基于知识图谱共同邻居排序采样的推荐模型
2022-01-04 09:35李世宝张益维刘建航崔学荣张玉成
电子与信息学报 2021年12期
李世宝 张益维* 刘建航 崔学荣 张玉成
①(中国石油大学(华东)海洋与空间信息学院 青岛 266580)
②(中国科学院智能农业机械装备工程实验室 北京 100190)
1 引言
随着云计算、Web开发框架等一系列技术的不断进步,推荐系统广泛应用于在线平台以满足用户的个性化需求从而缓解信息过载带来的影响[1]。传统的推荐模型基于协同过滤算法[2-4],该算法存在冷启动问题,且很难将用户没有浏览过但可能感兴趣的商品推荐给用户。文献[5,6]通过引进用户-项目对,社交网络等辅助信息的方法来解决因数据稀疏造成的冷启动问题。知识图谱作为异构图(heterogenous graph)的一种,图中节点对应实体,边对应实体之间的关系。图谱中实体间丰富的语义关联可以帮助系统挖掘出不同实体之间的潜在关系,合理延伸用户的兴趣,从而提高推荐结果的精度和多样性[7]。
现有融合知识图谱的推荐模型大致可分为3类:基于嵌入的方法[8-11]、基于路径的方法[12-14]和嵌入加路径的混合方法[15,16]。(1)基于嵌入的方法中,为了提高模型的推荐质量,文献[8]依次使用翻译嵌入(Translating Embeddings, TransE)[17]算法、去噪编码器和卷积编码器分别提取项目的图谱结构特征、文本特征和视觉特征,最后将上述3个特征与项目自身偏移量求和作为项目最终的特征;为了增强模型对细粒度用户偏好的建模能力,文献[11]首先利用TransE等图谱嵌入算法将实体与关系映射到低维的特征向量中,然后将关系向量填充到键值对记忆网络(Key-Value Memory Networks,K V-M N)的密钥槽,其次使用循环神经网络(Recurrent Neural Network, RNN)的序列偏好向量作为查询条件读取特定用户的值向量,最后将序列偏好向量与经过编码附带注意力权重的值向量结合作为用户偏好的最终表示。常用的图谱嵌入方法侧重于对严格的语义关系进行建模,因此相较于推荐更适用于图谱补全和链路预测之类的任务场景;(2)基于路径的方法中,为了利用异构信息挖掘用户的高阶兴趣,文献[12]首先引入基于元路径的潜在特征来表示不同类型路径上用户和项目之间的连通性,然后定义全局和个性化两个层次的推荐模块,最后通过贝叶斯优化算法对模型进行训练;针对融合异构信息网络(Heterogeneous Information Network, HIN)的推荐模型无法学习元路径的显式表示以及未考虑元路径与用户-项目对之间的相互作用这两个问题,文献[13]结合元路径的上下文,设计了一种3向神经交互模型:首先基于优先级采样高质量的路径实例,然后使用共同注意力机制改进元路径上下文、用户以及上下文的表示。基于路径的方法在设计有效的基础路径时需要大量的领域知识,因此对于有着不同类型和关系的复杂知识图谱而言设计模板路径需要大量的专业人才,成本过高;(3)为了解决基于嵌入和基于路径两种方法的局限性,文献[7]通过沿着知识图谱中的关系路径迭代地扩展用户的潜在兴趣来刺激用户的偏好在实体集合上传播,最终由用户历史点击项目激活的多个实体集合叠加形成用户的偏好分布,该分布用于预测用户最终的点击概率。嵌入加路径的方法通过端到端的训练可以利用图谱中的高阶信息探索用户的潜在兴趣,克服了前两种方法的局限性。
上述3种方法中基于混合方法的推荐模型效果相对最佳,但是在对图谱中的实体邻居进行采样时,现有模型采用的机制均忽略了图谱中实体之间的邻居关系。为了更好地利用知识图谱中的结构信息,本文在构建知识图谱中每个实体的接收域时基于共同邻居数目对中心实体的邻居实体进行排序采样,提出了基于共同邻居排序的知识图谱卷积网络(Knowledge Graph Convolutional Networks-Public Neighbors sorting, KGCN-PN)模型,该模型首先基于共同邻居数目对知识图谱中的每个实体邻域进行排序采样。然后利用图卷积神经网络沿着图谱中的关系路径将实体自身信息与接收域信息逐层融合。其次将用户特征向量与融合得到的实体特征向量送入预测函数中预测用户与实体项目交互的概率。最后根据概率大小进行Top-K推荐。KGCNPN在MovieLens-20M和Last.FM两个公开的数据集上与最近的基线模型相比,感受性曲线下的面积值(Area Under Curve, AUC)分别获得了1.9%和4.4%的提升。实验结果证明了KGCN-PN的有效性,同时在缺少用户-项目交互数据的冷启动场景中也保持了较强的推荐性能。
2 推荐问题建模

