
基于深度迁移的SSDAE滚动轴承故障诊断方法研究
2021-12-15 02:56徐宏飞张卫华宋冬利陈丙炎
噪声与振动控制 2021年6期
徐宏飞,张卫华,宋冬利,陈丙炎
(西南交通大学 牵引动力国家重点实验室,成都 610031)
滚动轴承作为重要的旋转零部件处于复杂的运行环境中,会受到很多动态和静态的冲击作用,一旦轴承失效,将会造成严重的后果。所以对轴承进行故障诊断很有必要。故障诊断方法可以分为模型驱动方法[1-2]和数据驱动方法。模型驱动方法是根据轴承的物理结构建立复杂的物理模型,并依赖很强的专业背景和先验知识来提取故障特征,比较耗时,难以实现。数据驱动方法可以直接从轴承振动信号或者声音信号中识别出故障,数据由传感器采集,对先验知识和专业经验依赖少。
2006年深度学习作为机器学习领域的一个新的分支出现。与传统机器学习的浅层网络相比,深度学习增加了网络的深度,包括增加了非线性神经元的个数和隐含层的数量。因此,深度学习能够自动提取原始数据中的有用特征,在旋转机械故障诊断中有着良好的应用前景。袁文军等[3]针对故障标签较少的问题,提出一种基于深度编码网络的轴承故障新型智能诊断方法。Chen 等[4]采用3 种不同的深层神经网络,包括深层玻耳兹曼机、深层信念网络和堆叠自动编码器来识别滚动轴承的故障。Lu等[5]研究了堆叠去噪自编码器在健康状态识别中的应用。然而,一般的深度学习算法要求训练数据和测试数据必须处于相同的工作状态,即要有相同的分布和特征空间,不能在实际工程中利用各种数据改变工作条件,因此很难推广应用到实际工况。以往的研究大多是通过大量的有标注故障数据对故障诊断模型进行训练和验证。在台架试验中,可以获得大量有标注的故障数据,但在实际运用中,由于轴承长期处于正常的健康状态,缺乏故障数据,导致标记样本不足。综上所述,传统的深度学习方法在故障诊断中的良好性能得益于在不变的工作条件下对大量标记数据的有监督学习。在不断变化的工作条件下,用无标记或者少量标记的数据检测轴承故障仍然是一个挑战。
