形态相差较大,这导致在对字符进行分割后,Tesseract引擎无法在字库中找到与之相对应的字符,影响对符号的识别。在后期研究中,会加大视频的语义分析,根据视频前后帧之间的关联进行识别。
6 结语
本文通过研究,得出了对战斗机机载雷达视频识别的一般方法,通过前期对视频进行预处理后,调用Tesseract引擎对视频内容进行识别,同时不断训练字符库以增强识别的质量和准确率,对战斗机机载雷达视频的识别与分析,不仅可以科学准确地评估飞行员对机载雷达的操作水平,查找其在飞行过程中的短板弱项,完成对飞行训练的复盘检讨和对飞行训练的成绩评定的需要,进而促进航空兵部队实战化训练水平的提升,还可以通过对不同人员的训练数据进行汇总,能够形成相关的飞行训练数据库,为下一步的训练评估与训练计划制定提供依据。
猜你喜欢
汽车工程师(2021年12期)2022-01-18
电脑报(2021年41期)2021-11-04
百科探秘·航空航天(2021年8期)2021-08-16
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
读者(2015年9期)2015-05-04
农机使用与维修(2014年10期)2014-10-23
意林(2011年10期)2011-05-14
航空知识(2001年5期)2001-06-12
