
基于改进的LST M-C N N模型的高校网络舆情预警研究
2021-12-27 12:40:42张戎秋
淮南师范学院学报 2021年6期
张戎秋,肖 强
(1.淮南师范学院 计算机学院,安徽 淮南232038;2.淮南师范学院 信息化建设与管理处,安徽 淮南232038)
网络舆情由网络言论发展而来,可以由任何事件刺激所产生的、能迅速通过互联网传播的、人们对于该事件的所有认知、态度、情感和行为倾向的集合[1],它很大程度依赖于网络言论主题是否具有很强的敏感性和活跃性[2]。高校师生对社会热点现象较为敏感,思维活跃,更容易爆发网络舆情。如何及时有效地发现高校师生新热度话题中的情感语义倾向,是网络舆情预警的关键问题[3]。为了有效地预判舆情发展趋势,做好高校网络舆情热度话题中的情感倾向性监测分析,文章通过采用softsign激活函数代替LSTM模型中的tanh激活函数;将L1范数和L2范数线性组合来正则化LSTM模型中的输入权重,两方面对传统的LSTM模型进行改进,然后结合改进的LSTM模型和CNN模型的各自优点,组合成改进的LSTM-CNN模型对高校网络舆情进行文本情感倾向分类,以获取网络言论主题中潜在的热度话题,以达到预警的目的。
一、长短时记忆网络(LSTM)

图1 LSTM模型内部结构
传统的LSTM是一种顺序结构的有监督的神经网络,具有学习长距离依赖关系的能力,所以称为长短时记忆网络(Long Short-Term Memory Network,LSTM)[4-6]。它用存储单元和门控电路机制来控制丢弃或增加信息,解决时间序列问题,能很好地保留历史信息,由于特征丢失较少,进而获得更持久的记忆功能。把LSTM应用在文本处理中,对上下文的语义进行提取具有较好的效果。
二、卷积神经网络(CNN)
卷积神经网络(CNN)核心架构是一种前馈式多层监督学习的神经网络[7],其中每一种特征通过一个卷积核来表示,原始数据同每一种卷积核卷积的结果(特征图)就是在其特征下的表现情况。首先通过多个卷积核对原始数据进行卷积操作,可以很好地提取出原始数据的特征,得到该数据在多个特征下的特征图;接着为了获得特征图中几个最突出的元素,再把特征图进行池化操作;然后运用Dropout正则化方法构成Dropout层,最后通过非线性激励ReLU函数得到输出结果。它是一种多层次堆叠模型,能够很好地进行局部特征的抽取,经常被应用于处理时序数据和数字图像[8-9]。

图2 CNN模型结构图
三、改进的LSTM
为了更好地解决神经网络梯度消失现象,文章对传统的LSTM神经网络进行优化,利用函数softsign具有去中心性、反对称性、可微分性的特征,替代传统的tanh激活函数[10]。
softsign函数相关表达式如下:

为了更好地解决过拟合的问题,文章引入L1范数和L2范数。通过利用L1范数正则化LSTM模型,可以使其具有稀疏性;利用L2范数正则化LSTM模型,可以增强其抗扰动能力。结合了L1范数和L2范数的优点,通过将L1范数和L2范数线性组合成为一个正则项来约束网络中输入权重的大小,对一些因子施加惩罚,来正则化传统的LSTM模型,可以更好地解决神经网络过拟合的问题,以此来提高预警效果。
构建改进LSTM模型如下:
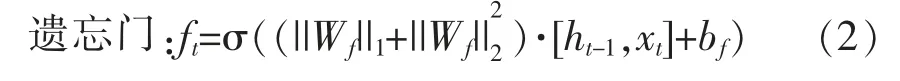
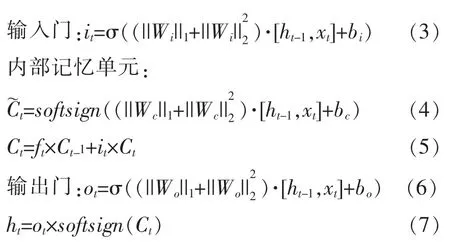
其中:ht-1表示上一单元的输出;xt表示本单元的输入;σ表示sigmoid函数;ft表示用来控制上一单元被遗忘的程度;it用来控制新信息被加入的多少;C~t表示输入门为C~t中的每一项产生一个在[0,1]内的值;Ct表示更新本记忆单元的单元状态;ht表示本单元的输出;W表示权重矩阵;b表示偏置量。
得到网络的最终输出表达式如下:

