
基于深度学习的在线学习成绩预测研究
2021-12-28 23:23郑安琪王宇琪郝川艳
计算机时代 2021年12期
郑安琪 王宇琪 郝川艳




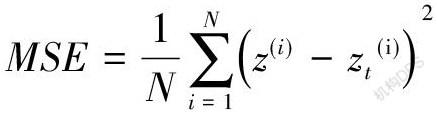
摘 要: 通过分析在线学习平台中的教育文本,能挖掘其所蕴含的情感、认知等信息进行学业预测。然而目前在线学习成绩预测大多基于结构化数据,难以深入、精准地挖掘学习者的状态、情感等信息,影响到预测的准确性。采用深度学习技术,其中CNN模型能够有效提取局部特征,而LSTM模型能够考虑全局文本顺序的优势,能对教育短文本数据进行分类和细粒度情感倾向分析,挖掘其包含的影响学习成绩的因素,实现对在线学习成绩的有效预测。
关键词: 深度学习; 成绩预测; 文本分析; 教育数据挖掘; 情感分析
中圖分类号:TP391 文献标识码:A 文章编号:1006-8228(2021)12-69-04
Abstract: By analyzing the educational texts in the online learning platform, the emotional and cognitive information contained in them can be mined to make academic achievement prediction. However, at present, online academic performance prediction is mostly based on structured data, which makes it difficult to excavate learners' state, emotion and other information deeply and accurately, thus affecting the accuracy of the prediction. Adopting deep learning technology, in which CNN model can effectively extract local features and LSTM model has the advantage of considering global text order, can classify educational short text data and analyze fine-grained emotional tendency, mining the factors that influence academic performance to achieve effective prediction of online learning performance.
Key words: deep learning; performance prediction; text analysis; educational data mining; sentiment analysis
0 引言
在线学习中蕴含的教育大数据资源与人工智能等新兴技术的融合,提升了教育大数据研究的深度与广度;深度探索教育过程中各因素之间的内在关系,为教育发展及策略改进提供了有力的支持,将成为教育发展的重要方向[1]。同时,在教育大数据支持下,学习预测已经成为教育数据挖掘的重点内容,通过揭示学习过程各因素与成绩之间的关系,形成预测模型,能够预判学习者的最终表现及成绩类别,从而为学业预警、调整教学策略及学习计划制定等提供重要依据[2]。
当前有关学习情况预测的研究中,所选用的数据类型单一,大多局限于较为整齐的结构化数据,使用学习过程的文本数据进行预测的工作仍较少;而文本数据中蕴含着大量的情感信息和学习状态信息,有效捕捉其中的情感倾向,诊断当前的学习状态,能够为学习成绩预测提供重要的依据。近十年来,机器学习领域发展最快的一个分支,深度学习技术,在文本数据分析等方面表现出了优越的能力。它能够学习样本数据的内在规律和表示层次,对数据解释进行强有力的支持。因此,本文提出使用卷积神经网络(Convolutional Neural Network,CNN)与长短期记忆网络(Long ShortTerm Memory,LSTM)相结合的方法进行在线学习成绩预测。CNN 模型的卷积结构能够有效提取大量数据中的局部特征,准确抓取到文本数据中的关键信息,同时,LSTM 模型具有能考虑到全局文本顺序的优势,可以综合课程学习全过程分析语义及情感倾向,结合二者的特点,能够更精准地挖掘学习成绩的影响因素,实现有效预测。
