
基于模拟退火算法的粒子群优化算法在容器调度中的应用
2021-12-22 13:18刘哲源吕晓丹蒋朝惠
计算机测量与控制 2021年12期
刘哲源,吕晓丹,蒋朝惠,2
(1.贵州大学 计算机科学与技术学院,贵阳 550025;2.贵州省公共大数据重点实验室,贵阳 550025)
0 引言
随着云计算产业的高速发展,面对高并发量的业务压力,虚拟机灵活性不足、创建速度慢、不易扩展等缺点越来越凸显。容器技术易扩展、秒级启动、灵活的弹性伸缩等特点,为这些问题提供了一种全新的解决方案。软件容器化已经成为软件部署和当今互联网的新趋势。Docker[1]则是其中一个开源的应用容器引擎,不仅是一个新型虚拟化技术,同时也是应用程序交付的一种方式。传统虚拟机一般由虚拟硬件和操作系统两部分组成,而Docker容器不需要安装特定的操作系统和VMM(虚拟机监控),Docker容器通过共享主机操作系统内核,用主机的硬件和操作系统来完成程序的操作,一定程度上减少了资源的浪费问题,两者架构对比如图1所示。

图1 传统VM和Docker的架构对比
Kubernetes[2]是目前主流的Docker容器编排平台之一,负责对容器的整个生命周期的管理。Pod是Kubernetes的基本运行单元,一个Pod内可以有多个容器,且可以在创建Pod的yaml配置文件中声名容器所需要的资源需求。Kubernetes在对Pod任务进行调度时,首先通过预选算法筛选出所有符合运行条件的节点,接着通过优选算法为这些节点进行打分,最终选择分数最高的节点用来绑定Pod任务,接着调用Docker-daemon通过Http方式向镜像仓库下载相应的容器镜像,具体步骤如图2所示。
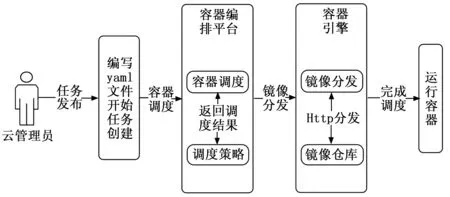
图2 Kubernetes调度过程
虽然Kubernetes的Balanced Resource Allocation调度算法虽然能一定程度上解决资源均衡问题,但是仍然达不到数据中心的预期水平。Kubernetes的调度算法仅仅考虑了工作节点的CPU和内存利用率,而未考虑工作节点的网络负载能力,从而影响Pod的任务最少等待时间。
