
大数据时代统计学研究分析
2021-12-20 10:46刘玉鹏对外经济贸易大学
现代经济信息 2021年29期
刘玉鹏 对外经济贸易大学
一、大数据和统计学概念理论
(一)大数据背景下统计学分析
大数据技术缩小了世界范围,促进各领域之前密切关联,改变了人们的生活方式和思维模式,物联网提高了各领域的感知力,在大数据时代,人们衣食住行方式发生了日新月异的改变。随着智能化设备嵌入了传感器,数据的获取、储存、转化提高了效率,改变了人们的工作和生活方式。大数据时代为背景,为了提高存储空间,衍生出了数据存储系统和计算模型,传统结构化数据不能充分解决的数据关系,而引用了非结构化存储系统,不再局限单一的字段格式和数据类型,而采用范式化结构设计,通过增加冗余来促进数据信息的访问效率。大数据背景下的统计学理论,主要是随着大数据技术的不断发展,使机器学习模型不断适应新技术,在语音识别、记忆模型、注意力模型等实现智能处理,除了简单的线性回归模型还有相对复杂的随机森林、梯度提升树等集成模型。这些模型可以从繁杂的数据中筛选重要的信息,提高统计学数据提取效率,大数据技术通过智能检索,关联数据等可以快速锁定目标参数,实现各领域间数据关联。
(二)统计学特征分析和研究意义
在数据预处理过程中,应对数据多个维度进行描述,并采集到适合大数据技术的多维度数据特征,对于数据缺失部分应适当修复和弥补。特征选择上应注意对关联度大的特征重点挑选,而筛选掉冗余特征,以免可以减少模型训练中的存储和计算流程,还能去除干扰来提升模型性能和效果。大数据时代下,同样维度的特征选择和提取应充分结合存储和计算开销。例如,在提取数据的排名特征需要较大排序开销,由于对全局数据进行排序,才能实现平法复杂度O(N2),如果内存不能一次加载,还应采用分布式处理来实现这一特征。因此,大数据时代下,统计学特征分析和处理既需要借助业务经验,还应依托于技巧。
二、特征预处理相关方法研究
(一)特征预处理概述
特征决定了大数据技术的上限,特征预处理在大数据技术中显得尤为重要,从多个维度记录和描述了数据信息,如果数据处理了过程中记录数据存在冗余或者信息量不够,会给后续模型训练增加处理难度,影响模型的有效性。数据采集需要耗费一定的时间和人力成本,增加软硬件的应用,拓宽应用场景。随着硬件成本的下降,数据采集特征将会增加,还应增加合理的数据结构和设计合适的存储模型。直接获取的数据特征无法表达出数据的本质,应变换数据的特征,对聚合之后的数据提取抽象特征,针对异常数据值在处理之前应做特殊处理。针对数据地理、空间等不同特征,不同数据场景反映出的数据类别有所不同。
(二)特征的采集、存储和类型
各领域间的特征采集方式有所区别。电信领域的数据收集可以通过用户的套餐定制、打电话拼读和用户联系人等途径收集;医疗领域的数据收集可以通过电子病历和X光图像等显示的数据;金融领域数据收集可以通过客户的消费、存款、交易额的情况来收集;同时还可以通过硬件的特殊性能来收集用户行为数据,包括GPS模块可以收集用户的精准为主,为了收集运动方向,可以运用陀螺仪的方式来收集等。目前运用最为广泛的是爬虫技术,价格合理,备受学术界关注和使用,是各领域统计数据的重要信息来源。例如,运用爬虫技术对电影和文本的有关评论数据进行细化分类,同时还可以运用分布式爬虫技术对互联网卖家历史价格变化情况进行系统研究。由于爬虫所爬取的互联网数据是公开的,受到国家法律保护,符合网站的Robot协议。个别网站出于商业目的而限制爬虫爬取,而采用分布式多线程爬虫技术访问网站,可以提高数据的抓取效率。特征存储对于少量数据可以运用分隔的csv、tsv存储,而Excel这类文档类文件需要占用较大存储空间,应增加文件存储空间。由于NULL数据使用空格表示,因此,NULL需要用特殊的字符表示,额外增加了数据存储空间。数据库解决了各类数据信息的存储、处理和查询,但结构化数据库对数据类型要求较为严格,导致一些数据信息口径不一很难插入,因此,采用非结构化实现数据之间互融互通,运用schema on read模型设计提高数据存储效率。
(三)特征数据变换
首先,连续特征离散化,为了提高算法的时间与空间效率,应将连续数据变换成离散数据,可以将浮点数变化成大于零和小于零的数据离散操作。大数据时代下,数据离散可以运用监督分类模型,决策树和朴素贝叶斯原理等来生成离散化数据特征标签。无监督可以运用聚类、等宽和等频等方式实现离散化数据特征。其次,离散特征蓝旭华,这类模型不能接受离散值接受,随着离散值的先后顺序变换为连续数据,突出特征排名(Rank)作为连续值,应扩大排序范围。最后,提取聚合特征。由于大数据时代衍生了大量数据,人工读取信息量有限,海量信息应对数据聚合提取出有价值信息实现人工角度可解释性。特征聚合分为横向和纵向两种聚合形式,是对每组数据或者特征的抽象处理。横向聚合操作是存储数据库上的线性时间复杂度。纵向聚合特征表示数据集中或者离散程度,其中集中特种主要有平均值、中位数、众数,而数据离散特征有变异系数、标准差和方差等。
