
出租车司机载客点推荐算法
2021-12-24 13:45许春晖张安勤
上海电力大学学报 2021年6期
许春晖, 张安勤, 陈 钰
(上海电力大学 计算机科学与技术学院, 上海 200090)
城市的发展使得市民对出行的便利、速度的要求随之提升。对于城市交通而言,出租车司机能快速地接到顾客,可有效缓解交通问题,提高市民对城市交通的满意度。对于出租车司机而言,准确找到乘客多的地方可以接到更多的顾客,收入也会相应增加。
出租车轨迹具有时空特征。冯琦森[1]利用出租车GPS轨迹数据分析识别居民感兴趣的热点路径和区域。张俊涛等人[2]提出了一种基于高斯定律的轨迹挖掘方法,发现城市居民出行行为的时空特征以及城市的热点区域。马云飞[3]利用空间聚类算法对出租车轨迹点数据进行时空数据挖掘,获取其隐含的出行规律信息。SUN J等人[4]开发了一种新的基于聚类的方案,可以利用基于轨迹和道路特征的多源信息来推荐出租车取车点。ZHU W等人[5]通过对各种交通影响因素的综合,以保证接驳点的设置与实际交通状况适应。
城市的变化在时间的分布上具有周期性,在空间的分布上也具有一定的规律。MAO F等人[6]提出城市居民的出行在时间上具有一定的周期性,在一天的完整时刻表上具有上下班高峰时间,也有深夜的交通流低谷时间。在工作日与休息日,城市居民的主要出行活动也不同。在空间上,QI G D等人[7]初步考虑了3个典型的类别区域,通过出租车轨迹分析可以很准确地分析出该区域出租车数量和社会活动模式。
出租车空间轨迹的聚类有不少难点。仅基于密度的聚类方法不能准确地反映出出租车轨迹在空间上的分布,出租车在城市中心与城郊地区的分布密度有较大差异,密度的阈值较难设定。每个地区可以是城市居民的出发地也可以是目的地,而吸引力值仅能反映地区作为目的地的出租车流量。此外,城市道路情况分布较为复杂,广场、停车场、高架道路等均会造成错误的数据统计。
