基于NOMA的移动边缘计算系统公平能效调度算法
2022-01-04 09:43胡晗鲍楠凌章沈乐
电子与信息学报 2021年12期
胡 晗 鲍 楠 凌 章 沈 乐
①(南京邮电大学物联网学院 南京 210003)
②(江苏省无线通信重点实验室 南京 210003)
1 引言
移动通信技术的飞速发展以及移动终端的日益普及,使得网络服务和新型应用不断涌现。然而,移动终端由于自身有限的能量及计算处理能力,难以针对高计算强度、时延敏感性的业务(例如,增强现实,虚拟现实)进行处理[1]。针对上述问题,业界提出了移动边缘计算解决方案[2]。通过在移动网络边缘部署较强的计算和存储资源,用户可以将全部或部分计算任务卸载到移动边缘计算节点,能够有效解决移动设备在资源存储、计算性能及能效等方面的不足,为用户提供低时延、低能耗的网络服务方案。
计算卸载是移动边缘计算研究中的一个重要研究领域[3,4]。其主要包含卸载决策、资源分配两个方面。根据系统的优化目标,目前计算卸载的研究主要集中在以降低时延为目标[5]、以降低能量消耗为目标[6]以及权衡能耗和时延为目标[7]的3种类型。文献[5]研究了多MEC服务场景下的时延最小化问题,提出了一种无需使用业务模型的资源调度方案,和传统算法相比,能够较好地降低通信时延及计算时延的加权和。文献[6]研究了IoT网络中的能效卸载问题,针对网络环境及任务到达的随机性,提出了一种基于Lyapunov的动态卸载方案,假设用户之间采用TDMA接入方式,通过优化各个用户的卸载时间,使得系统能耗最小的同时保证了平均任务队列长度的稳定性。文献[7]研究了多MEC服务器场景下的联合任务卸载和资源分配问题,考虑用户采用OFDMA接入方式,采用一种启发式算法解决了优化问题,上述文献均是采用传统的正交多址接入(Orthogonal Multiple Access,OMA)技术。
非正交多址接入(Non Orthogonal Multiple Access, NOMA)作为一种能够有效解决未来网络频谱资源稀缺的问题,成为当今无线通信中的研究热点技术。与OMA技术相比,NOMA系统可以在同一个信道中同时服务多个用户,可以非常大程度地提高频谱的使用效率,近年来基于NOMA技术的移动边缘计算系统的卸载决策及资源分配问题受到了广泛的关注[8-11]。文献[9]研究了上行NOMA移动边缘计算系统的资源分配问题,考虑相同群组内用户采用NOMA方式,不同群组之间用户采用TDMA方式,将用户的任务计算时延及能耗的线性组合最小化作为优化目标,提出了一种低复杂度的迭代算法,优化了不同群组之间的时间分配隙数,各个群组下每个用户卸载数据量,MEC的计算CPU频率分配以及用户发射功率。文献[10]研究了最大化功率和能耗受限情况下,NOMA-MEC系统中的时延最小化问题。结果表明,NOMA系统与TDMA系统相比,可获得较低的时延。文献[11]研究了MEC系统中的能耗最小化问题。考虑用户计算任务上传和计算结果下载都采用NOMA接入的方式,优化了用户传输功率、传输时间分配及任务分割因子,结果表明,与传统的正交接入相比,NOMA能够有效降低MEC系统中的能耗。
上述绝大多数文献[9-11]考虑最小化能耗或者最小化时延,同时在研究NOMA-MEC系统卸载决策和资源分配时,没有考虑用户之间的公平性,这可能会导致系统资源分配的不均衡,例如,当网络中某些用户处于信道较差状态时,它们的卸载速率相对较低,为了提升系统总体传输效率,系统将会对信道状态好的用户分配更多的传输资源,这样将难以保证信道较差状态下的用户的卸载速率,造成不公平的状况。
本文考虑了MEC系统中的部分卸载模型[4],将任务分成本地计算和卸载计算两部分;并在卸载计算中采用NOMA提升系统频谱效率。将用户速率与功耗比值定义为公平能效函数,分析了两种公平能效调度准则,即最大化最小速率准则及最大化系统能效准则下的网络资源优化问题。由于问题的分式结构和速率约束的非凸性,提出了基于Dinkelbach的连续凸近似算法(Dinkelbach-based Successive Convex Appro-ximation, DK-SCA)及基于Dinkelbach的低复杂度连续凸近似算法(Dinkelbach-based Successive Convex Approximation for Low Complexity, DK-SCALE),对这两种准则下的优化问题进行求解,分别得到用户本地最佳CPU处理频率及最佳传输功率。仿真结果表明,与基于NOMA的完全卸载方案及基于FDMA的部分卸载方案相比,本文所提出的基于NOMA的部分卸载方案,能够在系统处理速率及功耗之间取得一个较好的折中,进而有效提升网络的公平能效性能。
2 系统模型
如图1所示,本文考虑N个用户设备和1个MEC服务器组成的移动边缘计算模型。考虑每个用户设备采用部分卸载模型[4],即将自身的计算任务分成两部分,一部分本地计算,另一部分卸载到MEC服务器上计算。在上行卸载过程中,N个用户均采用NOMA技术以提高频谱效率。用户的本地计算和任务卸载是同时进行的,由于MEC服务器能量充足,本文仅关注用户在任务卸载及本地计算过程中消耗的能效问题。接下来将会给出本地计算和任务卸载的细节信息。