3 KGCN-PN模型架构
3.1 基于共同邻居排序的采样算法(PN)
尽管知识图谱中丰富的实体信息有助于提升推荐效果,但是过多的实体会导致模型在训练过程中因计算存储开销太大而出现无法收敛的情况。为了降低模型的计算存储开销,同时保持每批样本在训练过程中的时间复杂度相同,现有基于知识图谱的推荐模型均通过采样固定大小的邻居实体来不断扩大给定实体的邻域集合,同时将其邻域特征与自身特征合并来计算给定实体的特征表示。另外,知识图谱是由实体间不同的关系作为路径将所有实体相连构成的语义网络。为了挖掘用户潜在的偏好,增强推荐结果的可解释性,模型需要将邻域集合沿着不同的路径扩展至多跳以外来捕捉用户的远距离兴趣。KGCN-PN通过扩展加聚合的方式将实体特征嵌入推荐模型中;同时它可以自动寻找从用户历史到潜在兴趣的可解释路径,期间不需要任何形式的人工设计。为了描述用户在知识图谱上逐层延伸的兴趣偏好,本文使用N(h)={t|(h,r,t)∈G}表示与实体h直接相连的实体集合,采用递归的方式定义项目u在知识图谱上的k跳邻域集合

其中,K为采样大小。由此将式(1)中的N(·)替换为S(·)以获得更为紧凑的项目邻域集合,相应地式(1)中的用户邻域集合也会随之更新。值得注意的是,实体之间的共同邻居数量越多,说明实体之间的联系越紧密,即接收域经过编码得到的实体特征越丰富。然而传统方法在采样时忽略了待采样实体与中心实体之间的邻居关系,本文即根据上述事实提出了基于共同邻居的排序采样算法。
在KGCN-PN模型中,S(e)也称为实体e的单层接收域,图1为灰色实体的两层接收域示意图,其中黑色实体为采样过程中进入接收域的实体,白色实体为被忽略的实体,实体间箭头上的数字为共同邻居数目,为了描述简便,采样大小取3(模型实际训练过程中K值大应随训练集规模调整,4.5.2节给出了KGCN-PN在不同采样大小下的AUC值)。具体采样过程如下:

图1 灰色实体的两层接收域
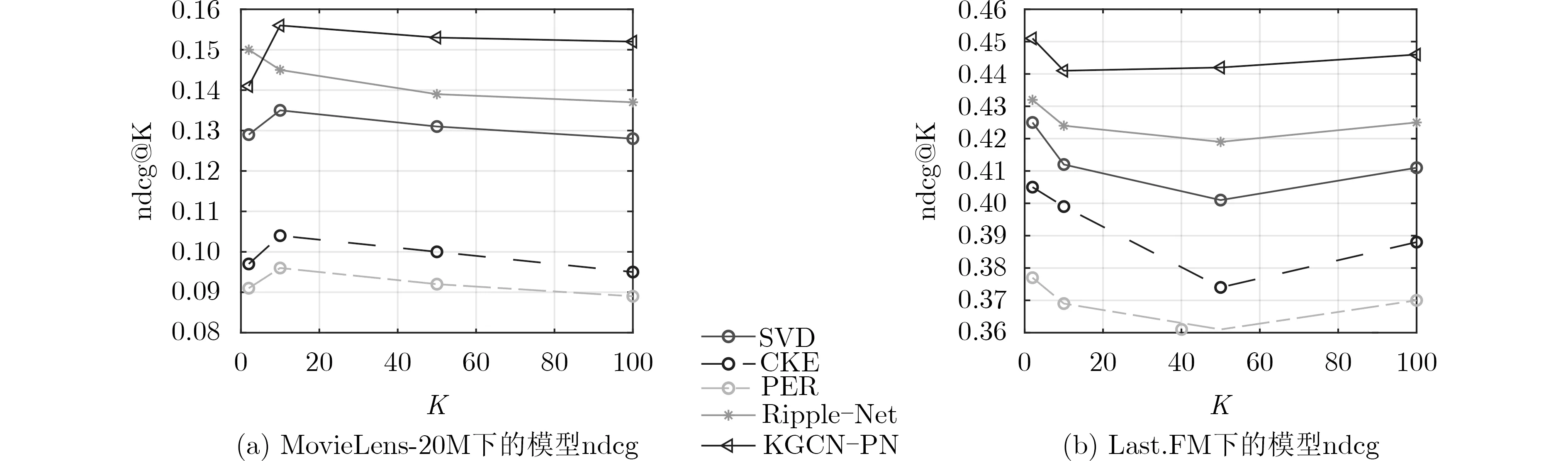
步骤 1 首先查找与中心实体e直接相连的实体集合N(e),并统计N(e)中的实体个数l(e)。比较l(e)与采样值K的大小:如果l(e) 步骤 2 计算中心实体e的邻居列表L(e):遍历集合N(e)取出每个元组内的第1个元素放入L(e)中; 步骤 3 计算共同邻居列表T(e):对L(e)中的每个实体i执行步骤2中的操作得到l(e)个不同的邻居列表,分别与L(e)求交集,将每个交集中的元素个数放入T(e)中 步骤 4 对T(e)中的元素进行归并排序; 步骤 5 取出排序后的序列中后K个元素进行遍历,查找每个元素在T(e)中的索引位置并放入采样列表I(e),遍历结束后删除采样列表中重复的索引,最后在N(e)中查找采样列表中索引对应的实体即可得到中心实体的单层接收域S(e)。 表1中的算法1给出了上述采样流程的伪代码。 表1 基于共同邻居(PN)排序的实体采样算法(算法1) 下面证明本文采样方法的有效性:设实体e单层接收域的总信息量为H(e),代表每个采样实体与中心实体共同邻居的总和;φe(v)表示基于共同邻居排序采样得到的实体v与中心实体e的共同邻居个数;Re(v)表示随机采样得到的实体v与中心实体e的共同邻居个数。则上述两种算法采样得到的接收域信息差为 由分析可知,式(6)只有在两种采样方式采样得到的实体均相同时结果为0,其余情况结果均大于0,换言之基于共同邻居排序采样得到的实体接收域相较于随机采样信息量更大。 在获得知识图谱中每个实体的单层接收域后,本文需要将知识图谱转化为针对特定用户的权重图。现实生活中,不同的用户有着不同的兴趣偏好:针对同一件商品,用户a可能看重商品的外观,用户b更注重商品的质量。本文使用用户-关系评分函数fu(r)来描述关系r对于用户u的重要程度:fu(r)=u×r,其中u和r分别为用户和关系的特征向量。 本文通过计算项目v的邻域线性组合来描述v的邻域拓扑结构 其中,J(yuv,yˆuv)为真实概率和预测概率之间的交叉熵损失,P为负采样分布,Tu是用户u的采样个数,最后一部分是L 2 正则项。本文中Tu=|{v:yuv=1}|,P遵循均匀分布。 图2 KGCN-PN模型架构 表2 图卷积算法(算法2) 算法1 计算项目接收域的时间复杂度为O(n2+nlgn),其中n为输入参数N(e)中实体的个数。算法2的每轮迭代中,每个循环的复杂度依次为Y,L,KL,Kd和d2,其中Y为用户-项目交互次数,L为最大跳数,K为采样大小,d为特征维度,因此算法2中图卷积的时间复杂度为O(Y LKL(Kd+d2))=O(Y LKL+1d+Y LKLd2)。 本节将对KGCN-PN模型在电影和音乐两个推荐场景中的表现进行评估。 MovieLens-20M是电影推荐中广泛使用的基准数据集,由MovieLens网站上约2×107条评价历史构成;Last.FM包含了Last.fm音乐平台上2000多名用户的收听信息。表3列出了两个数据集的统计内容。 表3 实验数据集统计情况 为了验证KGCN-PN模型的效果,本文将与下述的4个基线模型作对比: 协同知识嵌入(Collaborative Knowledge Embedding, CKE)[8]是基于嵌入方法的代表模型,基本思想是将知识图谱作为辅助信息引入模型的同时结合协同过滤方法完成推荐任务。 个性化实体推荐(Personalized Entity Recommendation, PER)[12]是基于路径方法的代表模型,它将知识图谱视为异构的信息网络并从中提取路径特征来表示用户与项目之间的潜在联系。 RippleNet[7]是基于混合方法的代表模型,类似于记忆网络,该模型沿着知识图谱中的关系探索用户的潜在兴趣。 KGCN-PN中,F为内积,最后一层接收域的激活函数σ为tanh,其余层的激活函数为ReLu。