在现有的出租车载客推荐算法中,鲍冠文等人[8]提出改进的DBSCAN(Density-based Spatial Clustering of Application with Noise)密度聚类算法,用于出租车载客热点区域挖掘,但要用A*寻路算法搜索最短路径,开销较大,且领域范围大小会对更大范围、更好载客点的推荐造成影响。针对这些问题,魏为民等人[9]提出了一种改进的A*+算法,即在原有算式上添加父节点启发式,并计算临界值筛选候选节点,从而使节点排查能力得到优化,搜索效率得到提高。张明月[10]提出了一种基于时空聚类的出租车载客推荐地点生成方法,但在推荐热点地区时,仅考虑了吸引力,存在一定的问题,因大多数情况下,吸引力高的区域往往是乘客下车的地方而不是载客的最佳地点。ZHENG L J等人[11]利用基于网格密度的GScan聚类算法对时空热点区域进行分析与挖掘,但基于密度的热点区域挖掘不能反映市民对出租车的需求分布。
针对上述问题,本文提出了基于时空数据挖掘的出租车司机载客点推荐算法。该方法对城市热点区域进行聚类,同时计算某一地区的人口流入量与流出量。流出量表明该地区的人搭乘出租车的概率,与流入量相比,具有更高的推荐价值。然后对出租车司机的日常活动范围进行分析,推荐载客点。
1 基于HITSK的热点区域聚类算法
HIST(Hypelink-induced Topic Search)[12]算法是子集传播算法的代表算法,通过Authority和Hub这两个权值对网页的质量进行评估。其中,Authority指的是内容权威度,即页面被引用的次数;Hub指的是链接权威度,即指向其他页面的数量。K-means[13]算法是使用最广泛的基于划分的聚类算法,通过把n个对象分为k个簇使簇内具有较高的相似度。HITS-K算法是基于改进的HITS算法与K-means算法组合而来的。
现有热点地区算法大多数基于地区吸引力,这对于人口流动统计来说不够准确。本文通过改进的HITS算法计算地区的交通流量值TF,挖掘出交通热点区域与潜在的交通枢纽。
1.1 算法描述
首先将地图进行划分。针对具体区域从经度和纬度上进行网格划分,在地图上将经度和纬度划分成等长区间。对每个网格记录下4个顶点的经纬度坐标,实现地图网格化。
