
结合协同过滤与隐语义模型的视频推荐策略
2021-12-24 09:29沈正一崔德龙刘晴瑞
湖南工程学院学报(自然科学版) 2021年4期
王 宁,沈正一,崔德龙,刘晴瑞
(湖南工程学院 计算机与通信学院,湘潭 411104)
伴随着移动智能设备的快速发展、通信设备及5G技术的快速普及,如今在移动设备上观看短视频已经成为人们闲暇时休闲娱乐的方式之一.但短视频的推荐结果却面临同质化严重的问题,因此如何提高视频推荐内容的多样化,避免内容同质化,给用户带来更加优质的体验是当今所有短视频平台所面临的主要问题.
协同过滤算法[1]作为一种结构简单的推荐算法被广泛地应用于各类推荐系统中,在1994年作为“信息过滤”[2]被提出研究,又在2002年被Prem Melville[3]称为“协同过滤”并进行了进一步研究.其算法核心是通过寻找集合中最近的“邻居”,并通过用户彼此之间的相似度来提供对于相应物品的推荐.目前则采用启发式或基于模型的协同过滤算法[4-5].
隐语义模型是在文本信息挖掘方面被广泛使用的一种方法,其算法是基于奇异值分解改进而来的[6].现主要用于提取文本中的隐含分类并与其建立关系.本文将隐语义模型与协同过滤算法相结合,通过建立模型找出用户与隐含分类之间所存在的关系以及物品与隐含分类之间的关系,利用隐含分类构建出用户对物品的兴趣信息,结合协同过滤算法进行推荐.实验结果表明通过该模型与协同过滤算法的改进能够较好地改进推荐系统的推荐效果.
1 推荐系统改进
本文通过对推荐系统进行了改进,将其主要分为协同过滤算法、隐语义模型、推荐过程三个部分,分别通过协同过滤算法和隐语义模型产生推荐列表,保证推荐结果的实时性、新颖性和多样性,最后对推荐列表中的内容进行排名,产生最后的推荐结果.
1.1 协同过滤算法
本文选择基于用户的协同过滤算法[7],主要是将用户观看视频的浏览记录作为主要的推荐依据.通过公式(1)再对相同的视频存在过浏览行为的用户之间建立一个相似度矩阵得到用户u,v之间的相似度矩阵U-V:
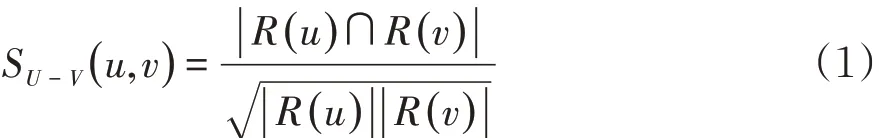
再根据用户v与其所浏览过的视频i建立出一个兴趣度矩阵V-I,通过两矩阵相乘就可以计算出用户u对视频i的兴趣程度:

为了保证对于视频内容的推荐结果具有多样性,因此在协同过滤的基础上需要减少关于热门视频以及相应标签内容对推荐结果的影响.因此通过改进用户之间的兴趣度计算得到公式(3):

通过改进后的协同过滤算法能够有效地减少向用户推荐相同或类似的视频内容,并能较好地增加用户的满意度.
1.2 隐语义模型
伴随人们对视频内容的需求,单一视频内所包含的内容也逐渐趋于多样化,通常在一个视频内会包含多个主题,即具有多个标签.因此若根据单一的标签就无法得到视频所真正具有的特性.本文选择通过隐语义模型分析出视频之间的隐含分类,根据所得到的视频之间的隐含分类再通过用户与视频之间的交互,计算出用户之间的相似度,并得到相应的推荐结果.用户u对视频内容i的喜好程度可以通过公式(4)进行计算:

通过公式计算还需要两个重要的参数P(u,c)和B(c,i),其参数的确定需要根据用户浏览视频的时间长度以及用户对于视频的反馈情况来计算.通过用户物品评分矩阵则可以将用户反馈的这些行为数据通过训练得到我们希望得到的推荐结果.为了减小训练结果的误差,采用公式(5)作为训练的损失函数:

由于学习过程中可能会产生过拟合从而造成计算出来的用户对视频的兴趣程度出现错误,因此对于损失函数,我们还需要加入正则化项:来对损失函数进行优化,最后可以得到公式(6)作为修改后的损失函数:

由于损失函数的复杂程度依然较大,因此仍需要对算法模型进行优化.本文选择了随机梯度下降法[4]来优化算法,求得参数的偏导数:

借助所得到的偏导数,根据随机梯度下降法得到:

将参数沿着最有效的下降方向进行推进.在此基础上只需要不断迭代对参数进行优化,以取得最优的下降步长.
1.3 推荐过程
虽然通过隐语义模型能够得到多样性较好的推荐结果,但由于计算隐语义模型所需要花费的时间较长,因此选择将其与协同过滤算法进行结合以保证推荐效率.首先通过上述的两种算法分别得出相应的推荐结果集.每当用户进行视频的浏览动作后,会在后台根据用户所产生的浏览数据导入隐语义模型并与协同过滤算法产生一个即时的推荐结果,根据权值对兴趣程度进行合并,在此基础上依据视频项目的兴趣程度的排序生成推荐列表.
2 实验结果及分析
2.1 数据集
本次实验通过使用Movielens-1M数据集[8],数据集包含了6040位用户对3900条物品所产生的1000209条观看及评分记录.在实验过程中对数据集以7∶1的比例随机划分为训练集及测试集,对数据集进行多次划分并对划分后数据集进行重复实验,最终将每次划分得到的实验结果取均值作为最终的实验结果.
2.2 度量标准
本文采用了广泛用于推荐系统评测的召回率和准确率作为评测标准[9].其中R为训练集,T为测试集,R(u)为训练集上所产生的推荐结果,T(u)为测试集中用户对物品产生的行为列表.

准确率计算式(11)通过计算符合测试集推荐的结果占训练集的比例,其结果能够较好地反映针对用户的推荐精度.召回率计算式(12)通过计算符合测试集推荐的结果占测试集的比例,反映出推荐系统对相应物品的推荐比例.
2.3 实验结果
为了验证改进后算法的有效性,本文选择基于用户的协同过滤算法以及PersonalRank,PureSVD这几种推荐算法[10]模型进行比较:
从图1中可以看出,四种推荐算法的召回率伴随着推荐项目的增加逐渐上升,从图2中可以看到在召回率上升的同时准确率却随之下降,但总体的下降趋势较缓.在图1中通过融合隐语义模型及协同过滤的算法相较于其他的三种算法伴随着推荐数量的提高,召回率指标有着较好的提升,图2中同样表现出了在召回率提升的同时,准确率也高于其余几种比较算法.

图1 隐语义模型与比较算法的召回率

图2 隐语义模型与比较算法的准确率
图1中当推荐数量较少时即数量在4~10之间,改进后的算法的推荐结果兴趣点过于单一,因此造成了召回率的下降.但伴随着推荐数目的增加,即当推荐数目增加到10左右时,通过隐语义模型的数据逐渐增强,推荐的召回率相较之前以及其余的推荐算法有所提高.
除此之外,隐语义模型中负样本的选择数目对于本文算法也存在影响,伴随着视频的负样本数目增加,改进后算法的召回率及准确率会呈现出先增后减的趋势,如图3所示.同时当数据集中的用户与物品的交互较少时,改进后的算法性能同样会出现下降.

图3 负样本对改进算法的召回率与准确率影响
总的来说,如表1所示改进后的算法与经典协同过滤算法、矩阵分解算法相比,推荐性能还是有所提升.因此在协同过滤算法的基础上通过引入隐含语义模型能够有效地挖掘出用户对于物品兴趣的隐含信息,并能够有效地提高推荐系统的推荐质量.

表1 改进后算法与比较算法的平均推荐性能指标
3 结论
本文通过融合在文本信息挖掘中广泛使用的隐语义模型与协同过滤算法,改进推荐系统,改进后的算法通过深度学习对用户相似度以及物品的兴趣度上进行数据分析,总体上优化了协同过滤算法中用户对物品兴趣度的计算精度.
当前深度学习发展迅速,同时其在信息的处理上也显现出了巨大的优势,通过与推荐系统的结合,利用神经网络提取出用户的相关兴趣,并对其进行预测,通过学习算法优化最后的推荐结果并排序,能够有效地提高用户对推荐系统的满意度.在未来的推荐系统的研究中应当更好地结合相关技术的发展,融合各种方法及思路来改善并促进推荐系统的发展.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(低年级)(2022年5期)2022-05-31
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
疯狂英语·初中天地(2021年11期)2021-02-16
健康体检与管理(2021年10期)2021-01-03
开放教育研究(2020年2期)2020-03-31
少年漫画(艺术创想)(2019年2期)2019-06-06
长江学术(2016年4期)2016-03-11
