
采用OpenFlow交换机的服务器负载均衡策略
2021-12-21 03:07:38曾友雯李双庆邹东升
重庆大学学报 2021年11期
曾友雯,李双庆,邹东升
(重庆大学 计算机学院,重庆 400044)
随着云计算的兴起,云数据中心往往通过负载均衡手段协调服务器池中的服务器负载分配,以获得优化的响应性能[1-2]。近年来,软件定义网络SDN(software defined network)在云数据中心广泛应用。SDN将控制平面与数据平面解耦合,由SDN控制器感知网络状态[3-4]。在SDN网络中,控制器通过OpenFlow协议[5]动态变换交换机中的流表规则,实现对网络的动态控制。一些研究利用这一特点,通过动态变换用作负载均衡的交换机LBS(load balancing switch)中的流表规则来实现服务器间的负载均衡。负载均衡的策略集中在控制器端,其优点是通过软件定义的方式动态部署不同的负载均衡策略,并且节省了传统负载均衡器方式的部署成本[6]。
近年来对SDN环境下的服务器负载均衡领域的研究主要集中在服务器均衡策略[7-8]、流表资源优化[9-11]等方面。Zhong等[7]将用户请求定向到实时响应时间最短的服务器处理,使服务器保持负载均衡的状态。Handigol等[8]提出Plug-n-Server流量负载平衡方案,将控制器模块化,通过控制器全局管理资源,使控制器高效有序地调度资源。Wang等[9]使用通配符规则转发服务请求,将请求端按IP地址前缀划分为多个区块,根据负载动态分解或合并各区,以期占用LBS较少的流表项资源。Lin等[10]提出通过给服务器分配优先级设置不同的通配符规则,适用于大规模数据中心,以更少的流表项达到更高效率。Mao等[11]提出单流表和组流表结合的动态流表设计算法,负载均衡时调整更少流表项,减少负载均衡流表变换。
文中提出一种采用OpenFlow交换机的服务器负载均衡策略,使用分区通配符规则均衡转发服务请求,在LBS上预先部署多地址定向流表,SDN控制器周期性采集LBS活跃连接数,据此计算出服务器负载状态。利用蚁群算法的信息正反馈和启发式搜索特性,在服务器负载偏差超过阈值时求解负载调度方案,迁移负载以达到负载均衡的目的。
1 基于通配符的流表规则
采用负载均衡策略的服务器集群对外以单一IP地址形成单一映像(single image)。作为负载分配器(load dispatcher)的LBS按照SDN控制器部署的流表规则转发请求到指定后端服务器。如果流表记录每个请求的转发规则,会产生流表溢出,影响转发效率,增大控制器处理开销[12-13]。
将服务请求按源IP地址前缀划分为多个区块,分别用通配符表示每个区块相同的地址前缀部分,将其映射到OpenFlow流表匹配字段中。在LBS转发服务请求时,由于多个请求匹配同一转发规则,因此称之为多地址定向流表MDFT(multi-address directed flow table),如图1所示。MDFT能有效解决流表过多的问题,主要用于流量转发和流量数据监控。
