
基于N3D_DIOU 的图像与点云融合目标检测算法
2021-12-14 02:07:10郭保青谢光非
光学精密工程 2021年11期
郭保青 ,谢光非
(1. 北京交通大学机械与电子控制工程学院,北京100044;2. 北京交通大学智慧高铁系统前沿科学中心,北京100044)
1 引 言
基于目标检测的环境感知是自动驾驶和机器人导航[1-2]的基础,常见的目标检测方法包括二维图像目标识别和三维点云目标精确定位。基于 二 维 图 像 的 SPPnet[3],R-CNN[4],Fast RCNN[5],Faster R-CNN[6]和 YOLO[7]系列算法被广泛应用于目标识别,这类算法效率较高,但对目标大小及位置的估计不够准确。
与二维目标检测[8-9]相比,基于三维点云的目标识别与定位[10]可以精准估计目标的三维尺寸及位置,对车辆自主驾驶和机器人导航具有更重要的意义。然而,三维目标检测面临着数据量大、点云分布不均匀和处理复杂等诸多挑战,许多相关研究致力于提高三维点云检测的时效性和准确性。Complex-YOLO[11]和 YOLO3D[12]算法对YOLO 的检测框架进行了三维扩展,PIX⁃OR[13]将三维点云投影到BEV 视图中进行二维检测,SqueezeSeg 算法[14]则将三维点云投影到了球形网格。上述这类算法均是利用成熟的二维探测框架将点云投影到平面上,然而投影过程中的空间信息丢失会导致空间遮挡和精度下降的问题。第二类算法通过对点云体素化进行三维卷积操作提取点云特征并生成检测框。ZHOU等人提出的VoxelNet[15]首先将点云划分为体素,然后使用RPN 网络进行对象检测;Second 网络[16]同样对点云进行体素划分,使用 Pointnet 对非空体素进行特征提取。由于点云的稀疏性,这类算法进行点云体素化大大增加了数据量,大量的空白体素会导致计算的浪费。
激光点云与图像融合算法也可以分为两类。Liang 等人[17]提出了多任务多传感器检测模型分别对激光点云和图像进行特征提取,然后输入到同一神经网络进行目标分类和预测,属于前融合方案。现有大部分前融合方案网络本身较为复杂,难以实现实时性。Wu 等人[18]分别利用点云和图像进行行人检测,再对检测结果进行匹配后输出最终融合的结果,属于后融合方案。但目前后融合方法应用较为局限,极少能够用于交通环境目标检测。
特征提取是目标检测的重要环节,卷积作为一种特征提取方法已经广泛应用于二维图像目标识别,但由于点云的无序性,卷积无法直接应用于点云特征提取。Pointnet[19]首次提出了一种针对三维点云直接提取特征的网络结构,但采用最大池化解决点云无序性问题,由于本地连接被忽略,仅能提取全局特征。为了解决这一问题,通常采用最远点采样方法生成种子点对原始点云进行分组,但这种方法只能保证覆盖面广,不能代表最优选择。为了优化点云分组策略,本文提出了一种改进的投票模型网络,利用神经网络优化种子点的选择并用于后续多尺度局部特征提取。
