
基于区块多源时空数据的道路网密度预测模型
2021-12-23 04:38:38黄士琛邵春福王晟由
北京交通大学学报 2021年5期
黄士琛,邵春福,王晟由
(北京交通大学 交通运输学院,北京 100044)
城市蔓延是区域在城市化进程中产生的无序扩展现象,影响了区域的可持续发展,从而引发各领域学者的广泛关注.人口增长、交通发展与城市蔓延之间具有密不可分的关系[1].文献[2]认为道路建设里程的增加虽然促进了经济发展,但同时作为催化剂引发了交通拥堵和城市蔓延.文献[3]发现道路网络的扩展会导致城市人口密度降低,中国城市环路的综合效应引起25%的居民从中心区向周边地区迁移. 文献[4]经过分析得出道路网密度是影响城市机动车出行与网络分析的重要指标.以上研究均表明城市蔓延和道路网之间具有相互演化规律.近年来,随着电子数据收集存储技术的不断成熟,连续数年纪录的公开土地覆盖和道路数据不断涌现,为人口、土地类型变化和道路网密度相互作用的研究提供了数据支撑.在研究交通与城市蔓延问题时,目前在两方面仍存在瓶颈,即如何将土地覆盖和道路等多源数据进行融合以及如何构建并标定可靠的预测模型,对城市蔓延与道路网时序下的演化规律进行解释.
深度学习作为大数据分析的关键技术,由于其准确率高,在图像与语音识别等领域取得重大成果,文献[5]在ImageNet数据集上训练了7层的CNN用于图片分类并取得较高精度.LSTM在自然语言处理、语音处理等时间序列方面展现了较强的竞争力. 文献[6]为加快收敛过程,降低调参难度,发明了批量标准化层. 文献[7]利用深度信念网络DBN进行短时交通流预测,通过交通流量的特征进行无监督学习,而后完成流量预测任务.文献[8]构建了STGCN模型,在短时交通流预测方面运用图卷积神经网络,在多种尺度下的交通网络数据集上得到较高精度.文献[9]提出STLSTM-PDP深度学习模型,成功用于民航客运需求与出租车客运需求预测,结果表明该模型优于现有预测方法.文献[10]将共享汽车的OD点作为输入,使用深度学习模型来预测共享汽车的需求.文献[11-12]将CNN运用在民航需求预测任务并取得了较高精度. 文献[13-14]将深度强化学习和DQN算法用于交通信号灯控制领域,即神经网络在得到信号灯与环境互动产生的奖励后,不断更新参数使更多机动车安全通过交叉口.文献[15]使用BiConvLstm模型检测视频中的暴力行为.文献[16]将卷积层结构代替长短时记忆神经网络中的全连接层,设计了卷积长短时记忆神经网络进行降雨量的预测.综合分析可知,目前道路网密度演变机理的研究较少,还没有对CNN和LSTM在道路网密度辨识与预测方面的适用性进行研究.
为研究大数据背景下的交通与城市蔓延之间的演化机理问题,采用深度学习中的关键技术,综合考虑人口、交通与城市蔓延的关系,对城市蔓延步伐和交通基础设施建设进度进行调控. 本文作者尝试将卷积神经网络(Convolutional Neural Networks,CNN)和长短时记忆神经网络(Long Short-term Memory,LSTM)等方法运用于道路与城市蔓延问题.本文的创新之处在于,设计基于区块的多源数据集融合方法与流程,将用地覆盖、人口和道路网络三种数据集融合成为时空数据集.在此基础上,构建融合时空数据的BiConvlstm2DNet深度学习模型,采用时间标签下的土地覆盖数据和人口数量表征城市蔓延过程,对未来年的道路网密度进行预测.研究可使规划者精细掌握城市蔓延和交通指标之间的演化规律,形成更为协调的道路建设进程,对防止城市过度蔓延具有重要的理论支撑和数据参考作用.
1 多源数据集构建
在收集多源数据的基础上,如图1中的基于区块的数据融合部分所示,本文通过区块确定和分割得到不同年份土地覆盖及人口融合数据.