迁移学习具有从源域学习到有用特征并应用到目标域的能力,为解决上述问题提供了一个很有前途的解决方案。迁移学习作为深度学习的一个重要分支,它把一个成熟领域研究过的知识应用到一个新的领域[6]。目标域中的数据集和源域中的数据集共享相似的知识,但两个数据集的概率分布不同。迁移学习的核心是利用源域中学习到的知识发现不同域之间的相似性,进而提高目标域的分类精度或回归模型的性能[7]。迁移学习的分类方式有两种,一种是按照源领域和目标领域样本是否标注以及任务是否相同,可以把迁移学习划分为归纳迁移学习、直推式迁移学习以及无监督迁移学习等。第二种是采用技术划分,把迁移学习分为基于特征选择的迁移学习算法、基于特征映射的迁移学习算法和基于权重的迁移学习算法。
近年来,迁移学习被逐步应用于旋转机械的故障诊断。Zhang 等[8]提出了一种基于神经网络的迁移学习故障诊断方法。该方法采用神经网络从大量的源域数据中学习特征,并相应地调整网络参数使得网络的结构随着数据分布的变化而改变。Xiao等[9]采用卷积神经网络(CNN)作为基本框架从原始振动信号中提取多层次特征,在训练过程中引入基于最大均值差异(MMD)的正则化项,对CNN 参数施加约束,以减少源域和目标域中的特征之间的分布差异。Sun 等[10]提出了一种基于堆叠自编码器的优化迁移学习算法来解决域自适应问题。Wen等[11]提出了一种新的TL 方法。采用三层稀疏自编码器提取原始数据的特征,并应用MMD 来最小化训练数据和测试数据特征之间的差异惩罚。Wu 等[12]提出了一种自适应的轴承故障诊断深度迁移学习方法,利用LSTM生成辅助数据集,并利用联合分布适配(JDA)减少辅助数据集和目标域数据集之间的概率分布差异。雷亚国等[13]构建了领域共享的深度残差网络提取迁移故障特征,并在残差网络的训练中加入领域适配正则项约束,形成深度迁移诊断模型。
上述方法的模型都需要完全重新训练以适应目标域,且方法中运用自编码网络的模型大多采用三层浅层自编码网络,没有针对网络层数对故障诊断的效果进行分析,在领域自适应方面的算法流程也较复杂。针对滚动轴承故障诊断的问题,提出了一种基于堆叠稀疏去噪自编码器和柔性最大函数的迁移学习模型(SSDAE-softmax),利用KL散度对输入信号进行重建并提取信号的隐含特征,并利用MMD评估以及最小化源问题和目标问题特征之间的分布差异。该方法具有以下优势:
(1)提出的模型具有良好的数据鲁棒性和重建能力,这是由于堆叠稀疏去噪自编码器的引入使模型具有较强的特征表达能力。