图1 系统模型
2.1 数据卸载
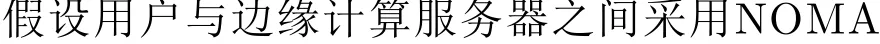

2.2 本地计算

根据DVS技术,本地计算的功耗为处理器速度的函数,可以表示为

其中,ε是处理器芯片的有效电容系数。
2.3 能量效率
能量效率是通信设计中的一个重要指标,特别是在边缘计算用户能源受限的情况下,以能量效率作为系统目标在保障用户服务质量的同时也保障了系统运行的稳定性和长久性。与此同时,由于无线通信链路的不确定性以及各用户任务负载量的动态变化,用户公平性也至关重要,特别是NOMA通信中各用户采用功率控制进行协调传输,在不同的应用场景下会有不同的公平性需求和限制。因此,为了考虑各个用户之间计算速率的公平性,本文采用系统公平能效作为性能指标,将其定义为用户计算速率公平效用函数[12-15]与用户总消耗功率的比值,具体公式为

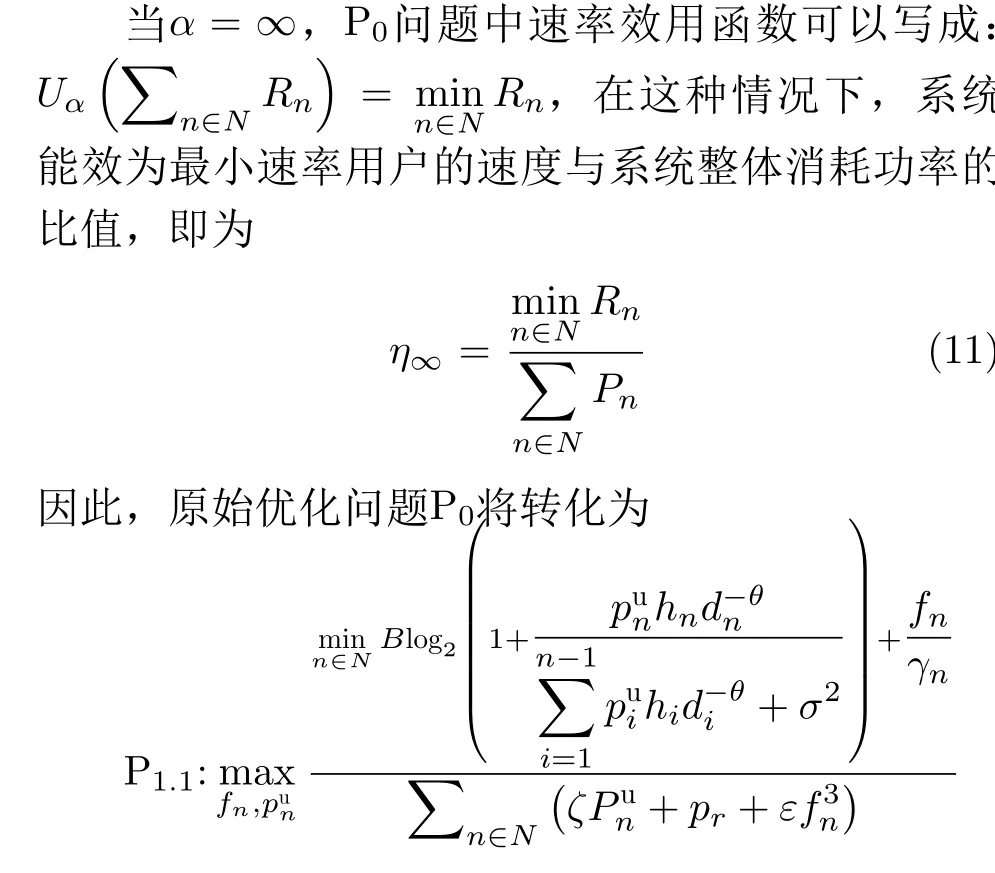
