
基于多任务学习和知识图谱的面部表情识别
2021-12-30 11:33:16张水平王海晖陈言璞
武汉工程大学学报 2021年6期
陈 龙,张水平*,王海晖,陈言璞
1.武汉工程大学计算机科学与工程学院,湖北 武汉430205;2.智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉430205
面部表情因其能真实呈现并传递信息,成为人们日常生活的主要沟通方式之一,心理学家莫翰彬研究表示,通过语言人类只传递45%的信息,包括语气、语调、口音等其他附加条件,其余55%的信息则通过面部表情的不同形态加以呈现。所以及时地分析发言者的表情变化,可以使听者揣摩发言者心理状态,推测发言者的情绪,进而推断发言者动机。通俗而言,面部表情识别是借助计算机将人类思维智能化,便于促进人与人的群体交互,呈现研究对象情感的不同形态,使研究者借助面部表情的不同形态预测研究对象的情绪和意图。如何让机器读懂人的脸部表情,改变单一的键盘输入或者语音输入的输入方式,能够使机器越来越智能化,满足人类在人机交互中的更高需求,提高人机交互的舒适度,提高机器服务的质量,是当前我们研究的重要问题[1]。
近年来,面部表情识别的研究和应用领域拓宽,是计算机视觉、人机交互、图像识别等领域的重点研究课题。传统的图像特征提取方法,有局部二元模式[2-3](local binary pattern,LBP)、Gabor小 波 结 合 梯 度 直 方 图 变 换[4-5](histogram of oriented gradient,HOG)、主 成 分 分 析 法[6](principal component analysis,PCA)、基于模型的方法[7]等,而传统的方法由于存在计算量大、鲁棒性不足等问题,在应用落地中比较困难。因此,基于数据驱动的面部表情识别收获了较多关注度[8]。2004年,Ahonen等[9]使用的LBP算法被用于面部识别领域,以获得更高效的特征提取。在识别分类的任务方面,采用迭代算法(adaboost)和支持向量机(SVM)等[10],这些都是人为设计的一些特征提取方法,大都损失了原有图像中的一些特征信息,实际检测的精度受到了很大影响;Li等[11]是通过改变不同的数据集来提高人脸表情识别分类任务的准确率,使用EM算法用来过滤不可靠的标签。徐琳琳等[12]提出一种并行卷积神经网络来缩短网络的训练时间,获得了65.6%的精度,这个并行结构具有3个不同通道,分别提取不同图像特征进行融合和分类,主要应用于处理在数量、分辨率、大小等差异较大的表情数据集,并得到高准确率和缩短时间。虽然数据驱动的方法为人脸面部表情识别问题带来了很大的性能提升,但是对数据大规模采集与标注提出了很高要求,随着所用数据模型复杂度增大,关注的问题就转移到了性能的提升。胡步发等[13]在面部表情识别任务中引入高层语义信息,从而提高了面部表情的识别率。朱瑞等[14]利用深度学习和知识图谱的相结合在推荐领域受到广泛关注。深度学习与知识图谱技术的结合可以同时发挥数据驱动与知识推理的功能,进而提高模型的泛化能力。