(2)提出的方法只需对目标域模型进行少量再训练。使用源域数据对模型进行预训练,然后将预训练模型参数用于目标域的领域自适应的微调过程,降低了算法的复杂度,避免了模型在目标域的重新训练。
(3)提出的方法在领域自适应的过程中源域训练模型和目标域训练模型都采用相同的预训练中隐藏层连接的模型,微调不需要解码过程,降低了领域适配的复杂度,然后进行同步训练更新权值,提高领域适配的效率。
1 稀疏去噪自编码器和迁移学习
1.1 稀疏去噪自编码器
传统的自编码器是直接将原始信号进行压缩特征提取,然后进行解码重构信号。当自编码器可能仅仅简单地拷贝原始输入,或者简单地选取能够稍微改变重构误差却不包含特别有用信息的特征,训练好的模型对数据的重构能力较差。去噪自编码器的核心思想是:一个能够从原始信号中恢复出原始信号的神经网路表达未必是最好的,能够对损坏的原始数据进行编码和解码,然后还能恢复真正的原始数据,这样的特征才是好的,并使学习到的特征更具有鲁棒性[14]。
去噪自编码器的原理如图1所示。首先对输入神经网络的原始数据进行损坏,损坏方式有两种,第一种是在原始信号上叠加噪声,第二种是对原始数据进行随机失活;然后将被破坏的原始数据输入网络进行特征提取,使其进行信号重构,并和原始信号进行比较。
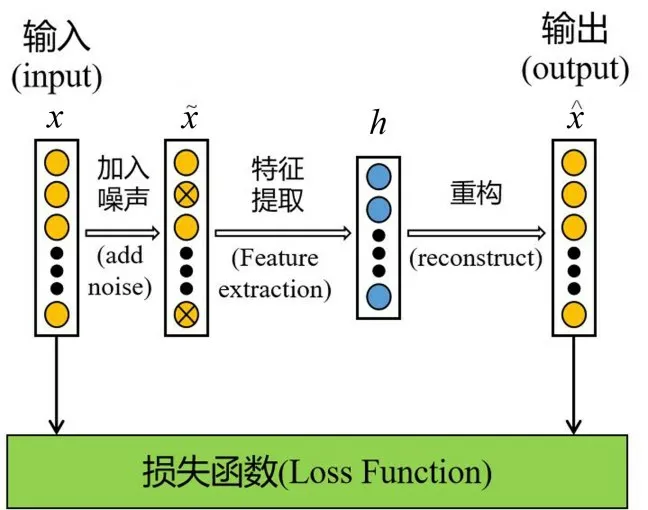
图1 去噪自编码器结构
通常,自编码器隐藏层的神经元数量少于输入层和输出层的神经元数量。由于自编码器最初用于数据的降维,所以当隐藏层的神经元数量多于输入层和输出层的神经元数量时,其自动学习特征的能力就不存在了,从而导致神经网络的鲁棒性较差,为解决这个问题本文在自编码器中引入了稀疏限制,即稀疏自编码器。隐藏层神经元数量可以多于输入的神经元数量,且通过对隐藏层节点进行随机失活,能够提高网络的鲁棒性。
当隐藏层神经元的输出接近于1 的时候,假定这个神经元处于被激活的状态;当输出接近于0 的时候,假定其处于被抑制的状态。对网络施加稀疏性限制使隐藏层的大部分神经元在大部分时间中处于被抑制的状态。
为了实现稀疏性限制,引入KL散度作为优化目标损失函数的额外的惩罚因子:
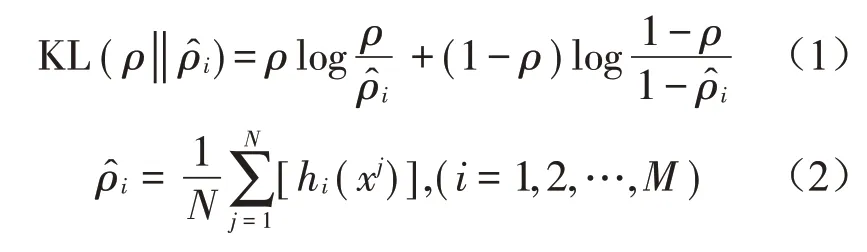