每个数据集中训练集、验证集和测试集的比例为6:2:2。本文在以下两个实验场景中评估模型性能:(1)点击率预测场景。本文使用训练好的模型对测试集中每个用户-项目对的交互情况进行预测,评价指标为模型的AUC值。(2)Top-K推荐场景。本文使用训练好的模型为测试集中的每个用户挑选K个预测点击率最高的项目,并选择Recall@K,Precision@K, ndcg@K 3个指标对推荐集分别进行评估。模型的所有训练参数由Adam算法进行优化。 表4与图3-图5分别列出了点击率预测和Top-K推荐的实验结果。从中可以观察到KGCN-PN在音乐数据集上的提升要高于电影,这表明KGCNPN能够有效缓解冷启动问题,因为Last.FM中的数据相比于MovieLens-20M更加稀疏;未引入知识图谱的SVD模型的性能实际上优于引入知识图谱的CKE和PER模型,这说明后两个模型没有充分利用知识图谱中的实体特征和人工设计的路径信息;Ripple-Net相比于其他基线模型有更优的性能,因为它也利用了图谱的多跳邻居结构,这说明捕捉知识图谱中实体的邻域信息对推荐任务有重要意义;KGCN-PN的AUC值相较于基线模型中性能最高的Ripple-Net,在Movie和Music数据集上分别提升了1.9%和4.4%。 图3 Top-K推荐中不同模型的召回率 图5 Top-K推荐中不同模型的ndcg 表4 不同模型在点击率预测场景下的AUC值 如图3所示,在Movie数据集下当推荐的项目数K超过35时,KGCN-PN的召回率开始超过其他基线模型;在数据相对稀疏的Music数据集下KGCN-PN的召回率一直优于其他基线模型。图4中KGCN-PN的精确率在Movie和Music数据集上分别平均超过了Ripple-Net 15.72%和12.37%。图5中KGCN-PN在两个数据集上的ndcg均高于基线模型,同时折线的走势平缓,说明KGCN-PN的鲁棒性和稳定性较强。 图4 Top-K推荐中不同模型的精确率 4.4.1 冷启动场景中的实验结果 推荐系统中引入知识图谱的一个主要目标是缓解数据稀疏问题。本文在验证集与测试集大小固定的情况下,分别使用MovieLens-20M完整训练集的20%~100%5个不同大小的训练集进行训练,图6列出了5种情况下的AUC曲线。当训练集大小为完整训练集的20%时,相较于完整训练集4个基线模型的AUC值分别下降了8.1%, 2.6%, 3.0%和3.9%,KGCN-PN仅下降了1.7%。这表明在用户-项目交互数据稀疏的情况下,KGCN-PN仍能保持良好的预测性能。 图6 模型在不同规模训练集下的AUC曲线 4.4.2 超参数敏感性分析 本文首先分析KGCN-PN对接收域层数L的敏感性:其他参数固定的情况下,依次更改L进行实验,实验结果如表5所示。L取1或2时模型效果最好,取4时效果最差,这是因为计算中心实体的邻域特征时过大的L会引入不必要的实体特征从而导致模型过度平滑。 表5 KGCN-PN在不同接收域层数下的AUC值 本文其次分析了采样大小对模型性能的影响,实验结果如表6所示。起初随着K的增大,模型性能会提升,因为适当的采样大小能够编码更多的用户和实体信息;但是过大的采样数会导致模型过拟合。 表6 KGCN-PN在不同采样大小下的AUC值 本文提出基于知识图谱中共同邻居排序采样的推荐模型。KGCN-PN首先通过共同邻居排序算法获取知识图谱中每个实体的有效邻域,然后使用图卷积神经网络提取实体的邻域特征并结合用户特征进行项目推荐。实验结果表明在电影和音乐推荐场景中,KGCN-PN的性能优于其他基线模型。该模型不仅适用于电影和音乐推荐,也适用于其他构建了相应知识图谱的领域。 本文通过实验发现图卷积层数太深不仅会使模型收敛速度变缓,还会导致实体在训练过程中丢失自身特征,因此在保持GCN层数不变的前提下,如何更有效地学习实体特征将是下一步工作的重点。

