
针对时间序列的城轨牵引能耗异常分析
2021-12-23 04:38:10张立成
北京交通大学学报 2021年5期
李 熙, 张立成
(1.北京市地铁运营有限公司,北京 100044; 2.北京交通大学 电子信息工程学院,北京 100044)
城市轨道交通由于绿色、安全、高效的特点,近年来发展迅速,总体能耗快速增长.2019年中国内地城市轨道交通总用电量超过150亿kW·h,其中北京市城市轨道交通总用电量超过20亿kW·h[1].系统能耗的增长使运营成本不断上升同时不利于节能减排工作的推进.在城轨系统中,牵引能耗占系统整体能耗的40%~60%[2].牵引能耗受运营时间、空间等因素影响较大,分析牵引能耗时间序列的能耗特点是把握牵引能耗规律,发掘节能潜力的重要基础.因此,如何准确根据列车运营时间的变化确定列车的牵引能耗模式并建立异常能耗判别方法,实现城轨列车异常分析是城市轨道交通能耗分析的重点之一.
城市轨道系统多年的运营积累了大量等间隔的牵引能耗时序数据,为提高能耗数据分析的效率和精度,各地铁运营单位建立能耗分析平台,通过统计及图表展示的形式实现了城轨能耗数据的监测分析,改善了传统分析工作量大、数据管理不精等问题.北京地铁于2016年建立能耗管理平台,为地铁提供电能综合管理和电能质量分析[3].上海申通地铁集团建立三级架构的能耗监测管理系统,针对站、线、网进行能耗管理及分析[4].广州地铁6号线建立面向牵引用电的电能质量管理系统,实现了数据的快速分析展示和预警[5].此类能耗管理系统能够从供电角度监控线网能耗总量,从宏观角度分析和评估运营能耗数据.但现有能耗监管平台的局限性在于忽略了城轨列车牵引能耗模式的变化,缺乏对大量时间序列数据的有效利用,分析精度有待进一步提高.
城轨列车牵引能耗模式是指列车牵引能耗水平随时间和空间变化的规律[6],列车在不同运营时段内的能耗水平存在较大差异,如果不考虑列车牵引能耗模式进行牵引能耗分析和评估,会导致分析结果存在较大误差.目前实际工作中通常采用人工抄录牵引变电所的供电数据对城轨列车牵引能耗进行分析,该方法获得的供电数据无法精确到列车牵引用电过程,适用于线路、路网等宏观维度的能耗分析.通过在地铁列车上加装能耗计量装置,可以收集列车运行过程中的能耗数据.采用传统聚类算法针对站间特征标签数据进行简单的能耗模式划分,其工作量巨大且难以形成简洁高效的能耗模式分析方法.实际工作中时序能耗数据占较大比重,针对时序数据的分析停留在统计和图表展示阶段,尚未形成一套规范的牵引能耗模式分析及异常能耗判断方法.
目前针对城市轨道交通系统列车牵引能耗模式分析及异常检测的研究较少,建筑领域相关研究开展较早,大量学者采用聚类算法进行建筑能耗模式分析.文献[7]采用模糊聚类FCM分析制冷机组运行性能,得到三种典型的能耗模式并验证模式划分的合理性.文献[8]从运营商角度分析使用聚类方法进行电力使用模式识别的可能性,并建立了有效的聚类分组技术.文献[9]基于符号化聚合近似方法和聚类分析对挪威某高校的三年供热数据进行聚类分析,得出典型的能耗模式.文献[10]等对民用住宅和办公楼能耗数据时间序列采用K-means聚类方法进行聚类,得到的每个簇中的数据具有相同的能耗模式.文献[11]采用基于层次的聚类方法对能耗特征向量进行聚类分析得到能耗模式.
针对城轨列车牵引能耗模式分析和异常判断问题,本文作者提出了一种基于符号化近似聚合的城轨列车牵引能耗分析方法,可用于解决时序能耗数据的降维和符号化处理,进而利用聚类分类算法实现城轨列车牵引能耗模式,结合时序数据相似性度量方法实现异常能耗判断.
1 时间序列牵引能耗数据集
1.1 数据来源
本文研究所使用的数据来自北京地铁某车组实际运营过程中记录的牵引能耗数据,该车组为6节动车2节拖车编组.通过在每节车厢加装能耗计量装置,分别记录动车和拖车的每秒累计能耗.每节车厢采集的累计能耗经处理得到一小时内累计能耗数据,单位为kW·h.以日牵引能耗为研究对象,每小时能耗为一个数据点,形成24维能耗时间序列数据.收集北京地铁该车组2020年全年牵引能耗数据,共计366 d,经处理得到366组24维时间序列数据,共8 784个数据点.