式中:ρ为稀疏性参数,通常是一个接近于0 的较小值。假设ρ=0.1,则代表最终的优化目标是使隐藏神经元的平均活跃度接近于0.1。ρi是第i个隐藏层对所有隐藏层输入的平均激活度。当ρi=ρ时,KL值最小,当ρ和ρi的差值越大,KL值越大。N是隐藏层输入神经元的数量,M是隐藏层神经元数量。
稀疏自编码器的重构目标函数为:
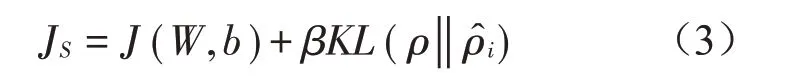
式中:β为稀疏权重系数。
在稀疏自编码器的输入中加入随机噪声或将输入进行随机失活,就得到稀疏去噪自编码器,其结构如图2所示。稀疏去噪自编码器的重构目标函数为:
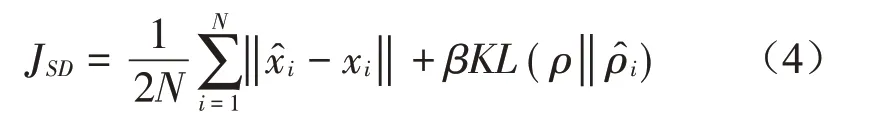
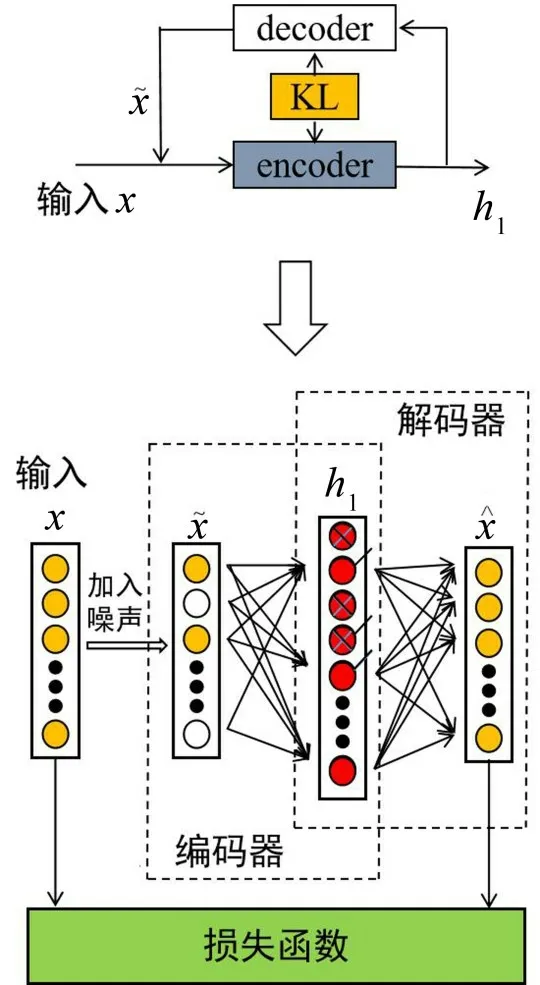
图2 稀疏去噪自编码器结构
1.2 迁移学习算法
迁移学习在近年来受到了广泛的关注和研究,其目标是将已有的源域知识迁移到目标领域,使其在目标领域有较好的应用,其中目标领域中仅有少量甚至没有带标签数据。迁移学习包括两个基本假设:(1)目标域样本和用于训练的源域样本应满足独立同分布的条件;(2)源域必须有足够的样本用于训练以得到一个较好的分类模型。在迁移学习中,目标域和源域共享的因素越多,迁移学习就越容易,否则越困难。因此,在迁移学习时会将源域和目标域映射到一个特征空间进行训练或者判别两领域之间的差异,即领域自适应。领域自适应在共同的特征空间中为两个领域寻找到一个度量准则,使得源域和目标域的特征分布尽量接近。
MMD可以用来度量源域和目标域之间的距离,直观判断两个数据的分布。假设源域数据集Xs=[xs1,xs2,…,xsn]和目标域数据集Xt=[xt1,xt2,…,xtm]满足不同的分布,存在一个再生希尔伯特空间和一个映射函数φ(⋅),可以将数据集从原始空间映射到希尔伯特空间。MMD可以由式(5)定义:
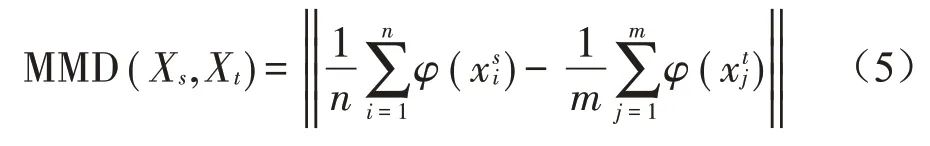
式中:n和m分别为源域和目标域的样本数量。高斯核函数具有可以映射无穷维空间的优势,所以本文采用高斯核函数作为映射函数φ(⋅)。
本文在模型的微调过程中将目标域数据和源域数据共同输入到去掉解码器的神经网络模型中,将各层的输出提出进行MMD 领域分布差异计算,并将MMD加入到微调模型的用于分类的目标损失函数中,在领域自适应过程中进行同步训练更新权值,提高了领域适配的效率。过程如图3所示。