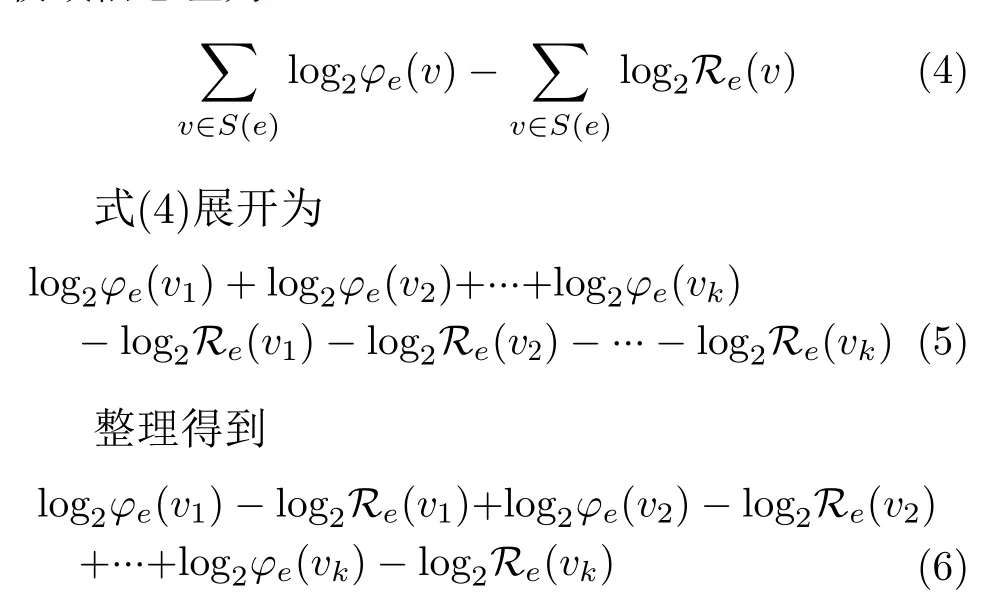
3.2 知识图谱上的图卷积过程(KGCN)




3.3 算法复杂度分析


4 实验分析
4.1 数据集

4.2 测试配置

4.3 实验设置
4.4 实验结果分析






5 结束语
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
少先队活动(2020年12期)2021-01-14
吉林大学学报(理学版)(2020年3期)2020-05-29
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
自动化学报(2018年7期)2018-08-20
中成药(2017年3期)2017-05-17
周口师范学院学报(2016年5期)2016-10-17
领导科学论坛(2016年9期)2016-06-05
华东理工大学学报(自然科学版)(2014年2期)2014-02-27