1.2 数据预处理
原始秒级牵引能耗数据可能存在错误或丢失,为提高时间序列数据的质量,使最终的列车牵引能耗分析结果具有较高的可信性,在进行时序数据符号化处理前首先进行预处理,补充缺失数据并删除错误数据.针对缺失的秒级能耗数据,通过k最邻近算法进行插补,针对异常数据采用3σ原则进行筛选并删除.
利用预处理得到的秒级累计能耗数据计算小时累计能耗,形成原始能耗时间序列C=C1,C2,C3,…,C24时间序列的各个维度表示1~24 h的每小时累计能耗,绘制2020年该车组能耗图如图1所示,其中一条线代表一天的实际能耗即一个原始能耗时间序列.

图1 2020年日牵引能耗数据Fig.1 Daily traction energy consumption data in 2020
由图1可以看出,牵引能耗水平变化趋势分为:1)牵引能耗曲线先升高然后保持高能耗水平一段时间后回落;2)牵引能耗曲线包含2个能耗高峰,在一天内经历2次升高与降低的过程.结合列车实际运营情况可以分析得出,第1种牵引能耗走势代表列车上线运营后全天处在运营状态,第2种能耗走势代表列车仅在早晚高峰投入运营,其他时间能耗水平较低.
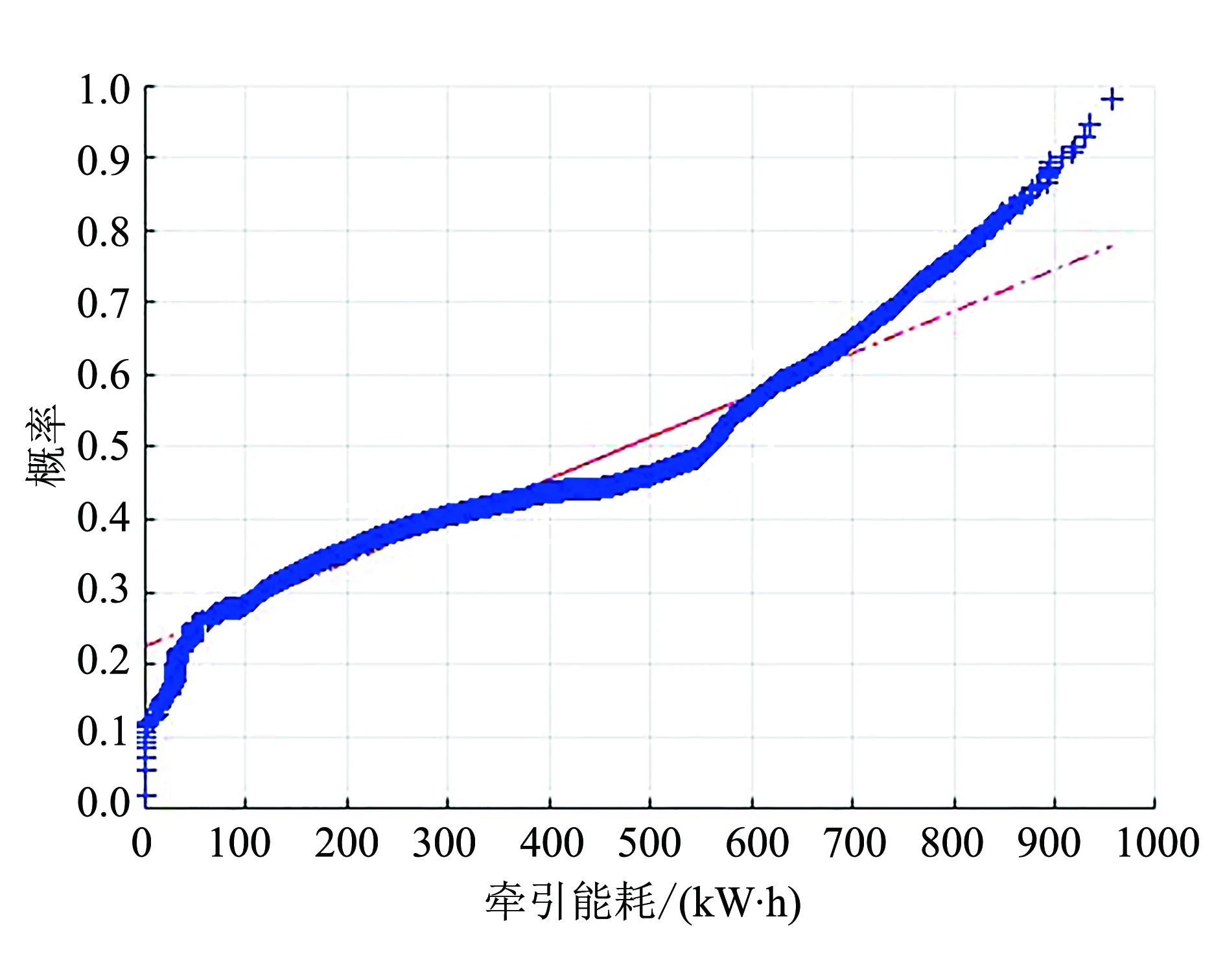
图2 2020年牵引能耗数据正态分布Fig.2 Normal distribution of traction energy consumption data in 2020
本文采用的时间序列处理方法需要数据服从标准正态分布,需要正态分布检验后再变换为标准正态分布.根据正态分布检验原理,数据分布在图2红线附近则为服从正态分布,由图2可知,牵引能耗数据集中间段比较符合正态分布,上下端偏离正态分布红线较远,由于原始数据集能耗数据点在中间段分布集中,因此可认为原始时间序列数据集近似服从正态分布.采用Z-score标准化方法,对原始数据集进行变换,使之服从标准正态分布N(0,1),μ=0,σ=1标准化函数如下
(1)
2 牵引能耗模式分析方法
2.1 符号化近似聚合
预处理后的原始时序能耗数据每一个维度均满足标准正态分布,但时序数据维度较高,通常聚类、分类等机器学习算法处理高维数据效果较差,需对原始时序能耗数据进行降维处理.符号化近似聚合(Symbolic Aggregate approXimation,SAX)是一种基于分段近似聚合(Piecewise Approximate Aggregation,PAA)的符号化处理工具[12].该方法复杂度低,同时具有较高的自主选择性和数据灵敏度,经SAX降维处理后的数据兼具低维度和丰富的数据结构,并适合采用机器学习算法进行分析.