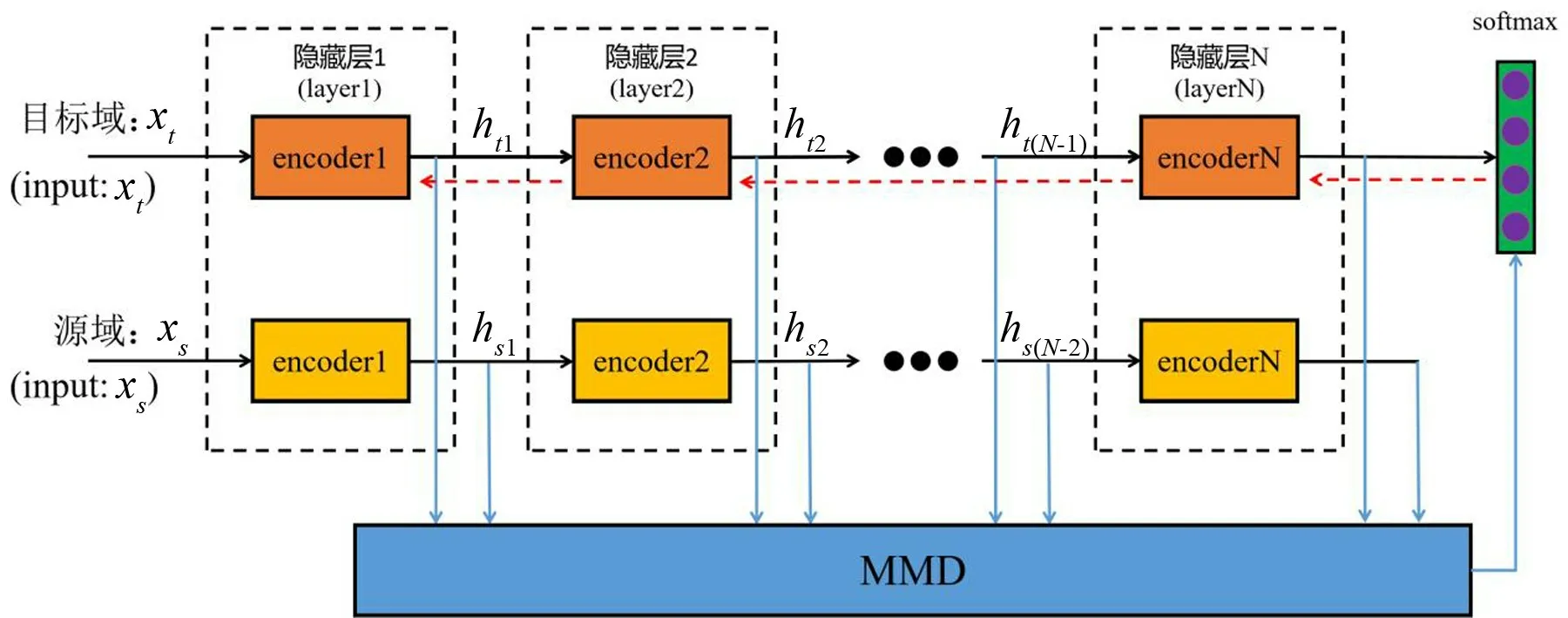
图3 微调过程图
2 基于SSDAE的迁移学习方法
本文提出一种基于堆叠稀疏去噪自编码器(SSDAE)的迁移学习方法把从源域学习到的知识应用到目标域。算法的流程图如图4所示。算法的详细步骤如下。
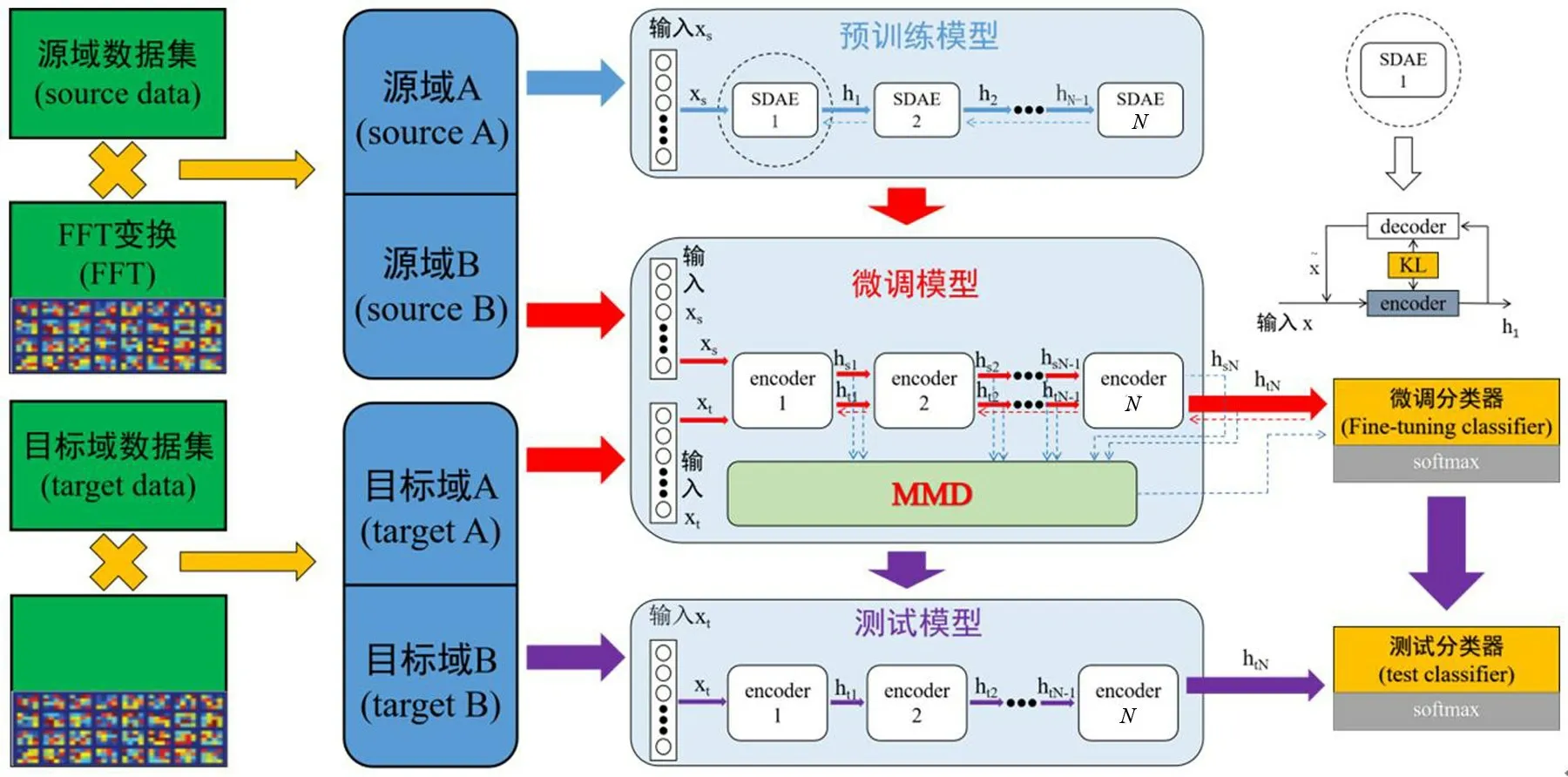
图4 迁移学习的结构图
(1)步骤1:对原始数据进行预处理
将数据通过快速傅里叶变换进行预处理,并划分数据集,将源域数据集划分为A、B 两个数据集,同理处理目标域数据集。其中,目标域数据集B 用于对方法进行验证。
(2)步骤2:预训练SSDAE模型
将源域数据输入到第一个SDAE(Sparse denoising autoencoder)模型当中。通过加入随机噪声对源域数据xs进行破坏得到x͂s,x͂s经过编码器和解码器得到恢复数据xs,通过式(13)的目标损失函数对SAE 模型的参数进行更新,最后得到隐藏层的输出h1。
对于第i层SDAE,由上一层的输出hi-1作为输入,经过训练得到hi。运用逐层贪婪训练法进行逐层无监督训练,直至SSDAE中的所有子模块全部被训练完毕。
(3)步骤3:微调预训练SSDAE模型
逐层预训练完成后,将每一层SDAE 的隐藏层提取出来并连接到一起,隐藏层参数采用预训练好的模型参数,并在顶部加入分类器,分类器采用Softmax函数,对分类层的参数进行随机初始化。采用少量有标签的源域数据对模型进行微调,更新各层参数。
(4)步骤4:在目标域微调模型
引入微调后的模型,将源域数据和目标域数据同时输入模型,并得到每一层的输入hsi和hti,引入MMD加入到目标优化函数当中,通过优化更新参数实现源域知识向目标域的迁移,实现目标域分类器的实现。
(5)步骤5:模型测试
利用目标域数据对微调好的模型进行测试,得到分类精度。
3 实验数据和分析结果
3.1 数据描述
为了验证本文所提出的故障诊断方法的可行性和有效性,采用轴承试验台的滚动轴承振动数据对诊断方法进行验证。滚动轴承振动数据来自美国凯斯西储大学的轴承试验台[15],轴承试验台如图5 所示。试验台主要包括左侧的电机、中间的扭矩传感器、测功器和控制电子设备等。在测试轴承上设置单点故障,数据包含正常情况和3种故障类型,分别为外圈故障、内圈故障和滚子故障。

