
基于谱聚类的BaaS资源负载均衡调度算法
2021-12-21 03:08:32熊衍捷杨晋生
重庆大学学报 2021年11期
熊衍捷,高 镇,李 根,杨晋生
(天津大学 a.微电子学院; b.电气自动化与信息工程学院,天津 300072)
近年来,区块链[1-2]技术不断发展壮大,作为区块链与云计算结合的产物——区块链即服务,正改变着传统的云计算服务模式[3],使区块链技术成为一种触手可及、开箱即用的工具服务于大众。超级账本[4](Fabric)是BaaS的核心模块,提供基于联盟链的身份认证、交易背书及区块上链等功能。网络节点peer负责维护账本(Ledger),依据具体功能的不同,可分为提交节点(committer peer)和背书节点(endorser peer),Fabric从1.0版本开始采用了多通道(channel)的设计,尽管有利于增强用户的隐私性和系统的扩展性,但是每一个peer均要处理来自不同通道的事务且保存一份相应的账本,将对有限的计算资源带来挑战并增大磁盘空间的存储压力。改善BaaS的性能已经变得愈加迫切。
基于Kubernetes[5]的云计算平台,才丽[6]提出了面向BaaS的Best-Balanced加权评分模型解决资源负载均衡问题,Best-Balanced算法从资源量负载平衡、资源量剩余量平衡和不同资源类型间负载平衡来衡量资源分配的平衡性。Medel等[7]通过基于Petri网的性能模型对Kubernetes容器的部署和终止开销进行分析,提出合理的Pod下容器配额规则,最后实现一种考虑容器资源争夺现象的调度算法。
基于多通道的设计,如果多个peer加入了同一通道并被调度至同一虚拟机,即使通道内的业务量不大,其任意时间点的负载均为每一个peer负载的总和,也可能造成虚拟机的负载过重,甚至发生单点故障,从而降低用户服务质量。针对上述问题,笔者提出了一种面向多通道的基于谱聚类(Spectral Clustering)的负载均衡调度算法SC-channel,使用典型的NJW[8]谱聚类算法进行聚类分析,采用Jaccard相似系数依据对应的通道度量peer之间的相似度,使用基于数量加权的k-means算法做最后的特征聚类,并与平台默认提供的调度算法进行对比,实验结果证明了所提出算法能够增强系统的可靠性与可用性。
1 SC-channel算法描述
谱聚类算法[9]是机器学习领域中的一种无监督学习算法,基于图的分割理论划分样本集,以达到类内样本点距离最小而类间的样本点距离最大。相较于传统的聚类算法,如k-means聚类[10]、层次聚类[11]、基于密度的聚类(DBSCAN)[12]等,能够在任意形状的样本空间上聚类且收敛于全局最优解。为了充分发挥谱聚类适应性强、收敛度高的优势,需要合理地选择具体谱聚类算法并依据问题空间选择度量样本间距离的方式。