1 相关工作
对教育数据筛选与整理,借助分析统计工具建立关系模型,可以挖掘学习者学习行为和学习效果之间的潜在联系,从而对学习者后续的表现进行预测。已有的研究内容:一是基于日常表现数据对学习者能力及后续发展进行预测,该类方法基于学习者自身情况[3]、环境及学习过程中各因素[4],分析学习趋势,进而为未来发展提供指向性建议;二是对学习者的课程成绩进行预测,利用从学习平台收集的客观、结构化的基本信息数据、学习行为数据及阶段性的学习成绩来进行预测[5],同时,通过参考以往学生的课程成绩,能分析各门课程间、前导课程与后续课程的相互联系,为教学计划制定提供重要依据[6]。
在成绩预测的技术实现方面,在探究各因素之间的关系时,以往研究较多采用线性回归、决策树及神经网络等算法,但由于与学习成绩或效果相关联的因素是多种类且复杂的,使用这类算法计算得到的关系预测模型,仍没有达到理想的效果。
深度学习是机器学习算法重要的分支与发展成果之一,最早由多伦多大学的 Hinton 教授于2006年提出[7]。它的基本机制是让机器能够像人一样具有分析学习能力,对样本数据或训练集进行学习,分析其内在规律,从而能够有力地解释识别诸如文本、图像和声音等数据,达到远超过先前相关技术的目标,目前已经在诸多领域取得了优秀成果[8],教育领域也不例外。就深度学习在学习预测中的研究而言,其对教育数据具有良好的分析效果,使用复杂神经网络对文本数据处理的分析及预测,能够更有效地刻画教育数据中丰富的内在信息。
2 深度学习技术对成绩预测的支持
2.1 细粒度文本情感倾向分析
在线教育中,师生通过交流、评价和反馈等互动来深化和完善课程学习,平台记录下大量文本数据,其中蕴含了丰富的观点、想法、态度及主观情感等;当前文本情感倾向分析,可以分为篇章级、句子级的粗粒度文本情感分析以及短语级的细粒度文本分析[9],粗粒度分析方法适合判断整体的情感,可以处理一些写作作业的文本分析任务,但在线平台产生的大多是简短、随意性较强的短文本,使用粗粒度分析难以得到细致、精准的处理结果。使用深度学习神经网络模型能对多类型数据进行处理与变量转换,模拟人类的神经系统对文本逐步分析、进行特征的提取,自动学习优化模型输出,能有效地提高文本分类的有效性[10],实现细粒度情感分析,为成绩预测提供支撑。
另一方面,影响学习结果的因素十分复杂,涉及的特征提取过程是一个巨大的需要专业领域知识的工程,人工特征提取存在着难以联系上下文、特征稀疏等困难,很难精准高效地识别并归纳出特征,影响预测结果的有效性和准确性。而深度学习技术可以利用任何可向量化的数据作为输入且不需要特别的注解和标记,从而减少了大量的人工特征提取工作。这对于学生成绩建模极具优势,可以提升预测结果的效度和信度[11]。
2.2 复杂函数关系的拟合
在线学习中各影响因素与学习成绩之间的关系并不是简单的线性关系,因素与因素之间,因素与成绩之间的关系都是复杂多变的,各变量之间的函数关系通过简单的分类回归难以拟合。对于结构化数据,指定输入(影响学习成绩的各类数据)和输出(最终学习成绩)以后,提供足够量的数据,通过训练可以轻松地得出两者之间的关系,从而在输入新的数据时得到成绩预测结果。但当输入变为大量的、多类型的非结构化数据时,蕴含的影响因子复杂,很难得出输入与输出之间的映射关系,而神经网络则能够解决这个问题。典型的神经网络结构由输入层、隐藏层、输出层构成。隐藏层的神经网络模拟了人类大脑皮层神经网络,由多个神经元组成。底层神经元的输出是高层神经元的输入,可以拟合任意复杂度的函数。深层神经网络则是增加了网络层数来模拟人脑复杂的层次化认知规律,以使机器获得“抽象概念”的能力,在特征学习方面表现出了更为优越的性能[12]。因此使用深度学习技术可以有效的对非结构化数据实现特征学习,精准得出影响因素与成绩之间的关系,实现预测任务。
3 基于深度学习的成绩预测设计
在线学习平台中,所留下的本文都具有简短、随意性强的特点,CNN的卷积层能有效提取此类短文本数据的特征,相比较传统方法能够更准确地捕捉文本中的特征,找到与学习效果有关联的因素。而LSTM网络则考虑了文本的前后顺序关系,从学习者个体发展脉络和时间序列出发,有效地提高了对文本的解释能力。将CNN与LSTM相结合,能够精準拟合各影响因素与成绩之间的关系,提高预测的精准度。
3.1 基于CNN的短语特征提取
CNN是一种带有卷积结构的深度神经网络,基本结构由输入层、卷积层、池化层(也称为取样层)、全连接层及输出层构成,卷积层和池化层通常以多个交替排列的方式存在。正是由于这种结构,CNN擅于从大量的数据中提取局部特征,并且能够很好地将结果泛化到同类型的数据集上。CNN显现出的巨大的优势在自然语言处理上同样受到广泛关注,能有效地提取文本特征并应用于文本分类问题中[13]。