目标检测精度通常采用检测框与实际目标框的交并比(IOU)作为评价指标。目标检测中一般使用L1 或L2 损失函数进行检测框的优化,但是不同的L1 和L2 损失值可能具有相同的IOU 值,此时利用IOU 作为二维检测损失函数会存在很大的不收敛风险[20-21]。为了提升收敛性,文献[22-23]通过 IOU 进行优化提出了 GIOU 和 DI⁃OU 损失函数,但只适用于二维情况。为了解决三维目标检测问题,本文提出了一种适用于三维点云检测的N3D_DIOU_loss 损失函数来统一损失函数和评估准则,达到了较好的检测效果。
本文充分利用经过事先联合标定的二维图像及三维点云信息,提出了融合二维图像与三维点云的目标检测框架,利用二维图像中检测到的目标提取三维点云中的截头体来滤除多余的背景点,降低了三维计算成本;提出基于广义霍夫变换的改进投票模型用于多尺度特征提取,同时提出N3D_DIOU_loss 将DIOU 损失函数从二维拓展到三维,代替传统的L1 损失函数优化回归目标框,使得目标框的生成更精确。KITTI 数据集的消融实验表明:与经典方法相比,本文算法在三维目标检测精度和俯瞰图检测精度上均有较大提升,达到了较好的检测效果。
2 基于投票模型的目标检测网络
本节主要介绍融合二维图像及三维点云的目标检测网络整体结构。如图1 所示,目标检测网络分为三个主要部分:(1)数据预处理;(2)投票模型网络;(3)RPN 网络。目标检测网络以三维原始点云和二维图像作为输入,用二维图像检测框对应的平截头体进行点云过滤;过滤后的点云被初步聚类,并由改进的投票模型网络层进行特征提取,然后使用FCN 网络进行多尺度特征融合,融合后的特征被输入到检测头,包括分类头(CLS)和回归头(REG),以预测检测结果。

图1 检测网络框架Fig.1 Detection network framework
2.1 三维点云预过滤处理
为了综合利用二维图像及三维点云提供的特征信息提升点云处理效率,假设激光雷达和摄像机已经联合校准,可以执行坐标转换。由于二维图像目标检测算法相对成熟且高效,本文首先使用二维检测器在图像中提取目标框,然后用二维框所对应的平截头体过滤三维目标点云,过滤后的点云围绕二维图像中对应目标中心点的空间点进行旋转直到中心线与坐标轴Y对齐,以便于后续的点云聚合。其中,中心线是由二维被测物体中心反投影到三维空间生成的。
2.2 投票模型网络
学习点云的语义特征,首先需要提取相邻点的低层几何特征。
过滤后的点云仍具有离散性和无序性的特点。为了对点云进行分类和分割,一些算法使用最近邻采样来聚集点云,使用最远点采样(FPS)生成原始种子点,FPS 虽然覆盖的点云范围很广,但无法确定目标的具体位置。另一类算法采用体素分割用于在同一体素内聚集点云,然而这种体素分割方法无法获得边界的位置。
为了解决这些问题,我们提出了一个如图2所示的改进的投票模型网络来生成原始种子点,该网络主要由投票模块、分组模块和Pointnet 模块组成。其中采用结合基于广义霍夫变换的vote 投票模块与基于最远点采样的分组模块进行点云的聚类,采用Pointnet 进行多尺度特征提取。

图2 投票模型网络Fig.2 Vote model network