1.1 算法可行性分析
如图1所示,Fabric产生一笔交易的基本流程如下:

图1 交易的基本流程Fig. 1 The basic process of transaction
Step1 客户端创建一笔交易,该交易包括客户端的ID、链码(chaincode)ID、提交交易自身的载体、时间戳、其他域客户端的签名,依据背书策略被发送到所选择的背书节点;
Step2 背书节点模拟交易并产生背书签名;
Step3 客户端收集到足够多的交易背书后,通过排序(ordering)服务广播该交易,如果客户端没有设法为交易收集背书,则放弃这个交易并稍后再试;
Step4 排序服务向各peer节点提交交易,在完成最终的确认后交易被提交上链。
图1中的①②③④对应于step1、2、3、4。除步骤3外其余基本流程均需要peer的响应,因此peer在Fabric中承担着主要的计算任务。
如表1所示,该实验将4个peer以两两一组的方式分别放置于2台虚拟机(1G2核)192.168.10.157和192.168.10.158上,创建通道channel1和channel2,给定每秒处理的交易量分别为6和3进行2组实验,每组实验重复3次,结果如图2、图3所示。

表1 部署peer的两组实验
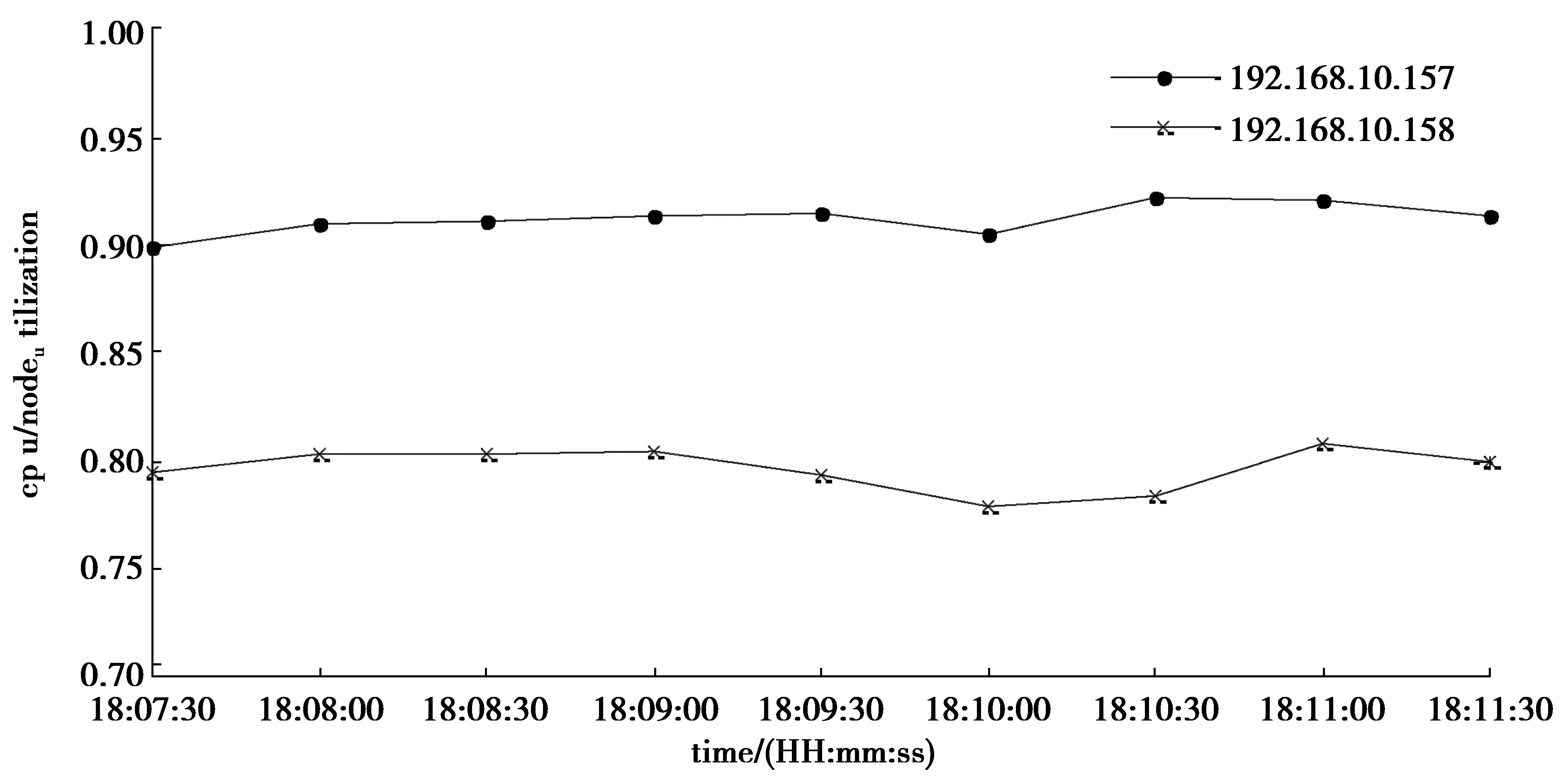
图2 同一通道的peer在不同虚拟机的结果Fig. 2 Resulets of peer in the same channel in different virtual machines
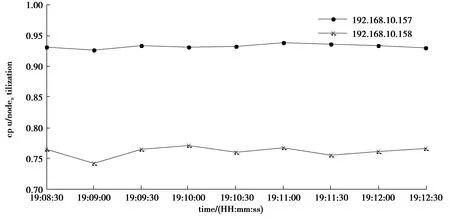
图3 同一通道的peer在相同虚拟机的结果Fig. 3 Resulets of peer in the same channel in the same virtual machine
如图2所示,将同一通道的peer放置于不同虚机上,通过对peer合理的分类,使各虚拟机cpu利用率更接近平台的平均cpu利用率,负载的均衡度更高,然而这仅考虑的是一种简单的场景,如果peer的数量较多,需要创建的通道数量也较多,那么如何确定分类原则将变得复杂。由于谱聚类算法不依赖于样本的形状,聚类效果优异,因此采用该算法对复杂场景下的peer做聚类,以此来提高平台的可用性。
1.2 算法思想描述
根据图划分准则的不同,经典的谱聚类算法可分为PF算法[13]、SM算法[14]和NJW算法等,NJW算法采用高斯径向核(Radial Basis Function,RBF)构造相似矩阵W,即
(1)