基于当前面部表情识别的关注问题,为进一步提高模型的准确率与鲁棒性,本文提出一种基于多任务学习和知识图谱的面部表情识别方法(multi-task learning algorithm model,MLAM),该方法通过分别构建基于数据的预测模型和基于知识的图谱推理机制,将二者进行耦合,进而实习多任务学习的目标。根据不同人的情绪表征,不同种族、性别、年龄、工作的人在表达情绪时面部表情都有某种隐藏特征(局部表情),本文提出多任务学习和知识图谱的面部表情识别方法。比如,东方人和西方人在表情上就会有很大的差异,西方人更偏爱用夸张的表情表达出喜怒哀乐,而传统的深度学习方法未考虑个体的差异,所以本文引进了知识图谱运用到深度学习的技术当中。
目前的深度学习框架已经可以完成端到端实体之间的识别、关系抽取、关系融合、关系补全等任务,创建知识图谱。本文提出的方法可以基于知识图谱建立起情绪表征与个体的联系,进而提高人脸情绪识别的性能。
1 基于多任务学习和知识图谱的面部表情识别
由于传统面部识别算法的局限性,人为干扰因素较大,算法的鲁棒性和识别精度都有待提高。本文提出MLAM算法,该算法是一个端对端的通用深度识别框架,该框架完成人脸表情识别的主体任务。同时引入知识图谱嵌入任务作为辅助识别任务,知识图谱将人脸识别中非常重要的情绪因素以知识的形式进行存储,并用于提高深度学习的预测准确率。知识图谱和图像识别这两个子任务虽然是独立训练与工作的,但是本文设计了一种交叉压缩单元将两个模块进行耦合,进而实现在识别算法中的局部表情(item)与知识图谱中单个或者多个实体(entity)之间的关联。
将推荐算法中的用户(user)与物品(item)创新性引入人脸识别领域,分别用于表示待识别对象(个体)与局部表情,并采用知识图谱构建二者之间的关系。知识图谱的引入为人脸识别提供了一个知识库,不仅可以建立起个体与个体之间的关系,而且可以表征个体与局部表情之间的关系,帮助人脸识别预测模型更好地完成任务。为了对局部表情和个体之间的共享特征进行建模,本文MLAM算法提出了交叉压缩单元(cross&compression unit),可以建立局部表情(item)和个体(entity)特征之间的高阶交互,并自动控制两个任务的交叉知识转移。使用交叉压缩单元后,局部表情(item)和个体(entity)的表征可以相互补充,避免两个任务产生过拟合和噪声,并提高泛化能力。MLAM算法的工作原理介绍如下。