1.1 数据准备
为了验证本文提出的处理时空序列数据的BiConvlstm2DNet模型,采集了深圳市的相关数据.其中数据分为网格化的土地覆盖数据集[17]、世界网格化的人口数据集(GPWv4)[18]和Openstreetmap[19](OSM)道路网开源数据集,其中土地覆盖数据集为2008年、2011年和2013年,GPWv4数据集的时间跨度为2000—2020年每隔5年,OSM路网结构数据集的时间跨度为2008—2019年每隔1年.土地覆盖、人口和道路网密度,三者共同组成本文的实验数据,详细信息如表1所示.
土地覆盖数据集通过landsat5和landsat8采集了1988—2015年精度为30 m的遥感图像,而后使用C4.5决策树提升算法将遥感图像分割为森林、草地、耕地、高反射率建成区、地反射率建成区、空地和水体,形成了深圳市土地覆盖数据集.
GPWv4通过采集人口调查数据,联合国人口估计数据等,构建了2000、2005、2010、2015和2020年全球网格化的人口数据集,采用比例分配网格算法并结合联合国人口数据进行调整,将人口数量分至30弧秒(赤道约1 km)的网格单元.
OSM数据集的结构由点、边、关系和标签组成,具有数据来源丰富,容易获取,接口开放等优点,本文通过OSM提取切分网格化的路网结构,而后根据数据集需求计算道路网密度.
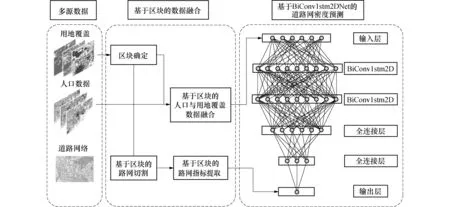
图1 基于区块多源数据的神经网络模型构造过程Fig.1 Construction process of neural network model based on blockbased multi-source data
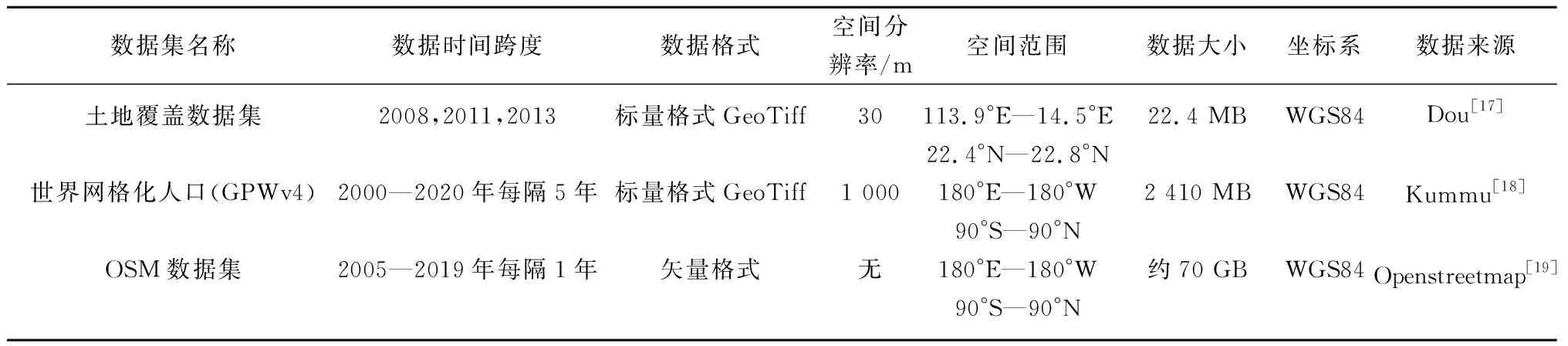
表1 多源数据集的详细信息
1.2 数据融合
空间数据集需将同一地区不同来源的专题数据,采用不同的方法进行重组,补充要素属性的同时改进其精度,调整多源数据在不同尺度和要素粒度下的差异.本文根据来源不同的3种数据源进行清洗融合,制作成适合本文的数据集.研究分析3个数据集的时间跨度,以土地覆盖数据集的2008年、2011年和2013年为基础划分区块,并根据GPWv4以插值的方法计算区块在对应年份的人口数量,最后通过OSM提取2015年的深圳市道路网络结构并计算对应区块的道路网密度.