其中,α是公平指数。在实际应用中,根据不同的场景需求,需要选择不同的α值以保障用户的公平性[12-15]。本文考虑两种特殊场景,一种是当α=∞时,式(6)效用函数转换为所有用户中最小速率,系统旨在保障最小速率用户的公平性,系统能效即为最小速率用户的速度与系统所消耗功率的比值。另一种是当α=0时,式(6)效用函数转换为用户和速率,此时系统旨在保障用户的总体性能,系统能效为所有用户速率之和与所有用户消耗功率的比值。具体论证过程详见文献[13]中第3部分的引理3,该结论已广泛应用于文献[12,14,15]。接下来,我们将分别针对这两种场景,通过优化用户计算处理频率以及发射功率,以最大化最小速率用户的系统能效(α=∞)及最大系统总体能效(α= 0)这两种情况。
3 问题形成
本文旨在通过优化用户传输功率和本地计算频率来最大化系统的公平性能效,进而形成系统资源分配优化问题为
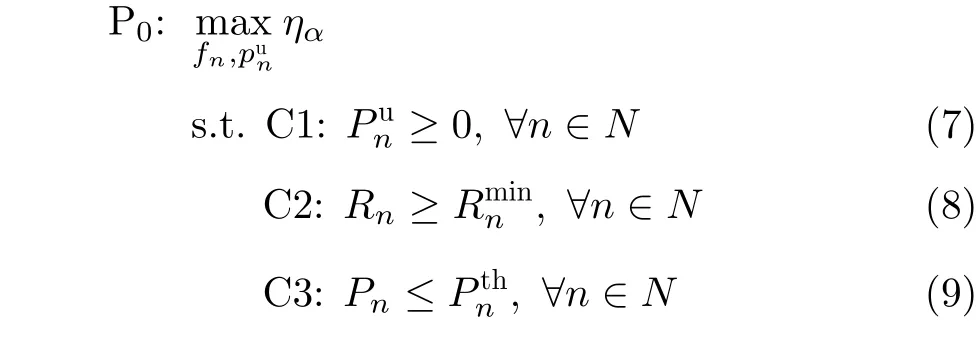

4 算法设计
4.1 最大化最小速率用户系统能效(α = ∞)
s.t. 式(7)-式(10)