1.1 模型框架
MLAM模型框架如图1所示,主要包括3个模块:识别模块、知识图谱嵌入模块与交叉压缩单元,其中左侧为识别任务,右侧是知识图谱特征学习任务。算法整体框架通过交替优化两个任务的不同频率进行训练,以提高MLAM算法在真实环境中的灵活性和适应性。

图1 MLAM识别算法框架Fig.1 Framework of MLAM recognition algorithm
1.2 识别模块
识别模块的输入为表情识别者向量U与情绪表征向量V,输出为表情识别者对于情绪表征的情绪表征率Y,模块分为low-level和high-level两部分,其中low-level部分使用多层感知器(multi-lay perceptron,MLP)处理表情识别者的特征U L,情绪表征部分使用交叉压缩单元来进行处理,返回一门情绪表征的特征Y L,最后将U L与V L拼接,通过识别算法中的函数fRS,输出情绪表征预测值[15-16]。对于给定表情识别者的初始特征向量U,使用L阶的MLP提取其特征:
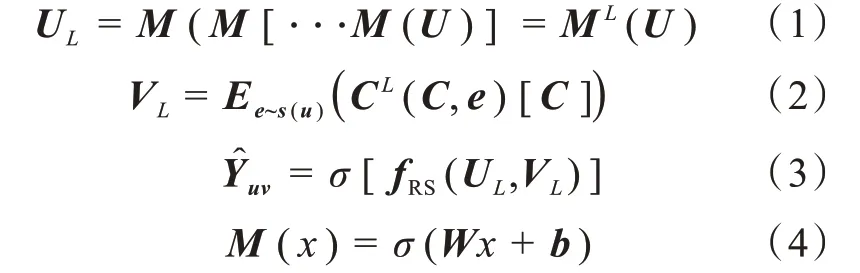
其中的M(x)=σ(W x+b)为全连接神经网络层,权重为W,偏置为b以及非线性激活函数σ(·),在情绪表征V中使用L阶交叉压缩单元提取特征。
1.3 知识图谱嵌入模块
知识图谱嵌入模块[17]就是将三元组的头部和关系嵌入到一个向量空间中,同时保留结构,对于知识图谱嵌入模型,现有的研究提出了一个深度语义匹配架构,与识别模块类似,根据给定知识图谱G以及实体-关系-实体三元组(h,r,t),其中分别通过交叉压缩单元与非线性层处理三元组头部h和关系r的初始特征向量。之后将潜在特征关联在一起,最后用K阶MLP预测尾部t:
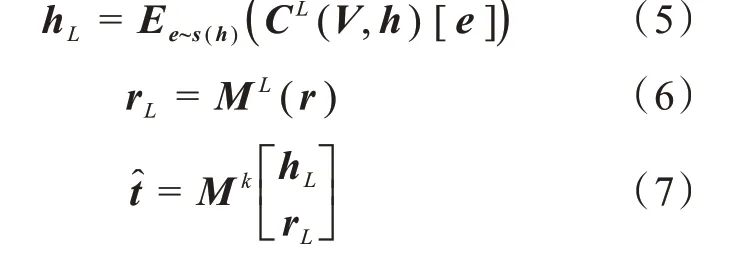
其中S(h)为h的关联项集合̂为根据尾部t得出的预测向量。
1.4 交叉压缩单元
交叉压缩单元[18]是为了模拟局部表情(item)和实体(entity)之间的特征交互,其只存在于MLKR算法的初始阶层中,由于面部识别算法中的情绪表征(item)和知识图谱嵌入模块中的实体(entity)有对应关系,并且有着对同一情绪表征(item)的描述,其中embedding相似度极高,即可以被连接,于是中间每一层都使用交叉压缩单元作为连接的结合。如图2所示,L层的输入为情绪表征item的embeddingV L和实体的embeddinge L,下一层的输出为embedding,交叉压缩单元模块分为两部分:交叉特征矩阵(cross)和压缩层(compress),其中交叉特征矩阵(cross)将V L,e L进行一次交叉,V L为d×1的向量,e L为1×d的向量,矩阵计算后获得d×d的矩阵C L。压缩层(compress)将交叉后的矩阵C L重新压缩回embedding space,并通过参数W L压缩输出V L+1,e L+1[19-20]。