目前,国内外对容器调度后的资源利用率不均衡问题有较多的研究。文献[3]设计了EVCD(基于虚拟机弹性供给的容器部署),利用贪婪first-fit和round-robin,并EVCD可以在运行时重新分配容器实现QoS的改进,提升容器调度的效果。文献[4-5]通过对容器需求的CPU和内存资源进行分类,针对不同类型的容器使用不同的调度算法。文献[6]提出了基于应用历史记录的调度算法,减少容器调度后的镜像分发过程中带来的网络资源的损耗。文献[7-10]使用群优化算法对容器的多指标调度设计,实现了较好的资源使用率。文献[11]通过对数据中心资源进行更细粒度的划分,在保证了服务器性能的同时,集群资源利用率也得到了提高。文献[12-13]针对容器动态调度的问题,设计寻找最优解的动态调度算法,解决了动态调度中的资源浪费问题。文献[14]设计一种多目标容器调度算法Multiopt,通过对工作节点当前状态进行计算评估出合适的调度节点。文献[15-16]对集群负载均衡性进行考虑,采用智能算法对集群中所有节点进行评定,最终确定调度节点。文献[17]通过预先训练随机森林回归模型,预测集群压力进行容器调度。文献[18]提出了一种VM-Container混合分层资源调度机制,通过调度状态综合性将任务划分为不同的级别,针对不同的级别制定不同的PSO调度算法,但没有考虑到特殊情景下的容器调度。文献[19-20]关注容器资源要求环境和任务规模变化,提出采用粒子群优化算法来进行容器部署,解决了容器部署过程中的网络消耗问题。
尽管国内外很多学者已经为此做了很多有价值的工作,但是仍然存在不足。因此,研究的重点在于改进容器调度算法以提高集群节点的资源利用率从而达到数据中心的预期水平,减少容器任务最少等待时间,提升容器云的服务质量。
1 数学模型的设计与构建
在Kubernetes平台中,创建容器首先采用声明式方法在Pod的yaml文件中声明容器所需要的资源信息,接着通过kubectl命令来创建Pod。因此,在Pod开始调度之前,系统已经获取了Pod的资源需求情况。同时,Kubernetes中的api-server组件收集集群中节点的指标资源使用情况。构建数学模型如下。
容器云集群:
Cluster={Node1,Node2,...,Noden}
(1)
式中,Cluster为n个Node节点组成的集群,每个Nodei节点都具有4维属性表示为:
Nodei={UCPU,UMem,UNet,status_now}
(2)
式中,Nodeid表示为Node节点i中的可用第d维资源,Nodei4表示节点Nodei得可用第4维资源status_now,即为当前主机状态,其具体取值如下:
(3)
式中,当节点Nodei当前处于宕机状态时,status_now为值0,反之,status_now为值1。