首先将包含点云位置和激光反射强度特征的过滤点云输入到由conv 层、BN 层和relu 层组成的投票模块中,这些模块共享权重模拟了广义霍夫变换对中心点的投票过程寻找点云的聚类中心生成目标中心。在此基础上,本文进一步基于目标中心的深度和角度生成采样中心以此改进了投票模型,使得网络可以获得更精细的局部特征。目标中心的位移偏移Δxi和特征偏移Δfi由投票模块生成,并由L1 损失函数监督。投票模块生成目标中心yi,再由分组模块基于最远点采样原理对过滤后的点云进行聚合得到分组点。由于目标的大小和点云的密度未知,所以使用四组不同的欧式距离划定球形区域进行粗略聚类,在球形区域中使用最远点采样法对点云进行降采样获得四组不同尺度的降采样点云,最后将不同尺度的降采样点云分别输入到四个Pointnet 模块就可以获得四组不同尺度的点云特征图。
2.3 基于 FCN 的 RPN 网络
利用上述投票模型网络完成了点云聚类和不同尺度的特征提取,四种特征的尺度大小分别为f1=L·d/4,f2=L·d/4,f3=L·d/2,f4=L·d,其中,L是采样点数,d是特征大小。为了进一步对不同尺寸物体进行目标框预测,本文设计了如图3 所示的对四种不同尺度特征进行融合的FCN网 络 结 构 。 FCN 网 络 由 conv 层 、deconv 层 和merge 层组成;merge 层也是 conv 层,用于特征图融合;deconv 层用于调整特征图大小,以保证需要融合的各特征图具有相同的尺寸。

图3 FCN 网络结构Fig.3 Structure of FCN network
经过FCN 融合后的特征图输入分类头和回归头,分类头用于识别目标的类别,采用softmax结构输出感兴趣目标的分类概率;回归头用于目标的定位,输出包含实例的最小包围立方体参数(包围框中心、长、宽和高)。回归框与分类概率也一一进行对应,因此可以用一个统一的多任务损失函数对分类与回归进行统一的优化训练。
2.4 参数微调
为降低二维检测精度对算法的影响,本文提出的方法参考 F-Convnet[24]进行参数微调,过程如下:
(1)根据坐标对检测出的三维框进行归一化,每个检测框的中心作为它们各自坐标系的原点,坐标轴的方向统一到第一检测框;
(2)在预处理过程中,将点云的过滤范围扩大并乘一个膨胀系数,在本文中,这个膨胀系数被设为1.5;过滤范围扩大有助于降低检测框定位不够精确造成的点云过多的过滤,从而提高算法稳定性;
(3)将(2)中过滤后的点云再次送入后续网络重新训练,调整网络参数。消融实验表明,参数微调过程对提高探测精度具有显著作用。
3 3D_DIOU 多任务损失函数
深度神经网络的训练实际上是基于梯度下降的一种优化过程,设计合理的损失函数可以加快训练过程并获得最优解。为了完成多任务分类,本文设计了一种基于三维DIOU 的多任务损失函数,包含分类损失函数Lcls与三维扩展的DI⁃OU 损失函数N3D_DIOU_loss 两部分。为了在训练期间将每个部分的损失函数保持在相似的范围内,两个部分分别乘以权重ω1和ω2,如公式(1)所示。
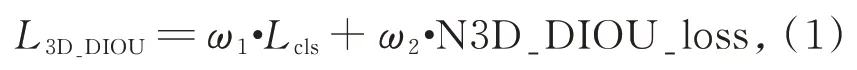
其中,权重ω1和ω2要保证训练过程中两部分损失下降的速度相当,根据经验并基于上述原则优化后的权重值为ω1=1 和ω2=8。
3.1 分类损失函数
由于RPN 预测的大多数检测框都是负样本,因此正样本和负样本之间存在很大的不平衡。这种不平衡使得训练过程中的负损失远大于正损失,这对网络训练是有害的。为了解决这个问题,Lin[25]提出了焦点损失函数(FL),并表示为公式(2):