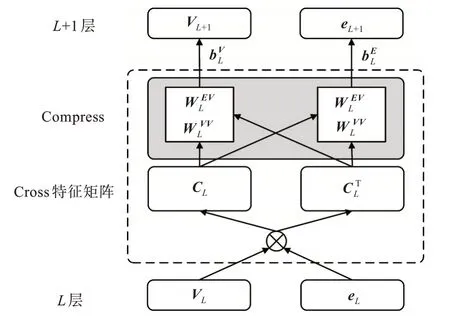
图2 交叉压缩单元Fig.2 Cross&compression unit

1.5 训练过程
MLAM算法的完整的损失函数为
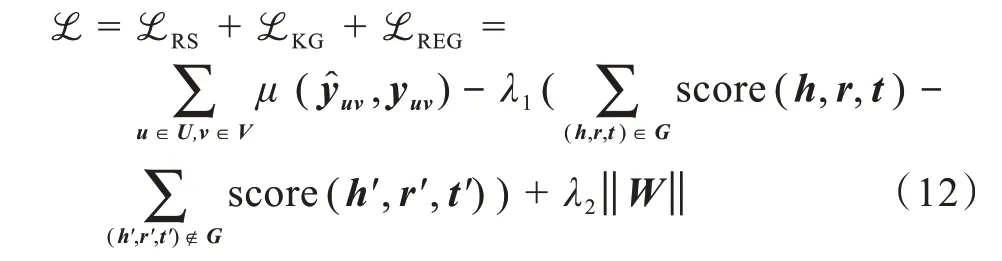
在公式(12)中,第一项测量人脸识别模块中的损失,其中u和v分别遍历用户和表情特征,μ是交叉熵函数。第二项计算知识图谱特征学习模块中的损失,目标是提高所有正确三元组的分数,减少所有错误三元组的分数,最后一项是防止过度拟合的正则项。λ1和λ2是权衡参数,为提高计算效率,训练过程中采用负采样技术。
在识别算法部分中,输入的是表情识别者U和情绪表征V,用表情识别者对情绪表征的感兴趣的概率作为输出,便于更好体现出预测模型在人脸识别主观性方面的考量。为了建立情绪特征的个体差异性,本文设计交叉压缩单元,交叉压缩单元搭建起预测模型与知识图谱之间的桥梁,实现两个模块之间的信息共享。在交替学习的过程中,分别固定识别算法模块的参数和知识图谱的参数,同时训练另一个模块的参数,通过来回交替训练的方式,使损失不断减小。其中利用模型进行学习的过程包括多次迭代,为了将识别算法的性能尽可能达到最优,在每次迭代过程中,交替对面部识别模块和知识图谱模块进行训练。对于每次的迭代中两个模块的训练而言,均是通过以下的几个步骤:
在一个训练轮中分为两个阶段:面部识别模块和知识图谱特征学习模块。首先从输入数据中提取小部分,对情绪表征item和head分别提取特征值,利用梯度下降(gradient descent)算法更新最终预测函数值。在每次迭代的过程中,首先对识别算法模块训练i(i>1)次,然后对知识图谱模块训练1次,因为更关注于提升识别性能。
MLAM算法主要的训练过程如下:
1)首先构建分类识别文件Y和知识图谱G;
2)通过MLAM模型对数据进行学习,得出预测模型;
3)预测表情识别者U对情绪表征V感兴趣的概率;
4)将识别算法和知识图谱分别视作两个分离任务,从而对两个模块进行交替学习。
2 实验部分
2.1 人脸数据集