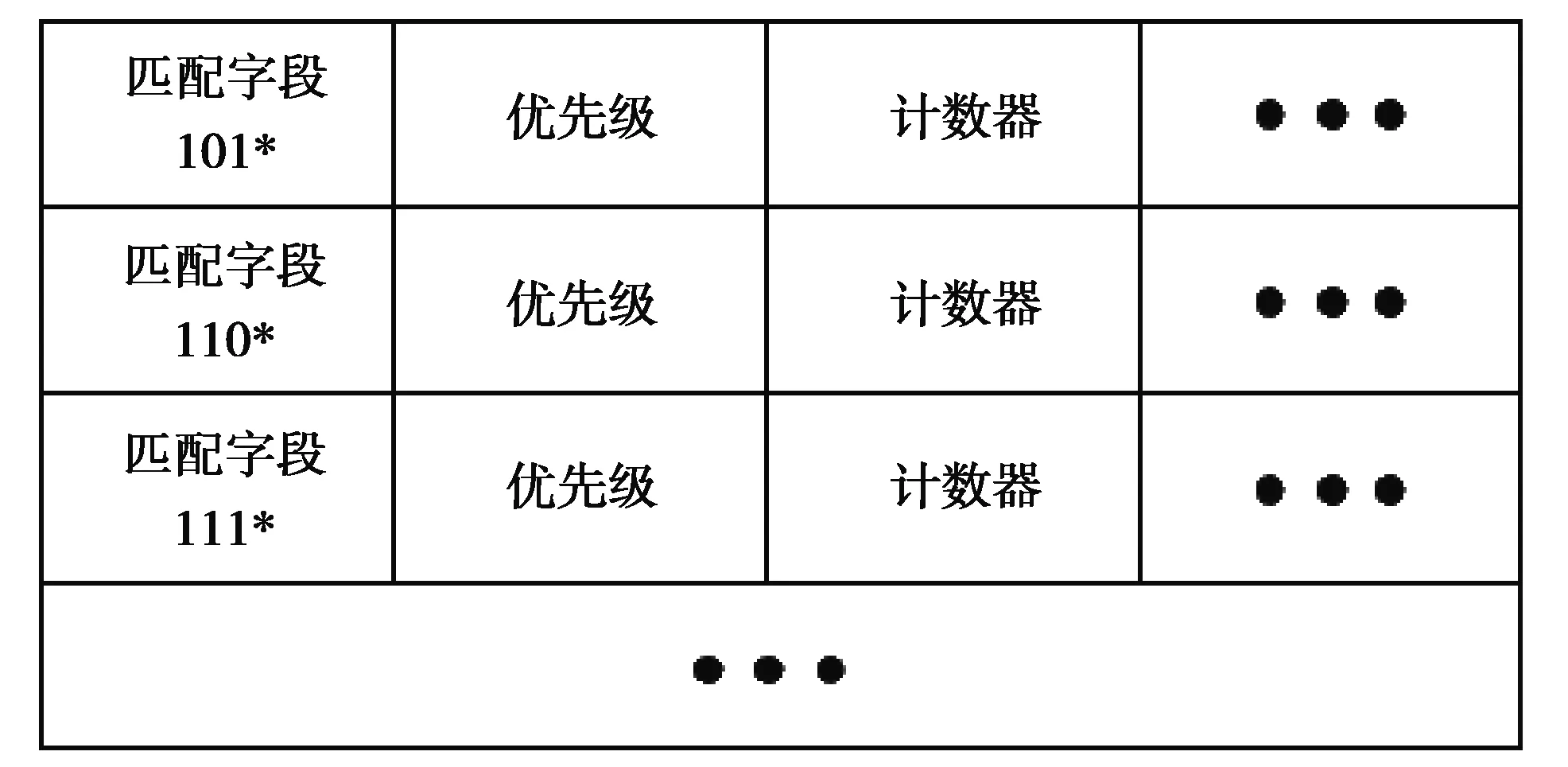
图1 多地址定向流表表项Fig. 1 Multi-address directed flow entry
当需要平衡负载,将原区域的负载重新分配时,引入单地址定向流表SDFT(single-address directed flow table)。在负载均衡调整期中同时存在调整前的TCP连接和调整启动后的新连接。SDFT登记每条新请求的TCP连接,而调整前的流量则继续沿用原来的规则,从而保障TCP连接映射服务器的一致性。
在匹配规则上约定SDFT优先级高于MDFT,当请求同时满足SDFT和MDFT匹配条件时,按照SDFT规则转发流量。多个MDFT可以将服务请求转发到同一服务器,但MDFT间IP通配符地址不能重叠,以保证服务请求转发到唯一服务器。MDFT生存时间较长,在不需要调整流表项时,服务请求按照MDFT转发。SDFT生存时间较短,仅在负载均衡调整期使用。
2 基于OpenFlow交换机的负载均衡策略
如图2所示,假设部署x台服务器Si(i=1,2,…,x),将请求端按源IP地址前缀初始划分为m个区块Bk(k=1,2,…,m),每个区块分别映射一个MDFT表项,其IP地址前缀为Ipre_k,每个区块覆盖n个请求端源IP地址,SDN控制器对应生成并下发m个流表项Fk(Ipre_k,Si,p)到LBS,其中k=1,2,…,m,p为流表项的优先级。地址前缀满足Ipre_k的服务请求通过LBS匹配流表项Fk(Ipre_k,Si,p)后被转发到服务器Si。当不同服务器分配到的负载发生不均衡时,SDN控制器需要及时感知并做出负载再分配以均衡服务器负载。
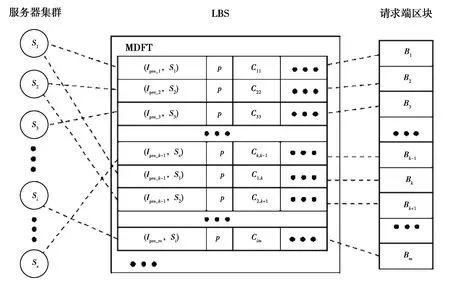
图2 负载均衡交换机转发示意图Fig. 2 Diagram of load balancing switch forwarding
2.1 服务器负载计算
在衡量服务器负载时,主要分为直接或间接方式获取服务器的负载状态。李艳冠等[14]和于天放等[15]通过控制器采用SNMP协议获取服务器CPU利用率、内存利用率等指标来计算服务器负载。文献[7]通过控制器发送Ping命令测试服务器实时响应时间,根据实时响应时间度量服务器负载。上述直接获取服务器负载状态的方法可以较准确地衡量服务器的负载情况,但该方式对服务器缺乏透明性,对服务器的响应方式有一定的要求,因此存在一定的局限性。另外,该方式需要控制器直接参与服务器数据采集,增加了控制器的开销。Boero等[16]提出通过交换机服务请求的入队速率和处理速率衡量后端服务器负载不均衡程度,将交换机中入队速率大于处理速率的流量重路由,从而达到后端服务器负载均衡的目的。该方法采用对服务器透明的机制,虽不能计算出服务器实际负载,但可以有效衡量后端服务器负载不均衡程度,减少控制器资源消耗,不限制服务器的响应方式。

Li=θ*Ci,
(1)
