
低秩先验引导的无监督域自适应行人重识别
2021-12-21 03:07李玲莉谢明鸿张亚飞李华锋谭婷婷
重庆大学学报 2021年11期
李玲莉,谢明鸿,李 凡,张亚飞 ,李华锋,谭婷婷
(昆明理工大学 a.信息工程与自动化学院; b.云南省人工智能重点实验室 昆明 650500)
行人重识别是一种从不同相机视角下在采集的行人图像中搜索出相同行人的技术,在智能监控中发挥重要作用,因此受到研究者的广泛关注。在现实监控环境中,同一行人的不同图像常常因相机视角差异、光照变化等影响呈现出不同的外貌特征,这给行人重识别带来了极大挑战。由于不需要进行大量人工样本标记,近年来无监督域自适应行人重识别方法已成为研究热点之一。这些方法主要是通过无监督域不变特征提取、对抗学习和图像风格迁移等手段来减小源域与目标域之间的差异。然而,无监督域不变特征提取的方法往往很难挖掘具有判别性的特征信息;基于对抗学习的无监督方法提取到的特征往往是来自不同域样本的共有信息,丢失了不同域样本之间的特有信息,容易加剧样本特征之间的歧义性;基于图像风格迁移的方法虽然有效,但容易导致迁移图像标签信息改变。
不同数据集之间产生域偏移的主要原因之一是相机的成像风格不同。从图1可发现来自同一视角下的行人图像,呈现出相似的风格信息,如果将这些图像的视觉特征由矩阵表示,这个矩阵在数学上就会呈现出低秩性。因此根据这种低秩先验性,设计一种域不变特征分离模型,将风格信息从图像特征中分离出去,这种策略不仅能缓解不同视角之间域偏移给行人重识别带来的挑战,还能保持行人身份特征信息不发生改变,避免传统无监督域自适应方法的标签迁移。整体思路如图2所示。

图1 挑选自不同数据集同一摄像头的行人图像Fig. 1 Pedestrian images selected from the same camera view of different datasets