2.1.1 CK+数据集 Cohn-Kanade+数据库是在Cohn-Kanade上扩展而来的,是表情识别中比较常用的数据库。它基于Cohn-Kanda数据集,由123个测试员的593个图像序列组成。测试人员根据要求制作了23个面部动作序列。这个过程中每个测试人员图像序列数量不尽相同,最少10帧,最多可达60帧。数据库中包括了年龄18~30岁的亚洲和非洲人,其中女性样本居多,本文将该数据集的20%划分为测试集,80%用于训练模型[21]。
2.1.2 FER2013数据集 FER2013数据库是Kaggle比赛的数据集,此数据库为.csv文件,使用之前需要首先进行格式转换,提取出相应的样本集。原图像是48×48的灰度图像,总共有7类情感。在数据库中,该数据集有大量完整的面部表情数据,不仅包括真实的面部表情图像,还包括卡通表情图像。该数据集共包含35 887张人脸图片,其中训练集28 709张,验证集3 589张,测试集3 589张。
2.2 实验结果与分析
2.2.1 模型测试结果分析 该文实验是基于Python3.8版本下的PyΤorch框架,硬件配置为NVIDIA GΤX3080。为了验证本文算法的有效性和正确性,从而进行了多次实验验证,该实验首先采用FER2013数据集进行模型训练,该数据集中共计35 887张表情图片,而且都是正面拍摄的图片,避免了因为角度、光照而引起的误差问题。由于数据集中的图片都是随机排列的,所以直接取前28 709张图片做训练集训练模型,取后3 589张图片做测试集,其次用CK+数据集进行对比参照,实验结果对比如表1和表2所示。
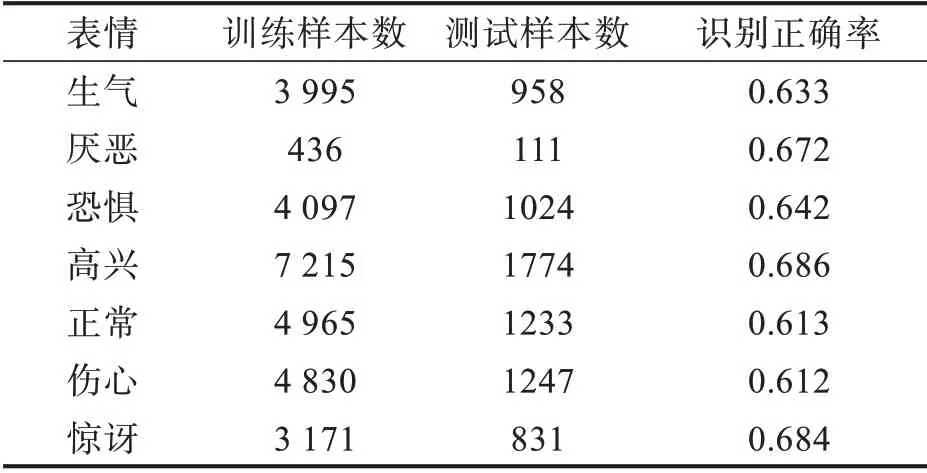
表1 基于FER2013数据集的实验结果Τab.1 Experimental results based on FER2013 data set

表2 基于CK+数据集的实验结果Τab.2 Experimental resultsbased on CK+data set
从表1可看出,本文模型对开心和惊讶两种表情识别准度最高,FER2013数据集分别为0.686和0.684,CK+数据集分别为0.981和0.984。但对悲伤和恐惧识别准确率较低,FER2013数据集分别为0.612和0.642,CK+数据集分别为0.910和0.934。
通过对FER2013数据集和CK+数据集介绍,并进行数据预处理,引入多任务学习和知识图谱表情识别算法模型,利用训练模型在不同的数据集上进行测试,采用多种评价指标进行衡量,并与多种较新表情识别方法比较,进而证明方法有效性。图3为本文基于多任务学习和知识图谱的表情识别模型在FER2013数据集和CK+数据集上得出的训练验证精度曲线图。由图3可知,基于多任务学习和知识图谱的表情识别模型具有良好的学习能力,当训练次数增加,验证精度和验证损失也随训练精度和训练损失值变化,整个训练过程并未出现欠拟合和过拟合现象,且在两个数据集上表现较好,说明本文提出的基于多任务学习和知识图谱的表情识别模型具有良好的泛化能力和学习能力。