对于每次创建任务Podi,都具备3维属性:
Podi={RCPU,RMem,Rimage}
(4)
式中,Rmem,Rimage分别为任务Podi所需要的CPU、内存、容器镜像等资源需求。当开始调度时,通过Kubernetes编排平台中的预选决策后,集群已经通过预选决策筛选出了一部分可以满足调度任务可正常工作节点:

(5)
式中,Node为筛选出来符合调度条件的工作节点的集合,且被筛选出来的Node节点均包含有当前节点目前的资源使用情况,UCPU为节点当前的内存使用量,Umem为当前节点的内存使用量。尽管筛选出了一部分可以使用的工作节点,我们仍需要通过优选测了为Podi找到一个最优节点进行调度,以提升集群的整体资源利用率。
对于每个数据中心而言,CPU、内存等资源的长期闲置也是一种开销损耗,而资源利用率超过一定负荷阈值则证明其在负荷运行,同样也是对服务器的生命周期的一种损耗,因此保证资源利用率不低于资源阈值,且不高于负荷阈值,则是提升资源利用率的一种有效方式。对于资源利用率我们希望其:

(6)
式中,Z表示为资源类型,包括CPU、内存、网络等资源类型,Zmin为云服务厂商所希望资源不低于的最低资源阈值,Zmax为云服务厂商所希望的不高于的负荷阈值。ZNodei-use为若Podi绑定到Nodei节点后Z资源使用率,ZNodei-t为Nodei节点的总资源,ZNodei-U为当前节点此时刻的Z资源类型的资源使用量,ZPodi-R为任务Podi所需要的资源量。
容器云调度过程应尽可能多地为上层应用分配计算机资源,给容器云经营者带来更多的收益,因此,以所有执行任务所需要的资源量的价值来表示容器云经营者满意度函数如式(7)所示:
f(Z,Nodei)=(Zmin+Zmax)*ZNodei-t-2UZ
(7)
式(7)意为:当适应性函数在节点i的函数值越高,则证明资源Z在Nodei上的资源使用率低,越不符合数据中心的资源使用率预期,因此是Pod任务绑定的较优节点。在Pod任务绑定到Nodei节点后,Z资源的使用率高于最低资源阈值,且不高于最高负载阈值,以达到容器云运营者的满意程度。
因此,我们主要对数据中心资源使用不均情况较为常见的CPU、内存指标和工作节点当前网络负载情况进行数学建模:
1)CPU模型构建。根据Pod所需要的CPU需求量RCPU,与筛选出的节点Nodei中目前所使用的CPU使用量UCPU进行量化建模,具体公式如式(8)所示:
(8)
