
基于流计算的保险大宽表系统的应用研究
2021-12-29 03:55安建民周一波彭送庭
现代计算机 2021年31期
安建民,周一波,彭送庭
(英大泰和人寿保险股份有限公司,北京 100089)
0 引言
统计分析系统是公司各级管理人员了解前一日公司经营情况的重要系统。该系统通过数据抽取软件,每日批处理生成各种统计指标。随着互联网的高速发展,数据规模的不断增加,数据变化速度越来越快[1],用户希望得到更快的数据处理和响应时间[2],因此建设数据实时展示系统,实现对指标数据的实时计算变得越来越重要。
为让公司各级管理人员能够实时看到指标数据,本文设计的保险大宽表系统,利用分布式流计算技术[3]解决了在分布式环境下数据处理的一致性问题[4]、在数据从源数据库Oracle同步到MPP数据库的时效问题以及在界面展示时数据的主动推送问题。对比统计分析系统是以T+1[5]的模式对数据进行分析处理,无法实时查看最新保单数据信息,该系统极大地缩短了数据处理时间,实现了保险数据基本指标T+0模式下的数据实时同步和计算[6]。
1 系统总体设计
本文主要采用分布式流计算实现个险渠道大宽表保单数据实时计算、多表关联和分布式处理。通过采用分布式流计算技术,应用Kafka和Spark Streaming[7]实现分布式并行处理,提升系统计算性能和高可用性[8];应用MPP数据库,提高了对海量数据的分析处理[9]和并行数据计算能力,让业务人员能即时知晓最新保单和汇总数据的变化情况。
图1详细展示了保险大宽表系统设计框架。
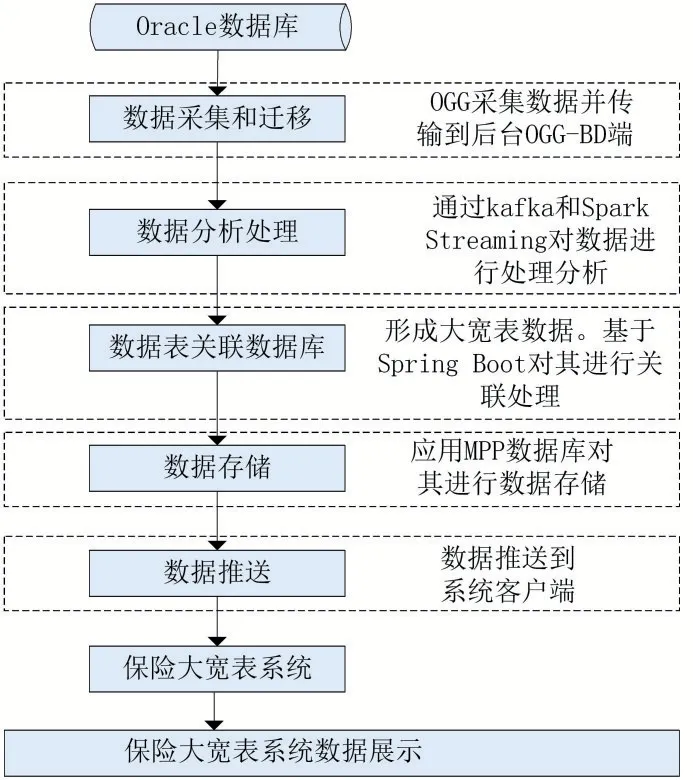
图1 保险大宽表系统设计框架
2 详细设计分析
2.1 数据采集和迁移
保险大宽表系统通过采用OGG(oracle golden gate)源端去抽取和投递保单变化的所有数据信息。OGG-BD(OGG-bigdata)端会通过复制进程把发送过来的Trail file数据存入到分布式消息队列Kafka中。传统保险系统数据库应用以Oracle为主,在进行数据采集和迁移过程中,对数据业务的处理有很高的时效性要求。OGG是一种成熟的数据迁移产品,可以在异构的基础上实现大量数据的秒级数据采集、转换和投递。通过解析源数据库在线日志或归档日志获得数据的增、删、改变化,再将这些变化应用到目标数据库,实现源数据库与目标数据库的同步和迁移。
2.2 数据分析处理
本文针对海量、多源、处理效率要求高的保险业务数据特点设计了基于Kafka和Spark Stream⁃ing的分布式并行处理方案。Kafka是具有高吞吐量的分布式消息订阅和发布系统[10]。主要由Pro⁃ducer(生产者)、Broker(代理)和Consumer(消费者)三大部分构成[11]。其中生产者负责将收集到的数据推送到代理,而代理负责接收这些数据信息,并将这些数据本地持久化。消费者则直接对这些数据进行处理[12]。
在技术上,本文应用SharePlex监控Oracle日志文件,实时获取数据库的操作消息,获取数据库系统中增、删、改的数据。同时应用Kafka记录监控的数据信息,Kafka进行消息队列分发,将数据推送到下方进行处理加工操作。
Spark Streaming主要是用来抽取数据,对数据进行并行计算处理。