3.1.1 文本嵌入
在线平台中师生产生的短文本作为一种自然语言,需要对其进行向量化处理转化为机器能够理解的语言,也就是将文本数值化之后才可作为CNN模型的输入数据,这一步骤称为词向量表示词语。首先需要对文本数据进行分词,然后转化为词向量。假设句子的最大长度为[l],每个词最终转化为[m]维的词向量,词向量[wi]表示为[wi=[xi1,…,xij,…,xim]],最后每个短文本句子都将表示为[m×l]的二维矩阵[Z=[w1,…wi…wl]]。
3.1.2 特征提取
将短文本变为可计算的词向量以后,将其输入CNN模型中进行特征提取;这一步工作主要由网络模型中的卷积层来完成,经过卷积层处理后的特征矩阵表示为:
[b]为偏置量,[W]为滤波器,用于实现卷积操作。[f]为激活函数,可以为给神经元引入非线性因素,使得神经网络可以达到能模拟非线性函数的效果,在此采用ReLU反向激活函数进行非线性映射:
3.1.3 池化
池化层的目的是保留主要的特征,去掉一些不必要的参数,从而降低信息冗余。在这一步骤中,将提取到的文本特征进行处理,实现了特征降维和特征不变性。我们采用最大值池化(Max pooling)方法来处理。池化后的特征表示为:
3.2 基于LSTM的短文本情感特征分类
经过CNN模型处理计算后,能准确有效地提取到师生互动话语短文本的特征。但在线学习平台的教育文本记录了课程全过程中学习者状态的变化,与时间序列有着密不可分的联系,CNN能够提取到短文本的特征,但是却没有考虑到这一问题;而LSTM是一种时间循环网络,对于有着时间特征的序列数据能够有效地利用上下文的特征信息,将文本的顺序信息考虑进去。因此,采用两种模型结合的方式,能够将CNN提取局部特征和LSTM考虑全局上下文信息的特点相结合,有效地对在线教育平台中的短文本进行文本分类,从而分析情感倾向。
LSTM的功能主要由输入门、遗忘门、记忆单元和输出门等结构来完成,记忆门、遗忘门和输出门的门控状态以及当前输入单元状态分别表示为[zi],[zf],[zo],[z],通过前一个记忆单元的输入信息[ht-1]和当前输入信息[xt]计算得到,公式如下:
遗忘门的功能是选择性地忘记上一个门的状态[ct-1]在下一步中所不需要的信息,由[zf]进行控制;记忆门由[zi]控制,功能是决定输入[xt]哪些信息将存储在当前记忆单元中,其中包括sigmoid层(决定更新值)和tanh层(建立新的候选向量),该层可以补充遗忘门所遗忘的信息,得到当前传输给下一个记忆单元[ct]的输入[z];最后为输出门,由[zo]控制,经过Sigmoid和tanh两函数的处理,两者相乘即为输出信息[ht]。公式如下:
3.3 学习成绩预测
在线学习成绩的预测,需要分析自变量及因变量之间的关系,即对各影响因素及成绩之间的关系进行建模。得出相关模型后,输入学习者现阶段的数据预测出未来学习趋势,同时根据不同维度并以时间为序列可视化呈现出学生的学习情况,为学习者及时调整学习策略或学习状态提供依据。
如图1所示,深度神经网络模型(DNN)包含输入层、隐藏层、输出层,中间隐藏层的层数视情况而变化,每一层的全部神经元与下一层全部神经元以全连接的方式相连,多层隐藏层增加了模型的表达能力,能够更精确的拟合变量间的关系。
在本研究的成绩预测中,设学生在线短文本数据中包含的影响因素变量为[x],学生的最终成绩为[z],以局部模型为例,基于深度神经网络得出学生成绩影响因素变量[x]与学生成绩变量[z]之间的关系需通过线性关系:
及激活函数[σz]来表达。其中[i]为所在隐藏层的层数,[m]为共有隐藏层的层数,线性关系系数[w]及偏倚值[b]则为表达出影响因素变量与成绩变量之间关系的重要参数,也是得出关系模型的所求参数。从局部模型来看,神经网络仍是线性关系和激活函数的组合,但由于隐藏层数量和神经元数量的增加,使其能够更精确的拟合变量之间的关系。同时,为提高模型表达力,使模型更有区分度,引用的激活函数为ReLU:
然后通过反向传播算法(Back Propagation,BP)可求得系数[w]及偏倚值[b],由前向传播过程随机为系数[w]及偏倚值[b]赋值,最后输入成绩影响变量[x],层数[m],及激励函数等,生成输出变量[zt]。接下来,需判断[zt]与收集到的真实的学习数据中的值,也就是期望值[z]的相符情况;若不相符,则重复反向传播过程。输出量[zt]与[z]之间的差异程度则由损失函数表達,在这里采用均方误差来表示,公式为:
