
基于BERT的多特征融合的医疗命名实体识别
2021-12-30 01:15李正民云红艳王翊臻
青岛大学学报(自然科学版) 2021年4期
李正民 云红艳 王翊臻

摘要:
针对传统字向量难以表达上下文语义以及抽取的特征较为单一等问题,提出基于BERT的多特征融合模型BERT-BiLSTM-IDCNN-Attention-CRF,通过BERT建模字向量的上下文语义关系,并融合双向长短期记忆网络(BiLSTM)和迭代膨胀卷积 (IDCNN),分别抽取的上下文特征和局部特征,使两种特征进行互补以提升实体抽取效果。本模型在全国知识图谱与语义计算大会CCKS2020中文电子病历数据集上进行测试,与BiLSTM-CRF等基准模型进行比较,F1值提升127%。实验结果表明,本模型能较好地识别电子病历中的医疗实体。
关键词:
命名实体识别,多特征融合,BERT,BiLSTM,IDCNN
中图分类号:TP391
文献标志码:A
收稿日期:2021-05-19
基金项目:
国家重点研发计划 (批准号:2016YFB1001103)资助。
通信作者:云红艳,女,博士,教授,主要研究方向为语义Web与本体工程、智能信息系统、大数据集成。E-mail:yunhy2001@163.com
电子病历用于患者临床治疗过程中,以电子化方式记录患者就诊时的病情变化及诊疗过程,是临床科学诊断治疗的基础材料[1]。电子病历包含了丰富的医疗实体,通过使用医疗命名实体识别技术(Medical Named Entity Recognition,MNER)从电子病历中挖掘出各类医疗实体,可用于建立医疗知识图谱,增强数据的可用性、可理解性与可见性[2]。命名实体识别技术从早期的基于规则和词典的方法逐渐向机器学习和深度学习过渡,近年来由于神经网络具有强大的特征提取能力,因此成为命名实体识别中的主流方法。