能够直接得到聚类效果较好的样本集k路分割,因此选择NJW算法作为文中谱聚类算法的具体实现,该算法的主要步骤如下:
Step1 计算相似矩阵W,获得度矩阵D,得到拉普拉斯矩阵L;
Step2 计算矩阵L的前k个最大特征值所对应的特征向量x1,…,xk,构造矩阵X=[x1,...,xk]∈Rn×k;
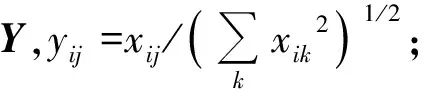
Step4 使用k-means算法或其他经典算法按行对矩阵Y聚类。
尽管NJW算法具有聚类效果好、多路分割的优势,但是簇类数目C和尺度参数σ需要人为选定,具有一定的不确定性。对于簇类数目C的选定,文献[15]提出了一种启发式确定类数的DP-NJW谱聚类算法,根据密度分布确定类中心和类数,Zeng等[16]通过使用模糊聚类测量谱聚类数目,Li等[17]基于传统的量子聚类,能够在不知道聚类数量的情况下找到任何形状的聚类,进一步缩短了计算时间,提高了计算效率;对于尺度参数σ的选择,Xie等[18]提出了局部标准偏差(Local Standard Deviation Spectral Clustering,SCSD)谱聚类算法改进NJW和Self-Turning算法[19]对σ的选取,Mohanaval- li等[20]计算每个数据点i与其他点的距离,基于该点的度Di使用四分位数自动确定σi,具有较好的聚类效果,文献[21]提出SC_SD和SC_MD两种谱聚类算法,其定义样本的标准差与样本到其余样本的距离的均值作为邻域半径,具备完全的自适应性。
将平台下具备计算能力的虚拟机数量作为簇类数目C,使得类之间隔离计算资源,能够较好解决人为因素带来的影响。相似矩阵W的构造,由于peer样本集属于离散型、集合型数据,不再适用于采用RBF构造的相似矩阵,因此采用Jaccard相似系数度量样本间的距离。Jaccard系数适用于表示有限样本集合的相似性与差异性,假定x和y分别具有n维特征(n个通道),xi和yi的取值为二元类型数值{0,1},对于计算x与y的距离,Jaccard系数使用a,b,c,d4个参数来计算相似度,即
(2)
式中:1)a表示样本x和y中满足xi=yi=1的数量,在SC-channel中表示x和y加入同一通道的数量。2)b表示样本x和y中满足xi=1,yi=0的数量,在SC-channel中表示x加入某通道而y未加入该通道的数量。3)c表示样本x和y中满足xi=0,yi=1的数量,在SC-channel中表示x未加入某通道而y加入该通道的数量。4)d表示样本x和y中满足xi=yi=0的数量,在SC-channel中表示x和y均未加入同一通道的数量。
由式(2)可知,加入相同通道数量越多的x和y相似度越高,越趋向于分入同一个类,而据1.1节实验可知,加入不同通道的x和y处于同一虚拟机,即处于同一类簇,使负载均衡度提高,文中使用改写的Jaccard系数构造相似矩阵,即