图2 研究算法的整体框架Fig. 2 The overall framework of the algorithm in this paper
为解决单个数据集中多个视角下行人图像风格不一致问题,提出低秩成分分解的字典学习模型,将不同相机视角下的行人图像特征分解成具有低秩特性的风格信息和具有判别性的行人身份信息,通过去除分解出来的风格信息,利用剩下的行人身份信息来训练判别字典学习模型,并将行人身份信息在其对应字典下的判别系数作为行人的潜在身份特征,作为最后行人身份相似性度量。为进一步缓解域偏移所带来的影响,利用同一身份行人属性的域不变性,将属性与特征关联模块嵌入到字典学习框架中,构建从特征到属性的映射,进一步挖掘属性与特征之间的关系。为了保证潜在视觉特征迁移到语义属性空间的过程中行人身份信息不发生改变,在字典学习模型中引入自重构约束以及身份判别特征与标签一致性约束,提升字典的判别性。通过构建标记样本身份判别特征和标签之间的关系,拉近同一行人潜在特征之间的距离,拉远不同行人潜在特征之间的距离。最后,通过选择置信度高的伪标签来调整模型参数,使其更适应目标数据的识别。
1 相关研究
1.1 无监督域自适应行人重识别
为解决有监督行人重识别方法和传统无监督域自适应行人重识别方法推广应用方面的不足,近2年研究者提出了一些新的无监督域自适应的行人重识别方法。其中包括基于样本存储的域自适应方法[1],基于块判别性特征学习的无监督行人重识别方法[2],基于自相似聚类的域自适应方法[3],基于元学习的域生成方法[4],基于对抗学习的域自适应行人重识别方法[5-7]以及基于域不变特征提取方法[8]。
基于样本存储[1]的方法利用样本存储实现了3种基本不变性,即样本不变性, 相机不变性和邻域不变性,从而减小了源域与目标域之间的差异。虽然基于块的判别性特征学习[2]也是较为有效的算法,但这类算法没有考虑块与块之间的关系,导致识别性能稍弱。基于自相似聚类方法[3]可获得较高的识别性能,但这种方法克服域偏移问题的本质是自训练,与现实场景不符。基于元学习的域自适应方法是最近提出的一种有效方法[4],该方法使用元学习来更新模型中的分类器参数,并使用多个数据集来训练模型,使模型具有域不变性。基于对抗学习[5-7]的域自适应方法可以实现不同数据集行人图像的迁移,但在迁移过程中容易造成不同样本的特有信息丢失,不利于行人身份信息保留。基于域不变特征提取的方法[8]通过提取不同数据集间的共有信息用作行人身份识别,该方法虽然有效,但未能充分考虑域信息的低秩先验性,从而导致提取的特征判别性较弱,限制了识别性能的进一步提升。这些方法虽然能取得不错的实验结果,但不能有效挖掘无标记样本的判别信息,导致限制识别性能的提升空间,且对标记的训练数据的数量和规模都要求较大。为实现域自适应的行人重识别,利用同一视角下行人图像风格的低秩先验性,来实现风格信息与行人身份信息的分离,该方法在不需要大规模有标记训练样本的情况下便能接近甚至达到基于深度学习的无监督域自适应方法识别性能。
1.2 基于字典学习的行人重识别
字典学习因其在模式识别和图像处理方面的优异表现,已成为解决行人重识别问题的常用方法。这类方法通常利用字典和表示系数的乘积来表示特征,并把表示系数作为最终的底层视觉特征,用于最终行人图像间的相似性度量;这类方法还可以利用模型的正则项约束来提升表示系数的判别能力。近年来,一些基于字典学习的行人重识别方法被提出。文献[9]提出了一种多任务字典学习的跨数据集迁移学习方法,该方法通过将字典分解成任务共享字典和视角特定字典,分别获取不同视角下行人的潜在属性和行人外貌差异表示。文献[10]提出一种基于卡方核的正则化线性判别分析行人重识别算法,使数据在低维空间能够保持高维空间的可分性,提高行人重识别算法性能。文献[11]提出一种面向无监督域自适应的联合属性身份嵌入字典学习方法,该方法通过视觉特征空间和语义属性空间的对齐来学习语义属性字典和视觉特征字典。文献[12]将多特征字典学习和自适应多特征图整合到一个联合学习模型中,使得学习到的字典具有判别性。虽然上述方法在行人重识别中能达到不错的识别性能,但无法有效克服相机风格差异带来的域偏移问题。基于成像风格的低秩先验性,提出了一种判别字典学习的图像风格分离模型,降低成像风格差异所导致的不同视角行人图像之间的域偏移。
1.3 基于属性学习的行人重识别

2 方法论
2.1 问题定义

2.2 判别性字典学习
在无监督的行人重识别任务中,由于不同数据集间存在域偏移问题,在源域上训练的模型常常不能直接应用到目标域上。为解决这个问题,基于行人图像风格信息的低秩先验性设计了一个域不变信息分离模型
(1)

由于不同视角下同一行人的属性具有域不变性,如果将训练样本的属性与潜在特征建立一种映射关系,挖掘潜在信息,有利于实现目标域样本属性的预测。除此之外,利用属性作为辅助信息也能提高编码系数的判别性。因此,将属性引入到行人重识别的模型中,公式如下
(2)
其中,W是转换矩阵,其作用是建立行人潜在特征空间与属性空间的联系,β是平衡参数。在公式(2)中,利用自重构思想来保证行人属性和潜在特征的一致性。
为提高字典的判别性和减少行人特征之间的歧义性,将标签信息应用到模型当中,公式如下
(3)

(4)

2.3 模型优化
对于所有变量来说,公式(4)是非凸函数。然而,固定其它变量而更新其中某一个变量时,模型具有全局最优解。因此采用交替迭代法来获得每个变量的最优解。

(5)
式(5)具有如下形式的解析解
(6)

(7)


(8)

(9)
其中,Fv可由奇异值分解 (SVT) 算法[17]求解公式(10)得到
(10)