Liu等[3]通过实验对比了深度学习算法BiLSTM-CRF与机器学习算法CRF识别实体的性能,证明了深度学习算法更为有效。Yang等[4]基于BiLSTM-CRF訓练实体识别模型,从入院记录和出院小结中有效的抽取医学实体。Chiu[5]使用BiLSTM和CNN混合结构获取词级和字符级特征,进一步提升了模型识别性能。Strubell等[6]将空洞卷积IDCNN应用于命名实体识别中,大大缩减了模型的训练时间。近年来,注意力机制在自然语言处理领域得到了广泛的应用。Yin[7]等利用CNN提取汉字字符间特征信息,利用自注意力机制捕获字符之间的依赖关系特征来识别医学电子病历中相关实体。以上传统方法未能充分利用不同粒度特征在实体识别方面的优势,且电子病历命名实体识别面临训练语料不足、标注质量不高以及传统静态字向量在表征字的语义方面的不足等限制了模型的学习能力。针对以上问题,本文使用微调的BERT提取动态字向量并拼接词性等特征嵌入共同作为嵌入层的输出;在特征提取层分别使用BiLSTM和IDCNN提取上下文依赖特征与局部特征;最后将抽取的两类特征动态融合后经CRF解码层获取全局最优标签序列。该模型融合了两类不同粒度特征,有效提升了模型识别准确率。
1 数据
1.1 数据来源
采用的数据集是CCKS2020中文电子病历数据集,数据集共标注了“疾病和诊断” “解剖部位” “实验室检验” “影像检查” “手术” “药物”等六种实体类型,共包括1 050条标记数据。
1.2 数据预处理
数据集由专业人士手工标注完成,并且其中存在大量标注不统一、漏标以及标注错误等问题。因此,本文对数据集的标注做了预处理,并对上述标注采用手工的方式进行纠正。另外,统一数据集中字母大小写与中英文标点符号等;在保证语义相对完整的前提下,对句子进行切分,设定每个句子长度最长为202,最短为20。数据预处理后,训练集与测试集中实体类型与实体数量见表1。