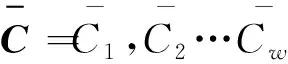
(2)
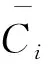

表1 间断点表Tab.1 Table of discontinuity points
例如,当a=3时,正态分布被2个间断点β1,β2划分为3个区间,即小于-0.43的值用字母a表示,-0.43到0.43之间的值用字母b表示,大于0.43的值用字母c表示.
2.2 参数选择与牵引能耗子模式
SAX转换的数据精度受w和a的取值影响.转换后字符串长度随w增大而增大;a取值越大,时间序列划分成的字符串的表现形式越复杂,一个时段内可表示的能耗级别越多,当w和a的取值越大,生成的牵引能耗子模式越多,极大地影响聚类等机器学习算法的时间、空间复杂度.
当w和a取不同的值时,生成的牵引能耗子模式及对应天数如图3所示.当w=4,a=3时,2020年该列车日牵引能耗被划分成21种子模式,其中主要模式为acbb;当w=4,a=4时,生成34种子模式,其中主要模式为accc;当w=6,a=3时,生成42种子模式,其中主要模式为aaccca;当w=6,a=4时,生成78种子模式,其中主要模式为aaddda.根据地铁列车运营和能量消耗水平的特点,将一天划分为6个时段,每个时段采用低、中、高三等级能耗水平进行描述较为合理.此外,当w=6,a=3时,生成的牵引能耗子模式较为集中,因此本文选择w=6,a=3作为SAX符号化处理的参数.
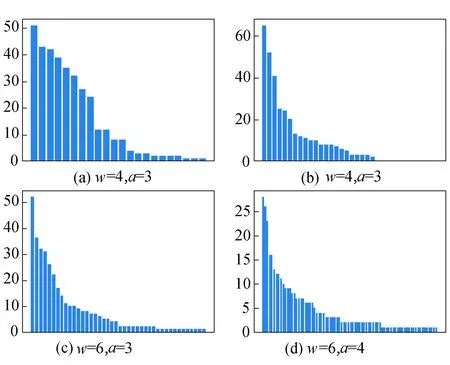
图3 不同取值下子模式数量及天数Fig.3 Number of patterns and days under different values
针对城轨列车牵引能耗模式的分析注重牵引能耗水平在1 d内的变化,因此选取1 d内每个小时的累计能耗构成24维能耗时序数据,根据2.1节的分析,选取w=6,a=3,对时序数据进行符号化处理,将原24维时间序列分成6段,每段用a、b、c三个字母表示.以2020年6月1日为例,当w=6,a=3时,SAX符号化处理将其转化为字符串acccba.每个字母对应4 h的时间段,a代表低能耗水平,c代表高能耗水平,b为中等能耗水平.利用python编写SAX算法程序实现原始牵引能耗时间序列预处理及符号化表示,将原24位时间序列数据降至6维.2020年该车组上线运营354 d,处理后得到354组6维字符串向量.统计得到42种牵引能耗子模式,SAX处理结果如表2所示.