将OD点与地图网格进行对照来聚类计算,将所有的OD点划分到相应的地图网格中,并将每个网格作为聚类,根据聚类中OD点的个数计算每个网格对应的人的流出值。SumiO=|O|表示在地区i中O点的个数,代表从该区域流出的人数。SumiD=|D|表示在地区i中D点的个数,代表从该区域流入的人数。
在网格聚类划分的基础上进行改进的HITS算法。每个网格取初始值为Authority(i)=SumiD,每个网格所占的D点数反应了网格所在地区的初始Authority值。以每个网格依次为起点,统计该网格到其余每个网格(除本网格外)的人数Ni,j,Ni,j表示地区i到地区j的人数。其中,i=1,2,3,…,n;j=1,2,3,…,n。
(1)
计算每个地区的Hub值,每个网格取初始值为Hub(i)=sumiO。每个地区节点新的吸引力Hub值为
(2)
每一步计算完 Authority和Hub后,对其进行规范化。公式为
(3)
(4)
(5)
(6)
Authority代表地区人口流入量;Hub代表地区人口流出量,所以地区的完整TF值是将Authority值与Hub值相结合,为
TF(i)=Authority(areai)+Hub(areai)
(7)
式中:TF(i)——地区i的交通总流量值。
最后,将迭代后的数据结果记录下来,作为地区对地区的完整TF值,利用K-means算法对地区吸引力值进行聚类。
2 出租车接客点推荐
不同的出租车司机驾驶模式不同,同一个出租车司机每天的活动轨迹也不相同。但大多数时间他们会在自己较为熟悉的区域活动。为了将出租车司机的日常活动核心区域挖掘出来。我们使用标准差椭圆[14]来描述出租车司机的活动轨迹。
计算轨迹中心位置的公式为
(8)
式中:xi——第i个轨迹坐标的经度;
yi——第i个轨迹坐标的纬度;
n——轨迹点个数。
计算标准距离偏差的公式为
(9)
计算椭圆的偏转角度的公式为
(10)
(11)
(12)
(13)

计算椭圆长短轴长度的公式为
(14)
(15)