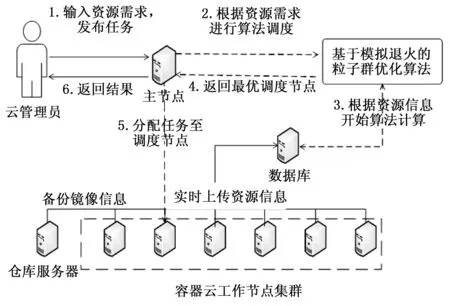
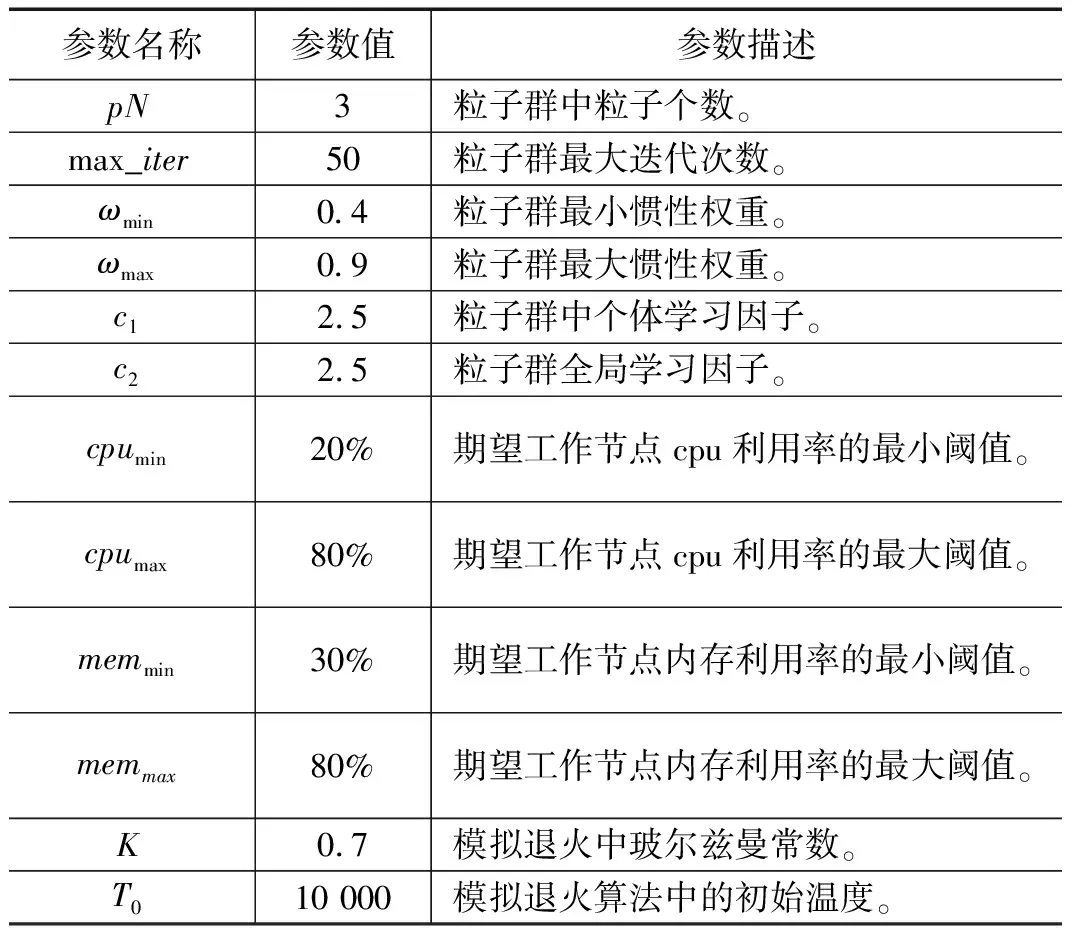
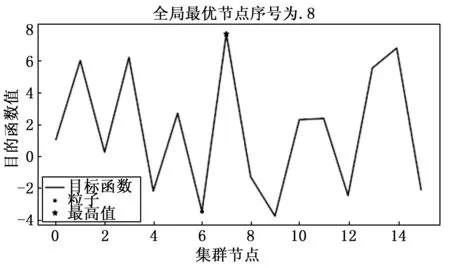
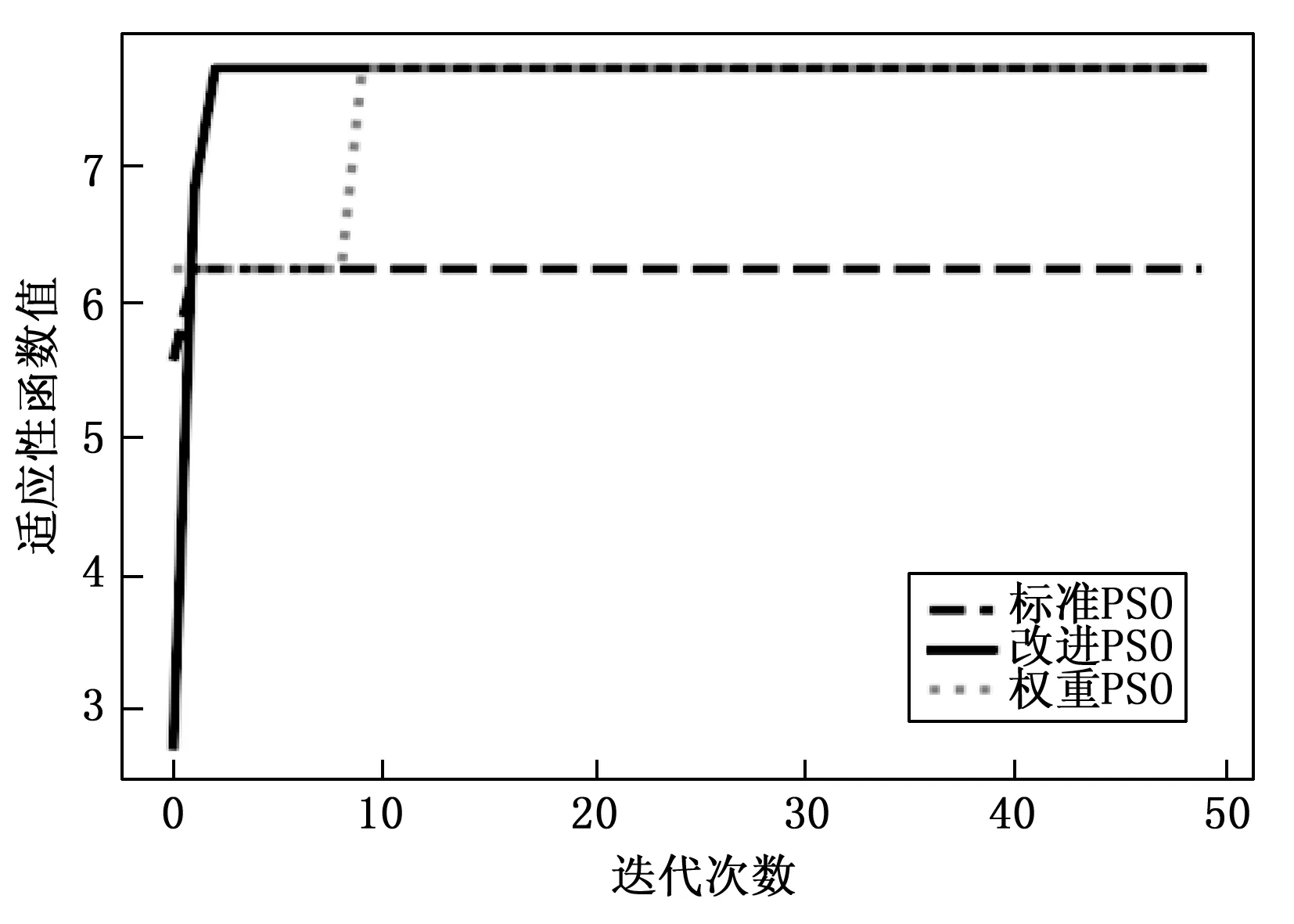
为了满足任务Pod所需CPU资源,E1应受限于:
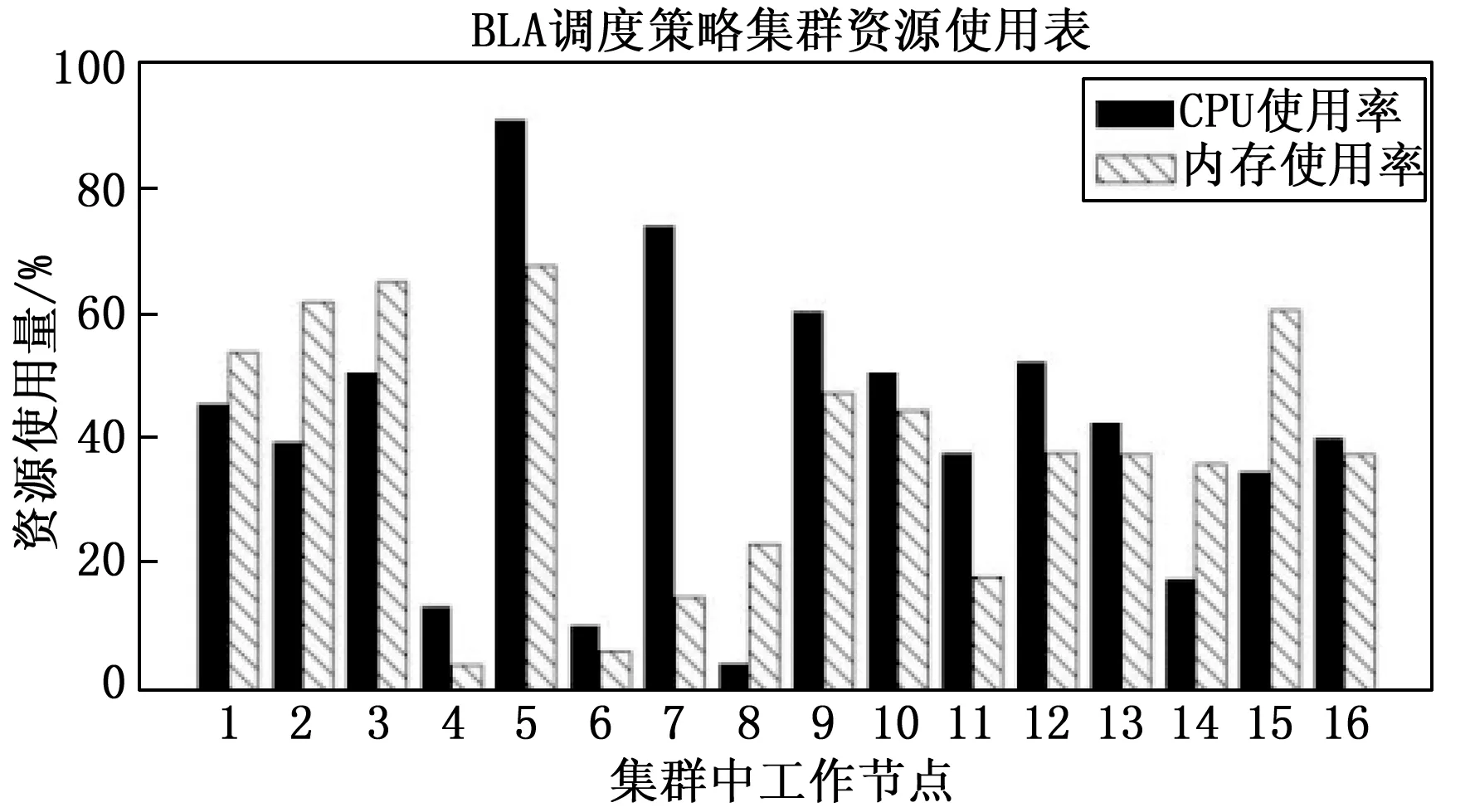
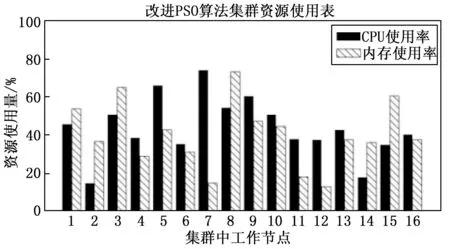
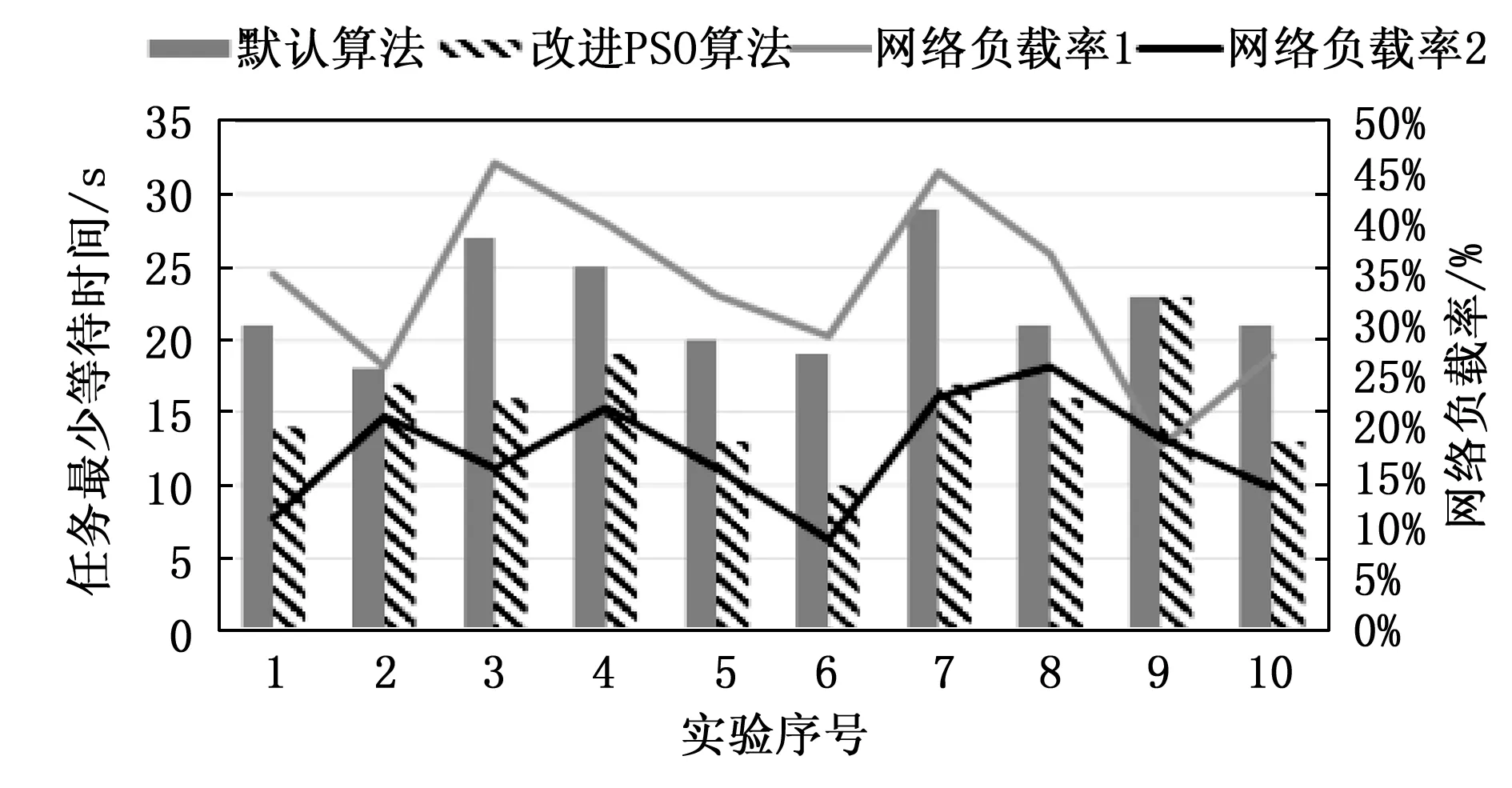
0 2)内存模型构建。根据Pod所需要的内存需求量RMem,与筛选出的节点Nodei中目前所使用的内存使用量UMem进行量化建模,具体公式如式(9)所示: (9) 为了满足任务Pod所需内存资源,E2应受限于: 0 3)网络负载建模。根据Pod所需要的镜像需求Rimage,与筛选出的节点Pod中目前所使用的网络负载量Unet进行量化建模,具体公式如式(10)所示: (10) 4)适应性函数构建。针对以上问题,对适应性函数公式可以建立为: (11) 式(11)中,Nodei4是Nodei得第4维属性status_now,当节点宕机时,该宕机节点得适应性函数function值为0,当适应性函数function值越高,则代表当前Nodei资源利用率越满足任务Pod运行条件,且绑定Pod任务后集群资源利用率趋于数据中心满意度。 粒子群优化算法(PSO)[21]是一种模拟生物行为活动的群智能化算法,每个粒子都存在一个存在可行解的搜索空间,且每个粒子都具备一定的空间搜索能力,通过粒子速度V,粒子位置X来表示粒子空间位置特征,并由目的函数确定适应度值,其值的好坏表示粒子的优劣程度。 粒子在独自的搜索空间内,每个粒子会记录自身最优位置与全局最优位置,并通过判断当前自身位置和个体最优位置以及群体最优位置的距离,若自身位置优于全局最优位置,则更新全局最优位置,并不断更新自身的位置和速度,不断迭代,直到找到种群最优位置。