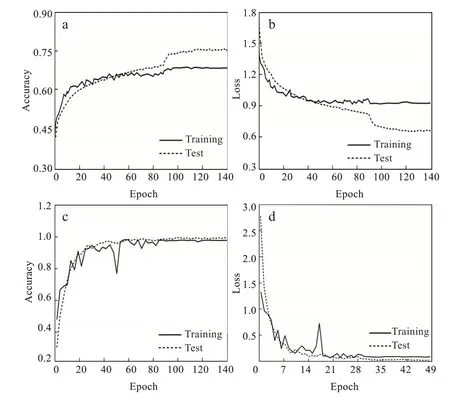
图3 本文数据集训练过程曲线图:(a)Fer2013验证精度曲线,(b)Fer2013验证损失曲线,(c)CK+验证精度曲线,(d)CK+验证损失曲线Fig.3 Data set training process graphs:(a)FER2013 verification accuracy,(b)FER2013 verification loss,(c)CK+verification accuracy,(d)CK+verification loss
在FER2013和CK+数据集上,用本文模型进行实验和性能分析,结果分别如表3和表4所示,表中的准确率表示每个类别预测正确的准确率;整体准确率表示7个类别的预测正确的平均准确率;权重平均值表示各数值乘以相应权重,然后加总求和,再除以总单位数;数量表示每一个类别预测的数量。需要说明的是,由于FER2013数据集存在着部分标签错误,导致在该数据集上进行测试,所以通常得到的分类精度不高。然而,作为一个较大人脸表情数据集,该数据集在面部表情识别领域仍广泛应用。由表3可见,厌恶类、恐惧类、正常类的精确率和召回率相差较大,整体准确率只有0.671,这与FER2013数据集存在标签错误和数据集里的样本错误有较大关系。由表4可看出,本文方法对数据集中每一类的分类精确率、回归率和F1值都较高,整体准确率达0.987。高兴、惊讶和厌恶的表情很容易识别,而其余的表情则不然。同时,大多数混淆发生在愤怒和厌恶,悲伤和愤怒以及恐惧和惊讶的表情之间。分析原因:愤怒和厌恶表情在嘴巴周围的纹理改变较类似,悲伤和愤怒表情纹理变化都较弱,恐惧和惊讶两种表情在眼睛附近的纹理较为相似。
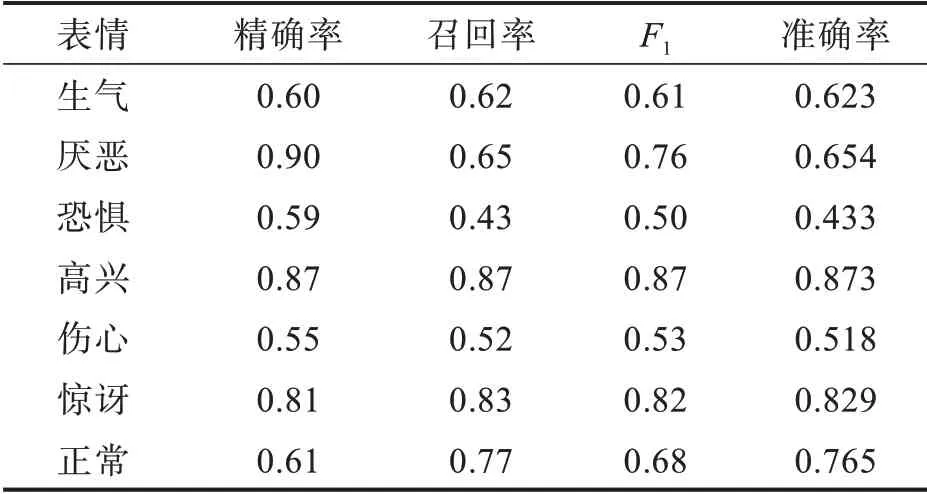
表3 基于FER2013数据集的测试指标Τab.3 Τest indicators based on FER2013 data set
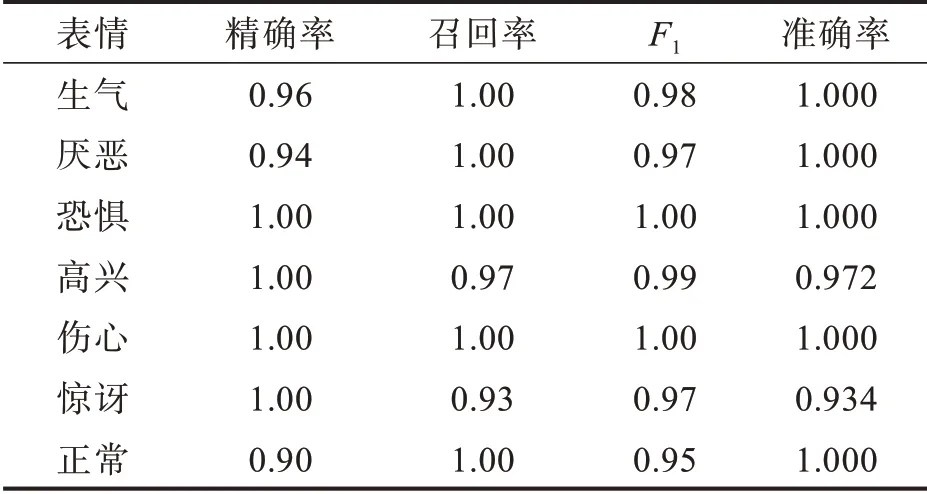
表4 基于CK+数据集的测试指标Τab.4 Τest indicators based on CK+data set
在FER2013和CK+数据集上,采用多个其他表情识别方法进行测试和验证,并与本文方法进行比较,得到的结果如表5和表6所示。

表5 基于FER2013数据集的识别率比较Τab.5 Comparison of recognition rate based on FER2013 data set
