
基于静态路由分组胶囊网络的文本分类模型
2021-12-29 07:19朱海景盛钟松陈贵强
四川大学学报(自然科学版) 2021年6期
朱海景, 余 谅, 盛钟松, 陈贵强, 王 争
(四川大学计算机学院, 成都 610065)
1 引 言
文本分类是自然语言处理中至关重要的一步,其目的是利用非结构化的文本数据来归纳信息[1].早期的文本分类方法是通过人工设计特征,然后用机器学习方法进行分类.但随着深度学习的深入研究,神经网络等被大量用于文本分类,并且能够自动获取文本特征,分类效果更好.
胶囊网络是一种新兴的神经网络结构,该结构的特点是能在小数据集中提升分类准确率.胶囊网络模型是2017年由Sabour等[2]在NIPS上首次提出的神经网络模型,类似于卷积神经网络,在图像领域获得了很好的效果.Ding等[3]采用分组反馈胶囊网络,利用分组胶囊获取局部信息并共享权重矩阵以减少参数,用反馈方式的网络模型预测胶囊来提高应对复杂数据环境的适应能力.Zhao等[4]将胶囊网络引入到文本分类领域,也取得了不错的性能.近年来,随着对胶囊网络研究的不断深入,其改进方法也越来越多,但主要集中在两个方面:(1) 是提升胶囊质量;(2) 是改进路由规则减少网络参数[5].本文通过对胶囊进行分组,以提取更有价值的文本信息,减少冗余信息,达到提高胶囊质量的目的;同时,利用静态路由机制[6],去除动态路由中的耦合系数[2];采用胶囊压缩[7]操作,减少了网络参数.为此我们提出了CapsNet-GSR文本分类模型.
本文的主要贡献有三个方面:(1) 将分组胶囊网络应用到文本分类中,验证了该方法在文本分类领域的有效性;(2) 采用胶囊压缩和静态路由机制减少网络模型的参数;(3) 通过对比实验,突出本文方法在模型参数和训练时间上具有明显优势.
2 相关研究
文本分类是指用计算机对文本数据集(或其他实体)按照一定的分类标准或体系进行自动分类标记的过程[8-9].文本分类始于20世纪50年代,利用的是专家规则,但该方法需要对相关领域有深入研究才能写出合适的规则,因此发展受限.80年代出现了专家系统,即利用专家掌握的知识构造分类系统[10],比如CONSTRUE系统[11].90年代有了支持向量机,便产生了基于机器学习的文本分类模型.2010年后随着深度学习的广泛运用,基于神经网络的文本分类模型表现突出,并广泛应用于学术界和工业界.
2.1 文本分类模型
从文本分类的发展来看,文本分类模型可分为传统的机器学习模型和深度学习模型.
传统的机器学习模型有朴素贝叶斯(NB)[12]、k-最近邻(KNN)[13]、决策树(DT)[14]、支持向量机(SVM)[15]等.与早期基于规则的方法相比,此类模型在准确性和稳定性上更甚一筹,但此类模型仍需进行特征选择与提取的过程,且容易丢失文本内的前后位置关系或语境,导致单词语义理解不准确.
深度学习模型是基于神经网络的模型,如卷积神经网络(CNN)[16-17]、循环神经网络(RNN)[18]、长短期记忆网络(LSTM)[19]和胶囊网络(CapsNet)[4,6-7,20-21]等.与传统的机器学习模型相比,深度学习模型不需要人为选择和提取特征,即可自动获取有用的语义信息.由此可见,文本分类采用深度神经网络更智能,而且利用深度神经网络,可以挖掘出更多更深层次的文本数据信息,以提高算法的分类准确度、鲁棒性和泛化能力.
2.2 基于胶囊网络的文本分类方法
胶囊网络主要由卷积层、初级胶囊层、数字胶囊层、全连接层等组成.胶囊层又由许多胶囊组成,其中每个胶囊又包含多个神经元.每个神经元表示图像中特定实例的属性,如姿态、大小、位置、方向、纹理等.每个胶囊即为一个向量,向量的长度表示实体存在的概率,长度越长,则存在的概率越大.因此胶囊层的胶囊输入是向量,输出也是向量.
胶囊网络中的胶囊包含丰富的空间位置等信息,相邻节点之间具有强相关性,而且能够保留原始数据中的底层细节信息,这些特性正好契合了文本数据中上下文之间存在的联系性和自然顺序性,能够很好地提取单词的语义信息,有利于文本的正确分类.另一方面,胶囊网络的结构较浅,对小数据样本集友好.但胶囊网络自2017年被提出动态路由机制后才得到广泛关注,因此将胶囊网络运用在文本分类领域的研究并不多.
Zhao等[4]在动态路由胶囊网络的基础上,提出了一个用于文本分类的胶囊网络.通过在胶囊层中增加共享矩阵和非共享矩阵,提高了胶囊内局部信息的多样性;通过引入孤立类别、修正连接强度等方法减少噪声.Zhao等[20]针对多标签输出数据集,通过引入自适应优化器、胶囊压缩和部分路由来提高胶囊网络的可靠性可拓展性,提出了可靠可扩展的胶囊网络模型.Kim等[6]提出运用一种简单的静态路由方法来降低动态路由的计算复杂度.Ren等[21]利用组合编码胶囊构造词嵌入来减少词嵌入参数,并采用K均值路由算法来提高网络模型的稳定性和鲁棒性.
3 本文模型
本文模型框架如图1所示.模型由卷积层、分组胶囊层、压缩胶囊层、文本胶囊层等组成.其中压缩胶囊层到文本胶囊层之间采用静态路由方法进行传递.
3.1 卷积层
首先,我们在嵌入文本上采用卷积过滤器进行卷积操作来提取特征.模型的输入为X∈RL×V的文本句子.其中,L为句子的长度;V为词嵌入大小(词向量维度).Xi∈RV为一个输入句子中第i个词的词向量.Wa∈Rk×V为卷积过滤器.其中,k为过滤器的宽度,本文采用3种过滤器Wa以提取不同的特征,其宽度分别为(3,4,5).然后将该过滤器与句子局部区域Xi:i+k-1∈Rk×V进行卷积以生成一个特征.
mi=f(Wa∘Xi:i+k-1+b0)
(1)
其中,“∘”表示为对应元素乘运算;b0为偏置项;f(·)为ReLU激活函数.利用过滤器以步长为1滑过整个句子文档后得到所有的mi组成一个特征图m(m1,…,mL-k+1).因此,当有A个过滤器Wa(a=1,…,A)就可以得到A个特征图:
M=[m1,m2…,mA]∈R(L-k+1)×A
(2)