(11)
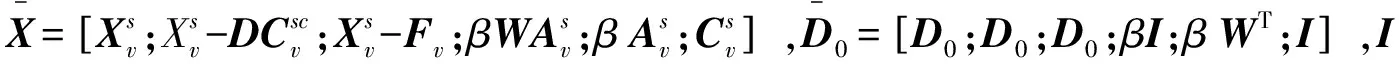
(12)

(13)
为便于求解,引入辅助变量Ph,公式(13)可写为
(14)
其中Ph可通过求解式(15)来得到
(15)

(16)


(17)
公式(17)可直接用 SVT 算法来求解,为此对其进行松弛化处理
(18)
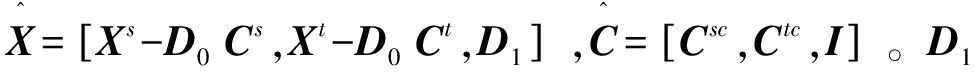
(19)
公式(19)可使用拉格朗日对偶法[18]进行求解。

(20)
为便于求解,引入2个变量H和T,公式(20)可表示为
(21)
其中,更新H和T的目标函数分别表示为
(22)
(23)
公式(22)和(23)均可采用奇异值分解(SVT)算法来求解。然后,更新D0,其目标函数为
(24)
可将公式(24)简化为
(25)
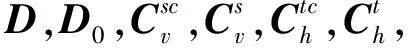
(26)
为便于求解,公式(26)可松弛化为
(27)
从而得到更新L的解析表达式
(28)

βCsCsTW+WAsAsT=βCsAsT+LAsT。
(29)
公式(29)是Sylvester方程,利用Bartels-stewart算法[19]求解。为便于理解,将求解公式(4)的优化算法总结在表1中。