更新公式如式(12)所示: (12) 标准PSO算法的伪代码如下所示: Algorithm 1:Find the maximum position of the maximum function. procedure PSO for each particlei Initialize velocityViand positionXifor particlei Evaluate particleiand setpBesti=Xi end for gBest= max{pBesti} while not stop fori= 1 to N Update the velocity and position of particlei Evaluate particlei if function(Xi) > function(pBesti) pBesti=Xi; if function(pBesti) > function(gBest) gBest=pBesti; end for end while printgBest end procedure 模拟退火算法[22]的是受固体退火过程的启发而发展出来的一种算法,固体加热至足够的高的温度时,再另其缓慢冷却,而固体中的粒子在升温过程中,内能增大,趋于无序;缓慢降温时又能够使得内能减小,趋于有序。因此理论上说,只要初始温度足够高,而降温过程又足够缓慢,那么算法在过程中将会收敛到全局极值。而之所以模拟退火算法可以有能力进行概率突跳,是因为采用了Metropolis准则,其表达式为如式(13)所示: (13) 如图3所示,在主节点api-server组件接收到Pod任务创建任务后,kube-scheduler组件调用基于模拟退火的粒子群优化算法,并向数据库请求实时采集容器云中工作节点的当前资源信息,得到返回数据后开始计算,计算完成后返回最优节点,工作节点kubelet组件通过watch监听主节点api-server得到调度任务后,调用本地Docker-daemon组件进行容器镜像的检索和下载工作,镜像存在本机后,启动任务,至此一次任务创建完成。 图3 基于模拟退火的粒子群优化算法框架图 粒子群优化算法的优化过程主要是通过粒子群中的粒子通过粒子间的信息(即个体最优解和全局最优解)不断更新自身的位置和速度,使其能不断地向全局最优解靠拢,最终得到全局最优解。但是由于基本粒子群算法处于运算后期时,因粒子多样性减少,容易陷入局部最优,且后期收敛速度变慢。在整个计算流程中,惯性权重对粒子速度和位置的影响不同:运算前期,较大的惯性权重有利于全局搜索,粒子速度快,但寻优值不够精确;相反,运算前期,较小的惯性权重有利于局部搜索,全局搜索能力较弱,但容易陷入局部最优。因此,将模拟退火算法嵌入粒子群优化算法中,就是在算法初期温度较高的时候,让种群例子有较大概率去接受非最优解,从而跳出局部最优解,而后期温度降低时,又能够收敛到全局最优,准确定位到全局最优解。