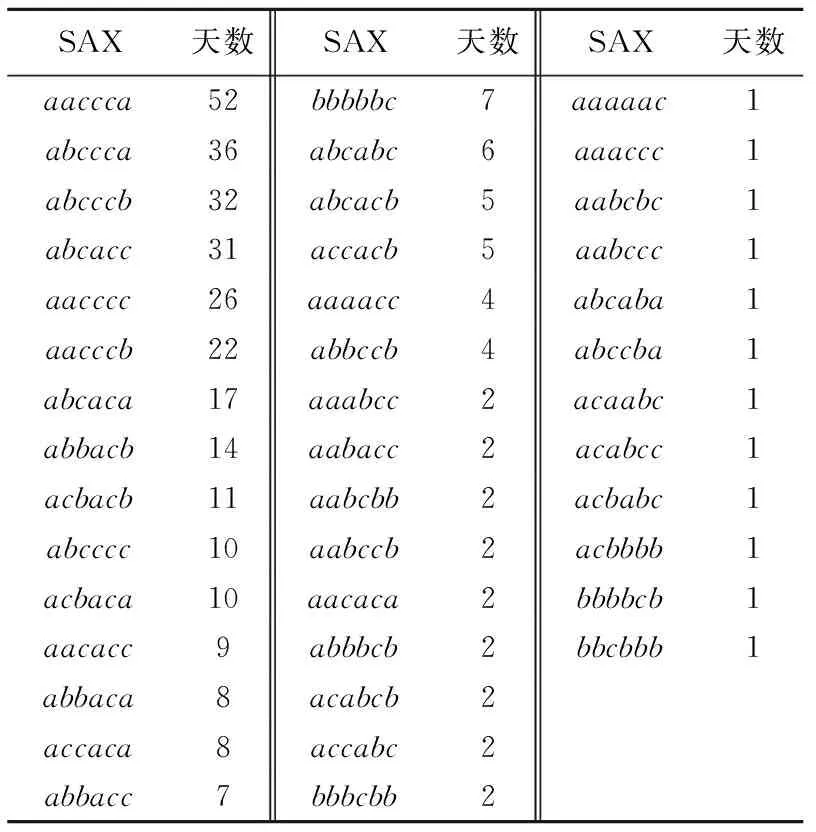
表2 SAX处理生成子模式Tab.2 Sub-patterns of SAX processing
2.3 牵引能耗模式识别与分析
原始24维牵引能耗时间序列数据经SAX处理后得到的牵引能耗子模式高达42种,模式较为分散,无法形成具有代表性的牵引能耗模式.K-means是典型的无监督学习算法,能够将相似的样本划分到对应的簇中.SAX转化后的结果可以通过K-means进一步聚类实现牵引能耗模式的判别.
K-means通过计算每一个样本点到聚类中心的距离来度量相似度,通常采用欧式距离作为计算函数.原始牵引能耗时间序列数据经过SAX处理后为6维字符串向量,由于字母间无法直接通过数值计算定义其距离,因此定义一种基于欧式距离和高斯符号划分表的字符串距离度量方法[14].两个长度为n的时间序列C和D,其欧几里得距离、PAA距离、符号化距离分别为
(3)
(4)
(5)
原始时间序列数据经过PAA压缩后,欧几里得距离函数相应压缩,采用符号化表示后,将(a,b)替换为dist(a,b),字符a、b间距离计算公式为
(6)
当a=3时,结合表1和式(6)可得出各字符之间的距离定义如表3所示.