表1 域自适应行人重识别低秩分解字典学习算法
2.4 相似性度量

(30)
同时,得到映射矩阵W后,可预测目标域的属性特征At
At=(WTW)-1(WTCt),
(31)
在得到测试样本行人身份信息编码系数Ct,行人属性表示At后,通过余弦距离[20]得到行人图像对的相似性分数
(32)
其中,zl(l=a,b)表示语义属性空间或视觉特征空间中的一个向量,ε>0是一个常数。为综合潜在视觉特征空间和语义属性空间的互补性,最终的相似分数可由下式来求得
simfinal=τsimC+(1-τ)simA,
(33)
其中τ为权值,simC和simA分别表示潜在特征相似性分数和属性相似性分数。由于属性的判别性较弱,因此取τ=0.8。
3 实 验
3.1 数据集和实验的设置
为了验证算法的有效性,选择了4个具有挑战性的数据集:VIPeR[21],PRID2011[22], CUHK01[23],GRID[24]。其中,VIPeR,PRID2011和GRID数据集有2个摄像头且每个行人身份在一个摄像头视角中只有一张图像。PRID2011和GRID都包含干扰图像,因此,更接近真实场景。CUHK01也有2个摄像头,但每个身份在一个摄像头下有2张图像。具体的数据集描述如表2所示。
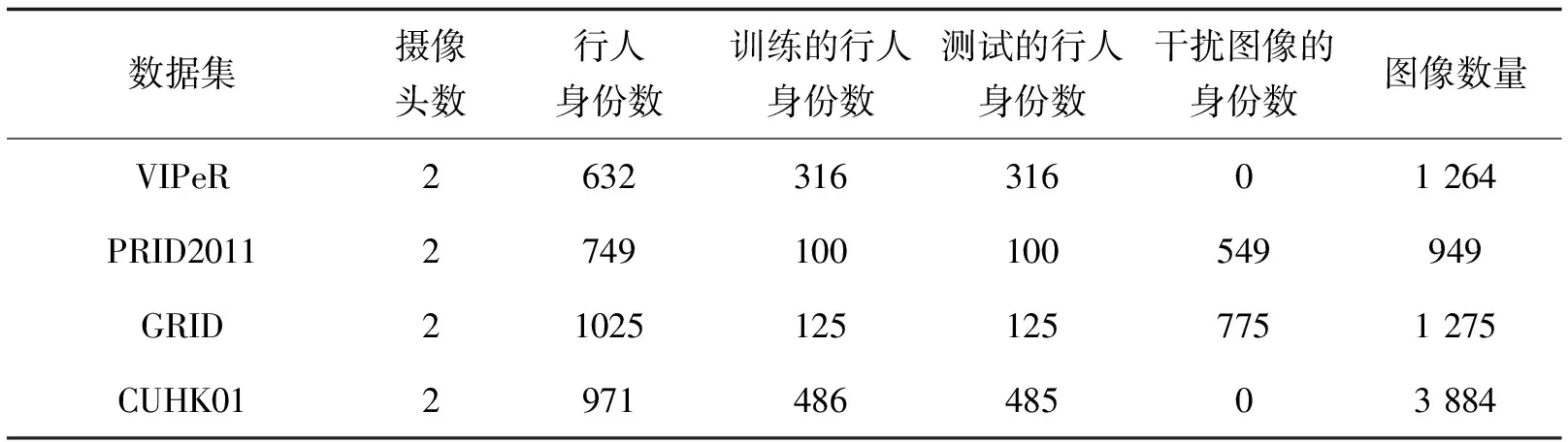
表2 实验数据集的详细设置
在上述的数据集中,只有VIPeR, PRID2011,GRID标注了语义属性。在算法中,这些被标注了语义属性的数据集可以用作训练集,而未标注语义属性的数据集可以用作测试集。具体来说,将上述的单个数据集的全部样本用来训练模型,而目标数据集中的样本按行人身份分成互不重叠的2个子集,一个参与模型的训练,另一个用于模型的测试,随机取10组数据的平均值作为实验结果。测试时,所有的干扰图像都会被用作测试集样本。该模型一共有10个参数,其中包括字典D和D0的大小d和d0,和8个超参数α1,α2,λ1,λ2,δ,δ1,β,γ。设定d=650,d0=800,α1=0.1,α2=0.1,λ1=0.6,λ2=0.5,δ=5,δ1=6,β=0.15,γ=0.5。在特征的选择上,使用Gaussian of Gaussian(GOG)描述符[25]来描述行人的外貌特征。在属性表示上,使用的VIPeR,PRID2011,GRID数据集上的属性定义是由R.Layne 等人[26]所标注的。
3.2 对比实验结果
在VIPeR上的实验:将PRID2011作为源数据集,VIPeR作为目标数据集,实验结果与UMDL[9],SAAVF[11],MFFAG[12],ADV[27],GL[28],SDC[29],CAMEL[30],DECAMEL[31],AIESL[32],SNR[33]比较,对比结果如表3所示。由此可以看出,在VIPeR上,研究方法的性能超过了深度学习的方法DECAMEL[31]和传统的无监督域自适应行人重识别方法UMDL[9],SAAVF[11],MFFAG[12],ADV[27],GL[28],SDC[29],CAMEL[30],AIESL[32],SNR[33]。证明了方法的有效性和优越性。

表3 在VIPeR数据集上的识别性能
在GRID上的实验:将VIPeR作为源数据集, GRID作为目标数据集,实验结果与DIMN[4],AIESL[32],SNR[33],TLSTP[34]进行了比较,对比结果如表4所示。由于GRID数据集携带了大量干扰图像,因此在该数据集上进行行人身份的匹配充满了挑战。由表4中的数据可以看出,提出的方法在性能超过了传统无监督域自适应行人重识别方法AIESL[32],SNR[33],TLSTP[34]和深度学习方法DIMN[4]。