图1 本文模型示意图Fig.1 Schematic diagram of model
3.2 分组胶囊层
分组胶囊层采用Ding等[3]提出的胶囊分组方法.每个胶囊组包含若干个d维胶囊,而每个胶囊是由特征图上不同通道相同位置的元素组成,同一通道的不同位置表示不同的胶囊.该胶囊示意图如图2所示.我们将胶囊均匀地分为若干个组,具体分组情况将在第4.2节中讨论.

图2 四维胶囊示意图
胶囊只有与其相关的胶囊之间才有利用价值,因此可以利用余弦相似度来衡量一对胶囊之间的相似度.我们希望不同组胶囊间的相似度尽可能小,同一组的相似度尽可能大,并通过最小化分组损失[3]来达到分组的目的,具体实现方法如下.
设{Gt}t=1~T,t表示胶囊组,每组有M个胶囊{vj}j=1~M,各组胶囊Gt的平均值可定义为
(3)
一对胶囊的相似度定义如下.
(4)
其中,(v1-μt)·(v2-μt)表示向量(v1-μt)和向量(v2-μt)的内积,然后可以得到所有胶囊类内相似度为
(5)
所有胶囊类间相似度为
(6)
其中,μt1表示第t1个胶囊组的平均值,可用式(3)计算得出,μ表示所有胶囊的平均值.最后,分组损失可定义为
LGroup=Sb/Sω
(7)
通过最小化分组损失,确保胶囊能够被正确地分成若干个组,即将同一组的胶囊拉近,将不同组的胶囊推开.

(8)
(9)

