
基于损失函数优化的巷道人体识别算法
2022-01-06 11:11中国矿业大学北京机电学院裴宇轩宋超凡曾日桓张国英
数字技术与应用 2021年12期
中国矿业大学(北京)机电学院 裴宇轩 宋超凡 曾日桓 张国英
为了解决巷道及煤矿工作面人体目标检测的准确和实时问题,本文设计一种基于预测目标损失优化的YOLOv3网络模型。实验结果表明,基于损失函数优化的网络模型的矿下人体识别方法,损失显著下降,误检下降,漏检得到改善。
0 引言
煤矿巷道及工作面环境复杂,存在着一定的危险性。对煤矿巷道及工作面工作人员实时准确识别,是降低煤矿伤亡事故的基础。
深度学习方法模拟人类大脑的神经元,直接从图像提取特征,逐层传递,获得图像的高维信息[1-2],传统方法则需要手动提取特征信息。目前基于深度学习目标检测方法可分为两类:第一类,首先生成目标候选框,再对候选框做分类和回归预测,如R-CNN、Fast R-CNN、Faster R-CNN等。另一类,不需要产生候选框,卷积神经网络直接预测不同目标的位置和种类,如SSD、YOLO系列网络等。对于实时性要求较高的场景,选用一阶段类型FPS较高的目标检测方法更为合适。
本文提出了用于矿井环境下人体识别的YOLOv3检测算法。首先改进了锚框中心坐标的损失函数[3],利于训练迭代的收敛[4];接着将无关背景造成的损失权重进一步下降,减少其对总损失的贡献,以便更好的符合实际矿井环境[5]。
1 损失函数优化的YOLOV3目标检测算法
YOLO首创了使用回归思想进行目标检测的方法,这么做将目标检测问题转化为了回归问题,通过预测变量的方式来检测物体的边界框坐标和物体类别。
1.1 YOLOv3网络结构
YOLOv3网络结构如图1所示,分为骨干网络Darknet-53以及目标检测网络两部分。
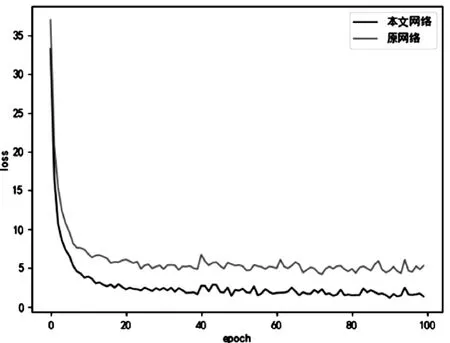
图1 验证集损失曲线对比Fig.1 Comparison of loss curve of verification set
Darknet-53的每一个卷积层都使用了特有的二维卷积的结构,在每一次卷积时都进行L2正则化,卷积完成后进行标准化以及Leaky ReLU。一般的ReLU是把所有的负数都设为0,而Leaky ReLU则是把负值都赋予一个非零斜率,数学表达式如式(1)所示:
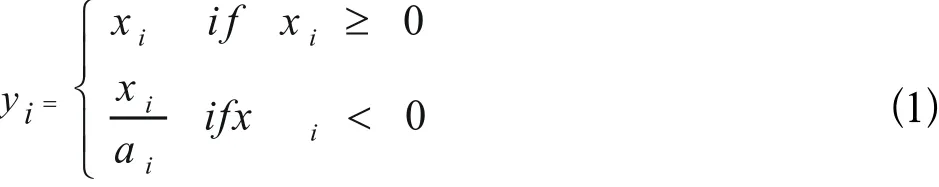
1.2 K-means聚类设定锚框参数
YOLOv3采用参考锚框的偏移量作为预测值机制,预测锚框中心点的坐标以及锚框的宽高。预测锚框与真实框的偏差值是K-means算法的输出值。原YOLOv3生成9个锚框,不同尺寸大小的特征图对应三个锚框。但公共数据集的样本具有普遍性,所设定的锚框参数对特定样本不具有普适效果。所以为了更好的预测真实边界框,需要调整预设的锚框参数[6]。
在YOLOv3中,Anchor聚类生成的计算公式为:
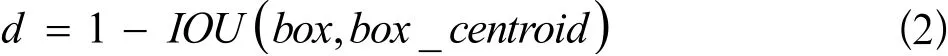
最终在自制的矿井人员数据集经过K-means聚类得到9个锚框,如表1所示。

表1 修改后的锚框参数Tab.1 Modified anchor frame parameters
1.3 损失函数权重优化
训练过程中,对于不需要检测出的物体称为误检测样本,要为其添加一个权重,该权重通过损失函数来定义。代表着检测错误受到的惩罚,因此也称为惩罚项。设计符合实际场景的损失函数,对训练模型的收敛速度和检测精度有着很大影响。
1.3.1 损失函数
YOLOv3的损失函数采用均方差结合交叉熵的形式,见公式(3)。