表4 在GRID数据集上的识别性能
在CUHK01上的实验:为进一步验证算法的有效性,将VIPeR用作源数据集,CUHK01用作目标数据集,实验结果与UDML[9],MFFAG[12],CAMEL[30],DECAMEL[31],AIESL[32],TSR[35],DAS[36],UJSDL[37]进行比较,对比结果如表5所示。由此可以看出,提出的方法在性能上超过了传统的无监督域自适应行人重识别方法UDML[9],MFFAG[12],CAMEL[30],AIESL[32],TSR[35],DAS[36],UJSDL[37]和深度学习方法DECAMEL[31]。
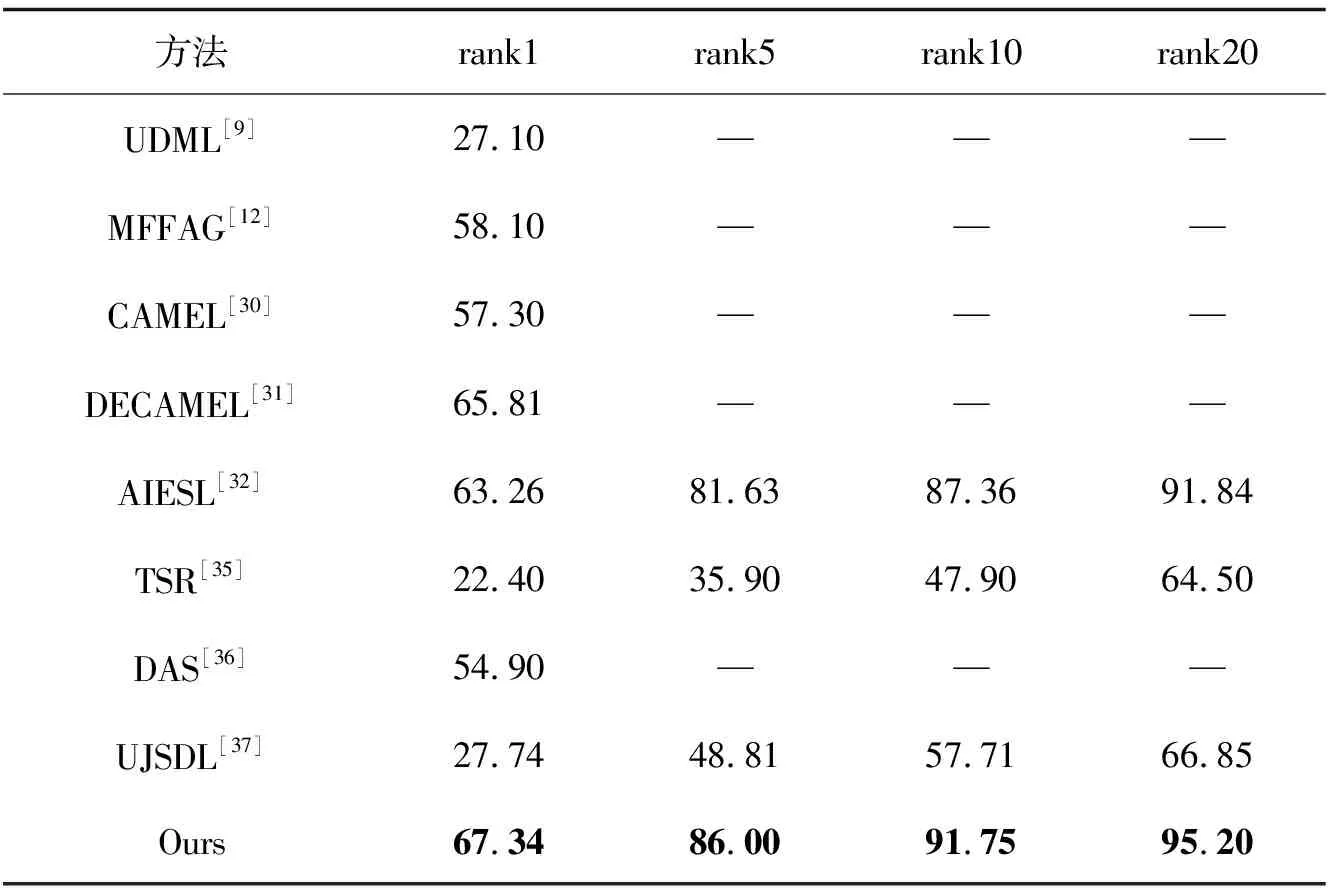
表5 在CUHK01数据集上的识别性能
3.3 算法分析
3.3.1 收敛性分析
目标函数(4)对变量{D,D0,W}来说是一个非凸函数,然而固定其它变量而更新其中某个变量时,模型具有全局最优解。在VIPeR数据集上对算法的收敛性进行了验证,其结果如图3所示。由此可发现,对于变量 {D,D0,W}而言,算法是收敛的,而且当迭代次数达到10次的时候,算法能达到稳定解。因此,将迭代次数设置为10。
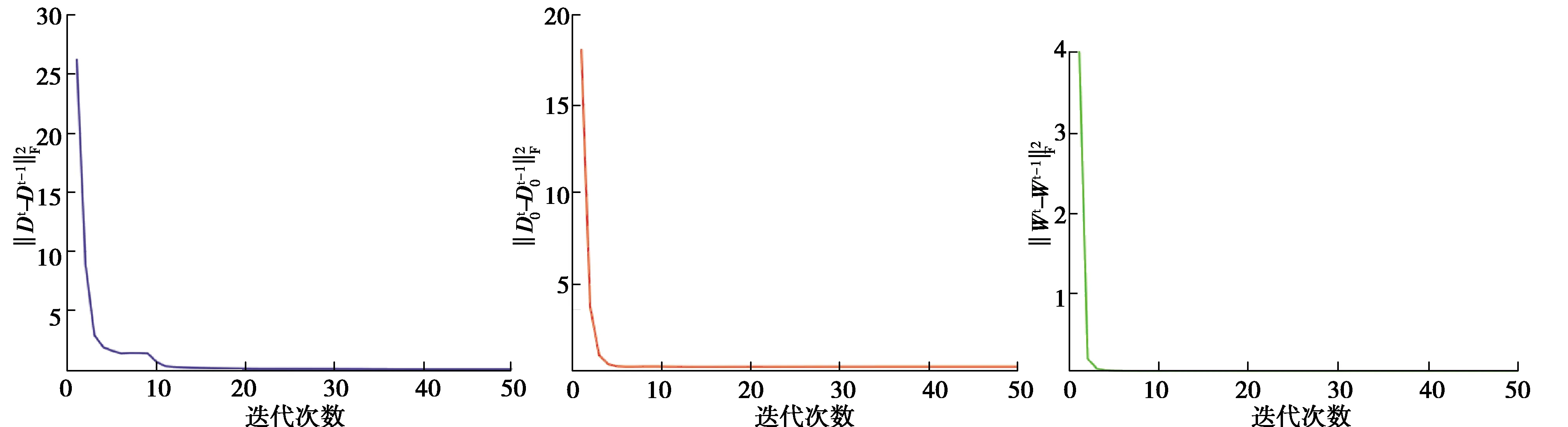
图3 算法在VIPeR数据集上的收敛性分析Fig. 3 Convergence analysis of the algorithm on VIPeR dataset
3.3.2 算法的复杂度分析