(四)缺失特征值处理
大数据技术处理过程中,缺失特征值是不可避免产生的。例如在问卷调查过程中,如果表格不完整,或者病历在录入过程中也会缺失文焕,因此,在设置某例数据非NULL,数据存储过程中可避免缺失。如果数据具有缺失特征只占总体数据的少部分,可以对这些缺失值进行补充或者直接删除。根据应用场景不同,含有缺失值的补充可以有多种备选方案,可以采用均值填充或者就近填充、回归法填充等。
(五)空间特征处理
空间特征包括地理数据和图像数据等,其中像素点的相邻关系和sift特性可以抽象为一组卷积变换,根据每个位置像素乘上每个位置权重得到卷积变换后结果,实现智能扫描特征,其中sift图像相邻像素类似一致的特征取值但对图像视觉感受不会造成影响。地理数据提取特征包括人口密度、气候环境等,通过经纬度距离可以观测到一个数据点到另一个数据点的关系,通过点、线、多边形的算法,从传统的经纬度坐标转换成为墨卡托平面坐标,进一步计算。
(六)数据不平衡问题
每个数据类别之间存在一定量差,是数据不平衡的体现,例如,统计男女人数,男女生比例严重失衡,导致模型失衡,导致验证集性能变差。大部分机器学习模型很难自动处理,一般可采取欠采样、生成数据、敏感代价函数等角度加以解决数据失衡问题。
三、特征选择前沿方法研究对比
(一)特征选择概述
从特征存储和计算角度来分析特征选择,由于当前大数据技术衍生的数据统计模型只能用于单一领域,应用场景也较为单一,由于这些模型对特定特征高度依赖,表明计算能力相同情况下,选择特征相关度高的做训练模型效果更加,随着数据量的增加,模型迁移到其他领域提高了难度。除了存储和计算资源匮乏外,边缘计算场景对统计数据的采集能力也受限,因此,应减少特征数量,增加模型的计算效率。统计学角度,特征选择是在模型迭代过程中实行数据筛选,其中决策树在生长过程中应根据训练规则选择相应特征,一些分裂没被使用的特征已经被筛选掉。
(二)基于相关度的选择
特征维度与响应变量之间做相关度特征,相关度越大,冗余性特征越小,可以在计算特征维度和变量之间平衡进而筛选特征,例如,在牛奶和苹果对比咖啡相关性中,为了准确评估咖啡销量,应以牛奶销量作参考自变量。每个维度都能计算一个相关度,通过筛选排序,对于大于谋而阈值的相关度作为有效特征,在后续模型迭代和数据代入相应公式中,只需要记录有效特征值即可。首先,模型具有很好的代表性,可以清晰表明贡献特征和冗余特征,其次,减少模型计算开销,避免模型迭代出现冗余特征。最后,简化算法,相关度只通过一轮扫描就可以得出各维度相应变量的相关度。
皮尔逊系数取值为1和-1之间,可以计算数据之间线性和非线性的相关性。假设X,Y两个数据对称系数公式为p(X,Y)=P(Y,X)恒成立。
互信息是非对称的,是一个一个数据分布到另一个数据分布,其中互信息越大表明特征越有用:
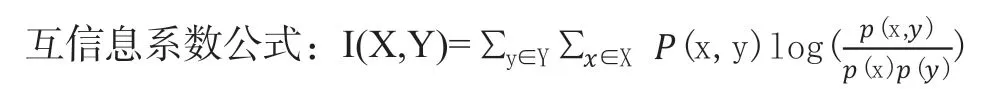
皮尔逊系数、互信息系数等在编程上都可以达到线性计算时间复杂度。
(三)基于Lasso罚项的稀疏选择
Lasso模型带有稀疏选择特性,筛选掉权重为零的特征,保留权重大于零的,属于嵌入式特征选择。Lasso既可以运用线性模型还可以运用多种高级模型,为了提高复杂度控制模型,可以采用XGBoost模型,由于整体目标函数不是凸的,因此,梯度下降法不能用作优化模型。
(四)利用集成方法做选择
根据强大数定理,集成多个简单模型,增加了整体抗数据干扰性能,避免拟合现象,其中集成模型可以特征选择,以随机森林为例,训练过程中,每棵树可以引入特征干扰,通过采样方式得出训练数据,而部分数据没有参与实际训练,但可预测最终效果。采样的树训练好后可以加上随机白噪声特征标签,对预测效果有一定影响,这些冗余特征对模型不构成影响。工程领域采用的统计方法基本以决策树体现。
四、结语
特征预处理和特征选择分别是升维和降维的过程中,大数据为背景,为了抽象特征提取更加有效,应基于应用场景来解决实际问题。统计学中需要预测的领域很多,为了降低误判率,应采用特征做行为预测,通过人为行动产生特征,二者相辅相成又互为因果关系,本文针对大数据时代统计学研究分析做出相应结论,有利于解决大数据时代下机器人学习。
猜你喜欢
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
电子制作(2017年23期)2017-02-02
光学精密工程(2016年6期)2016-11-07
西北工业大学学报(2015年4期)2016-01-19
核科学与工程(2015年4期)2015-09-26
振动工程学报(2014年4期)2014-03-01