其中,式(15)左侧第1项是一个凸函数,第2项是log-sum-exp形式,也是一个凸函数,因此其为凸约束,式(14)是一个指数函数大于线性函数,因此其非凸,为解决此问题,本文采用SCA方法将其转换为凸问题形式 ,SCA的思想是通过引入辅助变量将原表达式的非凸部分采用1阶泰勒公式近似,并连续不断更新辅助变量直到收敛至要求精度,进而给出次优解。根据 SCA,则有

s.t.式(7),式(9),式(10),式(12),式(15),式(16)P1.3所有约束条件均为凸约束,而其目标函数的分式结构为一个线性函数比凸函数的形式,这种形式满足Dinkelbach方案要求的单调性条件,因此,可以采用Dinkelbach方案将其转换成等价的形式,该方案通过设定一个初始值,并经过多次迭代更新的方法不断逼近最优解[16]。根据交替迭代算法的思想,原始的目标函数可以转换为



表1 DK-SCA迭代算法
4.2 最大系统总体能效(α = 0)


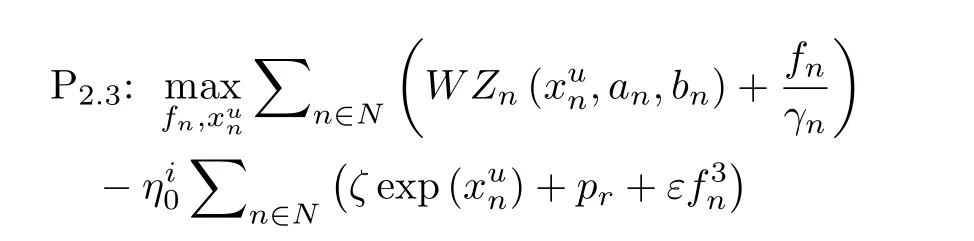
s.t. 式(7),式(10),式(26),式(27)P2.3的目标函数是最大化凹函数,约束条件均为凸约束,因此转化为一个标准的凸优化问题。可以采用凸优化工具进行求解,求解过程如表2所示。