(3)
使用式(3)计算peer间的相似度将更适合文中的研究问题。SC-channel算法伪代码如算法1所示。
算法1 SC-channel伪代码
输入:数据集Peer={peer1,peer2,…,peern},标签集Channel={channel1,channel2,…,channelm} ,类别数C。
输出:聚类后的各簇H={h1,h2,…,hC},按簇binding至C台虚拟机。
1)遍历peer根据标签信息利用式(3)求出邻接相似矩阵W;
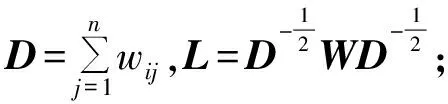
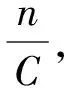
5)Kubernetes调度器执行binding操作,按聚类结果将peer pod调度至不同虚拟机。
2 SC-channel实验
笔者在基于Kubernetes v1.14.2的云平台上用5台虚拟机进行了实验验证,实验配置详情如表2、表3所示,通道创建详情如表4所示。使用Python、Shell混合编写SC-channel算法放于Master监听peer的调度,k-means算法参考sklearn.cluster包改进。在Master机器使用Fabric Nodejs SDK向BaaS发起invoke合约调用,部署Heapster、Influxdb对实验数据进行监视和收集,取平衡因子P为15,为了校验资源调度算法的有效性,采用资源利用率Vi的方差评价资源负载均衡度,即

表2 虚拟机配置详情
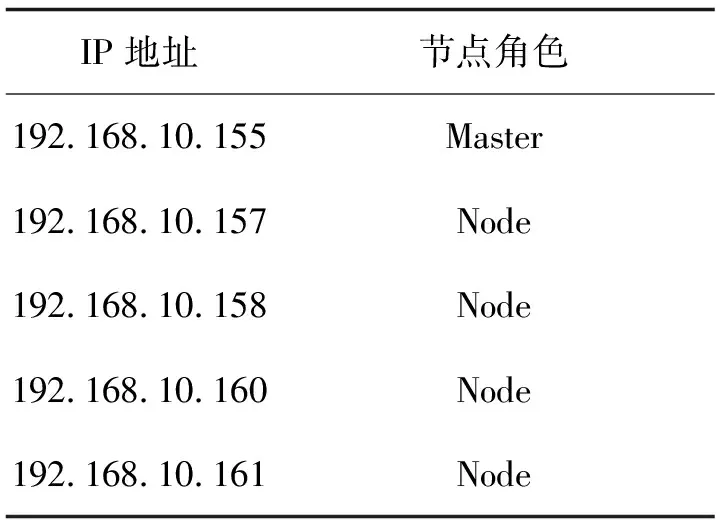
表3 集群网络拓扑

表4 通道的创建
Vi=αVicpu+βViram,
(4)
(5)
由于BaaS上CPU相比于内存变化波动较大,式(4)中取α为0.3,β为0.7。比较了SC-channel与仅仅采用经典的k-means的NJW算法(NJW)、(LRP, Least Requested Priority)、SSP, Selector Spread Priority)对9个peer pod的调度实验。
如图4所示,channel1与channel3始终保持较低吞吐率,channel2在第30 s发起交易,第150 s处结束,逐步增大TPS量,结果显示,负载均衡度随着不断增长的交易量呈现出先下降后上升的态势,当channel2具有小于等于15的吞吐量时,SC-channel与其他3种调度算法下的负载均衡度总体相差不大,随着TPS的不断提高,二者负载均衡度拉开差距。这是由于负荷的提高,平台下的一部分虚拟机已经达到了资源使用上限,而那些计算资源充足的虚拟机因peer未加入始终无法释放潜在的能力。