本文对于类别的预测即使用焦点损失函数,其中:pt表示对应边框模型的评估概率值,参数αt=0.25,γ=2。
3.2 N3D_DIOU_loss
在二维图像中,经常使用L1 损失来优化IOU 精度,但它不能完全代表网络训练时IOU 的精度。对于具有不同IOU 精度的检测框,可能有相同的L1 损失值。为了解决这个问题,F-Con⁃vnet 使用corner_loss 正则化三维框回归。而更直观的方法则是用IOU 作为损失函数[26],但如图4(a)所示当目标框和检测框之间没有交集时,IOU 损失函数无法进行训练。为解决这一问题,文献[22]提出了 GIOU 损失函数,但如图 4(b)和(c)所示时,GIOU 损失函数在水平或垂直情况下退化为IOU 损失函数,也存在无法较好收敛的风险。因此,文献[23]提出DIOU 损失函数进一步提高训练过程的稳定性和优化性能,二维图像中DIOU 损失函数的原始公式如公式(3)所示。
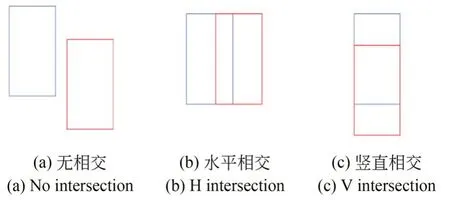
图4 三个检测框和目标框之间的位置关系Fig.4 Relationship between three detection boxes and target boxes
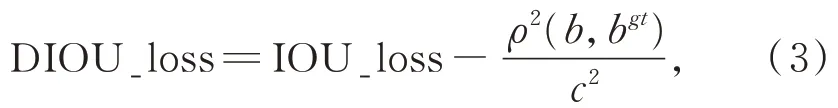
其中:ρ是检测框中心点b与目标框中心点bgt之间的距离,c是最小边界框的对角线距离。
三维框和二维框的IOU 计算并不完全相同,由于三维框存在角度朝向问题,使得三维IOU 的计算更加困难。如图5 所示,在计算三维目标框和检测框的IOU 时,重叠区域的计算更加复杂[27]。 为 此 ,本 文 提 出 了 下 面 的 N3D_DI⁃OU_loss 损失函数:
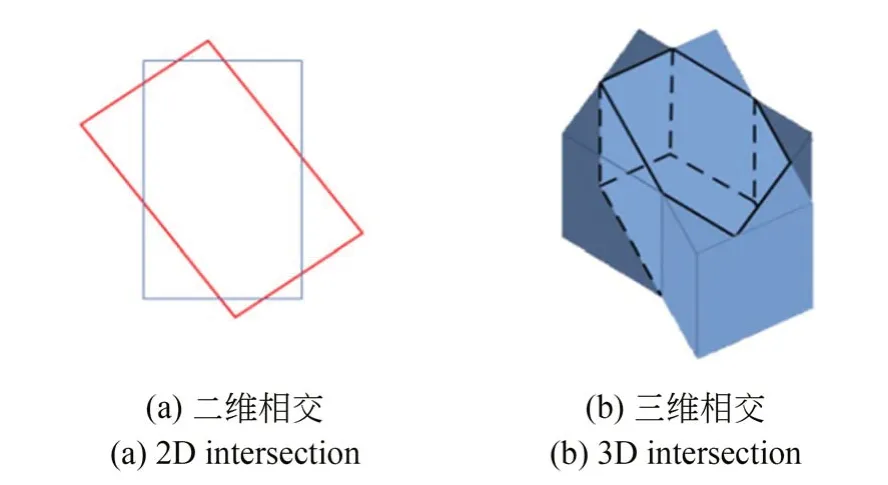
图5 存在角度偏差的目标框与检测框Fig.5 Target box and detection box with angle deviation
(1)将检测框和目标框旋转并与坐标轴对齐,利用max 和min 函数计算两框的所有交点,并将这个过程定义为检测框的正则化;
(2)三维DIOU 的计算退化为二维难度;
(3)对于角度,首先将其离散化,然后用L1损失函数监督角度偏差,最后与正则化的三维DIOU 组合成多任务损失函数。由此简化了三维DIOU 的计算,N3D_DIOU_loss 的伪代码如算法1 所示。
算法1 N3D_DIOU_loss 伪代码

4 实验与分析
为了验证算法的有效性,在公开的KITTI 数据集上进行了实验验证,该数据集包括7 481 帧的训练集和7 518 帧的测试集。由于测试集的标签没有公开,我们将训练集分为3 712 帧的训练集和3 769 帧的验证集进行网络训练和验证。主要检测目标分为三类,包括车辆,行人和骑自行车的人,数据分为简单、中等和困难难度级别。根据官方标准,当IOU 值达到0.7 时,汽车被认为分类正确。对于行人和骑自行车者,由于目标较小,IOU 阈值降低为0.5。
4.1 投票模型网络参数设置