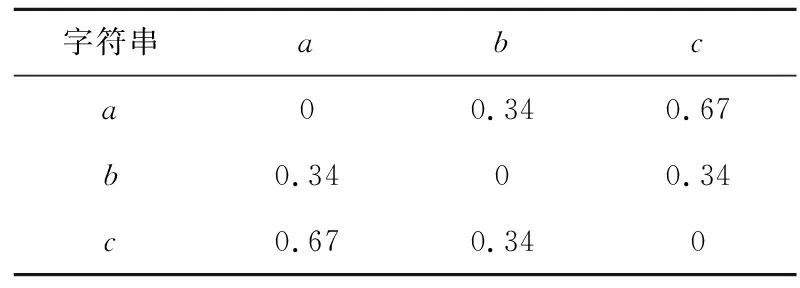
表3 字符距离表Tab.3 Table of distance between strings
选定式(6)作为K-means的距离度量函数后,需要确定聚类数目k,k值的选择极大的影响聚类结果.选取簇类个数k通常可采用手肘法和轮廓系数来判断k值是否接近真实聚类数目.手肘法是通过误差平方和残差平方和(Sum of the Squared Errors,SSE)这一指标的变化来判断k是否为数据的真实聚类数.其原理为随着聚类数k的增大,样本划分更加细致,每个簇的聚合程度提高.因此误差平方和SSE不断减小,当k达到真实聚类数时,再增加k值,SSE的下降幅度会迅速减小,随后再继续增加k值,SSE变化趋于平缓,因此当SSE变化较大的k值即为真实聚类数k.SSE计算公式为
(7)
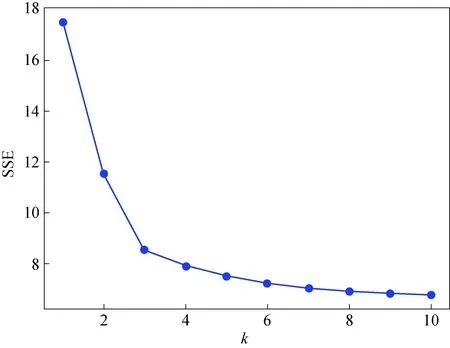
图4 当k取不同值时SSE变化趋势Fig.4 Variation trend of SSE when k takes different values
由图4可以看出,手肘法确定最佳聚类数k=3.2.1节由SAX处理得到的354组字符串数据,由于一些子模式包含天数过少,故视作非典型模式并剔除,剔除后得到324组字符串向量数据.通过修改K-means距离计算函数并确定聚类数k,对324组字符串数据进行聚类分析,聚类结果如表4所示.