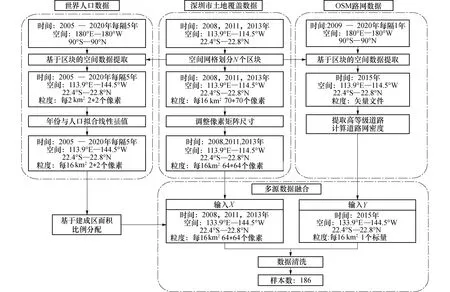
图2 多源数据集数据融合流程Fig.2 Data fusion process for multi-source dataset
2 BiConvlstm2DNet神经网络模型
如图1中的道路网密度预测部分所示,本文提出了BiConvlstm2DNet模型.模型以LSTM为基础,为构建空间结构关联性,加入卷积层设计了BiConvlstm2D模块,并将该模块与其他神经网络组件相结合得到BiConvlstm2DNet模型.
2.1 BiConvlstm2D各组件模型
1)全连接层.
全连接层(Dense)是传统BP神经网络中的隐含层,隐含层接收上一层输出的特征,并通过矩阵运算和非线性函数映射后的结果输出给下一层,同一层的单元之间无连接.对于全连接层的输入x∈Rn,根据式(1)实现全连接层:
z=σ(W*xΤ+b)
(1)
式中:W∈Rm×n;b∈Rm;z∈Rm;σ是非线性激活函数,全连接层是一个经典的神经网络模型.
2)卷积神经网络.
CNN设计了权重共享的卷积核,通过中、低层的卷积核提取图像的简单特征,深层卷积核整合低层卷积核的输出提取更加复杂的特征.本文设定卷积核的大小为3*3,每个CNN使用非线性函数Relu作为激活函数.最后为防止过拟合在卷积层后增加Dropout层,设定百分比r,训练时随机忽略r的节点,增强模型泛化性,测试时则使用全部节点.
3)长短时记忆神经网络.
LSTM设计了输入门i,遗忘门f和输出门o共3个门函数,用于更新整个单元的状态,为保证特征的留存和传递,LSTM将t时刻的xt和t-1时刻的状态ht-1经过全连接层的映射后,输入到3个门函数进行运算,而后得到t时刻的输出ot、状态ht和ct,如下
it=σ(Wxixt+Whiht-1+bi)
(2)
ft=σ(Wxfxt+Whfht-1+bf)
(3)
ot=σ(Wxoxt+Whoht-1+bo)
(4)
ct=ft⊗ct-1+it⊗
tanh(Wxcxt+Whcht-1+bc)
(5)
ht=ot⊗tanh(ct)
(6)
式中:Wxi,Whi和bi分别为输入门i中用于训练的参数;Wxf,Whf和bf分别为遗忘门f中用于训练的参数;Wxo,Who和bo分别为遗忘门o中用于训练的参数;Wxc,Whc和bc分别为状态函数c中用于训练的参数;⊗代表Hadamard积.
4)卷积长短时记忆神经网络.
Convlstm2D以LSTM为基底,将输入到隐藏与隐藏到隐藏的映射函数从全连接层改为卷积层,减少了参数数量的同时获得了更好的泛化性.同时为取得更优的训练及测试效果,本文在Convlstm2D层后均接入批量标准化层.向模型输入的xt,ct和ht-1均是三维张量,基于Convlstm2D映射后输出的it,ft和ht也是三维张量.Convlstm2D使用卷积层提取输入数据的空间特征,而后结合LSTM结构将数据整合过滤,Convlstm2D卷积式见式(2)~式(6)所示,只需将⊗运算替换成卷积层即可.
2.2 BiConvlstm2DNet模型设计
当输入数据为2维的空间数据时,为适应LSTM结构,迫使数据维度从2拉伸成1从而丧失了空间上的关联.因此本文选用Convlstm2D网络,使模型既能提取数据的空间特征,也保证神经网络具有一定的记忆能力.此外,单向的LSTM只考虑了时序数据的“顺序”流动而没有考虑“逆序”流动,如同在交通规划中规划者不仅需要考虑道路基础设施的建设能力,也需要回顾目前政策下的发展惯性.因此如图3所示的BiConvlstm2D模块,引入了双向(Bidirectional)循环神经网络规则,将时间-空间序列数据以序列起点至终点的顺序采用Convlstm2D提取特征,也反方向地,即序列末尾至起点的顺序提取特征.BiConvlstm2D双向提取序列数据的特征,考虑城市发展能力的同时还考虑现有政策对城市发展的“态度”.