将不同日期的出租车司机活动范围重叠,选择最大椭圆作为其日常活动范围。根据出租车司机的空间活动模式,选取推荐载客点。由于城市中不同区域具有不同的功能分区,在不同的时段人们在不同的功能分区中移动。我们将不同时段的热点地区进行聚类分析。首先计算每一类热点区域到出租车司机日常活动范围的距离,取出每一类热点区域聚类中前10个距出租车司机日常活动范围距离最短的区域。对于挑选出来的区域判断其Hub值。Hub值越高,代表上车的人数越多。
3 实验分析
3.1 数据格式
本文采用上海市出租车GPS数据。上海出租车GPS数据包含约5万辆出租车的数据,每辆车约隔1 min做一次记录。其中,从2014年12月28日至2015年1月10日的上海出租车GPS原始数据有91.4 G,数据字段格式如表1所示。
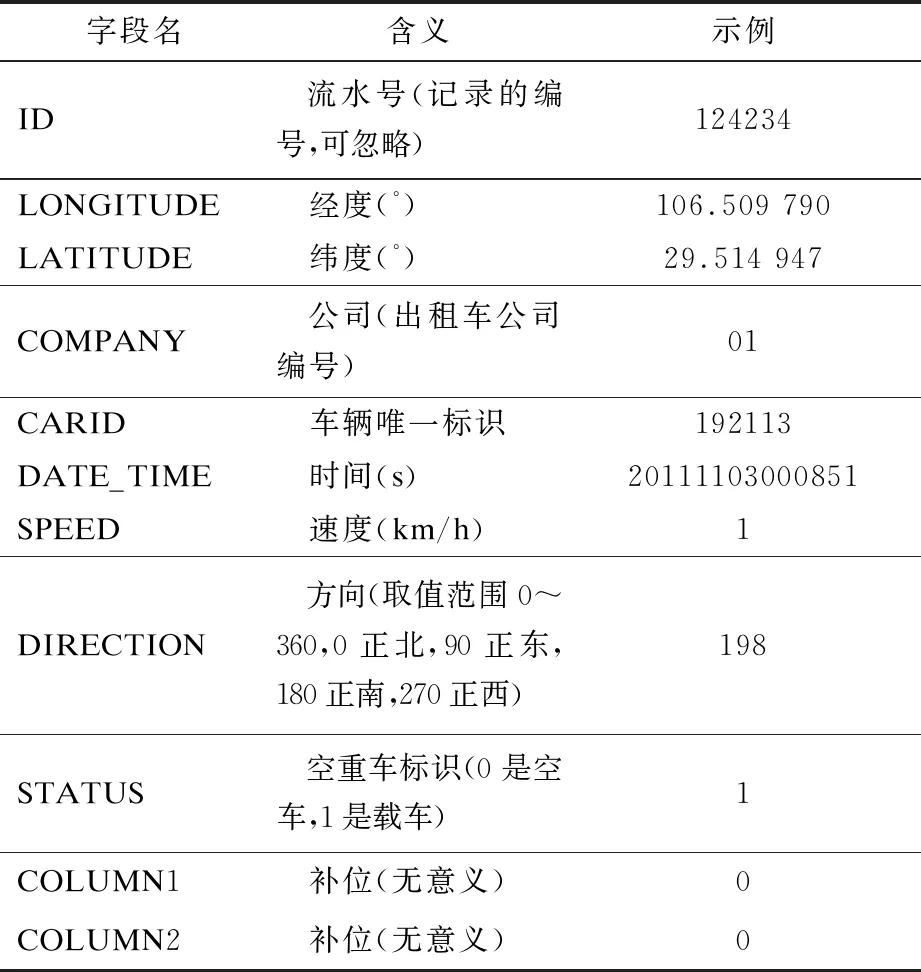
表1 数据字段描述
3.2 预处理
实际的GPS数据包括由交通与人为因素造成的异常点与冗余数据,不能直接用于轨迹数据的分析与挖掘。因此,需运用Spark对数据进行预处理。Spark 是一个分布式平台,支持规模较大数据的快速处理。它既可以在一台机器上运行,也可以协调在多台机器上进行数据处理,符合需要支持任意数据规模的要求。在预处理中,Spark的排序语句对出租车ID和时间两个维度进行排序;用过滤功能与判断语句将经纬度不在上海市区的出租车轨迹进行筛选,对停留时间较长的出租车轨迹进行判断与删除;最后用Scala算法将OD点与原始数据集合分离。处理的步骤如下。
(1) 记录中的GPS数据在出租车ID和时间两个维度上进行数据排序。
(2) 对经纬度数据越界进行处理。本文以上海市辖区为研究对象,不在此地理坐标范围内的记录予以去除。
(3) 对在一个地点停留太多时间的GPS数据进行删除。
(4) 去除出租车ID、经纬度和记录时间外的数据,减少数据的维度。
(5) 对数据中的OD点数据进行分析,出租车轨迹中间数据与OD点需要分离。
预处理后OD点数据与中间轨迹数据分离,OD点数据有4.28 G。
3.3 地区吸引力值聚类