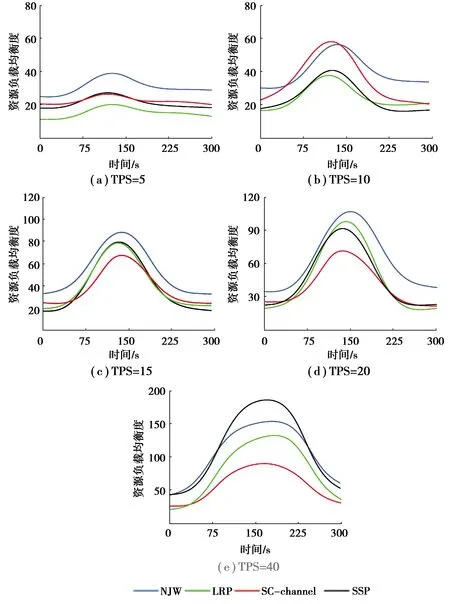
图4 TPS增大时2种算法下的负载均衡度Fig. 4 Load balance degree under two algorithms when TPS increases
统计每组实验的最高S值如表5所示。可以看出,当通道接近空载,默认调度算法LRP、NJW的均衡度更高,且二者相差不大,但随着处理量的增大,均衡度值不断降低,下降极为迅速,将降低用户响应时间,增大单点故障概率,若Pod因资源不足而迁移将产生额外的资源损耗,影响服务质量。随着TPS的提高,使用经典k-means的NJW调度算法与LRP、SSP的均衡度差距不断缩小,甚至在TPS为40时,相比于SSP均衡度更高,由于该算法产生了几个数量极少的簇,导致相应的虚拟机始终处于空载的状态,该算法更适应于庞大交易量的定向通道的业务场景,使那些需要处理繁重业务的少数peer分布在一个虚拟机中。SC-channel在20~40的TPS范围具有较高的均衡度,随着TPS的提高,均衡度表现得比较稳定。根据表5计算4种算法NJW、LRP、SC-channel、SSP下的平均S值分别为88.42、72.78、62.60和83.94,可见SC-channel负载均衡性能较好。
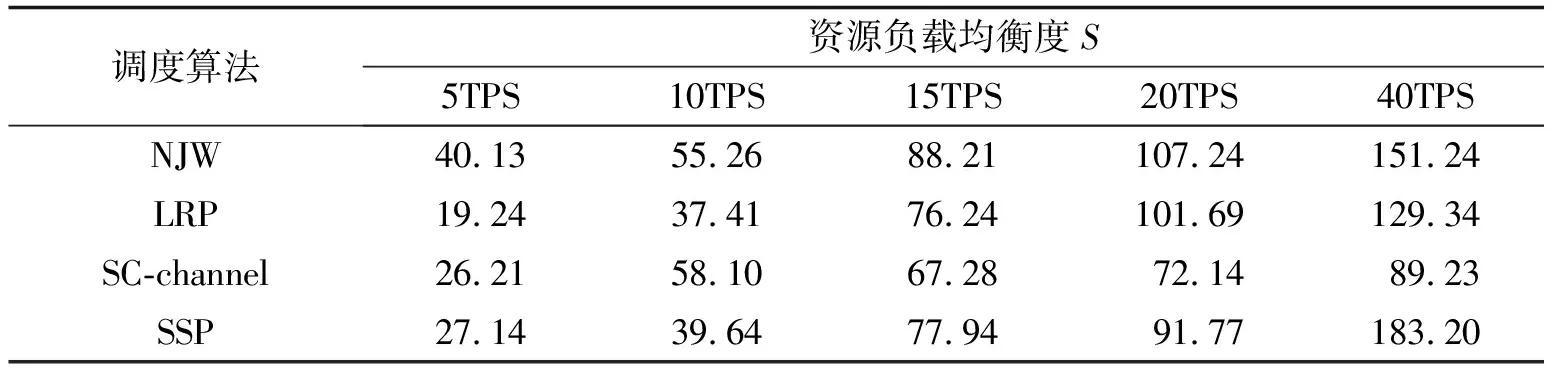
表5 每组实验取最高值S
3 结 论
区块链技术以其去中心、去信任的优点成为当前社会的研究热点,其衍生的比特币、以太坊、超级账本等区块链项目正焕发生机,研究时下热门的BaaS平台,提出了基于NJW谱聚类的资源负载算法,该算法改进默认调度算法的不足,基于peer加入的通道作为调度考量,实验结果表明,利用该算法对peer进行调度使平台面对不同负载压力下的负载均衡度显著提高,增强了平台的可用性与可靠性。
猜你喜欢
快乐语文(2021年34期)2022-01-18 06:04:04
汉字汉语研究(2021年4期)2021-03-09 05:18:52
科学(2020年5期)2020-11-26 08:19:12
科学(2020年6期)2020-02-06 08:59:56
传媒评论(2018年4期)2018-06-27 08:20:12
现代企业文化(2018年13期)2018-06-09 08:22:21
电子测试(2017年15期)2017-12-18 07:19:27
发明与创新(2016年8期)2016-04-20 05:40:04
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