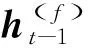
(7)
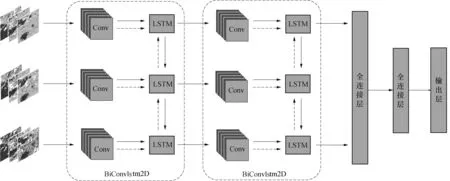
图3 BiConvlstm2DNet神经网络模型结构 Fig.3 BiConvlstm2DNet neural network structure
根据BiConvlstm2D模块和其他模块搭建BiConvlstm2DNet模型,图3为BiConvlstm2DNet的核心组件.模型输入为[ti,ti+1,…,ti+k]时刻的土地覆盖特征和人口数量,其中k为时间窗口,利用模型预测i+k+1时刻的道路网密度.模型由多个BiConvlstm2D层、池化层、标准化层和全连接层堆叠形成,详见表2.表2中,ksize表示卷积核大小,knum表示卷积核数量,dnum表示全连接层单元数量.BiConvlstm2DNet模型以[k, 64, 64, 3]张量作为输入,经过2个BiConvlstm2D层,标准化层Normalization,并辅以Dropout层避免过拟合,而后经过两个全连接层抽象特征,最后接入线性激活函数Linear进行回归预测,其中初始化使用Glorot正态分布初始化,偏置初始化至标量0.
单张融合人口数量后的用地覆盖数据被抽象为64*64*1的矩阵,本文通过图4来描述数据是以何种尺寸在模型中流动.根据表2和图4可以知道,卷积层使用卷积核提取与卷积核个数相等的特征(64*64*1-64*64*8),而后通过池化层压缩特征维度(64*64*8-32*32*8),LSTM不影响输入的尺寸,只用于处理时间序列下的用地覆盖特征(图4描述单张用地覆盖数据的尺寸转换).数据在经过两个BiConvlstm2D模块的映射后,将数据接入两个全连接层,将数据从4096(16*16*16)降维到256和64,最后连接线性输出给出模型的结果.