图3 一个分组胶囊的转化过程Fig.3 The transformation process of a grouped capsule
3.3 压缩胶囊层
由于胶囊的数量与输入文档的大小成比例的增大,当输入的文档或句子较长时,对GPU内存有很大的要求.因此在转化胶囊传递至压缩胶囊层时,我们对转化胶囊进行一个压缩操作,以合并相似胶囊,去除噪声胶囊.每个压缩胶囊uq通过使用每组所有转化胶囊vtj的加权求和来计算[7].
(10)
其中,参数bjq可通过监督学习得到,其利用均匀分布U(-0.01,0.01)采样进行初始化;J为每组转化胶囊数量;Q为压缩胶囊数量;j、q分别为转化胶囊、压缩胶囊索引.
3.4 文本胶囊层
对于图像分类领域,低层实体的空间位置等信息对分类结果有很大的影响,因此动态路由机制表现出很好的效果.然而在自然语言处理中,文本和情感的表达方式有很大的自由,句子中单词的前后顺序有时对分类结果影响较小.例如,“This movie is rubbish, I don't like it!”与“I don't like this movie , it is rubbish!”,虽然单词的位置发生变化,但其表达的意思是一样的.因此从这个角度来看,运用静态路由机制对分类结果影响不大,而且能够降低计算复杂度,其具体实现方法如式(11)和式(12)所示.
(11)
(12)
其中,sr为文本胶囊层胶囊r的所有输入向量;Wqr=[R×Q]为由压缩胶囊层到文本胶囊层的权重矩阵,可通过学习得到;R为文本胶囊的数量.vr为文本胶囊层中胶囊r的输出向量,式(12)即采用非线性挤压函数[2]得到胶囊r的输出向量.由此可见,静态路由取消了动态路由中的耦合系数,而是直接由压缩胶囊经权重矩阵,利用非线性挤压函数得到文本胶囊,此过程大幅缩短训练时间,减少了计算开销.
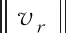
(13)
4 实验结果与分析
4.1 实验环境与评价指标
本文在5个文本分类数据集上进行了对比实验,囊括了新闻分类、评论分类、问题分类、观点分类等文本分类任务,其简要介绍如表1所示.表中“Tr”为训练集样本数,“Ts”为测试集样本数,“Cls”为数据集类别数,“Lavg”为句子平均长度.
本实验均由PyTorch实现,在Ubuntu 16.04 LTS操作系统上,Python3.6环境下,使用NVIDIA GeForce RTX 2070显卡,CPU为AMD Ryzen5 2600X处理器,运行内存16 G.采用预训练好的300维Word2vec[22]词向量初始化嵌入向量,批量大小除AG’s news为50外其他均为25. 为了能将胶囊平均地分成若干个组,且兼顾文本数据集的最大句子平均长度,我们将输入文本长度L调整为387. 使用Adam优化器,初始学习率为0.001.过滤器Wa的宽度分别为3、4、5,步长为1,填充为0,各128个.过滤器Wb的宽度为3,步长、填充各为1,每个胶囊组有64个.
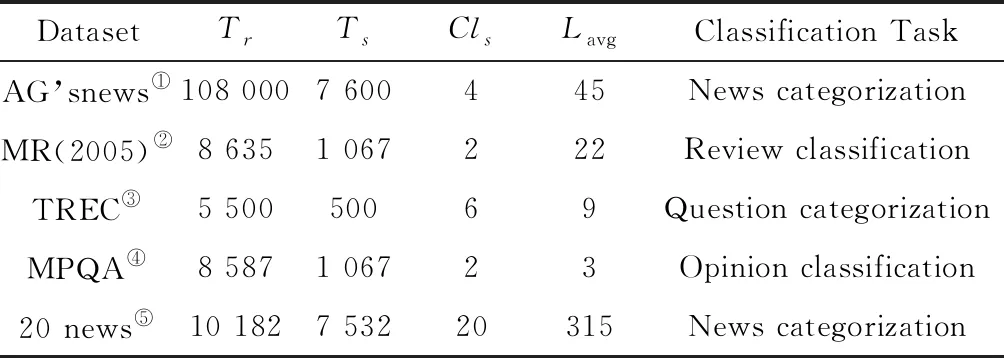
表1 文本数据集简介
本文采用准确率作为评价指标,准确率越高,模型效果越好.对于模型参数和模型训练时间,参数越少,训练时间越少,模型越好越稳定.
4.2 胶囊分组实验
本文将胶囊平均地分为若干组,每个组可以被视为具有相似语义信息的胶囊的集合.我们根据20 news文本数据集的分类准确率的高低来衡量胶囊组分组效果的好坏.如表2所示,我们将胶囊手动地分为D=1、2、4、8、16、32、64组时,对应的参数数量分别为0.69 M、0.76 M、0.91 M、1.20 M、1.79 M、2.97 M、5.33 M,准确率分别为79.01%、82.58%、84.66%、85.93%、86.85%、87.21%、85.07%,由此可知,随着分组的增加,参数数量也随之增加,这是因为有更多的权重在各组中进行共享.通过实验,在分组D=32时,文本分类准确率达到最高的87.21%,可见胶囊的分组对准确率有很大贡献.而当分组达到64时,由于参数的增加,网络训练较为困难,且过多的特征信息会导致网络过拟合,降低分类准确率(由87.21%降低为85.07%),因此我们将分组数量选为32组进行训练.