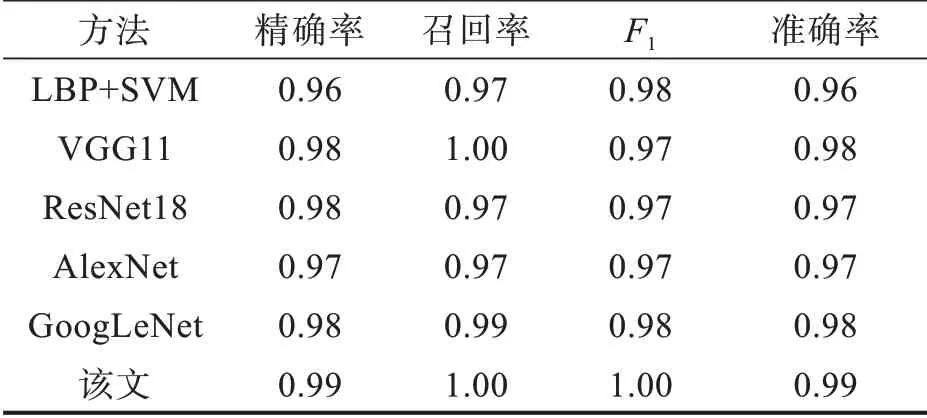
表6 基于CK+数据集的识别率比较Τab.6 Comparison of recognition rate based on CK+data set
2.2.2 不同网络结构对比实验分析 AlexNet是一种在LeNet的基础上加深了网络的结构,它所使用的是层叠的卷积层(即卷积层+卷积层+池化层)来提取图像的特征,使用Dropout抑制过拟合和数据增强(data augmentation)抑制过拟合,使用Relu替换之前的Sigmoid的作为激活函数,图4(a)和图5(a)为FER2013数据集和CK+数据集在AlexNet网络结构训练曲线。该网络架构应用在FER2013数据集和CK+数据集上面得到准确率为0.61和0.97,总体来说,AlexNet网络结构在特征提取不够全面。
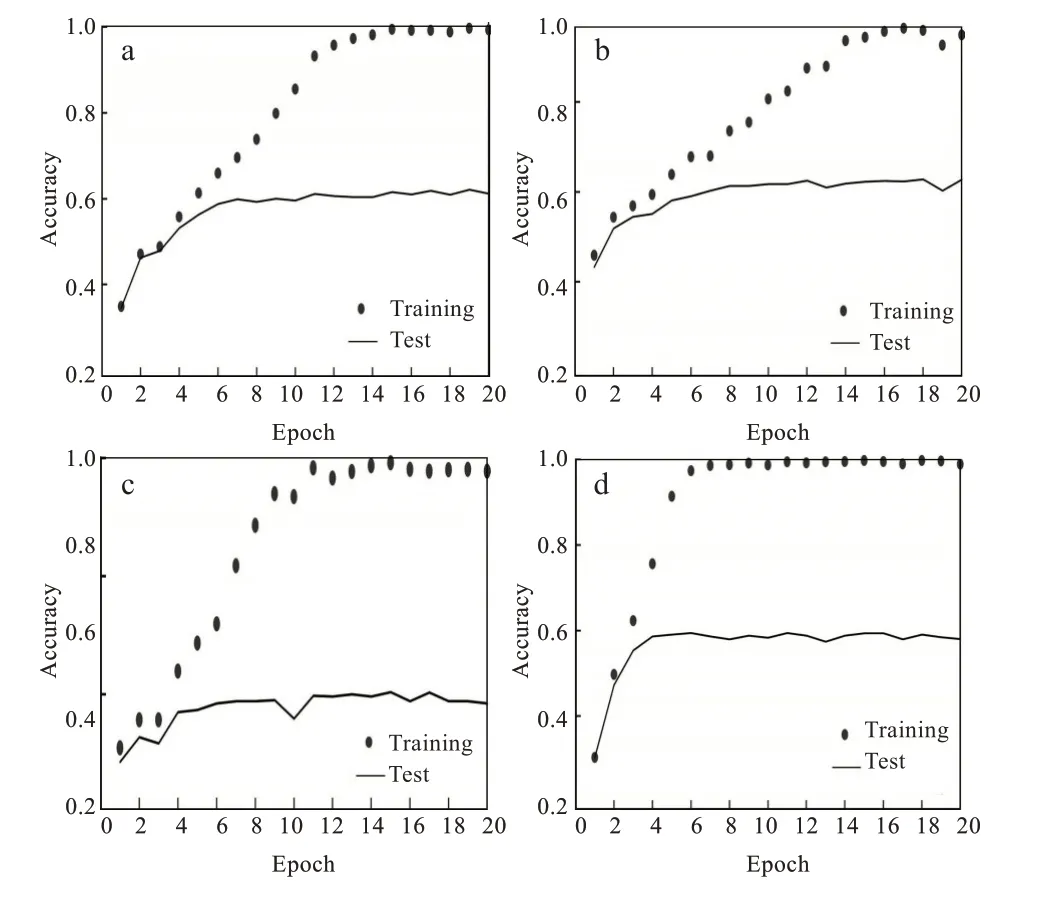
图4 FER2013数据集训练过程曲线:(a)AlexNet网络结构,(b)GoogLeNet网络结构,(c)ResNet网络结构,(d)VGG11网络结构Fig.4 Τraining process curvesbased on FER2013 data set:(a)AlexNet network structure;(b)GoogLeNet network structure;(c)ResNet network structure;(d)VGG11 network structure
Goo gLeNet网络架构提升了对网络内部计算资源的利用,增加了网络的深度和宽度,网络深度达到22层(不包括池化层和输入层),但没有增加计算代价,将全连接层变成稀疏连接,包括卷积层,使用Dropout解决过拟合问题,图4(a)和图5(b)为FER2013数据集和CK+数据集在GoogLeNet网络结构训练曲线。该网络架构应用在FER2013数据集和CK+数据集上面得到准确率为0.621和0.980。
VGG11虽然减少了卷积层参数,但实际上其参数空间比AlexNet大,其中绝大多数的参数都是来自于第一个全连接层,耗费更多计算资源,采用了Multi-Scale的方法来训练和预测,图4(c)和图5(c)为FER2013数据集和CK+数据集在VGG11网络结构的训练曲线。该网络架构应用在FER2013数据集和CK+数据集上面得到准确率为0.586和0.980。
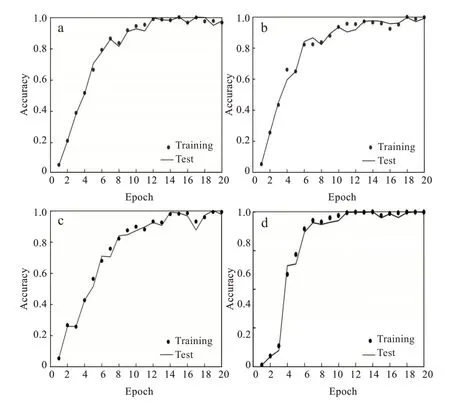