由于模拟退火有能够突跳的概率,因此可以有效避免算法陷入局部最优,有效避免了“早熟”现象。基于模拟退火的粒子群优化算法流程如图4所示。 图4 模拟退火的粒子群优化算法流程图 实验环境采用翔明云提供的虚拟机作为操作主机,创建集群大小为17的高可用Kubernetes集群,集群中3台节点搭建Master节点高可用,其中2台既是Master节点也是Node节点,共计16个Node节点。实验环境如表2所示。 表2 实验环境表 对SA-PSO算法(后称改进PSO算法)与标准PSO算法、文献[23]动态权重调整的PSO算法(后称权重PSO算法)进行性能及精度进行对比。同时对改进PSO算法与Kubernetes默认调度算法进行对比。服务器资源利用率的期望阈值根据贵州翔明云日常运维需求来进行设定,当CPU利用率在20%~80%,内存利用率在30%~80%之间,服务器性能较好,且资源利用率最合理,文献[24]实验得出当c1=c2=2.5时标准PSO算法的收敛效果最好,文献[25]指出模拟退火中K=0.7和T0=10 000时,基于模拟退火的粒子群优化算法效果较好。实验中具体参数设置如表3所示。 表3 实验参数表 3.2.1 性能测试和精度测试 对改进PSO算法的性能进行测试,通过对权重PSO算法,标准PSO算法的寻优过程中的迭代次数以及收敛性进行对比,测试改进算法的算法效率。实验过程通过发布一个CPU需求量为1 000 m、内存需求量为1 G的Nginx容器Pod任务,使用目标函数对不同Node节点的资源利用情况进行计算得到该节点的适应性值,适应值最高的节点即为本次任务的全局最优目标节点,不同的粒子在不同节点间自主运动,并不断与全局最优解进行比较,调整自身的运动方向以及运动速度,直到找到最高峰值,峰值所在节点既是全局最优节点,具体如图5所示。 图5 集群节点适应值曲线 当迭代次数为50,粒子群大小为3时,对3种算法的迭代寻优变化曲线进行对比,具体实验结果如图6所示。 图6 算法迭代寻优对比图 依此反复测试10次,目的函数达到最大值记为一次成功命中,意味着没有进入局部最优,达到了全局最优解,记为全局收敛成功。各个算法寻找到各自群体最优解看作完成迭代,记录为迭代次数,同时该记录也包含陷入局部最优解的情况。通过计算得出平均迭代次数、收敛成功率情况如表4所示。 