对于东经120°51′到122°12′,北纬30°40′到31°53′的上海地图,将其经度和纬度划分成等长的小区间,每个栅格经纬度之间的差为0.02,将经度划分成68个区间,纬度划分成60个区间,共计4 080个地区。记录每个网格下4个顶点的经纬度坐标。地图栅格化效果如图1所示。
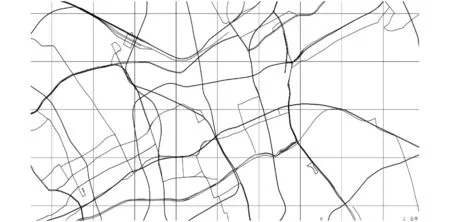
图1 地图栅格化效果
地图栅格化后,将OD点与地图网格对照进行聚类计算。如果O点在以4个经纬度坐标形成的四边形中,则将它们聚类在一起。所有的OD点划分到相应的地图网格中,每个网格作为一个聚类,根据聚类中样本的个数计算每个网格的吸引力值。得到的聚类结果如图2所示。图2中,白色的点O表示该栅格中原有人数,黑色的点D表示该栅格为终点。
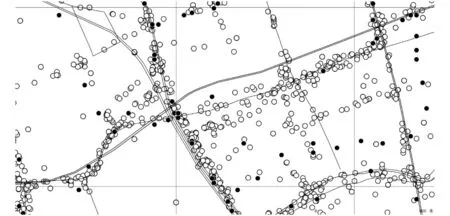
图2 聚类结果示意
通过HITS-K算法对地区吸引力值进行计算,对计算结果进行聚类,图3展现了聚类后的地区分布。图3中不同颜色的点表示不同的簇。地图上簇的分布具有规律,吸引力值由城市中心向郊区递减,最外层的吸引力最弱。一些场所虽远离市中心却依然人数较多,如机场、桥梁或隧道出入口。这符合城市的空间布局。

图3 热点地区聚类分布
图4是出租车司机a的日常活动范围的模拟图。由图4可以看出,出租车司机a的日常活动路线为城市的市中心区域,那里道路较多,人流量也相对较大。
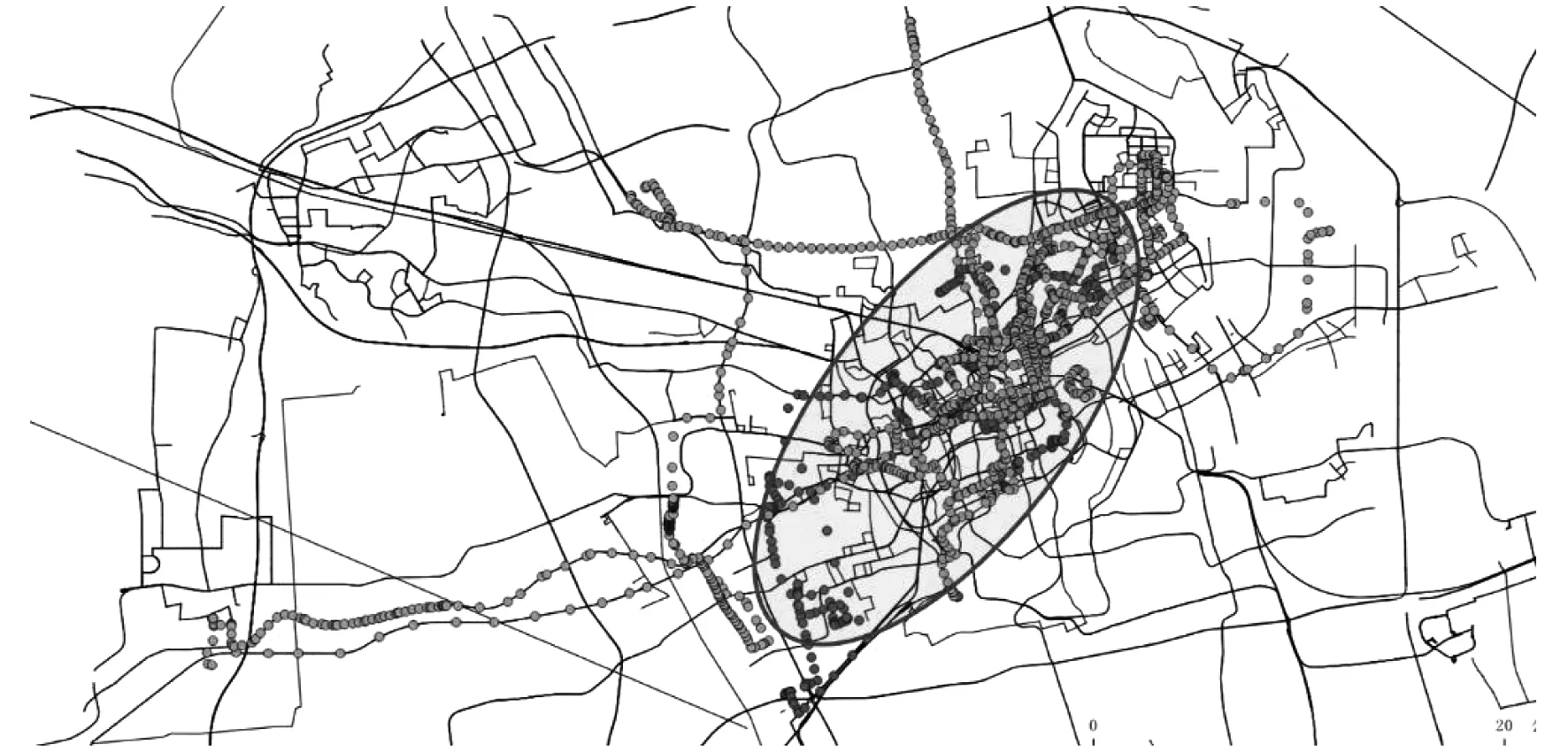
图4 司机a日常活动核心范围模拟
结合本文算法,出租车司机a在早上与下午的推荐活动范围分别如图5和图6所示。
图5 早上推荐载客点

图6 下午推荐载客点
由图5和图6可知,早上市民的主要活动方向为从住宅到工作区。虽然这段时间内市中心与周围的居民区都是热点区域,且市中心的人口密度更大,但是人们大多是在市中心下车,上车的人相对较少,故不推荐在市中心搜寻顾客;而在推荐右下角的区域中,出租车司机a几乎不去,实际上该区域同样有顾客需要搭乘出租车。
下午市民需要从工作区返回居住区,或从工作区去娱乐区。在上海,娱乐区与工作区的城市功能分区不明显,都集中在市中心。相比周围的居民住宅区,娱乐区与工作区在这段时间的人流量较大,所以下午的推荐区域在市中心附近。