公式3中前两项是锚框误差,对中心坐标和验证框的宽高做平方均值化处理,其中λcoord为权重;代表第i个网格的第j个锚框是否包含物体中心。和是网络经过归一化操作后得到的预测值,值域为[0,1]。
为了增加背景和人体区域的差异性,提出一种动态调节权重的YOLOv3损失函数[7],在迭代收敛速度上有较好的优化,准确度也有一定的提升。
1.3.2 无样本权重降低
在面对本文特殊的数据集时,会产生以下阻碍模型得到高效训练的困难:
(1)背景环境占据图像大面积:若背景环境的权值过高会导致网络训练收敛非常缓慢,因为降低了识别目标的占比过小,网络会倾向于识别成背景环境。
(2)难以识别样本损失优化:如果某个样本很明显是真实样本,那么它的值极其接近1,但可能它的预测值远小于1。以上情况需要对其损失函数进行复杂的优化,否则会对损失收敛和识别准确率造成巨大的代价。
1.3.3 优化锚框中心偏移损失
均方差损失会将背景环境与识别目标的预测概率和真实概率都进行计算,而交叉熵函数只会关注识别目标的预测概率。本实验是单分类任务,交叉熵比MSE更为合适。
在本文实验中,优化后的损失值为原损失的三分之一。
以下是原中心坐标的损失表达式:

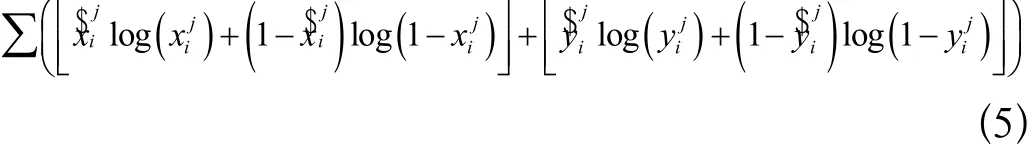
改进后的表达式为:
2 数据采集与实验设计
2.1 人体实验数据
在矿井下这一特定环境中,仅仅使用矿井的原始样本是不够的。于是加入了VOC2007中272张人体图片,加强训练模型的鲁棒性。
2.2 数据采集
样本主要是通过两种方式获得,从矿井监控摄像头的视频经过逐帧截取得到的,此类图片大都是弱光照,背景对比度较强的样本,一共780张;另一部分选取了VOC 2007公共数据样本,一共272张,合计1052张。
2.2.1 数据划分
按照训练集、验证集、测试集18∶2∶5的比例划分数据集。最终划分结果为训练集+验证集843张,测试集209张。
2.2.2 标注方法及内容
本文使用Labelimg软件标注每张图像,标注信息为人体分布情况以及人体边框的左上坐标和右下坐标。
2.3 数据样本处理
对数据集训练处理的步骤:(1)构建VOC的文件目录;(2)由训练集(Train)与测试集(Val)9∶1的比例,生成存放有标注信息的文本;(3)生成最终训练的文本。接着设置好训练参数,即可开始训练。
2.4 网络结构及参数设置
本文训练了两个网络模型,一个是标准YOLOv3网络,设为对照组,其具体的网络结构见文献;另一个是本文构建的网络。
本文实验平台为:Windows10操作系统,IntelCorei7-7700hq处理器,NVIDIAGTX1060独立显卡,6G显存,8G内存。采用Pytorch框架进行训练,Torch版本1.2.0,Torchvision版本0.4.0,Cuda版本10.0,Cudnn版本7.4.1.5。
3 实验结果
最后对实验得到的权重进行准确率测试,最终得到如下结论。
(1)改进了锚框中心偏移损失函数的YOLOv3模型对训练过程中损失的收敛速度有着大幅提高,并且最终得到的权重损失有着大幅下降。如图1所示,改进的模型在20轮次已经收敛,而原网络在40轮次接近收敛;改进模型的最终损失下降了三倍之多。
(2)如图2所示,原网络mAP值为96.83%,改进后的网络mAP值为96.92%,有了一定的提升。
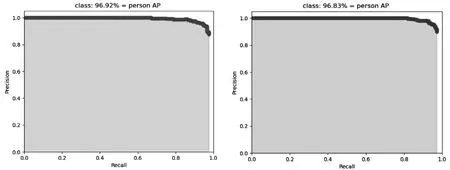
图2 测试集mAP(左:本文网络,右:YOLOv3原网络)Fig.2 Test set map(left: this network, right: YOLOv3 original network)
4 结语
本文提出了一种基于锚框优化及改进损失函数的YOLOv3网络模型,对于复杂背景、背景环境多的场景,降低背景环境对网络损失的影响,从而提高识别目标的准确率和训练损失的收敛速度。
迄今为止,YOLOv3作为一阶段网络模型中检测速度快,检测效果好的优异方案,已经在军事、工业生产、航空航天、教育等方面大量落地实施。本文提出的方法,在矿井这一特定光照较暗,背景无关信息较多的环境下有较好的表现。
引用
[1] 陈聪,杨忠,宋佳蓉,等.一种改进的卷积神经网络行人识别方法[J].应用科技,2019,46(3):51-57.
[2] 秦升,张晓林,陈利利,等.基于人类视觉机制的层级偏移式目标检测[J].计算机工程,2018,44(6):253-258.
[3] 张宽,滕国伟.基于位置预测的目标检测算法[J].电子测量技术,2019,42(19):164-169.
[4] 麻森权,周克.基于注意力机制和特征融合改进的小目标检测算法[J].计算机应用与软件,2020,37(5):194-199.
[5] 乔婷,苏寒松,刘高华,等.基于改进的特征提取网络的目标检测算法[J].激光与光电子学进展,2019,56(23):134-139.
[6] 鞠默然,罗海波,王仲博,等.改进的YOLO V3算法及其在小目标检测中的应用[J].光学学报,2019,39(7):253-260.
[7] 刘晓楠,王正平,贺云涛,等.基于深度学习的小目标检测研究综述[J].战术导弹技术,2019(1):100-107.
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
知识经济·中国直销(2018年8期)2018-08-23
中国老区建设(2016年1期)2016-02-28
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