表4 寻优情况表 实验表明,当粒子群大小为3,最大迭代次数为50次时,标准PSO算法容易陷入局部最优情况而无法精确地找到目标节点,而改进PSO算法和权重PSO算法相较标准PSO算法的收敛成功率以及命中率均有较大提升,且平均迭代次数要少于标准PSO算法。改进PSO算法由于对学习因子进行动态调整,收敛性能略优于权重PSO算法。上述实验可知,在本次实验环境下,改进PSO算法的成功命中率相较标准PSO算法提高了近60%。 3.2.2 负载均衡测试 对集群负载均衡度进行测试。使用Kubernetes的Scheduler-framework用来实现改进PSO算法的调度算法。通过选择先后选择BLA调度算法和改进PSO调度算法分别部署4个高资源需要求的Nginx服务器作为调度任务,在yaml文件中限制CPU大小为1 000 m,内存大小为1 G,通过Kubernetes的BalanceResourceAllocation(后称BLA)算法,将4个调度任务分别绑定到4个节点,先后次序为node15,node02,node05,node12,完成后集群资源利用使用图如图7所示。 图7 BLA调度算法集群资源使用情况图 实验结果表明,虽然BLA调度算法一定程度上提高了资源利用率,但是仍有部分节点资源使用情况不理想。在BLA调度过程中,主要会考虑任务绑定到某个节点时节点资源使用率是否均衡而不会考虑资源利用率情况,因此容易造成某些节点资源利用率不高的情况。通过改进PSO算法先后部署同样的4个调度任务,任务绑定节点先后次序为node08,node06,node04,node15,改进PSO算法能较好的提高整体资源利用情况,达到云提供商的资源使用预期,完成调度后的资源使用情况如图8所示。 图8 改进PSO调度算法集群资源使用情况图 通过对比两个算法的任务调度可以看出,改进PSO算法SA-PSO相对Kubernetes的Balance Resource Allocation算法实现了更好的集群资源利用率,同时部署节点的网络负载率也处于较低水平,为下一步容器镜像分发步骤节省了任务等待时间。在本实验环境中,改进PSO算法(SA-PSO)可以准确地找到任务绑定的最优节点,从而提高集群的整体资源利用率。 3.2.3 任务最少等待时间测试 使用Kubernetes默认调度算法和改进PSO调度算法进行分别部署10次镜像大小为133 MB的Nginx服务Pod任务,其资源需求配置如测试(2)相同,记录其任务最短等待时间,实验对比结果如图9所示。 