投票模型生成的特征图大小为f1=L·d/4,f2=L·d/4,f3=L·d/2,f4=L·d,其中L表示采样点数,d表示特征大小。为便于特征图融合,对于汽车,L设置为 280,d设置为 512;对于行人和骑自行车的人,L设为 700,d仍是 512。投票模型网络生成的中心点数量设置为[32,64,64,128],汽车的聚类距离设置为[0.25,0.5,1.0,2.0],行人和骑车人的聚类距离设置为[0.1,0.2,0.4,0.8]。
4.2 网络训练参数设置
对于检测网络的训练,初始学习率设定为0.000 1,随着训练epoch 的增加逐渐衰减到0.000 001,总 epoch 设置为 80。另外,使用 Adam优化器进行训练,优化器的系数为0.000 1。整个训练过程是在两个NVIDIA TITAN X GPU上进行的多GPU 训练,批量batch 为32。整个训练过程大约需要6 个小时。
4.3 基于KITTI 数据集的实验对比
为了验证本文算法的有效性,表1 给出了KITTI 数 据 集 上 本 文 算 法 与 经 典 的 MV3D[1],ContFusion[28],VoxelNet[16],F-Convnet[24],IP⁃OD[29]和 point columns[30],F-PointNet[31]先进算法在三维检测精度上的比较。其中,对于汽车的检测,本文算法在各个难度上都优于上述各算法,在典型的简单难度下,本文算法较上述算法中表现最好的提升0.71%。对于行人的检测,检测效果随着难度的增加而下降,在简单难度下较上述算法中表现最好的提升了0.37%。
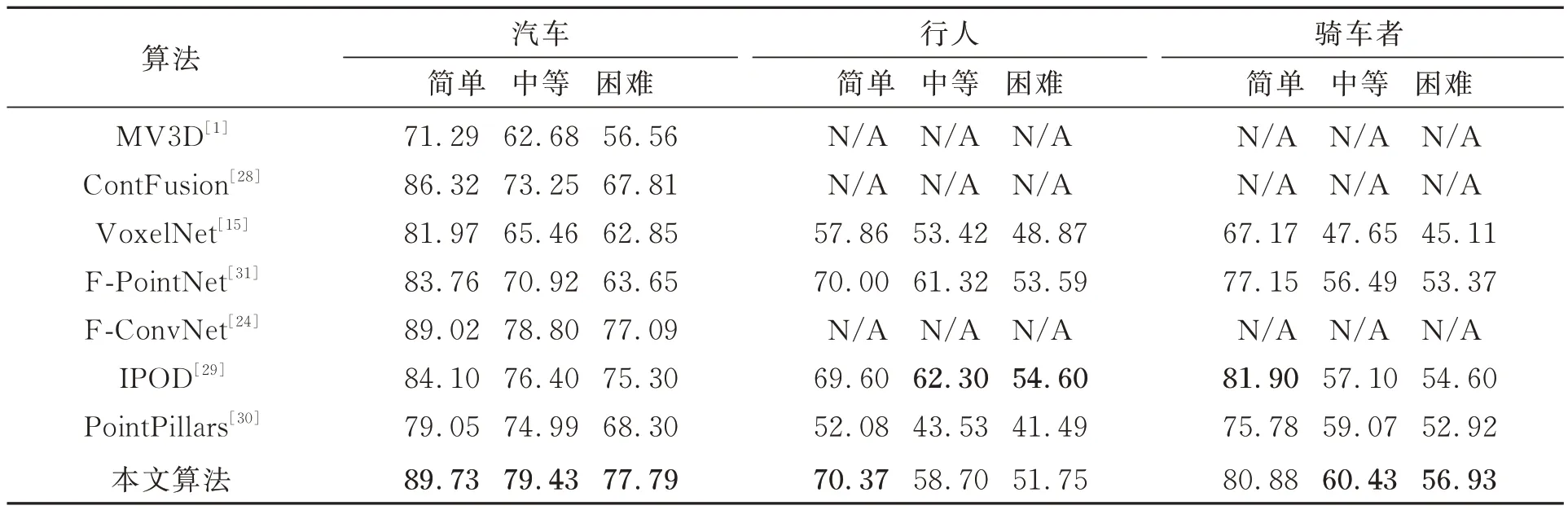
表1 KITTI 验证集汽车、行人与骑车者三维检测结果Tab.1 3D detection AP(%)of cars,pedestrians and cyclists on KITTI val set
除了三维检测精度之外,表2 列出了本文算法与各个算法在俯视图(BEV)检测中的比较。应用N3D_DIOU_loss 损失函数,检测框和目标框之间的重合度相对较高,因此BEV 检测精度提升较大。其中,汽车在典型的简单难度下较上述算法中表现最好的提升了2.07%,而行人在简单难度下提升了0.19%;对于骑车者,本文算法均达到了最好效果,在简单、中等与困难难度下分别提升了1.91%,3.41% 与2.88%。由于行人与骑车者体积小更难于识别,所有算法在检测精度上均低于汽车,但本文算法性能仍与表中最优算法相近并在大部分情况下有所提升。
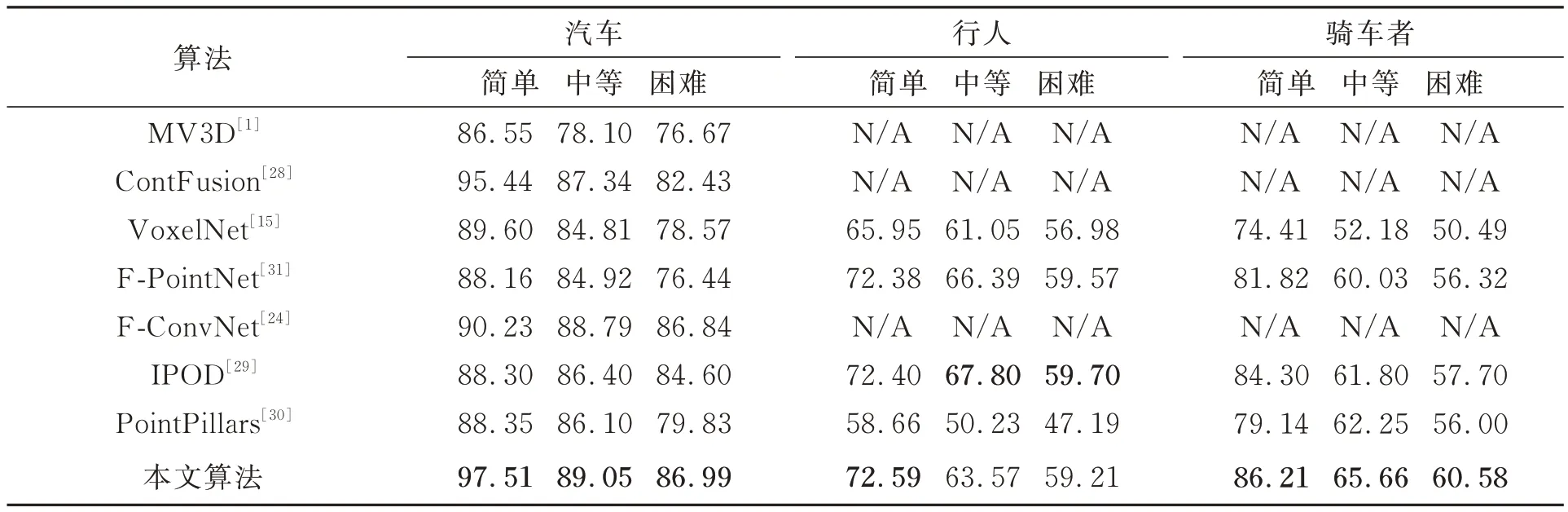
表2 KITTI 验证集汽车、行人与骑车者BEV 检测结果Tab.2 BEV detection AP(%)of cars,pedestrians and cyclists on KITTI val set
由于正负样本的不平衡,检测的召回率是算法性能重要的考虑指标。图6 显示了汽车、行人和骑自行车者的三维检测精度(Precision)随召回率(Recall)的变化曲线。从曲线可以看出,在召回率达到60%的情况下,各监测项均能实现超过60%的监测精度,其中,汽车表现最优,在召回率达到80%的情况下检测精度仍能超过80%,这表明了算法对于目标检测任务的有效性。