表2 在20 news文本数据集上的胶囊分组结果
4.3 实验结果与分析
本文与其他方法在模型参数数量,训练时间和准确率上进行了对比实验,实验结果如表3和表4所示.

表3 参数数量、训练时间对比结果
表3为本方法与其他方法在20 news数据集上的参数数量和训练时间的对比结果.批量大小均设置为8,运行时间为训练中每个epoch的运行时间.从表3中可以看出,我们的模型比其他胶囊网络模型有着更少的参数数量,同时每个epoch所消耗的时间也是最少的,在20 news数据集的分类准确率更达到了最高的86.89%. Capsule-A[4]采用了动态路由策略,与文献[2]的网络结构类似,且采用共享权重矩阵与非共享权重矩阵相结合,增加了网络的参数.CapsNet-GSR与Capsule-A相比,参数明显减少了很多,因此训练时间也大大缩短.而CapsNet-static-routing[6]虽然采用的是静态路由,但与CapsNet-GSR采用“胶囊压缩+静态路由”的组合策略相比,模型参数仍然更多.文献[21]中的模型通过组合编码胶囊构造词嵌入来减少词嵌入的参数,并采用K均值路由算法代替动态路由算法,因此在参数数量和训练时间上与本文模型相差不大,但在准确率上比本文模型要低2.95%.

表4 模型准确率对比结果
表4显示了本方法与其他方法在5个文本数据集上的准确率实验结果.从表4可知,本文方法在5个数据集中有3个获得了最高的准确率.
CapsNet-GSR与传统的CNN模型CNN-non-static[16]相比,在5个数据集上分别提高了0.33%、0.69%、1.37%、0.56%和0.61%.与传统的LSTM模型BiLSTM[19]相比,在前3个数据集上分别提高了4.43%、2.89%和5.37%.容易发现,本文模型在TREC数据集上提高较明显.究其原有以下两点:(1) 胶囊网络对小样本数据集较为友好;(2) CapsNet-GSR利用胶囊建立起局部-整体对应关系,并在静态路由过程中找到哪个局部属于哪个整体对象,从而保留了文档和类别的实例化参数,提高了文本的分类准确率.
与胶囊网络模型Capsule-B相比,本文模型在AG’s news、TREC、MPQA 和20 news数据集上分别有0.03%、2.17%、1.68%、7.18%的提高.实验表明,CapsNet-GSR利用分组,共享局部转换矩阵,减少了参数,经过胶囊的整形转化,局部特征被进一步得到提取与保留;通过胶囊压缩合并了相似胶囊,剔除噪声胶囊,提高了胶囊的质量;利用静态路由,进一步降低参数数量,防止过拟合,降低计算复杂度,提高了分类准确率.
与胶囊网络模型CapsNet-static-routing[6]相比,CapsNet-GSR在MR(2005)、TREC和20 news数据集上分别提高了1.21%、0.17%和0.47%.由此可见,采用胶囊分组与胶囊压缩操作对提高分类性能有促进作用.通过利用CapsNet-static-routing和CapsNet-GSR与其他模型比较,可见静态路由策略对提高文本分类准确率有较好效果,而且结合胶囊分组能使胶囊提取的特征更加利于预测分类.胶囊的压缩可能会丢失部分细节信息,但压缩的仅仅是相似胶囊或噪声胶囊,对分类结果影响较小.
5 结 论
本文基于胶囊网络提出了CapsNet-GSR文本分类模型.该模型采用胶囊分组策略提取文本局部信息,提高了胶囊相关性,减少了模型参数,利于胶囊的预测分类;再利用胶囊压缩操作合并相似胶囊,去除噪声胶囊;最后通过静态路由机制降低参数数量,减少模型训练时间.实验证明,CapsNet-GSR在参数数量和训练时间上均有大幅降低,在分类准确率上也有相应地提升.下一步研究中,我们将考虑在多标签分类领域中使用该模型来检验其分类性能.
猜你喜欢
现代装饰(2021年2期)2021-07-21
计算机与网络(2020年9期)2020-07-29
小学生优秀作文(低年级)(2020年4期)2020-07-24
网络安全和信息化(2019年11期)2019-11-25
小学生学习指导(低年级)(2019年3期)2019-04-22
科技与创新(2018年1期)2018-12-23
小学生学习指导(低年级)(2018年9期)2018-09-26
小学生导刊(低年级)(2017年1期)2017-06-12
电子制作(2017年24期)2017-02-02
中国科技术语(2012年3期)2012-03-20