其中σ表示softmax函数,Wy为输出权重,by为输出偏置项。
t时刻网络均方误差:

网络最终均方误差为:

其中T表示真实值与输出值的比较次数。
通过L1范数和L2范数对LSTM模型中输入权重W进行正则化后,得到的目标函数表达式:
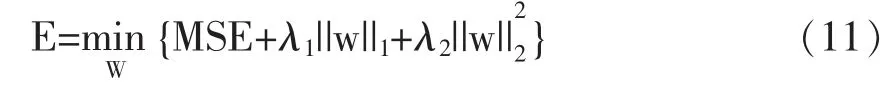
运用Adam优化器[11](P1-15)对于改进的LSTM模型的目标函数进行最小化,并不断更新参数,使整个模型的性能得到优化。Adam算法是神经网络中一种基于训练数据迭代更新权重的自适应学习率的优化算法,它利用梯度的一阶矩估计和二阶矩估计进行动态调节学习率,把学习率限定在固定范围内,这样使参数值比较稳定,可以加快训练速度。
Adam优化算法:

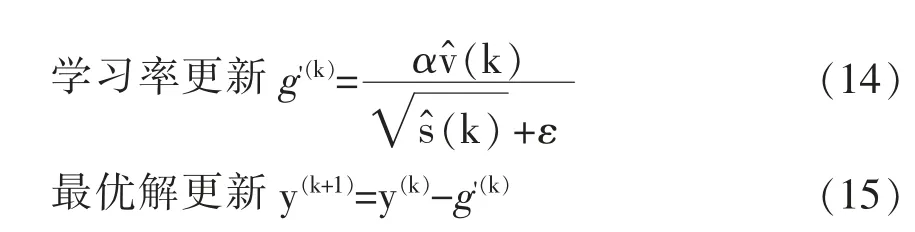
其 中v(k)表 示 一 阶 动 量 项,s(k)表 示 二 阶 动 量项,g(k)表示时间步序列上的梯度,β1表示为一阶矩估计,β2表示二阶矩估计的指数衰减率,○×表示按元素相乘,α为学习率,ε为小常数。
四、基于改进的LSTM-CNN模型的数据处理
LSTM具有利用门控机制和存储单元中的信息来捕获序列中长期依赖关系,最终获得持久记忆能力的特性[12](P1660-1669)。对LSTM模型进行L1范数和L2范数的线性组合正则化改进,能够解决神经网络的过拟合问题,从而更全面地捕获高校网络舆情序列特征,更好地获取高校网络舆情中文本上下文的关联信息;接着使用卷积神经网络(CNN)对高校网络舆情特征信息进行卷积、池化、非线性激励操作后,能够更好地抽取局部特征,挖掘出高校网络舆情信息的潜在语义信息。把改进的LSTM模型与CNN模型进行组合,构建一个改进的LSTM-CNN神经网络模型,充分地利用了改进的LSTM模型和CNN模型的优点。改进的LSTM-CNN模型数据处理流程如图3所示:

