一种高性能硬件加密引擎阵列架构
2022-01-04 09:35骆建军沈一凡冯春阳邓江峡
电子与信息学报 2021年12期
骆建军 沈一凡 周 迪 冯春阳 邓江峡*
①(杭州电子科技大学微电子研究中心 杭州 310018)
②(浙江宇视科技有限公司 杭州 310051)
1 引言
随着越来越多的硬件设备连接到互联网中,物联网安全面临在扩展连接环境下安全威胁引发的复杂挑战[1]。执行具有最小延时的高计算力的安全认证是网络安全的保障[2,3]。为了增强服务器性能,可以使用更为强大的CPU/GPU[4]。然而,即使执行少量的安全负载,CPU的容量和效率也会因此而降低[5]。
本文介绍了一种替代解决方案,即一种具有高速、高吞吐量的可插拔式硬件加密卡,来应对安全需求,并将CPU从执行加解密算法(如RSA[6]、ECC[7]、AES[8]等)的任务中释放掉。这种类型的密码模块(设备)会帮助服务器在不降低CPU性能的情况下处理大量验证请求。同时,这个模块和CPU之间通过高速接口来交换数据。以PCIe接口[9]为例,目前流行的是具有16个Lane的PCIe Gen4的CPU/GPU,其传输速率可达到32 GB/s,假定物联网系统认证按4 kB大小的数据包进行处理,那么该模块可执行8×106次认证操作。
要设计一种安全算法计算能力与8×106IOPS总线能力相匹配的PCIe卡其实是一个棘手的工程问题。虽然已有一些用FPGA实现的密码卡产品[10-12],但这样的产品里面每个引擎都需要进行数学运算,而这些运算受到硬件资源和物理逻辑门参数限制。要提供充足的逻辑门就需要用到多个FPGA芯片,即使这样其性能仍然低于期望值。
本文提出了一种新的加密引擎阵列架构,其多个加密引擎可以并行计算。这一架构用更少的引脚或连接来定义加密引擎接口,以降低封装成本。同时,考虑到eMMC总线与SPI总线类似,采用eMMC总线构建加密引擎阵列,使其在两个维度上都可以提供更高性能。此外,本文以PCIe接口为原型,还描述了一种高性能加密ASIC设计来验证该方法,并分享工程经验。
2 模块架构
2.1 架构描述
图1是经过实践检验达到预期性能的加密模块架构,由一个高速接口、一个中央管理监控模块(Central Manage & Monitor Module, CMMM)和一组多通道驱动的加密引擎构成。

图1 加密模块架构
高速接口被连接到使用PCIe, SAS, SATA的主机总线上。片上算法IP阵列会运行多个算法引擎,而每个引擎都有一个数据包接口,该接口可用于机械硬盘、固态硬盘、SD卡、eMMC卡[13]、SPI接口[14]或SATA接口[15]。外加的数据缓冲区用于接收从主机来的命令和数据包,或返回给主机已处理过的数据包和相应的状态信息,以提高模块的性能和稳定性。
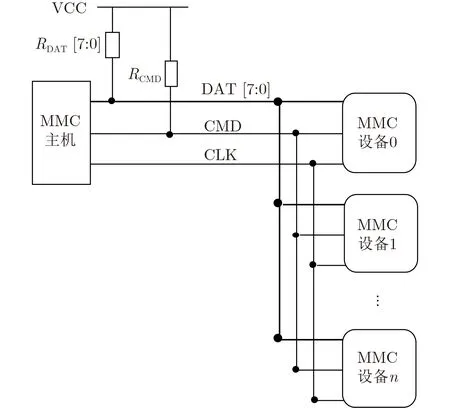
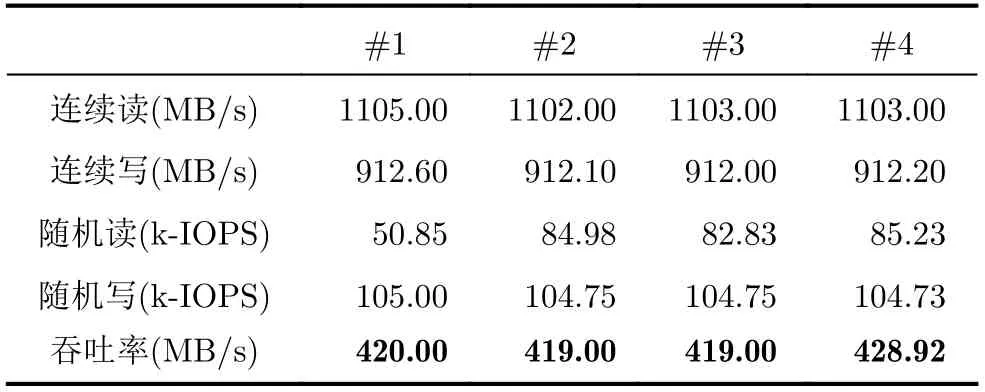
加密引擎阵列有N个并行的加密通道(CCi,0≤i 加密引擎由通道接口、数据缓冲区和具有安全密钥寄存器的特定算法组成,如图3所示。 图2与图3的缓冲区非常重要,因为它实际上是一个由CMMM管理的队列。这就使得模块能连续地接收含有命令和数据包的任务而不管之前的任务是否完成。所有的任务都临时被压入队列,而CMMM将把任务分配给任何空闲着的加密引擎。根据应用程序要求,CMMM也可以按不同的优先级来分配这些任务。图4是CMMM管理任务流程示例,主机依次发送任务1、任务2、任务3,CMMM对这些任务动态进行调整,并分配给加密引擎。最终,主机先后收到任务2、任务3、任务1完成后的数据和状态信息。显然,缓冲越大,队列越长,模块可达到的性能也就越高。 图2 使用MMC接口的加密块 图3 加密引擎结构 图4 加密任务流程 由于所有高速接口(如SATA, PCIe)的物理层使用差分信号进行传输,不能级联到阵列中,这也就意味着M只能为1,限制了该架构灵活地扩展到更大规模。因此,可以采用SPI总线或MMC/eMMC总线进行数据传输。 