图6 汽车、行人和骑自行车者的三维检测精度和召回率曲线Fig.6 3D detection AP and recall curves for cars,pedestrians and cyclists
图7 和图8 显示了KITTI 数据集上部分目标检测的可视化结果,包括汽车、行人和骑自行车者的检测结果。其中,绿色框代表目标框,红色框代表检测框,包括二维图像中的二维框(左侧)和三维点云中的三维框(右侧)。图7 中,在密集和稀疏点云中都能成功检测到汽车,表明该网络对点云的不均匀分布有很强的适应性。另外,图7(b)中远处遮挡严重、点云较少的车也能成功检测出来。结果表明,该网络对汽车具有良好的检测效果。图8 中,行人和骑车者的检测性能较汽车差,图8(a)中最前面的行人没有被检测出来,这是因为训练集中骑车者和行人相对较少导致网络训练不足。另外,骑车者和行人的特征相似导致的误判也降低了检测精度。

图7 汽车检测结果可视化Fig.7 Visualization results of cars

图8 行人和骑自行车者检测结果可视化Fig.8 Visualization results of pedestrians and cyclists
4.4 消融试验
为了证明N3_DIOU_loss 和投票模型的有效性,以 F-ConvNet[24]为基准,增加了两个网络层在汽车目标上进行相关的消融实验,结果如表 3~4 所示。表3 表明 N3D_DIOU_loss 和改进的投票模型在精度的提高上具有显著的作用。在3D 目标检测中,与传统F-ConvNet 相比,改进的投票模型可以有效地过滤并聚类点云,提高了0.21%的检测精度;N3D_DIOU_loss 可以提高目标框与检测框之间的重合度,进一步提升0.11%的检测精度,两者结合可以提升0.71%的检测精度。表4 的结果证实网络模型参数的微调可以对消融实验中各种结构的检测网络带来精度的提升。

表3 三维及BEV 检测对比Tab.3 3D and BEV detection performance

表4 参数微调实验对比Tab.4 Comparison of parameter tuning experiments
5 结 论
针对三维点云识别计算量大、准确率低的特点,本文提出了一种融合二维图像与三维点云特征的目标检测网络用于三维目标检测。论文首先利用二维图像目标检测框对应的平截头体限定点云的处理范围,然后提出改进的投票模型用于多尺度特征提取,并通过构造了包含分类损失函数与三维DIOU 损失函数N3D_DI⁃OU_loss 的多任务损失函数优化了网络训练过程及检测精度。KITTI 数据集上的识别结果及消融实验表明,本文算法提出的投票模型与N3D_DIOU_loss 对目标检测网络精度提升起到了重要作用,在三维检测精度上较F-ConvNet算法提高了0.71%,在BEV 检测精度上则提高了7.28%。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年11期)2018-08-04 03:25:38
测绘科学与工程(2016年5期)2016-04-17 06:51:15
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