图5 美国凯斯西储大学的轴承试验台
将实验数据分为源域数据和目标域数据,采用驱动端轴承故障数据作为源域数据,电机负载为2 HP 和3 HP,轴承故障尺寸为0.36 mm 和0.53 mm。采用风扇端轴承故障数据作为目标域数据,电机负载为0,轴承故障尺寸为0.18 mm。将各种电机负载和轴承故障尺寸的数据进行混合并分为4 种类型:正常轴承、外圈故障轴承、内圈故障轴承和滚动体故障轴承。每种故障类型的数据量见表1。
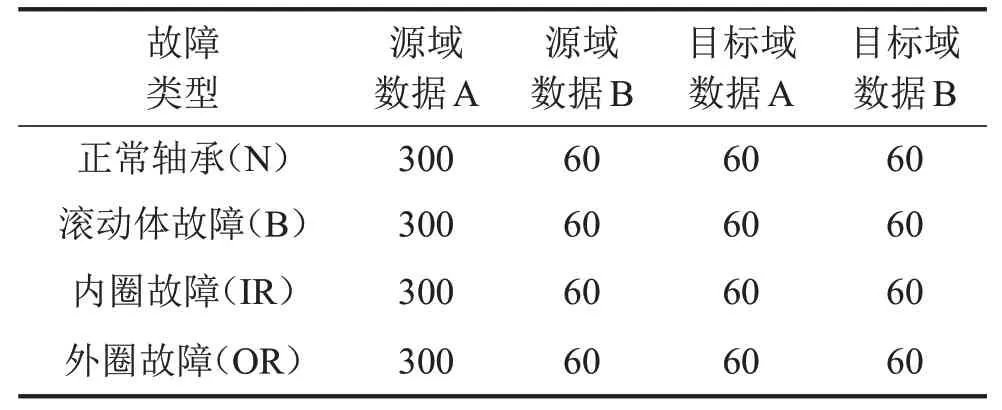
表1 不同故障类型数据集划分
每条轴承样本数据的采样频率为12 000 Hz,采样点数取1 024 个,并对时域数据进行预处理,应用快速傅里叶变换将时域信号变换到频域。由于傅里叶频谱的对称性,所以只采用一半的频域数据,因此每条轴承样本数据包含512个样本数据点。
3.2 实验结果
考虑到网络层数对诊断结果的影响,本文设置了不同的网络层数分别对4类状态轴承进行故障诊断,根据自编码器的特征提取原理,网络层数采用递减式的隐藏层的节点数组合,并以倍数递减的方式进行设置。由于网络层数以成倍数的方式递减时效果最好,结合输入数据长度,最大网络层数可以设置为8 层,所以网络层数分别设置为3、4、5、6、7、8 层,对每一种网络层数随机进行20次实验,取平均故障诊断率,结果如图6所示。
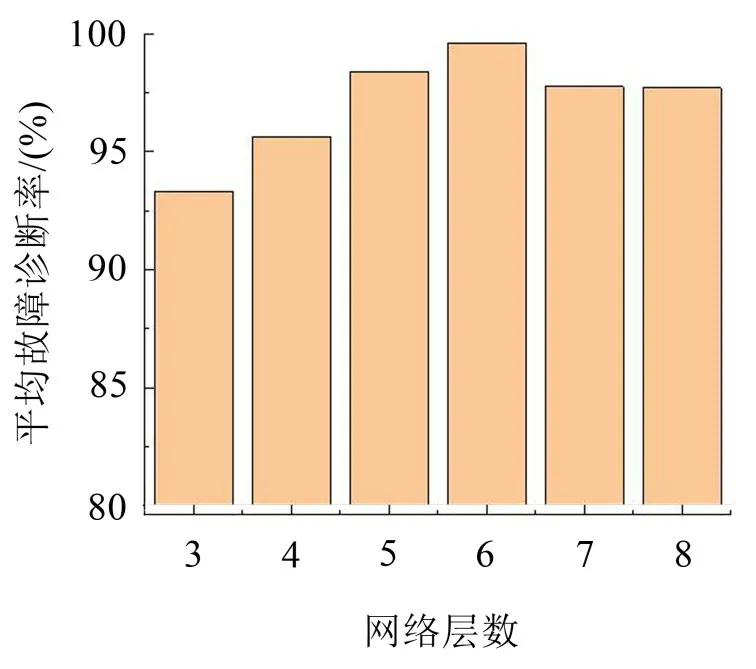
图6 不同网络层数诊断结果
从图6 可以看出,基于不同网络层数的SSDAE深度自编码网络的诊断结果有较大的差异,随着网络层数的增加,诊断准确率不断提高。当网络层数为6层时,诊断准确率达到最大值,当网络层数继续增加时,诊断准确率开始下降,由于隐藏层层数以递减式增加,网络层数7和8之间的神经元数量差别不大,所以诊断准确率趋于稳定。网络层数越多并不意味着诊断效果越好。当网络层数过多时,发生了一定的过拟合,导致网络在测试集上的诊断准确率有一定的下降。由此可得结论,并不是网络越深诊断效果越好,随着网络的进一步增加,网络的规模也会变大,要学习的参数也变得更多,这也和数据集的大小有关,在本实验划分的数据集中,综合考虑平均诊断准确率和诊断波动性,网络层数为6 层时诊断效果最好。