表2 BiConvlstm2DNet网络结构Tab.2 BiConvlstm2DNet network structure
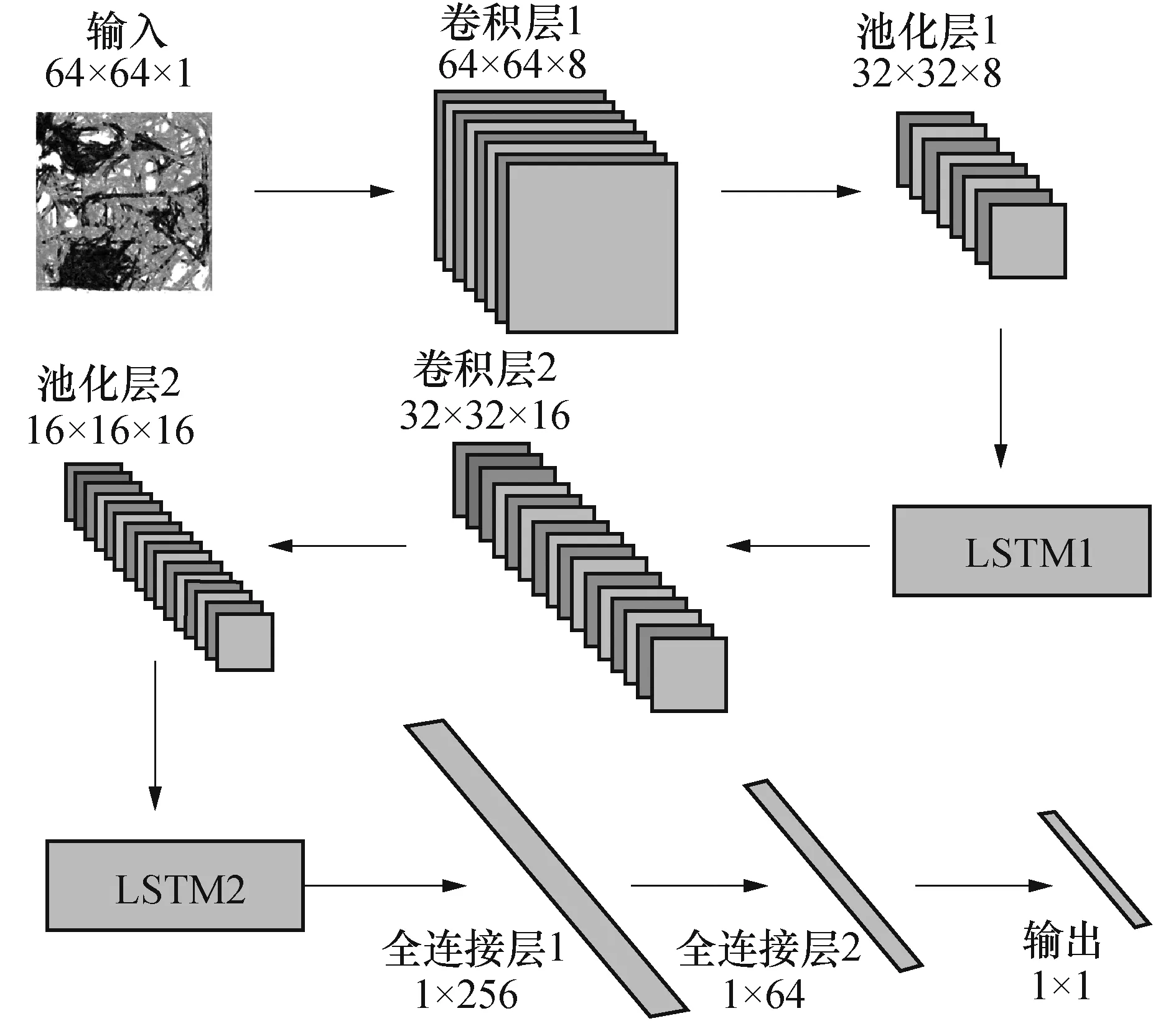
图4 用地覆盖数据在 BiConvlstm2DNet中的尺寸变化Fig.4 Dimensional changes of land cover data in BiConvlstm2DNet
3 预测结果评价及分析
BiConvlstm2DNet模型基于Tensorflow和Keras实现,两者集成了现今流行的深度学习框架,本文在英特尔酷睿i7年7700HQ,32GB内存和NVIDA GeForce GTX 1060的计算机上实验.BiConvlstm2DNet模型采用均方误差MSE作为损失函数L用以标定模型参数,如下
(8)

神经网络利用反向传播方法计算梯度更新神经网络的参数,本文使用随机梯度下降法(Stochastic Gradient Descent,SGD)优化神经网络.为综合考量模型的可靠性和准确性,本文选取平均百分比误差MAPE和平均绝对误差MAE两个指标进行度量,指标衡量预测值偏离真实值的误差,如下
(9)
(10)
式中:MAPE误差代表预测值和观测值之间的相对偏离程度;MAE误差表示所有测试样本的预测的实际误差,两者均为越小表示模型越精确.
在机器学习预测实验中,模型的精度不仅受模型结构设计的影响,还与超参数的选择密切相关.如果BiConvlstm2DNet模型的超参数设置不当,致使精度低于预期,严重时会使模型失效,而研究工作中并没有明确建议,本文通过网格搜索比选超参数.训练集损失值随迭代次数的变化曲线如图5所示.