SPI总线可以通过添加片选信号(CS)实现级联来构建一个2维加密阵列,但是通常的SPI总线的最大数据传输速率为1.2 MB/s,假设用4 kB大小的IO测试,其远小于300 IOPS,不能为认证过程提供足够的吞吐量。 MMC/eMMC具有与SPI总线类似的总线结构,其总线宽度还可以扩展到4位,甚至8位,其定义的一种机制可以通过某个部件号来选择或激活模块(卡),并且基本的MMC/eMMC模块可提供至少为25 MB/s的数据传输速率,最新的eMMC5.1可提供高达400 MB/s的数据传输速率,接近SATA III和USB3.0的性能。 鉴于以上分析,本文采用MMC/eMMC总线进行数据传输。MMC/eMMC设备通过可以配置数量的数据信号总线来传输数据。这些通信信号描述如下: CLK:从主机输出的时钟信号,每个信号周期下命令总线上传输1 bit,所有数据总线上传输1 bit或2 bit。时钟频率可以在零到最大时钟频率之间变化。 CMD:双向命令通道,用于设备初始化和命令传输。 DAT0-DAT7:双向数据传输信号,在推挽模式下工作,同一时刻进行单向传输(主机或设备驱动该信号)。在上电或复位后,默认只有DAT0用于传输数据。 MMC/eMMC总线的一个特性是在CMD线上采用“线与”机制时,可使某个设备在总线仲裁程序设置的环境中作为一个多终端设备运行。主机在开漏模式下开始设备识别过程,CMD线上的开漏驱动级允许在设备识别过程中进行并行的设备操作。驱动多台设备的MMC/eMMC架构如图5和图6所示。 图5 一个MMC主机驱动多个MMC设备 总线被激活后,主机将给设备发送有效运行条件 (CMD1),对于CMD1的响应就是“已连线”和对系统中所有设备进行环境限制操作。将不兼容的设备设置成“Inactive State”。然后主机发送广播命令ALL_SEND_CID(CMD2),要求所有设备发送其唯一的设备标识码(Device Identification Number, CID)。所有处于“Ready State”的设备在CMD线上同时相继发送其CID,只要这些设备发出CID的位与在任何一个“位”周期内相应的位有不匹配时,这些设备将不会被选上,还会立即停止发送其CID,保持“Ready State”,等待下一次识别周期。因为每个设备都有唯一的CID,所以最终只有一个设备给主机成功发送其完整的CID,这个设备之后进入“Identification State”状态。然后,主机发送SET_RELATIVE_ADDR(CMD3),为这个设备分配一个关联设备地址(Relative Device Address, RCA),用于数据传输。一旦RCA被接收,Device进入“Stand-by State”,由开漏模式变为推挽模式,不再对之后的身份识别周期做出反应。主机会重复设备识别过程(CMD2,CMD3循环),直到所有设备被识别,不再有设备响应。识别过程超时的条件是发送CMD2后超过一段时间(eMMC规范中定义的NID时钟周期)没有收到响应。之后,主机可以使用CID激活任意设备,并强制其他设备在总线上保持安静。 如果一个加密模块共有M×N×K个加密引擎,那么它能同时处理M×N×K个认证请求。比如每个加密引擎每秒可以运行R次AES或SHA算法,那么这个模块可以每秒执行M×N×K×R次AES算法,也就是说它的最大计算能力CAmax可以表示成: 但这不是最终测试到的性能,因为加密模块与主机间的接口吞吐量很可能是性能瓶颈。SATA接口的最大数据传输率TSmax=750 MB/s,PCIe Gen3×4的TSmax=4 GB/s。模块的最终性能由{CAmax,TSmax}的最小值决定。 为了分析模块性能和时延,定义以下几个变量: Tc:加密引擎处理一个命令数据包的时间。 Tt:处理器的本地缓冲区和模块中央缓冲区之间的数据传输时间。 Ti:通过通信接口接收数据的时间。 Tw:数据包在IO队列缓冲的时间。 模块中的加密引擎越多,电路可以提供的性能越高。假设原始数据被分割为P个小数据包,每个数据包的大小为4 kB。加密或解密一个数据包需要Tc,共有N个并行运行的加密通道,每个通道可运行M个加密块。