图3 改进的LSTM-CNN模型数据处理流程图
通过改进的LSTM-CNN模型的输入层输入数据集;在Embeding层,用结巴(Jieba)分词对文本进行特征分词,每个词使用word2vec的skip-gram模型对词语进行向量化处理,在词语向量化处理时,词向量维度为256时,性能达到最优[13]。迭代次数设为1 000次,学习率设为0.001,采用数据集信息对改进的LSTM-CNN模型进行训练优化。把数据集中的文本按情感倾向进行分类,分别分为非负面情绪、负面情绪两大类,来达到高校网络舆情预警的目的。
五、实验分析
1.数据集
本文数据集来源:(1)中国中文信息学会举办的国际自然语言处理和中文计算会议公布的深度学习情绪分类评测中文数据集;(2)搜狗实验室下载的新闻分类数据集作为训练数据集;(3)爬虫抓取百度贴吧、新浪微博等主流媒体有关高校网络舆情数据信息作为测试集,测试集数据要通过数据预处理模块,把爬取的中文文本进行预处理,去除冗余信息,中文分词,停用词过滤,使用word2vec的skip-gram模型对词语进行向量化处理,最终文本串变成一系列有效的词语集合。
2.评价标准
文章引入了精确率P、召回率R和F1值,对改进的LSTM-CNN整体性能进行衡量。精确率P、召回率R和F1值定义分别为:

将正类预测为正类数,用TP表示;将负类预测为正类数,用FP表示;将负类预测为负类数,用TN表示;将正类预测为负类数,用FN表示。
3.结果分析
实验硬件环境为:服务器戴尔R730 CPU 2颗英特 尔 至 强E5-2 650 v4 2.2GHz,30M缓 存,内存128GB(8*16GB),DDR4 RDIMM,硬盘3块300GB 15K RPM SAS2.5英寸热插拔硬盘,RAID卡1G缓存,网卡2个千兆+4个万兆。客户机CPU Intel Core i7-10 700K 3.80GHz(八核)、内存32GB、显卡Nvidia GeFroce GTX 2060,软件基于Ubuntu 20.04平台,开发环境Anaconda+TensorFlow技术架构环境下进行实验。
(1)不同的优化法对改进的LSTM-CNN模型影响
在NLPCC 2014中文数据集和搜狗新闻分类数据集上,对改进的LSTM-CNN模型分别采用Adam优化算法和传统的SGD算法进行性能对比,得到测试数据上F1值随迭代次数的变化情况,实验结果如图4所示。
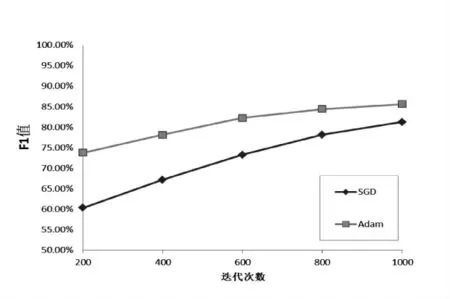
图4 Adam优化算法与随机梯度下降(SGD)算法性能比较
实验结果表明:通过Adam算法最小化目标函数及更新模型参数,进而使网络最优,提升了整个改进的LSTM—CNN模型的性能。
(2)改进的LSTM-CNN模型的收敛性
为了验证改进LSTM-CNN模型的收敛性,在NLPCC 2014中文数据集和搜狗新闻分类数据集上,分别采用改进的LSTM-CNN模型和传统的LSTM-CNN模型进行预测,得到测试数据上F1值随迭代次数的变化情况,实验结果如图5所示。