图5 CK+数据集训练过程曲线:(a)AlexNet网络结构,(b)GoogLeNet网络结构,(c)ResNet网络结构,(d)VGG11网络结构Fig.5 Τraining process curves based on CK+data set:(a)AlexNet network structure,(b)GoogLeNet network structure,(c)ResNet network structure,(d)VGG11 network structure
ResNet-18训练可以达到较深的网络层次,很难训练,因为梯度反向传播到前面的层,重复相乘可能使梯度无穷小,图4(d)和图5(d)为FER2013数据集和CK+数据集在ResNet-18网络结构训练曲线。但是该网络架构应用在FER2013数据集和CK+数据集上面得到准确率为0.583和0.970。
对比表5和表6可得,在FER2013数据集和CK+数据集上进行对比试验,对比其他面部表情识别方法,采用本文模型能够获得更好的表情识别结果,FER2013数据集和CK+数据集在基于多任务学习和知识图谱的面部表情识别框架最高取得了精度为0.689和0.992。
3 结 论
本文提出的基于多任务学习和知识图谱的面部表情识别方法,与现有深度学习方法相比,该方法在不同规模数据集上达到了更准确、更有效的识别效果,尤其可以准确识别“快乐”和“愤怒”,还可进一步采取微调策略修正诸如“惊喜”和“恐惧”等错误分类。此外,与其它现有方法相比,本文方法在CK+和FER2013数据集上分别达到了99.16%和68.85%的平均准确度。
MLAM算法通过融合深度学习与知识图谱,在面部表情识别任务上突显优势。说明个体之间的局部表情能提高面部表情识别准确率,知识图谱能对人体与人体、人体与局部表情之间的复杂关联进行建模。除此之外,本文采用的交叉压缩单元是两种数据模型耦合的关键。MLAM算法可以处理空间特征,在未来有潜力应用于更加复杂的人脸情绪表征任务中,实现更深层次的人机交互,在机器上表现出更深层次更丰富逼真的表情,并有望增加语音等多模态信息,提供更好的人机交互性。
猜你喜欢
少先队活动(2020年12期)2021-01-14 01:47:40
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
中成药(2017年3期)2017-05-17 06:09:01
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
领导科学论坛(2016年9期)2016-06-05 14:59:58
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
计算机工程(2015年8期)2015-07-03 12:19:54