Spark Streaming是基于Spark上用于处理实时计算业务的框架,其实现是把输入的流数据进行切分,切分的数据块用批处理方式进行并行计算处理。
基本的分布式流处理框架包括数据接入层、消息缓存层、流处理业务层和集群服务[13]。Kafka主要作用于消息缓存层,Spark Streaming主要作用于流处理业务层。如图2所示。

图2 流数据处理基础框架
从图2可以看出,存储过来的数据指将数据源加载到消息队列的过程。对于Kafka来说,是生产者将数据载入消息队列,并解耦数据的生产方和使用方,对数据进行消息缓存,重建分布式查询系统,提供增量数据加载接口模式。通过这种情况可以分布到多个节点上,不同的数据节点,将其对应的数据源以消息的形式发送到对应的节点上。流处理业务层负责消费消息队列中的数据,对这些数据进行分析处理并得到相应的结果,解决在数据载入过程中数据库中可能存在的性能劣势问题[14]。
2.3 数据表关联数据库
Spring Boot主要是用于多层架构体系的模型业务层,具有降低多层模块间的耦合性、分层模块化架构应用业务系统的优势[15]。
保险大宽表系统通过Spring Boot和Spark Streaming实时消费Kafka中的数据,对数据做质控、关联的操作,最终形成大宽表的数据。Spark Streaming从Kafka消息队列中按照时间窗口不断提取数据,然后进行批处理[16],其主要是对保险大宽表系统里的保单数据进行统计分析。然后对处理的数据结果进行存储,以保单号和时间字符串为key进行存储,主要存储到Redis中,如图3所示。本系统中数据质控分析中的一些字典信息是通过Redis内存缓存来提高查询分析的效率。在关联过程中,首先判断已有的Redis里是否已经存在这些数据信息,如果存在则直接调用,如果不存在,通过查找数据库里面的内容并将其存入Redis且设置好TTL,方便下次可以直接在Redis中调用,而不需要再去数据库中进行查找,提高了查询效率。
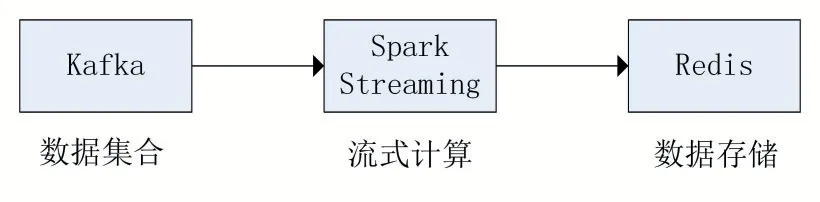
图3 Redis存储数据
2.4 数据存储
保险大宽表系统数据存储采用MPP数据库,其拥有海量的计算能力、容错能力及优秀的扩展性。不仅如此,它还可以让所有数据分布到每个节点上,使得每个节点去计算自己的部分数据,达到并行处理无需人工干预的目的,并可以通过增加通用硬件去扩充新的计算节点。
针对普通的节点,可以将一份数据分布在多个节点上,由此避免由于单个节点出现故障而导致数据丢失和数据不可用现象的发生,对于管理节点而言,一般也采用高可用设计,避免单点故障,提高了对数据查询和分析的效率。
2.5 数据推送
将数据实时发送给系统前端,保险大宽表系统使用WebSocket协议作为服务化接口。Web⁃Socket作为一个独立在TCP上的协议,本质是基于TCP为客户端和服务器提供一种socket通信连接,使得客户端和服务器端实现双向通信[17]。对比传统实时数据更新方案,WebSocket[18]可极大地减少网络流量与延迟[19]。
保险大宽表系统中所有数据采用push方式进行推送,服务器接收到数据后会立即发送到客户端上。客户端和服务器之间通过进程创建基于WebSocket技术的通信连接,系统就能利用服务器的推送功能实现对保险数据指标的实时查看。