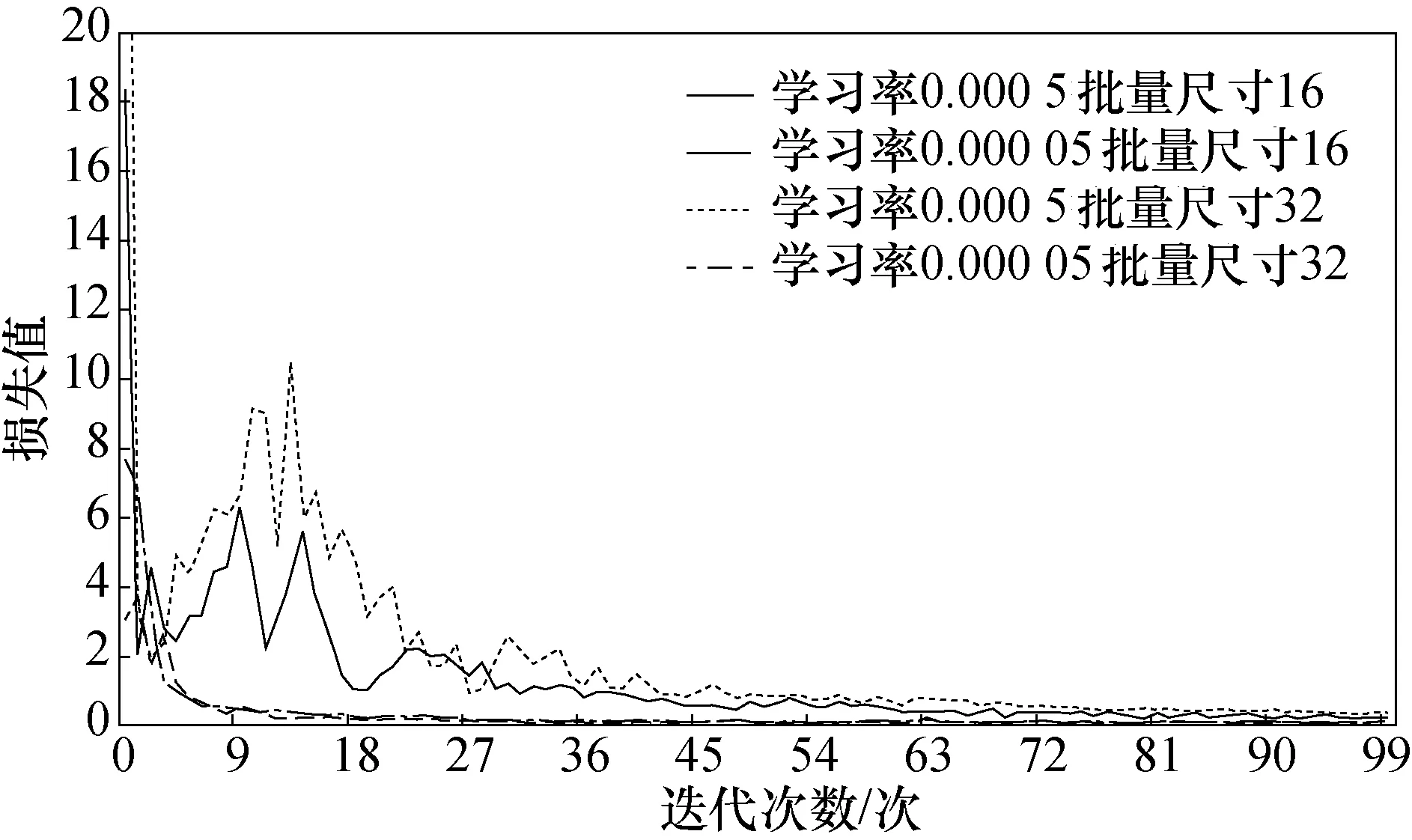
图5 BiConvlstm2DNet不同超参数下 模型训练损失值Fig.5 Model training loss of BiConvlstm2DNet under different hyperparameters
本文采用随机梯度下降法,动量设定为0.99[20],迭代次数epochs为200,测试了学习率、批处理大小在训练过程中的损失值.由图5可知,训练开始损失值较高,迭代次数在40次之前均有起伏,其中学习率为0.000 05的模型损失值下降较快且平稳,模型在迭代次数100次以后基本收敛,说明了模型的有效性,而学习率为0.000 05且批处理大小为16和32时收敛速度和效果俱佳.
为对比本文提出的BiConvlstm2DNet模型,选用三种模型进行比对,其中支持向量回归和随机森林回归是比较经典的机器学习算法,Convlstm2D模型超参数设定同BiConvlstm2DNet模型一致.