3.3.3 消融性分析
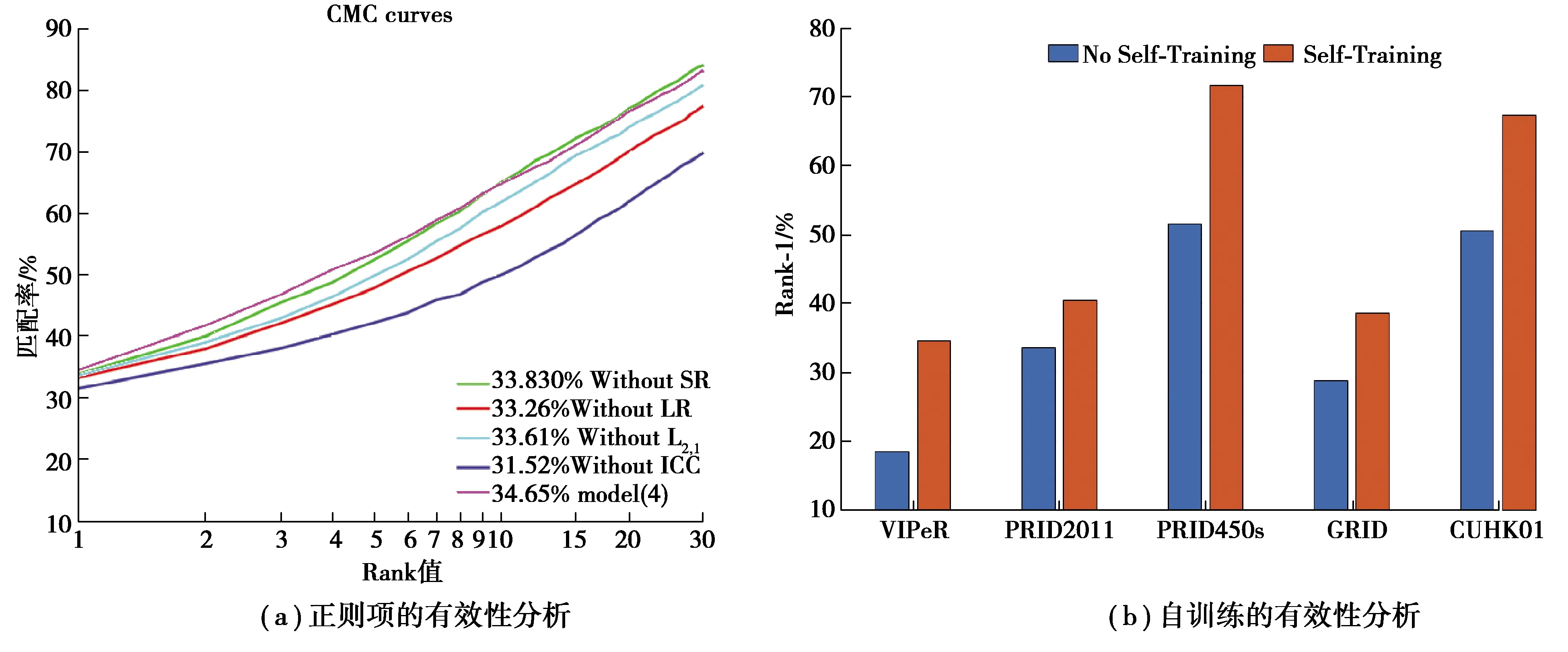
图4 算法的消融性分析Fig. 4 Ablation analysis of the algorithm
3.4 参数的选择
在算法中共有8个超参数α1,α2,β,λ1,λ2,δ,δ1,γ和字典的尺寸大小d,d0需要选择,根据实验经验,设置d=650,d0=800,α1=0.1,α2=0.1,δ1=6,γ=0.5。其余主要模块参数β,λ1,λ2,δ的设置采用交叉验证方法来进行选择。在此过程中,改变其中某个参数,其余参数固定,研究该参数对识别性能的影响,找到最优参数值。对于β,δ,λ1,λ2来说,其变化范围从10-6到103,每次以10的倍数递增。图5(a)—(d)给出了这4个参数取不同数值时的识别性能,由此可以看出,当λ1=0.6,λ2=0.5,δ=5,β=0.15时,算法能取得较为满意的结果。


