
基于机器视觉的聋哑人手语识别
——语音交互系统
2021-12-14 02:47北京工业大学
物联网技术 2021年12期
北京工业大学
王婧瑶,范 飞,刘豪宇,蒋钰雯
1 作品介绍
本项目旨在研究一款基于机器视觉的聋哑人手语识别—语音交互系统。将该系统集成在Jetson TX2开发板上,并嵌入设备载体,由用户随身携带,在不改变聋哑人生活方式的前提下,利用机器视觉以及深度学习等技术,为其与正常人更加便捷、高效的交流搭建友好的沟通平台。
初代产品的终端形态拟构建为智能眼镜,如图1所示。镜架侧面搭接双目摄像头,可以通过调节角度确定捕捉范围。摄像头后侧镜腿处,嵌入Jetson TX2开发套件,作为核心处理系统。另一侧镜腿上嵌入扬声器等元件作为语音模块,输出声音信号。

图1 初代产品示意图
扬声器一侧镜腿处,设置有开关按钮与音量键调节滚轮,以及蓝牙与充电插孔。同时,该设备电源等原件,以及布线皆在镜架内部完成搭接。参数规格如图2所示。
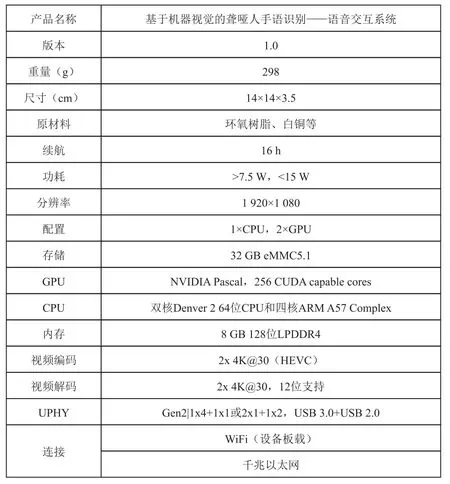
图2 参数规格
使用说明:开启设备镜腿一侧的开关按钮,摄像头处小灯亮起表明开始工作,扬声器一侧滚轮滑动调节声音大小。设备开启后,可将开关按钮拨动至中间档位(共分为三档,即开、关、中档),即可暂时关闭实时捕捉功能,设备将进入挂起状态,保持最低功耗。将档位拨动至“开”,即可继续实现交互,完成交流。同时,按动左镜腿第一个按钮,小灯亮起,表示语音开始提取,对方回复将会通过蓝牙传至手机端,将语音转为文字,便于用户实时查看转换结果。该设备可实现双向交互,无交流障碍。
若需要重新设置系统参数,例如在特定场合需要加载专业语言包,又或者需要重新设置交流音色以及相应频率,只需利用设备携带的蓝牙数据线连接电脑,登录设备网站或者通过相关附带插件进行语音包扩充、查看帮助文档,从而对设备进行重新设置。
后续也将推出扩充定制语音包,用户只需打开移动端的配套小程序或APP窗口,即可实现实时加载,适配多种环境与多种语言。
2 技术原理
该项目研究基于机器视觉、深度学习、运动捕捉等技术,通过Python编写并实现相关算法。运用嵌入式设备JetsonTX2,CMOS传感器,摄像头等搭建硬件系统,进而采集分析多种环境下的聋哑人手势动作及变化并进行识别,借助已有的语音数据库,建立不同手势与语音库中语言的对应关系,完成手势到语音的自动转换,实现语音输出。最终得到一款针对聋哑人的手语识别—语音交互系统。本系统技术路线以及相关硬件搭建如图3所示。
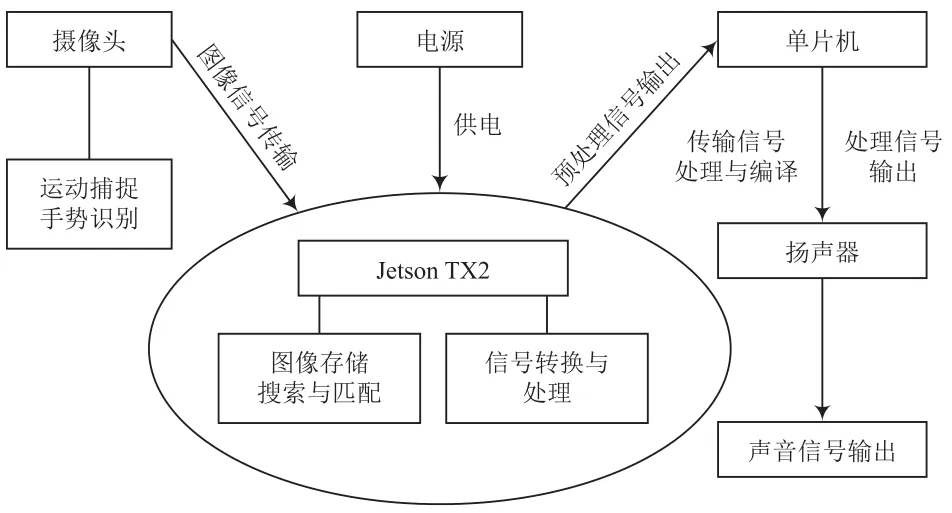
图3 产品设备搭建图示
产品算法的构建主要基于深度学习与机器视觉进行。利用基于高斯混合模型的水平集手部轮廓提取算法与粒子滤波算法等,构建视觉模块架构。又或通过Matting算法等进行图像边缘锐化、斑点检测和角点检测等,解决传统提取跟踪方法带来的精度问题,同时减小大数据流的存储空间进而降低成本。通过Python编写并实现相关算法。