模型结构采用6 层结构,各层的节点数为521-256-128-64-32-4。KL 散度的稀疏性参数设置为0.1。为了验证迁移方法的有效性,将在同等结构的SSDAE模型中去掉MMD领域适配方法后的模型用于故障诊断。同时,为了验证SSDAE模型中稀疏和去噪两种方法对故障诊断的有效性,将同等结构的SAE(堆叠自编码器)模型用于验证分析。
首先验证SSDAE 模型中稀疏和去噪两种方法对故障诊断的有效性,随机进行一次实验,实验结果如图7所示。图7为两种模型诊断结果的混淆矩阵。由图7(a)可知,SSDAE 模型对4 种轴承故障类型的诊断率都很高,对于正常轴承的诊断率达到100%,诊断率最低的为外圈故障,诊断准确率为96%,相差较小。由图7(b)所示SAE模型的结果可知,该模型对不同故障类型的诊断准确率相差很大,其中对于滚动体和内圈的故障诊断率较高,诊断精度可达98%以上,但对于外圈和正常轴承的诊断精度较低,分别为82%和75%,说明SAE 较SSDAE 缺少了稀疏和去噪两个方法后的诊断针对性差了很多,这些结果验证了在基于自编码器的故障诊断方法中加入稀疏和去噪方法对于提高模型的鲁棒性的优势。
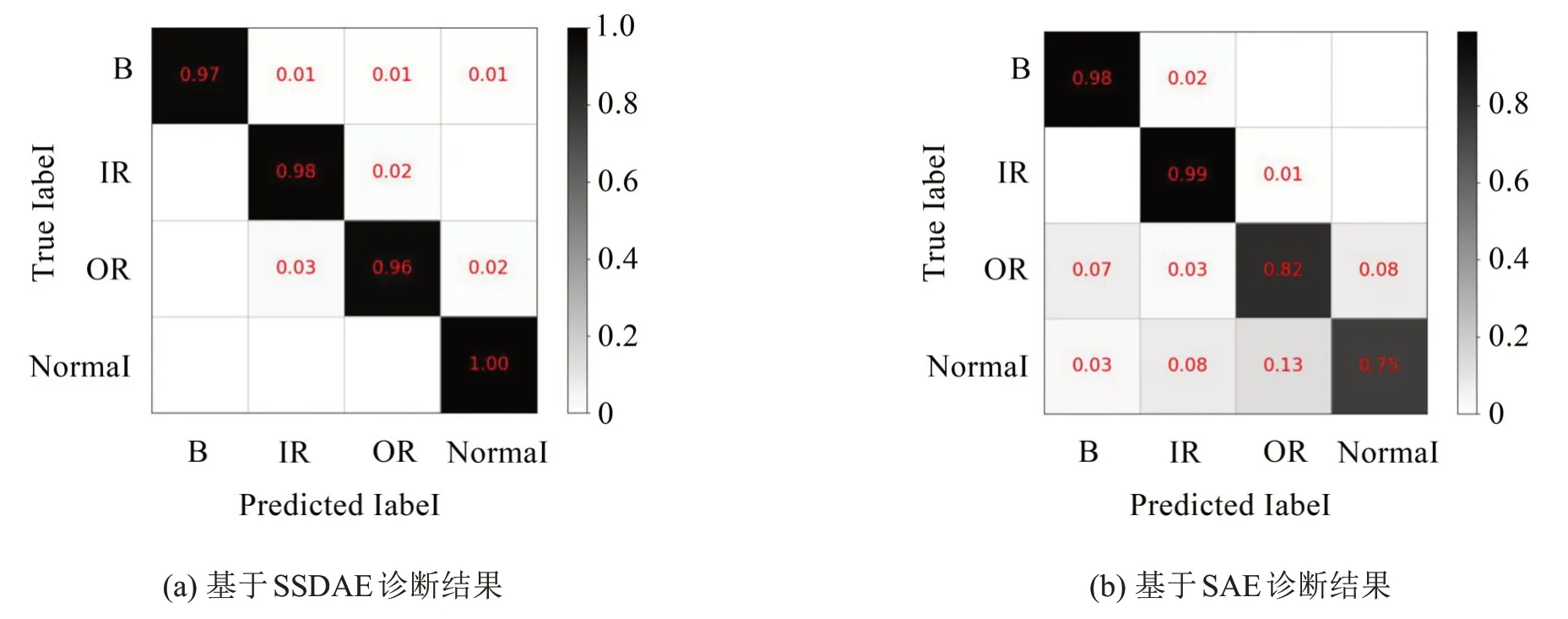
图7 基于SSDAE和SAE诊断结果对比
在迁移方法的验证方面,本文提出方法的诊断结果如图8 所示。在加上迁移功能后,模型的诊断精度进一步提高,其中对于正常轴承和外圈故障的诊断精度可以达到100%,滚动体故障和内圈故障的诊断精度也达到了99%以上。相较于SSDAE 方法对于滚动体故障的诊断精度提高了2%,内圈故障的诊断精度提高了1%,外圈故障的诊断精度提高了4%。这说明了加入迁移算法对诊断精度提高的有效性。
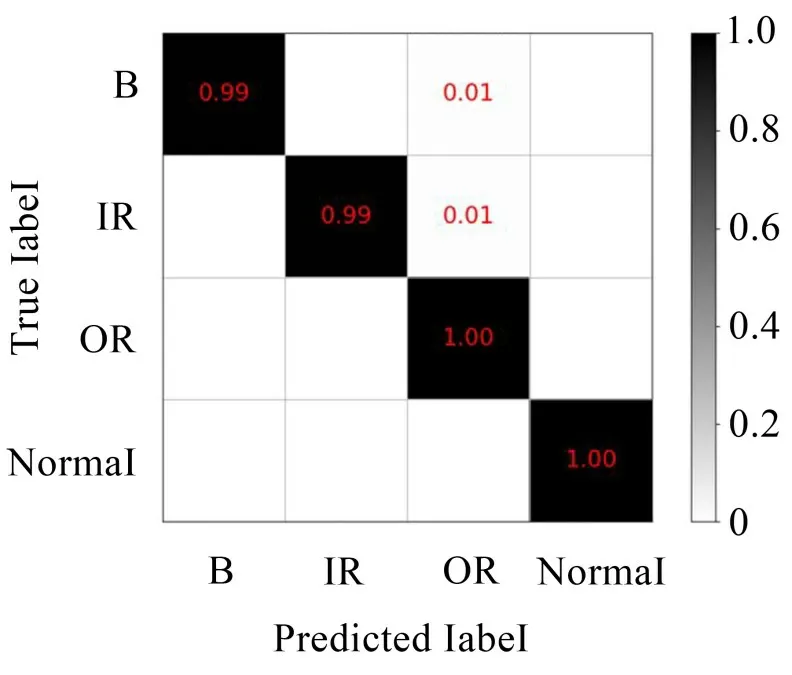
图8 基于SSDAE-TL诊断结果