式中,θ为活跃连接数对服务器负载的影响因子。当服务请求到达LBS,LBS中匹配的流表项通过计数器对TCP的SYN位和FIN位计数,SDN控制器周期性采集LBS流表项中的该计数值,从而计算出活动连接数。
考虑负载均衡出现抖动,采取t次采样数据计算平均数的方法来计算确定服务器平均负载
(2)
式中,Li[z]为在第z时刻服务器的总负载,t为采样次数。
通过方差表示服务器间负载失衡度δ为
(3)
式中,δ(t)为t时刻服务器间负载失衡度。δ(t)越大,表示服务器间的不平衡程度越大。SDN控制器触发负载均衡策略的条件为
δ(t)>ω,
(4)
式中,ω为负载失衡度阈值。
2.2 自适应动态负载均衡策略
文中提出一种自适应动态服务器负载均衡策略,利用SDN控制器向LBS部署MDFT和SDFT流表项重定向服务请求,SDN控制器采用基于蚁群算法的负载重定向算法ACO-LBSA(ACO-based load balance switching algorithm)来决策服务器间的负载迁移,以达到负载均衡。
2.2.1 负载重定向方案选择
蚁群算法[18-20]是一种模拟蚂蚁寻找食物过程中发现路径的智能优化算法,该算法具有分布计算、信息正反馈和启发式搜索的特点。在研究场景中,负载均衡策略需要实时监控全局负载变化,并自适应均衡负载分配,因此采用蚁群算法以达到较快的收敛速度和较高的求解准确度。将服务器负载情况作为蚁群算法的信息素,重定向活动连接数的倒数作为启发函数,服务器间负载失衡度作为路径长度,算法目标是求解过载服务器负载重定向最优方案。
假定在当前时刻服务器Si过载。负载重定向算法过程描述如下:
1)初始化信息素浓度及每只蚂蚁。在云数据中心初始化阶段,考虑服务器之间的处理能力异构性,用服务器的负载处理能力对信息素τki初始化:
τki=di,
(5)
式中,di表示为服务器Si处理负载的能力。创建包含m个MDFT表项、x个服务器的蚂蚁对象,初始化服务器失衡度。蚂蚁随机选择路径(Fk,Si),路径表示为将流表项Fk重定向到服务器Si。并将分配过的MDFT从搜索列表gh中删除,加入到禁忌表。
2)选择重定向服务器。蚂蚁按照概率与轮盘赌算法选择服务器重定向MDFT,在t时刻第h只蚂蚁选择将流表项Fk重定向到副本服务器Si的概率
(6)
式中:τki(t)表示t时刻将流表项Fk重定向到服务器Si的路径上的信息素浓度;α为信息素启发因子,表示蚂蚁在路径上留下的信息素的重要性;β为期望启发因子,反映了启发函数的重要性。ηki(t)为启发函数表示服务器Si处理流表项Fk转发流量的可见度,本策略采用重定向活动连接数定义启发函数
(7)
3)更新任务禁忌表、搜索列表和服务器负载情况。根据步骤1中的方法更新禁忌表、搜索列表和服务器负载情况。
4)每只蚂蚁形成一个局部最优解。当一次迭代结束后,每只蚂蚁按照式(8)选择最小失衡度的解为最优解,最优解加入到序列List<(Fk,Si)>中,其中a代表蚂蚁的数量,h代表第h只蚂蚁
(8)
5)更新信息素。为了防止信息素堆积,对每只蚂蚁完成分配后,调整信息素:
(9)
(10)