图5 两种模型迭代次数和F1值的变化情况
实验表明:改进的LSTM-CNN模型为了避开梯度消失问题,采用了softsign函数代替了tanh激活函数;为了解决过拟合问题,采用L1范数和L2范数线性组合的正则化方法来惩罚传统的LSTM模型的输入权重,在一定程度上提高了传统的LSTM-CNN网络的收敛速度和效果,并提高了传统的LSTM-CNN预警精确率。
(3)五种模型性能比较
为了验证改进的LSTM-CNN方法的有效性,文章在同一数据集上运用SVM模型、LSTM模型、LSTM-RNN模型、传统的LSTM-CNN模型、改进的LSTM-CNN模型分别进行测试实验,并把实验结果进行对比,得到各种模型的精确率、召回率、F1值如表1所示:
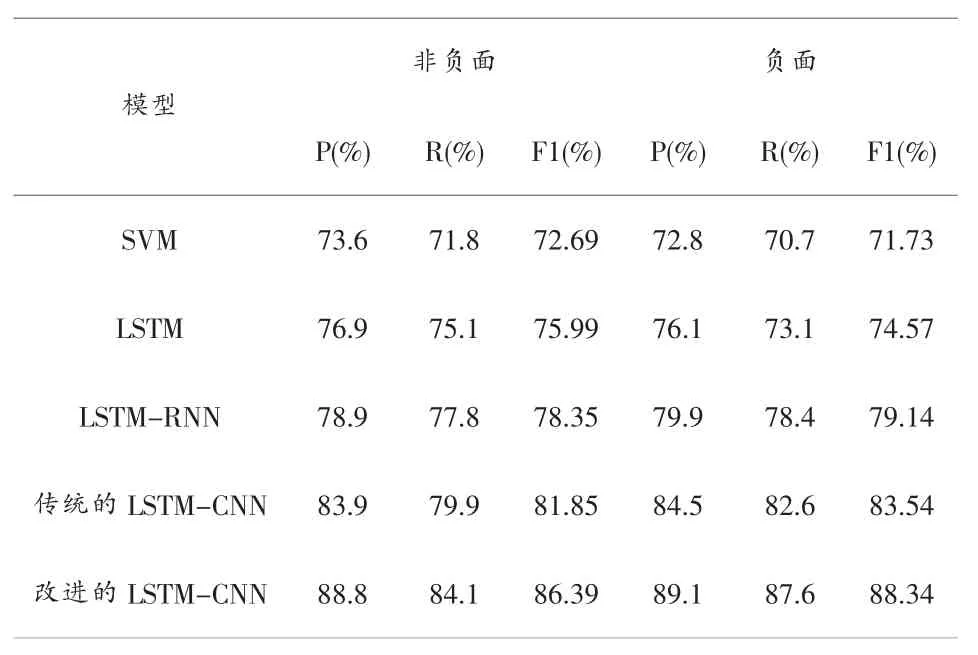
表1 五种分类模型的性能比较
实验结果表明,改进的LSTM-CNN对于非负面情绪的分类精确率为88.8%,召回率为84.1%,F1值为86.39%;负面情绪分类的精确率为89.1%,召回率为87.6%,F1值为88.34%。F1值在非负面情绪和负面情绪的预测结果均高于SVM模型、LSTM模型、LSTM-RNN模型和传统的LSTM-CNN模型,说明改进的LSTM-CNN模型性能优于其它四种模型,因此文章选择使用正则化改进的LSTM-CNN模型作为高校舆情信息的分类模型,分类性能提升显著。
六、结 论
为了对高校网络舆情进行监测,对话题的情感倾向性进行分析,有效地预判舆情发展趋势,本研究首先采用softsign函数代替了tanh激活函数,然后引入L1范数和L2范数对LSTM模型进行正则化改进,对一些因子施加惩罚,以更好地解决神经网络的梯度消失问题和过拟合问题。同时,采用改进的LSTM-CNN模型并对高校网络舆情中文本情感倾向进行分类,把网络舆情中的文本情感倾向分为非负面情绪和负面情绪两大类,以达到预警的目的。最后通过实验证明,不论是在非负面情绪语义还是负面情绪语义的上预测,改进的LSTM-CNN模型的各项性能指标相较于其它的几种LSTM模型均有所提升,验证了改进LSTM-CNN模型是有效的。
猜你喜欢
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
数学杂志(2018年5期)2018-09-19 08:13:48
中国校外教育(下旬)(2017年8期)2017-10-30 17:32:36
数学物理学报(2017年3期)2017-07-01 16:18:48
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:06
传媒国际评论(2014年1期)2014-02-27 07:12:12