从表4可以看出,SAX处理生成的21种模式经过K-means进一步聚类得到3种能耗模式,能耗模式曲线如图5所示.
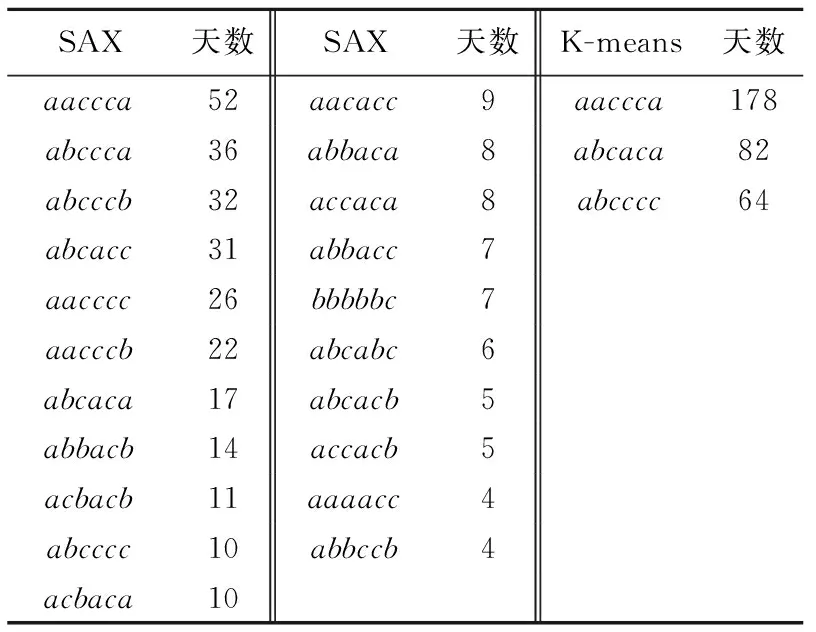
表4 SAX和K-means生成的模式Tab.4 Patterns of SAX and K-means
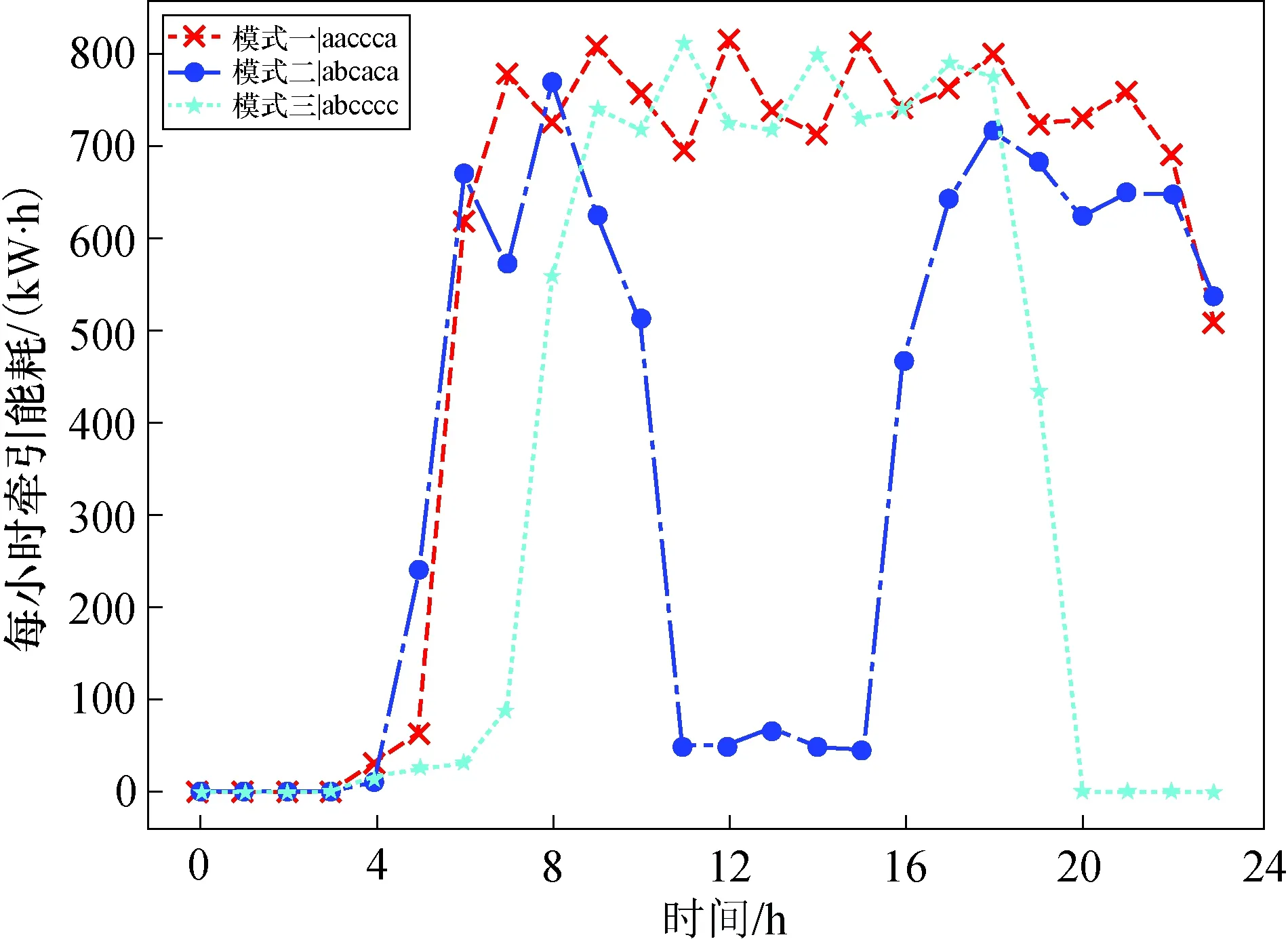
图5 三种典型牵引能耗模式曲线Fig.5 Curves of three typical traction energy consumption patterns
通过SAX符号化处理和K-means聚类,分析北京地铁某车组2020年共354 d实际运营中记录的牵引能耗数据,将列车日牵引能耗划分为3种主要模式.模式一:列车于23:00至次日6:00处于低能耗水平,6:00-23:00处于高能耗水平.模式二:列车牵引能耗在一天中有2个能耗高峰,分别是6:00-10:00和16:00-23:00,其他时段处于低能耗水平.模式三:列车于20:00至次日7:00处于低能耗水平,7:00-20:00处于高能耗水平.
相关研究指出,列车牵引能耗与车底运用计划关系密切,当列车处在运营状态下产生牵引能耗,且客流高峰牵引能耗水平高于一般时段.通过表5该列车车底运用计划中主要运营时段和聚类得到的典型能耗模式之间的匹配关系可知,基于SAX和聚类分析得出的典型牵引能耗模式与列车当日执行的车底运用计划表现出高度的一致性,展现了该牵引能耗模式分析方法的有效性.