3 系统实现关键问题分析
3.1 分布式并发处理数据一致性问题
在采用分布式技术提高数据计算和系统本身的性能时,需要考虑到数据的一致性问题,比如同一份保单数据在很短的时间内先后发生两次变更,两次变更后的数据分别是U1和U2。在分布式环境下,U1和U2可能被随机分配到不同机器的不同线程上执行,执行的顺序可能会变成先U2后U1,这样数据的一致性无法得到保证,导致目标数据库的数据发生错误。
基于以上问题,保险大宽表系统利用Kafka同一个Topic的同一个partition顺序消费且同一个Topic的同一个partition只能被同一个线程消费数据的特点。处理程序时,首先把OGG-Bigdata发送到Kafka的数据根据数据特征分类到同一张保单上,再根据保单编号为key通过shuffle动作发布到另外一个Topic,这样就保证了同一个保单编号的数据肯定会分配到同一个partition,处理程序处理shuffle后的Topic,从而保证了数据的一致性。如图4所示。
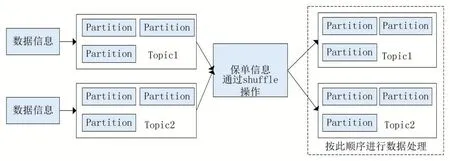
图4 数据一致性处理过程
在保险大宽表系统中,通过利用Kafka实时收集数据并传到Spark Streaming可进行实时分析,Spark Streaming可以将接收到的数据汇总成多个小数据集,Spark Streaming每次处理的是一个时间窗口的数据流,实质上是对这些数据进行批量的实时处理[20],如图5所示。这一特点可以很好的避免并发数据处理中频繁的任务分配和调度问题,能达到次秒级延时的实时处理。

图5 数据实时处理
3.2 从Or ac l e到MPP数据库的实时同步问题
当数据从中转数据库导入到MPP数据库中时,关键部分是要保证数据同步。MPP数据库具备高性能、高可用和高扩展特性,但其对数据的增删操作比较差,在并发量大的情况下,性能会更低。因为每天保单系统上都会有大量的变化数据产生,从源数据库中采集而得到的数据直接导出文本在进行导入会占用很大的空间,耗时长,导致数据时效性差,不能达到数据实时同步。
保险大宽表系统通过利用Batch(批处理)操作,先定期删除发生变化的数据,把这些变化的数据导出为CSV格式文件,通过load操作解决数据在增加和更改过程中效率慢的问题,实现数据的近实时变化。
4 结语
本研究通过分析目前保险系统中业务人员不能实时查看当前保单系统的保单信息和各个指标汇总数据,给出了一种基于分布式流计算实现一个流式大宽表数据系统,可以实时采集保单系统各项数据的变化。通过将Kafka和Spark Streaming结合的方式实时关联多表数据,处理数据增删改变化,最后存储到MPP数据库中,能够让保险业务人员实时查看最新保单数据信息及各个保单指标汇总信息。
猜你喜欢
科学与财富(2021年35期)2021-05-10
通信产业报(2020年43期)2020-01-15
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
东坡赤壁诗词(2018年3期)2018-07-16
金融经济(2018年3期)2018-04-03