图5 算法在VIPeR数据集上的参数分析Fig. 5 Parameters sensitivity analysis of the algorithm on the VIPeR dataset
4 结 论
根据同一视角下行人图像所表现的低秩先验性,提出对风格鲁棒的无监督域自适应行人重识别方法。该方法将反映图像相机风格的信息从图像特征中分离出去,极大缓解数据集之间由风格差异引起的域偏移给跨数据集行人重识别带来的影响。在算法中,为建立目标数据集与源数据集之间的联系,提出联合学习算法,将行人身份特征信息、语义属性和标签信息嵌入到一个字典学习模型中。为了有效利用目标数据集中的信息,将目标数据集中被分配伪标签且置信度较高的样本选出来调整已训练模型参数。在域自适应行人重识任务中,算法比传统的无监督域自适应行人重识别方法及部分基于深度学习的无监督域自适应行人重识别方法表现出较强的竞争力。
猜你喜欢
意林(2021年5期)2021-04-18
疯狂英语·新策略(2019年10期)2019-12-13
小学阅读指南·低年级版(2019年11期)2019-07-01
当代陕西(2019年10期)2019-06-03
扬子江(2019年1期)2019-03-08
数学小灵通·3-4年级(2017年9期)2017-10-13
小天使·一年级语数英综合(2017年6期)2017-06-07
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
河南科技(2014年23期)2014-02-27