表5 车底运用计划中主要运营方式Tab.5 Major operation prescribed in the rolling stock scheduling plan
3 牵引能耗异常分析方法
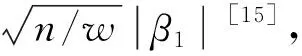
为验证本文提出的列车牵引能耗模式分析及异常判断的准确性,利用2020年剔除的30组日牵引能耗时间数据及当日车底运用计划,分别计算30组字符串向量与3种典型牵引能耗模式匹配情况,计算结果见表6.
由表6可知,少数模式aacaca和abcaba与典型模式二abcaca匹配,其余27d对应的少数模式均与3种典型模式不匹配,视为异常能耗模式,该异常模式判断方法准确度约为90%.
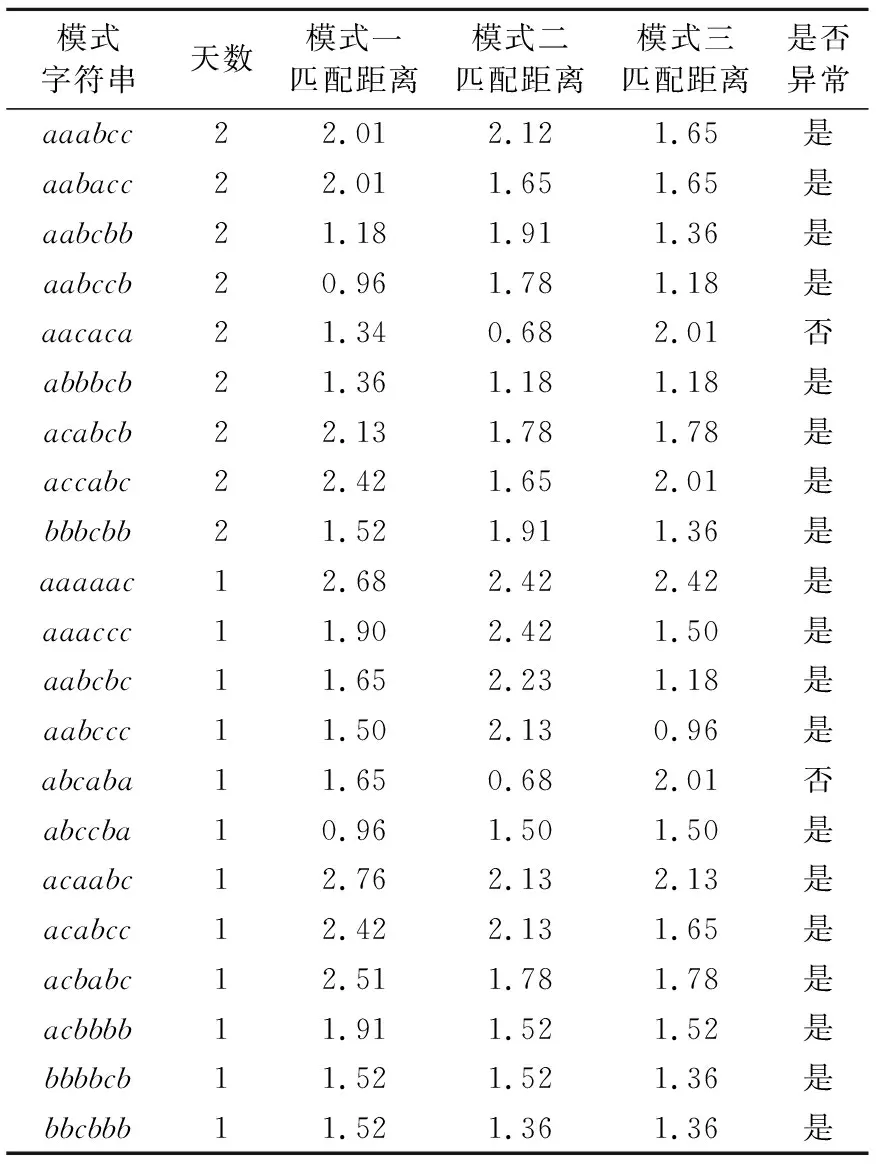
表6 异常模式匹配Tab.6 Abnormal patterns matching
4 验证与分析
为验证本文所提出牵引能耗模式分析及异常判断方法的有效性,选取2021年1月该车组实际运营中记录的牵引能耗数据,利用SAX符号化处理方法得到字符串数据,并分别计算与3种典型能耗模式的匹配度,与3种典型能耗模式均不匹配则判断为异常能耗模式,针对其原始牵引能耗时间序列数据进一步分析能耗异常出现的时间点.2021年1月数据符号化结果如表7所示.