那么电路每秒可以执行N ·M/(Tc+Tt)次加密/解密操作,在此忽略了给模块分配任务的时间。那么,IOPS可表示成 加密/解密处理器的延迟由多个参数决定。比如,如果有一个或多个空闲的加密引擎,此时数据包以最小的延迟通过中央缓冲区被加密引擎处理[18],Tw可以取最小值并忽略不计。如果所有的加密引擎繁忙且IO队列已满,接收到的数据包在中央缓冲区处于等待状态,直到有一个加密引擎被释放到空闲状态,Tw具有最大值。Tw的计算公式为 假设缓冲区的最大容量Cmax=4 0 0 0,Ti=1 ms,Tc=5 ms,Tt=1 ms,当N=1, 2, 4, 8,M=1,8时,理论计算得到的最大总时延TL如表1所示。 表1 不同情况下的最大总时延(ms) 缓冲区的容量,即IO队列的最大深度,必须满足队列请求的数量大于加密引擎的数量,否则一些加密引擎将会被闲置,模块整体性能无法达到最高。另外,如果IO队列深度配置得过大,响应的时延就会增加。因此,IO队列的深度应该有一个极值。一般来说,队列深度可以等于密码引擎数量,并且每个队列请求在缓冲区可占用1~4 kB空间。也就是说在时延可以接受的情况下,队列深度越大越好。 为验证该架构,本文完成了一个PCIe Gen2×4接口的ASIC加密模块。使用55 nm制程工艺,最终制备出尺寸为4.8 mm×4.7 mm的芯片,时钟频率高达500 MHz。 该模块共有8个通道(N=8),每个通道驱动8个eMMC模块(M=8),每个模块有16个加密引擎(K=16),单个加密引擎每秒可以执行133次SHA-256加密操作(R=133),并且 IO大小为4 kB。测试结果见表2,表明其平均吞吐率等于419.23 MB/s。 表2 性能测试 目前已报道了具有高性能密码设计的FPGA解决方案。比如文献[19]中由3块Xilinx Virtex FPGA芯片实现的模块,其SHA-256吞吐率为47.75 MB/s。而本文ASIC架构其吞吐量是它的8~9倍。 PCIe Gen4的速度比Gen2的快4倍,如果使用PCIe Gen4×8接口,理论上,该模块的IOPS可达到容量为100k×4×2=800k,每个加密通道可提供100k的IOPS吞吐量,每个eMMC加密块的IOPS应大于12.5k。实际上,eMMC总线频率高达200 MHz,这可以支持运行最大为25k的IOPS。这意味着模块可以在1 s内用SHA-256算法处理800k次认证请求。即使面向更高性能需求,(M,N) = (8, 8) 甚至 (M,N) = (8, 4)的配置仍然能满足这一需求。 本文实现的ASIC加密模块中,IO队列深度被设置为128,由于IO队列深度提供了足够的等待缓冲区,所以所有加密引擎都有足够的时间运行相应的算法。如果IO队列深度过小,IOPS将会下降到1.3k左右。PCIe Gen3×4的数据传输速率高达4 GB/s。其发送和接收数据的时延Ti=4 kB/(4 GB/s)=1 μs。 考虑到大多数情况下数据传输率较为稳定,在相同硬件配置的情况下,Ti不会有太大不同。因此,时延主要由在IO队列中的等待时间决定。测试结果如表3所示。 表3 随机读写的时延(μs) 本文描述了一种高性能的支持并行运算加密引擎阵列的PCIe接口加密卡,其平均吞吐率高达419.23 MB/s。此外,模块集成的加密引擎越多,模块的性能就越好。下一步的工作目标是采用最新的PCIe接口、更多的PCIe物理通道以及更强大的加密算法引擎,为物联网安全系统提供更高性能的加密卡。


2.2 总线分析
3 性能分析




4 测试结果

5 结论
猜你喜欢
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
沈阳工业大学学报(2018年1期)2018-01-08
水利规划与设计(2017年11期)2017-12-23
商周刊(2017年22期)2017-11-09
产品可靠性报告(2017年7期)2017-09-05
河南电力(2015年5期)2015-06-08
项目管理技术(2015年3期)2015-04-23
皖西学院学报(2015年5期)2015-02-28