6)重复进行迭代,直到达到最大迭代次数,计算出最优解,并给出最优负载重定向矩阵
(11)
若eki的值不为空,则表示将流表项Fi的负载重定向到服务器Sj;若为空,则不重定向。
2.2.2 基于蚁群算法的负载重定向算法
根据前文求解到的最优负载重定向矩阵E,SDN控制器向LBS下发流表项重定向服务请求,实现负载均衡。基本思路为:SDN控制器下发优先级为p1(p1>p)的流表项Fnew(Ipre_k,Si,p1)和转发到新服务器Sj流表项Fnew(Ipre_k,Sj,p),当服务请求到达Fnew(Ipre_k,Si,p1)时,流表项检查TCP标识SYN位。若SYN=1,视为新的TCP流,由SDN控制器下发优先级为p2(p2>p1)的源IP地址为Ikj的SDFT表项fnew(Ikj,Sj,p2)定向到新的服务器Sj,并将流表项加入SDFT表项集合fj,将新的TCP请求重定向到新的服务器处理;若为原来持续的流,由SDN控制器下发流表项fnew(Iki,Si,p2),设置空闲超时时间idle_time,从而保障TCP连接映射服务器的一致性,并将流表项加入集合fi。通常情况下[9],若在60 s内无数据传输,视为连接关闭,因此实验中设置idle_time 为60 s。超过idle_time后,删除fj和Fnew(Ipre_k,Si,p1),查看fi,若为空则删除集合,实现无差错的负载重定向。该算法伪代码如表1所示。

表1 ACO-LBSA算法
3 实验结果与数据分析
3.1 实验环境
研究在Ubuntu环境下使用Mininet搭建SDN网络仿真实验环境,选择Ryu作为SDN控制器,选择OpenVSwitch作为负载均衡交换机,构建实验网络,该网络拓扑结构如图3所示。

图3 实验网络拓扑Fig. 3 Experimental network topology
实验为服务器集群配置4台服务器,服务请求端选择整个IP地址空间的一个子集,将其划为24个初始区块,每个服务器初始按平均方式各分配6个区块。
3.2 实验分析
以云数据中心为目标,模拟4种场景下分别使用Random算法、Round Robin算法和ACO-LBSA算法进行均衡负载的过程。4种场景分别为:①低负载运行,服务器负载均在10%~20%;②负载失衡度较高,不同区块的负载相差可达10倍;③服务请求突增,某些区块的负载在某个时刻陡增一倍;④高负载运行,服务器负载均在80%~90%。如图4~图7所示,为4种场景下发生一次负载均衡过程前后总共180 s内服务器平均响应时间,其中每隔5 s计算一次平均响应时间。

图4 场景(1)下服务器平均响应时间变化趋势Fig. 4 Trend of average server response time under scenario (1)

图5 场景(2)下服务器平均响应时间变化趋势Fig. 5 Trend of average server response time under scenario (2)