1.3 实体标注
命名实体识别可看作是序列标注问题,需要将原始标注语料处理成序列标注形式。本文使用BIOES标注方案将数据集给出的标签映射到每一个字符上,进行字符级别的标记[8]。其中B,I,E分别表示实体开始、中间和结束,O表示非实体,S表示单字符实体。数据标注格式示例见表2。
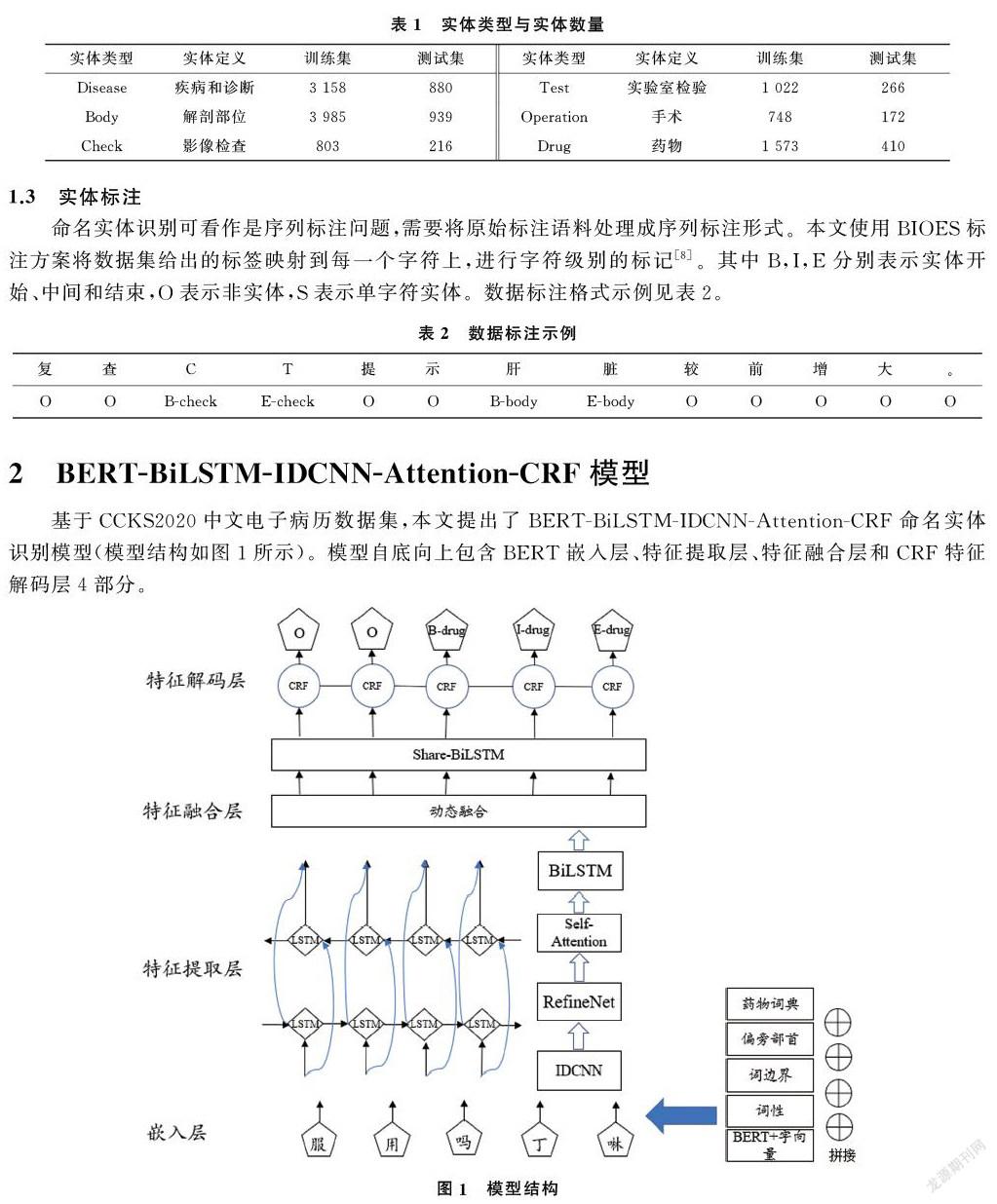
2 BERT-BiLSTM-IDCNN-Attention-CRF模型
基于CCKS2020中文电子病历数据集,本文提出了BERT-BiLSTM-IDCNN-Attention-CRF命名实体识别模型(模型结构如图1所示)。模型自底向上包含BERT嵌入层、特征提取层、特征融合层和CRF特征解码层4部分。
2.1 嵌入层
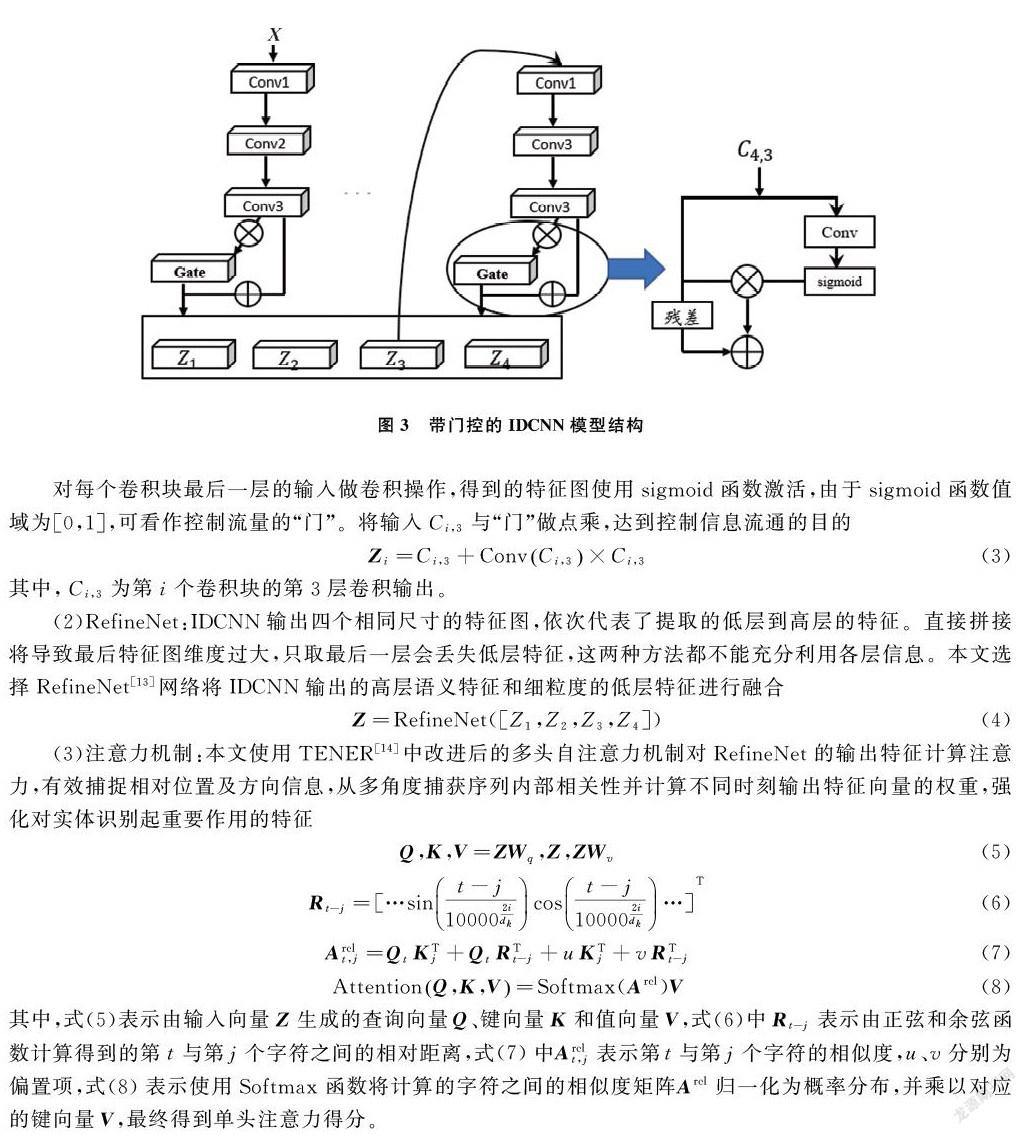
2.1.1 BERT字向量嵌入 将文本数据送入模型之前需将文本数据进行向量化表示,传统的文本表示模型存在表征静态、表征能力不足以及缺乏领域性特征等问题,而BERT[9]模型很好的解决了此类问题。首先经过预训练后的BERT不仅可以从大量无标签的非结构化文本中学习丰富的先验语义知识,同时通过多层的transformer对输入序列的每个单词建模上下文语义知识,使得同一个单词在不同的上下文中得到不同的词向量表示。其次对预训练模型使用领域数据集进行微调,使得模型融入领域知识,适应领域任务需求。
本文选择在预训练模型RoBERTa[10]基础上对其参数进行微调,得到微调后的RoBERTa-FT模型。然后固定该模型参数,BERT只作为字向量的特征生成器,将输入的文本序列转化为字向量序列[11],在此基础上拼接字嵌入embedding作为BERT生成字向量部分不进行训练的补充。