表2 DK-SCALE迭代算法
5 性能评估
在本节中,我们在MATLAB2018a平台下进行了实验仿真,通过仿真结果来分析验证所提方法的性能。仿真参数设置参考文献[17]。假设用户服从[0,1000]×[0,1000]区域上的泊松分布,瑞利衰落因子hn服从均值为1的指数分布,路径衰落指数θ= 4。系统带宽为W=3×106Hz,干扰σ2= 10−7,用户总数为N=3,每个用户的任务计算强度为γn= 103cycle/bit。计算能量效率系数ε=10−28,放大器系数ζ=2。每个用户设备的最大和最小计算能力均等设置,即fnmax=109Hz,fnmin=106Hz时,电路功率pr为5 dBm。仿真结果中,本文所提出的两种公平性准则下基于NOMA部分卸载方案均标记为NOMA+partial offloading。另外,本文采用两种基准对比方案:基准方案1为基于FDMA部分计算卸载方案,在图中标记为FDMA+partial offloading;基准方案2为基于NOMA的完全任务卸载方案,在图中标记为NOMA+complete offloading。
图2-图4分别给出了当α=∞时,最大化最小速率准则下3种方案下的系统能效、处理速率和功耗的对比情况。系统能效与系统速率下限约束的关系如图2所示,可以看出,本文所提出的方案能取得比两个参考方案更好的能效性能。值得注意的是,3种方案在速率下限比较小的时候,均保持高水平,但是随着速率下限逐渐增加,各方案均出现了下降的趋势。这是因为在要求速率较小时,基于能效的方案可以将处理速度维持在最佳能效处,而当系统要求的速率下限逐渐增大时,最佳能效处的速率无法达到要求,于是各方案不得不增加任务处理的速率,从而导致功耗的升高,能效的下降。需要说明的是,由于NOMA带来的卸载增益,两种基于NOMA的方案取得的能效均远高于传统的FDMA方案。相比较NOMA完全卸载的方案,本文提出的方案在可以在本地处理和卸载间进行动态调整,因而能够取得更好的能效表现。综上所述,本文所提出的方案,可以帮助系统提升公平性能效。