图9 任务最少等待时间与网络负载率对比图 图9中,网络负载率1为默认算法调度工作节点的网络负载率,网络负载率2为改进PSO算法调度工作节点的网络负载率。由实验结果可知,改进PSO算法较于默认调度算法由于在调度过程中将工作节点的网络负载率带入计算,优先选择网络负载率低的节点进行调度,因此可以提升镜像分发的效率,从而减少任务最少等待时间。 随着云计算产业的快速发展,Docker的出现给了互联网企业一种新的解决问题的思路。面对大规模的软件部署,若不能合理利用服务器资源,无论对云提供商还是软件方都是一项额外的开销。而主流的容器编排平台Kubernetes在调度容器的过程中存在着资源利用不足的问题,同时目前主流研究没有将容器调度过程与镜像分发过程相结合。因此,在此提出了一种基于SA-PSO调度算法,通过模拟退火算法解决粒子群算法易于陷入局部最优解的问题。经过实验表明,SA-PSO算法相较标准PSO算法以及权重PSO算法有较强的收敛能力以及寻优精准度,在本实验环境中,寻优精准度相较标准PSO算法提升约60%。同时,在Kubernetes平台实验测试中,SA-PSO调度算法不仅对数据中心期望的资源阈值进行考虑,而且在集群资源利用率方面优于BalanceResourceAllocation调度算法。对工作节点的网络负载率进行考虑,显著减少了容器任务的任务等待时间。2 基于模拟退火的粒子群优化算法
2.1 标准粒子群优化算法
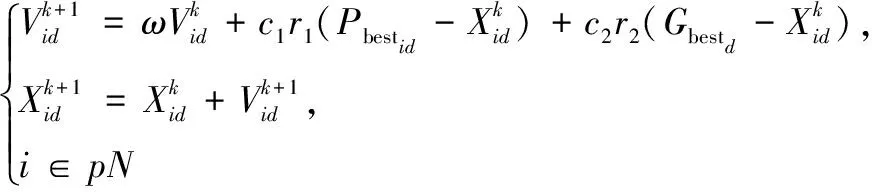
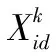
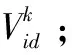
2.2 基于模拟退火的粒子群优化算法思想


3 实验结果与分析
3.1 实验环境

3.2 实验与分析

4 结束语
猜你喜欢
汽车实用技术(2022年10期)2022-06-09北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20智能制造(2020年11期)2020-02-08妇女生活(2018年7期)2018-07-14智富时代(2018年1期)2018-03-26智富时代(2018年1期)2018-03-26电子技术与软件工程(2018年12期)2018-02-25软件(2017年7期)2018-01-24分析化学(2018年12期)2018-01-22环球时报(2017-06-27)2017-06-27