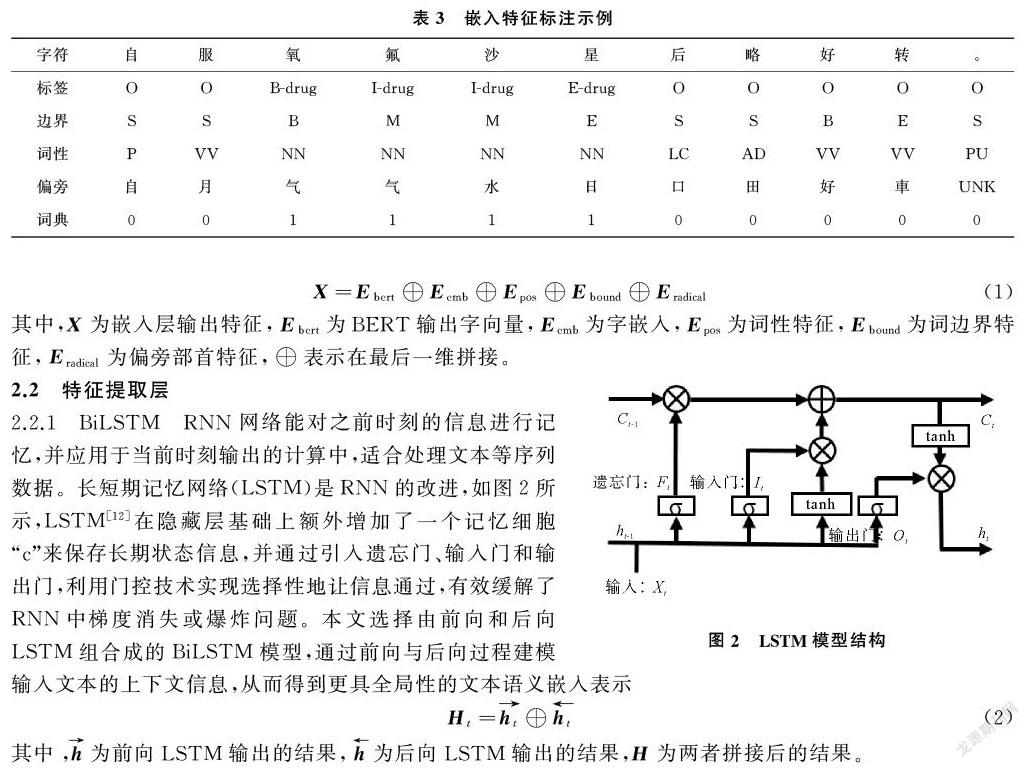
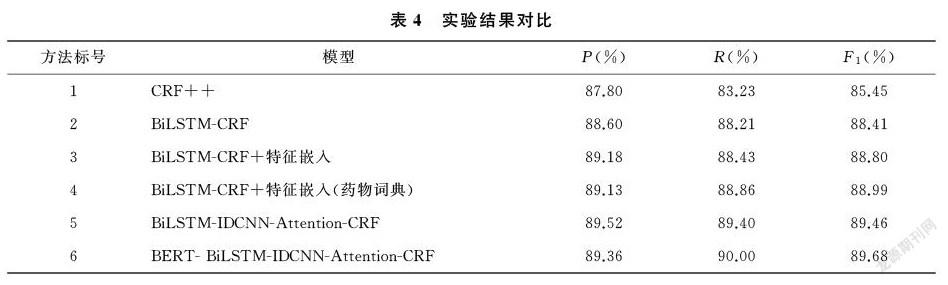
2.1.2 特征嵌入 在电子病历文本中,命名实体如“解剖部位”“疾病与诊断”“药物”中多为名词词性,而“影像检查”“手术”实体前通常会有动词“行”来表示这一动作的发生。因此词性与命名实体有着较强关联关系。本文使用fastHan工具(https://github.com/fastnlp/fastHan/)提取文本的词性特征与词边界特征,同时提取了偏旁部首特征作为补充信息,由于繁体部首相比简体部首在字形字构上更具解释性,且数量更少,实验中将构建繁体部首映射表,获取每一个字的繁体部首特征。
為提高特定实体的识别准确率,制作了药物词典特征辅助模型的识别。从搜狗词库(https://pinyin.sogou.com/dict/)下载药物词典后去除非药物名称后得到相对干净的药物词典,再加入训练集中所有药物实体。使用双向最大匹配算法,从测试集中匹配出在词典中出现的实体并标注,匹配到的标记为1,剩下的标记为0,从而构建药物词典特征。嵌入特征的标注示例如表3所示。
4 结论
本文通过使用BERT作为嵌入层生成蕴含丰富语义信息的动态字向量,针对单一BiLSTM缺乏局部特征提取能力,使用IDCNN提取文本的局部特征并将抽取到的多层特征经RefineNet整合,充分利用了抽取到的各层信息;然后将整合后的特征使用注意力机制增强对实体识别起重要作用的特征,提升模型识别性能。最后将抽取的两类特征使用动态融合方法后送入CRF解码层得到最优的标签序列。通过测试CCKS2020医疗电子病历数据集,结果表明,基于BERT的多特征融合模型对医疗命名实体识别有明显提升。
参考文献
[1]黄建英.电子病案管理发展现状趋势[J].医学综述,2009,15(13):2078-2080.