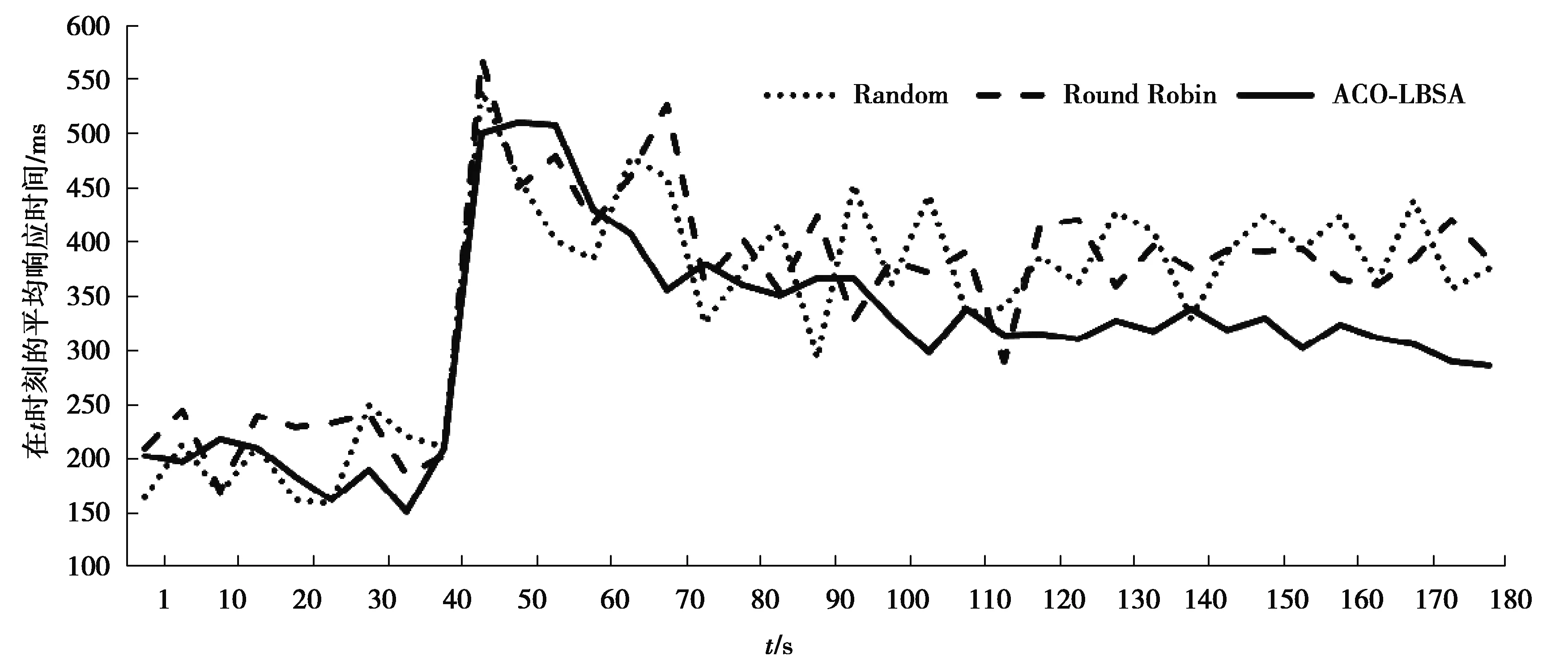
图6 场景(3)下服务器平均响应时间变化趋势Fig. 6 Trend of average server response time under scenario (3)

图7 场景(4)下服务器平均响应时间变化趋势Fig. 7 Trend of average server response time under scenario (4)
如表2所示,为分别采用ACO-LBSA算法与Random算法、Round Robin算法在4种场景下服务器响应性能对比。

表2 服务器响应性能对比
从图4~图7和表2中可以看出,在场景(1)下,采用3种算法的服务器平均响应时间相差不大,但采用ACO-LBSA算法的服务器平均响应时间略有优势,且服务器平均响应时间波动更小;在场景(2)下,采用ACO-LBSA算法的服务器平均响应时间明显优于其他2种算法,且服务器平均响应时间波动更小;在场景(3)下,采用ACO-LBSA算法的服务器平均响应时间明显优于其他2种算法,且服务器平均响应时间的波动明显降低;在场景(4)下,采用ACO-LBSA算法的服务器平均响应时间优化较场景(1)~场景(3)下程度更高,服务器平均响应时间波动较其他算法明显降低。
根据以上实验可以看出,文中提出的ACO-LBSA算法较Random算法和Round Robin算法在服务器响应性能方面有所改善,在云数据中心处于负载失衡度较高、服务请求突增和高负载运行等典型场景下,较其他2种算法对服务器响应性能改善更为明显。
4 结束语
提出了一种采用OpenFlow交换机的负载均衡策略。通过通配符规则缩减流表项数量,分别采用MDFT和SDFT用于均衡的负载分配和负载调整期的负载过渡,以活跃连接数度量服务器负载,从而使负载均衡对服务器保持透明。当服务器负载失衡度超过阈值,SDN控制器通过蚁群算法求解出最优的负载调度方案,并向LBS下发MDFT流表项和SDFT流表项重定向服务请求,以达到负载均衡。通过仿真实验显示文中的策略较随机和轮转策略性能更优。后续研究工作将在此基础上讨论引入区分服务的负载均衡策略。
猜你喜欢
通信技术(2022年5期)2022-06-11 00:47:44
河北大学学报(自然科学版)(2020年4期)2020-09-02 14:23:38
计算机工程与应用(2020年7期)2020-04-07 10:48:54
电子测试(2018年21期)2018-11-08 03:09:34
网络安全和信息化(2018年3期)2018-11-07 03:02:44
西安电子科技大学学报(2018年5期)2018-10-11 12:32:08
计算机与网络(2018年19期)2018-09-10 14:44:16
科学与财富(2018年12期)2018-06-11 01:49:24
中南民族大学学报(自然科学版)(2017年3期)2017-10-18 01:04:38
移动通信(2017年13期)2017-09-29 16:30:11