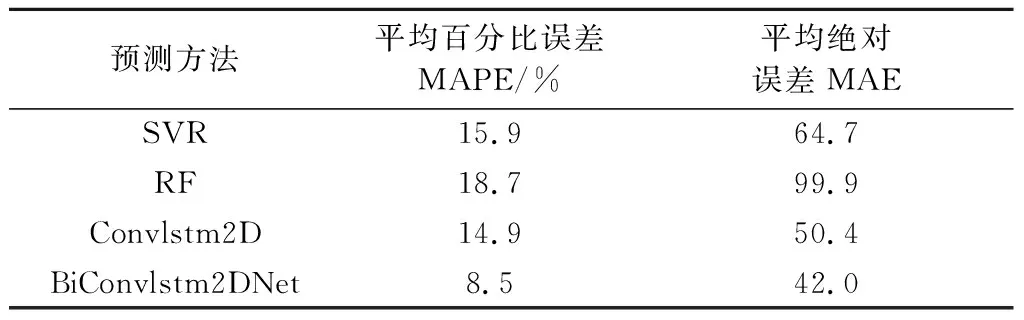
表3 四种机器学习算法在多源数据集上 效果指标对比Tab.3 Metrics comparisons of 4 machine learning algorithms on multi-source dataset
由表3可知,4种机器学习算法在测试集上的结果表明,随机森林回归误差最大,本文提出的BiConvlstm2DNet模型误差最小,MAPE为8.5%.由于支持向量回归和随机森林回归没有提取空间特征,两种算法的误差较高,Convlstm2D和BiConvlstm2DNet的卷积层对空间信息进行留存和提炼,进而提升了模型精度.BiConvlstm2DNet在加入了前向和逆向单元后,相比Convlstm2D模型,MAPE降低了6.4%,模型精度提升明显.
为分析模型在不同道路网密度下的预测性能和精度,将不同道路网密度的地块分成为5类后计算平均百分比误差MAPE,该值越低则说明模型的准确度越高. 如表4所示.

表4 BiConvlstm2DNet模型在不同类型 区块上的准确度对比Tab.4 Accuracy comparison of BiConvlstm2DNet model on different types of blocks
道路网密度为3 km/km2以下和12 km/km2以上的样本数量较少,模型在测试道路网密度在3 km/km2的地块时的准确度最低,在6~9 km/km2的精度最高.相较于表3中测试集下BiConvlstm2DNet模型8.5%的MAPE,模型对道路网密度6 km/km2以下地块的MAPE较全测试集高1.3%,而对6 km/km2以上的地块则低0.93%,说明模型对道路网密度较高区块的预测精度高于密度较低的新建项目区块.
4 结论
为使城市规模扩大、人口增长与道路网建设相辅相成,缓解城市蔓延对自然环境和居民出行的影响,
1)提出了含土地覆盖、人口和道路网数据的时空多源数据融合流程,构建了与时空数据相适应的BiConvlstm2DNet模型,解决了区块化时空多源数据下的道路网密度预测问题.
2)在深圳市时空数据集上进行实验后,BiConvlstm2DNet模型在测试集中取得8.5%的平均百分比误差,优于支持向量回归、随机森林和Convlstm2D预测模型.
3)所提出模型在时空数据预测方面能够展现优势,为宏观指标提供可靠的数据支撑,帮助协调发展土地利用规划和交通规划,具有一定应用前景.
由于土地覆盖数据的采集范围受限,后续将对土地覆盖数据集进行丰富,对新建项目地块或土地覆盖类型变化剧烈地块的未来年道路网密度进行预测,进一步扩展本方法的应用场景.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科学(2020年5期)2020-11-26 08:19:12
科学(2020年6期)2020-02-06 08:59:56
电子制作(2019年11期)2019-07-04 00:34:38
传媒评论(2018年4期)2018-06-27 08:20:12
现代企业文化(2018年13期)2018-06-09 08:22:21
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国工程咨询(2015年5期)2015-02-16 05:35:24
影像技术(2015年4期)2015-02-11 02:57:01
电视技术(2014年19期)2014-03-11 15:38:20