图7是在出租车司机载客点挖掘方法中常用的传统DBSCAN聚类方法。从图7可以看出,出租车司机的推荐载客活动点同样是集中在市中心区域。在离市中心较远的区域也有推荐,但该区域远离出租车司机的日常活动点,司机不太可能偏离日常活动轨迹去一个较远的地方载客。在市中心外围有一圈细长的推荐带围绕,这些区域的载客点相互距离较远,分布较稀疏,它们本来不应该被推荐,但DBSCAN将他们聚类到一起形成一个较大的簇,对推荐造成了误差。此外,DBSCAN方法的各个参数设定没有依据,不同的参数结果不同,对最终推荐结果会有不同的影响。
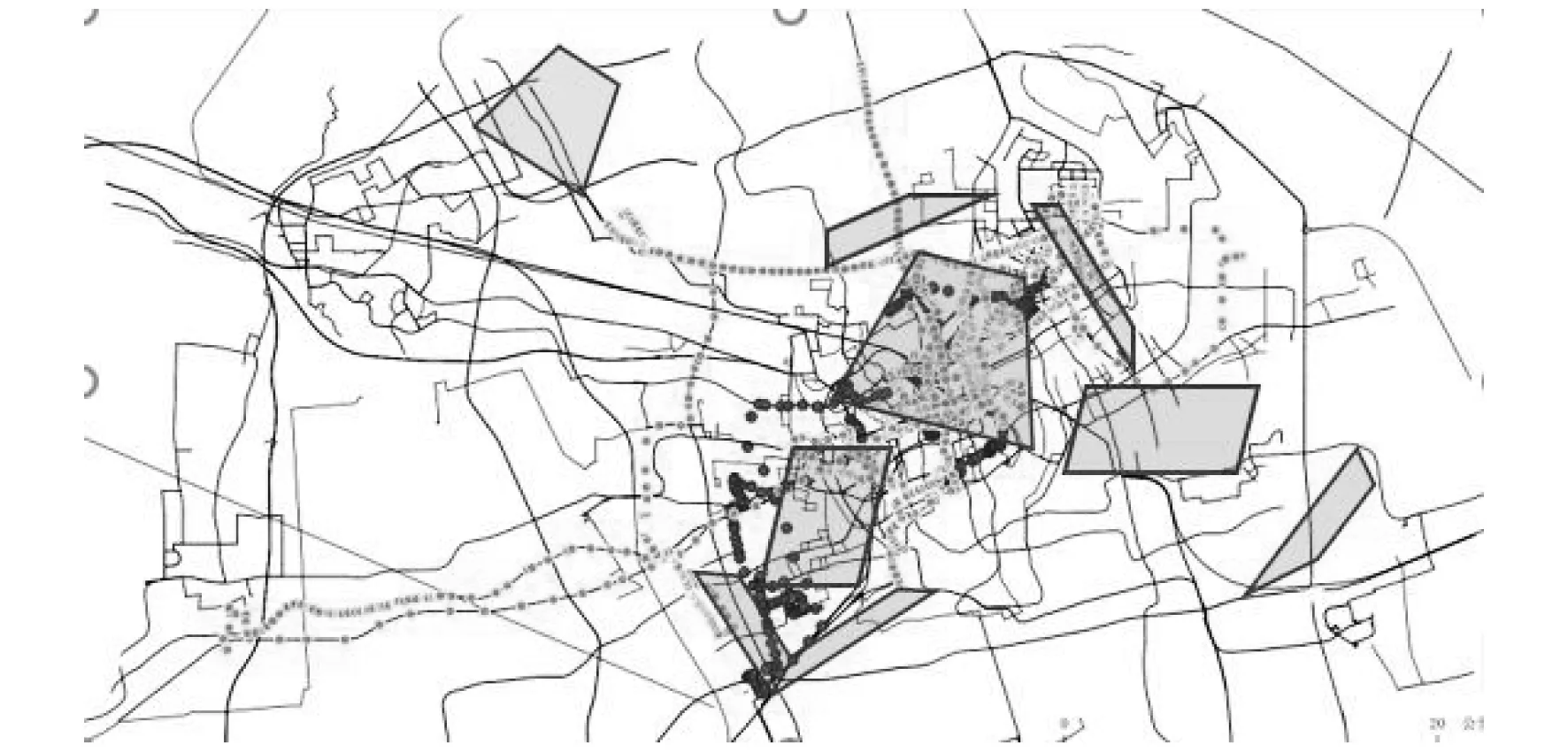
图7 DBSCAN推荐载客点
4 结 语
针对传统DBSCAN方法的不足,本文提出了基于时空数据挖掘的出租车司机载客点推荐算法。首先,通过使用Spark对城市路网信息、出租车轨迹数据进行预处理;其次,通过HITS-K对具体地区进行交通热点地区聚类,充分体现人口流动在时间和空间维度上的变化;再次,用标准差椭圆对出租车司机的日常活动范围进行分析;最后,根据热点区域聚类与热点区域中的Hub值对特定的出租车司机进行载客点推荐。与传统的DBSCAN方法相比,该方法在司机日常活动核心区域周围挖掘出了司机不经常去的推荐载客点,证明了方法本身的有效性。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
商用汽车(2021年4期)2021-10-13
数学小灵通·3-4年级(2020年10期)2020-11-10
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
今古传奇·故事版(2017年24期)2018-02-07
北京航空航天大学学报(2016年7期)2016-11-16
山东青年(2016年1期)2016-02-28
汽车观察(2016年3期)2016-02-28
太空探索(2015年5期)2015-07-12