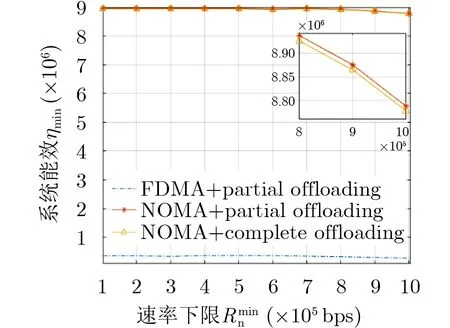
图2 最大化最小速率准则下3种方案系统能效对比分析
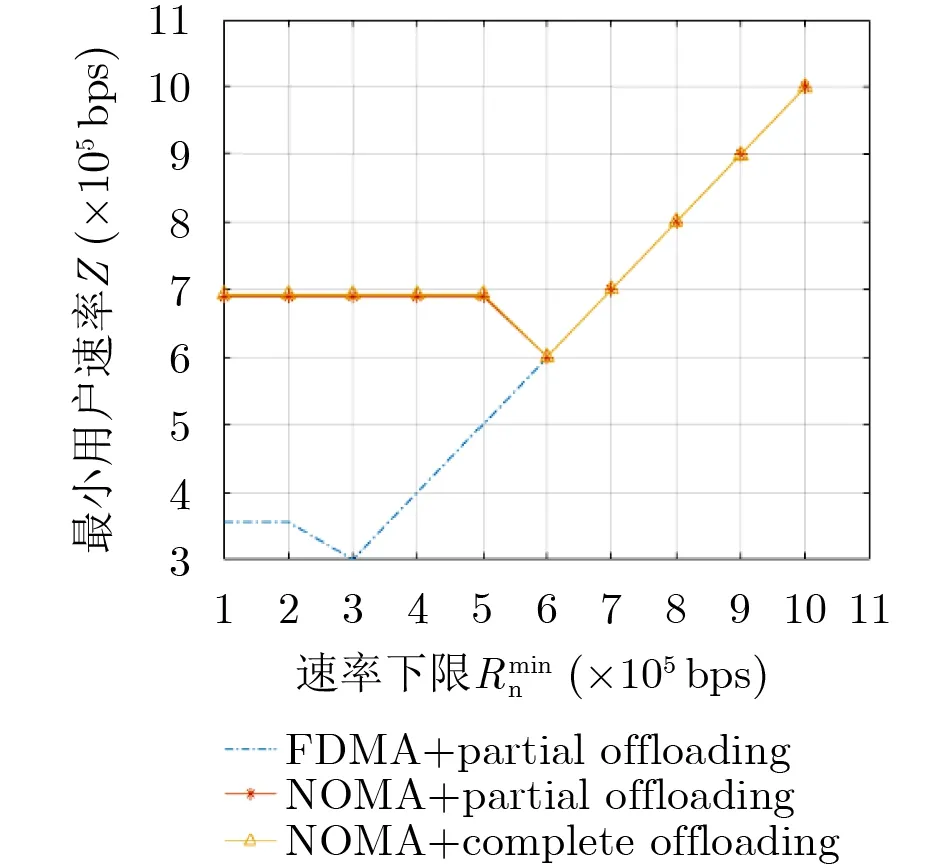
图3 最大化最小速率准则下3种方案下系统速率对比分析
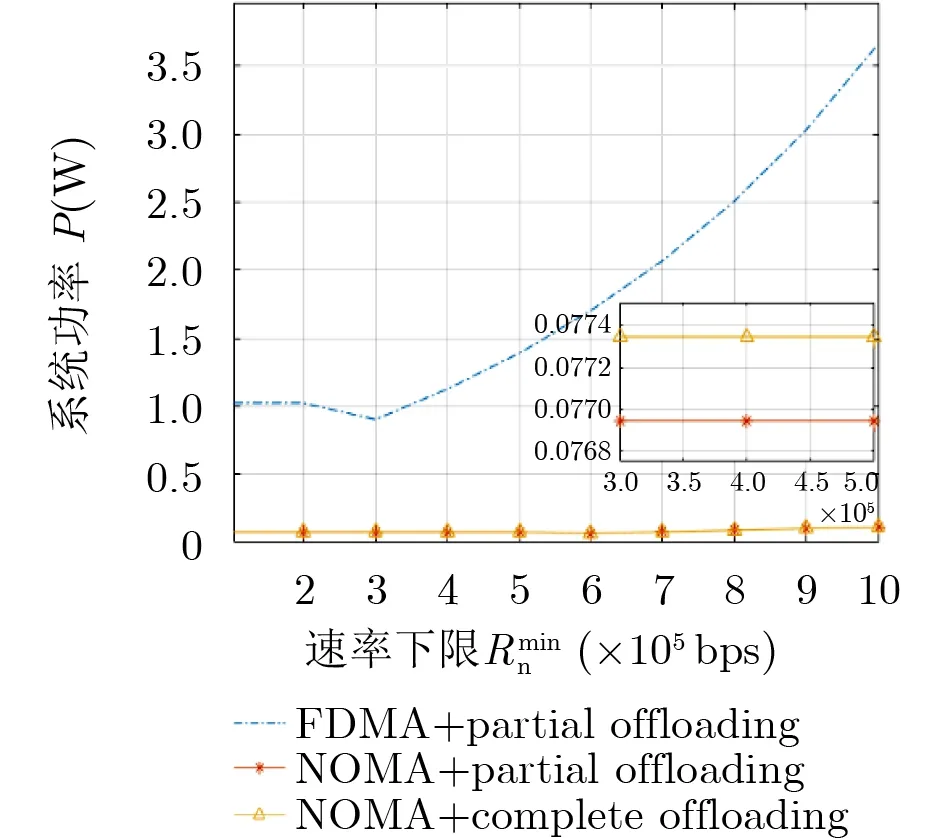
图4 最大化最小速率准则下3种方案的系统功耗对比分析
最大化最小速率准则下用户最小速率与系统速率下限的关系如图3所示,可以看出,各方案的系统最小速率在速度下限较小时保持在一个稳定的值,随着速率下限增大到一定程度,各方案的速率随速率下限要求进行线性增长。这与图2中观察到的结果相同,进一步说明了能效方案可以在速率和功耗间进行折中,同样,基于NOMA方案性能优于FDMA的方案。
最大化最小速率准则下系统功率与系统速率下限的关系如图4所示,其中基于FDMA部分卸载的方案功率远高于两种基于NOMA的方案,结合图2和图3的曲线趋势,可以看出,在速率下限小于6×105时,即使FDMA的方案消耗了更多的功率,其所能达到的速率远低于NOMA方案的速率,而当3种方案取得同样速率的时候,FDMA消耗的功率最高,能效最差。本文提出的方案所消耗的功耗是最低的,而取得的速率和其他两种方案相同,因此能效最好。综上,本文提出的方案能够取得最大化最小速率公平性场景中的最优能效。
图5-图7分别给出了当α= 0时,最大化系统能效准则下3种方案的对比情况。系统能效和速率下限的关系图如图5所示。从图中可以看出,随着速率下限的增加,基于FDMA部分卸载方案和本文提出的方案的能效均逐渐下降,而基于NOMA完全卸载方案维持在一个相对较稳定的范围,这是因为两种结合本地计算的方案会被速率下限迫使提升处理速率,进而导致功耗的增加,能效的降低。而基于NOMA完全卸载方案,由于维持在一个更高的速率,因此能效相对稳定,但是其能效是3种方案最差的。通过对比3种方案可以看出,本文所提方案能够取得最佳的能效。