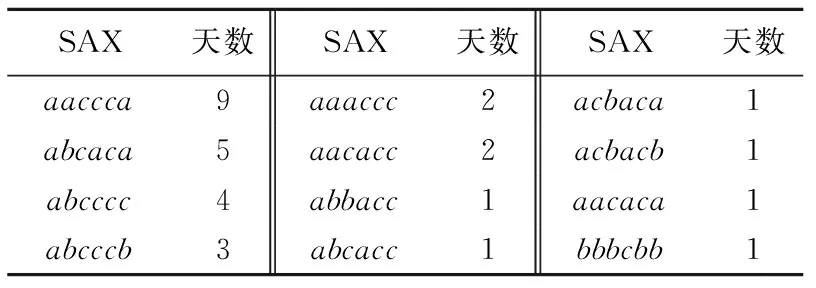
表7 2021年1月SAX处理结果Tab.7 SAX processing in Jan. 2021
根据模式匹配计算式(5),计算2021年1月SAX处理结果与3种典型模式的匹配程度,模式匹配结果如表8所示.
经验证,3种典型模式与测试集模式匹配度达96.77%,高于2σ原则规定的95.45%,因此可认为典型牵引能耗模式分析结果有效,与3种典型模式均不匹配的字符串即可判断为牵引能耗模式异常,并针对原时间序列进一步分析确定异常出现的时间点.
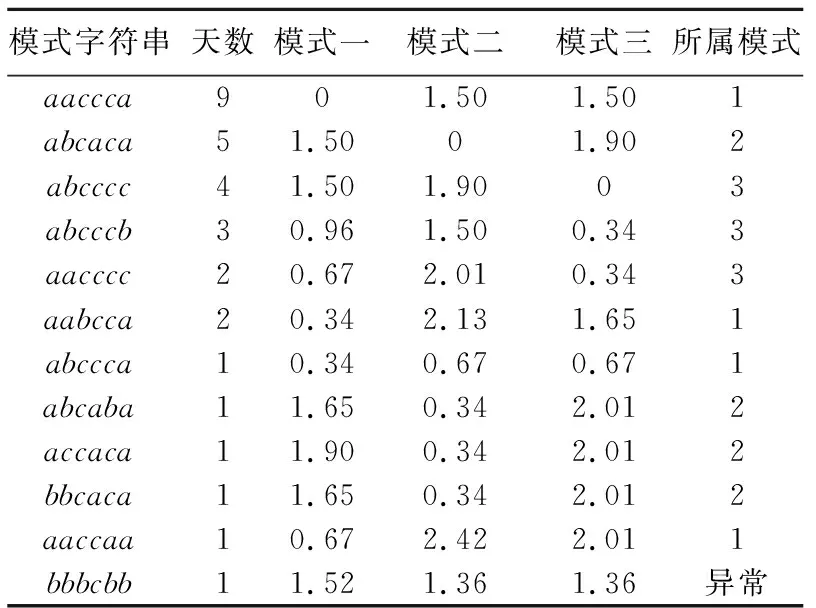
表8 三种典型模式匹配情况Tab.8 Matching of three typical patterns
5 结论
1)针对城市轨道交通运营中记录的大量时间序列格式的牵引能耗数据,提出了一种基于SAX符号化近似聚合和K-means聚类的牵引能耗模式识别及异常分析方法,可用于典型牵引能耗模式的获取和异常模式判断.首先基于SAX符号化近似聚合获得牵引能耗子模式,其次基于K-means获得典型牵引能耗模式,最后利用模式匹配公式判断异常能耗模式.
2)利用2020年北京地铁某车组列车时序牵引能耗数据集,分析得到3种典型牵引能耗模式并结合当日车底运用计划分析其有效性.
3)利用2021年该车组运营中记录的数据验证模式识别的准确性,基于此方法可以能耗时间序列为基础获得典型牵引能耗模式,并以此为基准判断日牵引能耗是否存在异常,为城市轨道交通系统能耗异常提供一种基于时序数据的分析手段.
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
数学教学通讯·小学版(2022年4期)2022-05-29 00:11:44
当代水产(2021年10期)2022-01-12 06:20:28
建材发展导向(2021年23期)2021-03-08 01:05:38
华人时刊(2018年15期)2018-11-10 03:25:26
电子测试(2017年15期)2017-12-18 07:19:27
新校园·上旬刊(2017年10期)2017-12-08 10:58:10
纺织科技进展(2016年3期)2016-11-29 01:27:00
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