为了对比所提方法的稳定性和诊断的准确性,将以上样本输入到传统的BP神经网络中,对每一个分类器都进行20次的随机实验,其中每次实验的诊断精度如图9 所示。由图9 可以看出,在20 次随机实验中,传统的BP神经网络分类模型的诊断精度明显要低于自编码器的诊断精度,表明自编码器在迁移故障诊断领域优于传统的BP 神经网络。对比3种自编码器模型,SSDAE方法的诊断精度优于SAE网络模型,诊断精度平均提高了7%。对于所提出的迁移学习方法,其诊断精度和稳定性都明显优于SSDAE 和SAE 网络模型。所提出模型和其他3 个神经网络模型的平均准确率如表2。
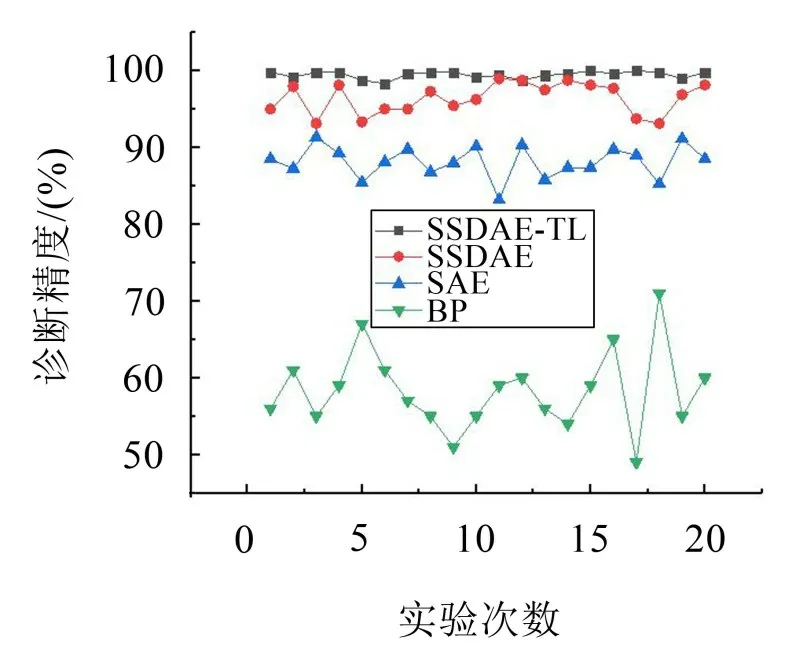
图9 诊断准确度对比

表2 诊断模型诊断精度比较
本文所提出的方法平均诊断精度达到99.46%,SSDAE 和SAE 的平均诊断精度分别为96.41 %和88.11%,均低于所提出的方法。传统的BP 神经网络在迁移故障诊断中的平均故障诊断率仅为58.25%,远低于所提出的方法。这些结果表明所提出的方法能够有效地用于滚动轴承的迁移故障诊断中。
4 结语
本文提出了一种基于深度迁移的堆叠稀疏去噪自编码器的滚动轴承故障诊断方法。该方法首先以无监督的学习方式,逐层贪婪训练输入数据的主要特征,消除输入数据特征之间的冗余。然后对模型进行微调,通过最大均值差异对源域和目标域数据进行领域适配,以将模型更好用于目标域的故障诊断。与现有利用MMD 进行领域适配的方法相比,该模型领域适配过程不需要解码过程,降低了算法的复杂度。采用美国凯斯西储大学的轴承试验台的振动数据对模型进行训练和测试。实验结果表明,该模型利用少量的目标域数据就能有效提高故障诊断的准确性。与传统的SSDAE 算法以及SAE 算法相比,提出的模型有着更高的诊断精度和更好的稳定性。实验和对比结果证实了SSDAE-TL模型在小样本故障数据条件下诊断的有效性和优越性。
猜你喜欢
计算机技术与发展(2020年11期)2020-12-04
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
现代商贸工业(2017年23期)2017-09-13
电子器件(2015年5期)2015-12-29
物联网技术(2015年8期)2015-09-14
电子与信息学报(2015年12期)2015-08-17
电测与仪表(2014年13期)2014-04-04
中国神经再生研究(英文版)(2014年11期)2014-01-22