系数[w]及偏倚值[b]的计算过程为:先初始化系数[w]及偏倚值[b]的值为随机值,通过前向传播算法与反向传播算法计算输出各隐藏层与输出层的线性系数[w]及偏倚值[b],得出影响因素与学习成绩之间的关系模型。之后将新的学生数据代入到预测模型中,经过计算预测出学习者的最终成绩,实现学习预警及干预功能。
4 总结
本文提出使用CNN模型和LSTM模型相结合的方式对学习过程的短文本数据进行文本分类和情感倾向处理,CNN的卷积层能有效提取短文本数据的特征,LSTM网络则考虑了文本的前后顺序关系。通过深度神经网络进行成绩预测,能够基于多个隐藏层和神经元精准拟合各影响因素与成绩之间的关系,提高预测的精准度。
本研究方法还存在着一些不足之处。一方面,LSTM的计算被限制为是顺序进行的,时间片的计算依赖时刻的计算结果,但在线学习行为在每个时间阶段上不一定能提供完整的特征信息;同时顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构在一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。另一方面,基于深度学习对学生成绩进行预测,对在线学习数据收集具有较高的要求。基于深度学习的预测需建立在数据量庞大的学习数据的基础上,数据的内容也决定着预测的有效性。因此,当前在线学习平台的功能设计、数据收集与记录能力与范围是影响学生成绩预测的重要因素,仍是今后值得深入探究的重要方向。
参考文献(References):
[1] 胡水星.教育数据挖掘及其教学应用实证分析[J].现代远距离教育,2017.4:29-37
[2] 陈子健,朱晓亮.基于教育数据挖掘的在线学习者学业成绩预测建模研究[J].中国电化教育,2017.12:75-81,89
[3] 舒忠梅,屈琼斐.基于教育数据挖掘的大学生学习成果分析[J].东北大学学报(社会科学版),2014.16(3):309-314
[4] 钱增瑾,孙东平.数据挖掘在研究生教育管理信息系统中的应用[J].学位与研究生教育,2013.5:46-49
[5] 尤佳鑫,孙众.云学习平台大学生学业成绩预测与干预研究[J].中国远程教育,2016.9:14-20,79
[6] 黄建明.贝叶斯网络在学生成绩预测中的应用[J].计算机科学,2012.39(S3):280-282
[7] Geoffrey E. Hinton,Simon Osindero,Yee-Whye Teh. A Fast Learning Algorithm for Deep Belief Nets[J].Neural Computation,2006.18(7).
[8] 陈先昌.基于卷积神经网络的深度学习算法与应用研究[D].浙江工商大学,2014.
[9] 宋严.社交媒体文本信息多层次细粒度属性挖掘方法研究[J].情报科学,2020.38(11):98-103
[10] 王婷,杨文忠.文本情感分析方法研究综述[J].计算机工程与应用,2021.57(12):11-24
[11] Steven Tang,Joshua C. Peterson,Zachary A. Pardos.Deep Neural Networks and How They Apply to Sequential Education Data[P]. Learning @ Scale,2016.
[12] 焦李成,杨淑媛,刘芳,王士刚,冯志玺.神经网络七十年:回顾与展望[J].计算机学报,2016.39(8):1697-1716
[13] ATTARDI G,SARTIANO D.Unipi at semeval-2016 task 4:convolutional neural networks for sentiment classification[C] //Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016).San Diego: Association for Computational Linguistics,2016:220224.
猜你喜欢
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
商业经济(2016年11期)2016-12-20
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
戏剧之家(2016年22期)2016-11-30
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
考试周刊(2016年45期)2016-06-24