图5 最大化系统能效准则下3种方案系统能效对比分析

图7 最大化系统能效准则下3种方案的系统功耗对比分析
图6给出最大化系统总体能效准则下3种方案总体速率和速率下限的对比关系。从图中可以看出,基于NOMA完全卸载方案的总体速率远高于其他两种方案,而基于NOMA部分卸载方案的方案次之,基于FDMA部分卸载方案的速率最小,这是因为有本地计算辅助的方案可以弥补纯卸载方案中信道差异带来的影响,所以系统能够更有效地进行功耗和处理速率间均衡分配,可以在满足最小速率下限的同时,将系统总体速率和能耗维持在一个更好的折中。同时,虽然基于NOMA部分卸载方案总体速率低于基于NOMA的完全卸载方案,但是其能效远高于其他方案,说明所提出的方案在保障速率要求的同时,能够更合理地进行功耗分配。
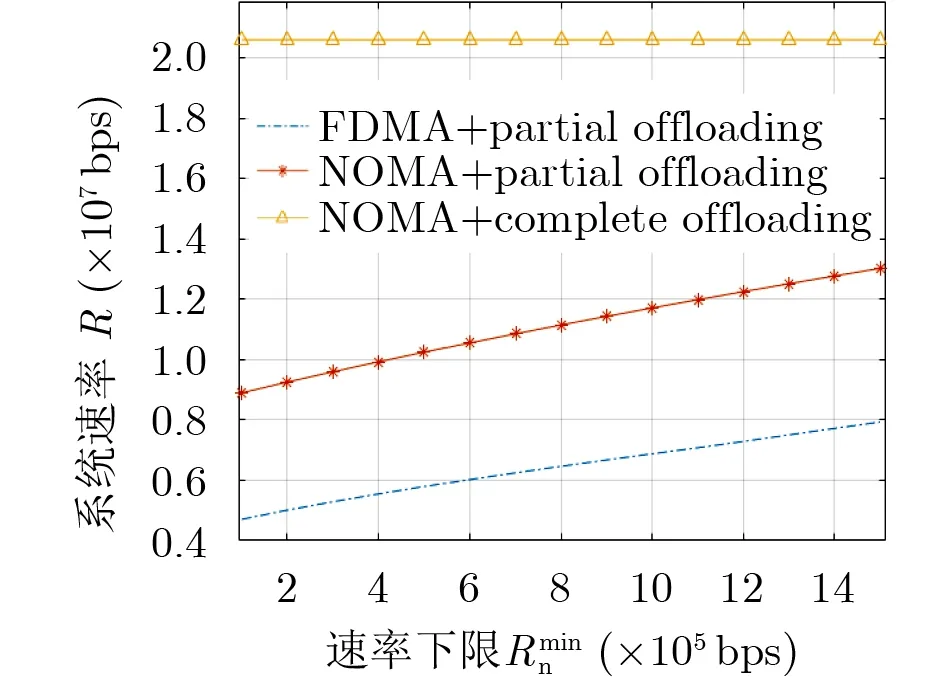
图6 最大化系统能效准则下3种方案的系统速率对比分析
最大化系统能效准则下系统功耗与最小速率的关系如图7所示,与图5、图6趋势相同,本文所提出的方案功耗最低,并且相比其他两种方案,本文的方案仅通过消耗极低功率就能取得较高的数据处理速率,满足最小速率要求和服务质量的同时,还保障了最佳的能效,因而能够取得最佳的速率与功耗的折中。
6 结束语
本文从用户公平能效的角度,针对采用NOMA多址技术的上行部分卸载MEC系统方案,提出了两种公平性能效的调度算法:最大化最小速率准则下的DK-SCA算法,及最大化系统总体能效准则下DK-SCALE算法。通过仿真表明,本文所提出方案能够有效地将本地计算和基于NOMA的边缘卸载结合,达到最佳的公平能效表现。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
南开管理评论(2021年1期)2021-04-13
当代陕西(2021年1期)2021-02-01
考试与评价·高二版(2020年3期)2020-09-10
华人时刊(2019年15期)2019-11-26
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
中国卫生(2015年3期)2015-11-19
中国卫生(2015年8期)2015-11-12
电源技术(2015年11期)2015-08-22