[2]林莉,云红艳,贺英,等.基于企业知识图谱构建的可视化研究[J].青岛大学学报(自然科学版),2019,32(1):55-60.
[3]LIU Z J, YANG M, WANG X L, et al. Entity recognition from clinical texts via recurrent neural network[J]. BMC Medical Informatics and Decision Making, 2017,17(2):53-61.
[4]YANG H M, LI L, YANG R D, et al. Named entity recognition based on bidirectional long short-term memory combined with case report form[J]. Chinese Journal of Tissue Engineering Research, 2018,22(20):3237-3242.
[5]CHIU J P C, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs[DB/OL]. [2021-05-05]. https://arxiv.org/abs/1511.08308.
[6]STRUBELL E, VERGA P, BELANGER D, et al.Fast and accurate entity recognition with iterated dilated convolutions[DB/OL]. [2021-04-30]. https://arxiv.org/abs/1702.02098.
[7]YIN M W, MOU C J, XIONG K N, et al. Chinese clinical named entity recognition with radical-level feature and self-attention mechanism[J]. Journal of Biomedical Informatics, 2019, 98:103289.
[8]LIU Z J, CHEN Y X, TANG B Z, et al. Automatic de-identification of electronic medical records using token-level and character-level conditional random fields-ScienceDirect[J]. Journal of Biomedical Informatics, 2015, 58:S47-S52.
[9]DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[DB/OL]. [2021-04-30]. https:// arxiv.org/pdf/1810.04805. pdf&usg= ALkJrhhzxlCL6yTht2BRmH9atgvKFxHsxQ.
[10] LIU Y H, OTT M, GOYAL N, et al. Roberta: A robustly optimized bert pretraining approach[DB/OL]. [2021-05-02]. https://arxiv.org/pdf/1907.11692.pdf.
[11] JAWAHAR G, SAGOT B, SEDDAH D. What does BERT learn about the structure of language?[C]//ACL 2019 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[12] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
[13] LIN G S, LIU F Y, MILAN A, et al. RefineNet: Multi-path refinement networks for dense prediction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 42(5): 1228-1242.
[14] YAN H, DENG B, LI X, et al. Tener: Adapting transformer encoder for named entityrecognition[DB/OL]. [2021-04-30]. https://arxiv.org/pdf/1911.04474.pdf.
Abstract:
In order to solve the problems that traditional word vectors were difficult to express the context semantics and extract multiple features, a multi feature fusion model named BERT-BiLSTM-IDCNN-Attention-CRF was proposed, which used BERT to model the context semantic relationship of word vectors and fused the context features and local features extracted by BiLSTM and IDCNN respectively. The model was tested on CCKS2020 Chinese EMR dataset, and compared with the baseline models such as BiLSTM-CRF, the F1 value is increased by 127%. The experimental results show that the proposed model can better identify the medical entities in EMR.
Keywords:
named entity recognition; multi feature fusion; BERT; BiLSTM; IDCNN
猜你喜欢
东疆学刊(2022年2期)2022-04-22
科学家(2022年3期)2022-04-11
作文评点报·低幼版(2020年25期)2020-07-23
东方女性(2018年3期)2018-04-16
中国社区医师(2016年8期)2016-12-20
学习与研究(2013年3期)2013-05-13
科技新时代·e医疗(2011年8期)2011-12-23
意林(2010年4期)2010-05-14
杂文选刊·中旬刊(2009年6期)2009-08-11