结合高斯模糊、像素块填充的经典纹理合成与高维隐空间特征编码等操作,对采集的图片进行去噪、消除敏感信息等处理,并构建库。将构建好的图片库分为训练集与测试集,采用提取特征+快速搜索模式进行图像匹配,并对编写的手势匹配聚类模型进行训练,实现机器学习。
经测试集校验精度后,调整全局匹配和局部匹配的关系,考虑采用多线程形式搭接语音包,从而使聚类编译后的信号可以以语音形式输出。
建立基于刚性连杆结构模型的手势仿真,并模拟实际操作中的运行流程,调用API对算法进行模拟测试,调整不同光照等环境条件,以及虚拟仿生手的不同肤色特点,对系统进行参数微调。精度达到预期后,烧录进开发套件,并进行线路搭接,嵌入到设备载体中,完成样机的设计。
2.1 运动手语捕捉
(1)摄像机标定:确定空间中人手表面各关节点的三维几何位置与其在图像中对应点之间的关系,利用合适的摄像机标定算法,提高机器视觉的鲁棒性。
(2)手势图像分割与特征提取:手势特征提取过程需减除背景,基于肤色分割算法对已有的手势识别算法进行改进,并利用合适的算法对图像进行二值化处理,使图像转化为一个包含完整信息但仅突出手势信息的单一图片。
(3)手势估计与跟踪:利用水平集算法及其改进分割图像,配合适当的模型对手部动作的轮廓进行提取和跟踪,用均值漂移算法等跟踪轮廓内外的图像特征分布。
(4)手势行为识别:使用适当的分类器识别已有手语库中的手势,力求提高识别率。
2.2 图像存储
得益于硬件的选型以及合理的图像工具的选择,高速大容量数据存储器控制系统是以SATA接口为储存介质设计的控制器,Jetson TX2中提供了一个SD Card卡槽和一个SATA接口,用于扩展存储空间,因此选择将Jetson TX2作为载体。图像储存流程如图4所示。
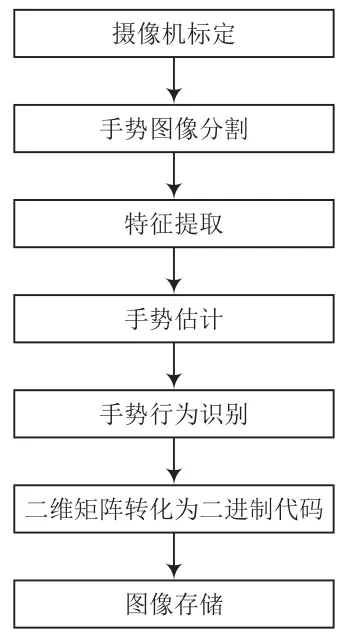
图4 图像存储流程
2.3 信号转换交互
信号转换可将机器视觉已识别出的与手势库中对应的图像和语音库中对应的语音联系起来。使用编码器和译码器在类似于FPGA的平台上搭建交互平台,手势识别完成后传入的二维矩阵信号通过递归、二分法等组成算法(如gram算法等),转化为二进制代码,传入语音系统后输出。信号转换流程如图5所示。
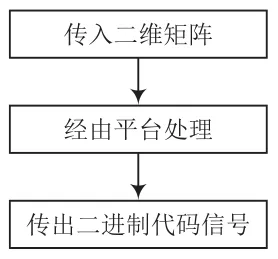
图5 信号转换流程
2.4 语音识别及输出
将用编码器和译码器转换的二进制代码借助交互平台输入语音系统,经过单片机(如WTN5055)等设备后,按一定控制模式进行语音编辑,翻译为声音信号,通过扬声器等播报。语音识别及输出流程如图6所示。
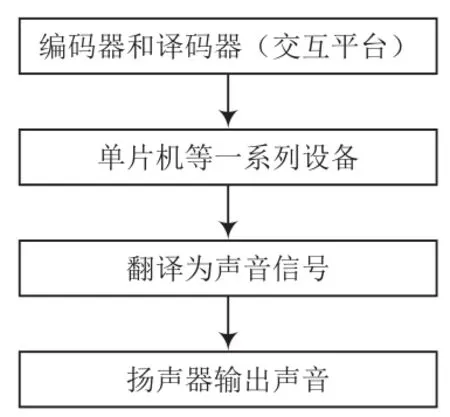
图6 语音识别及输出流程
2.5 硬件系统的构建
本项目组将Jetson TX2,Kinect摄像头等硬件进行线路设计与组装连接。包括系统架构设计搭建、手势检测算法的硬件搭建、任意手形转换语音的硬件搭建、语音系统的硬件搭建等。对所有需要用到的硬件(TX2等)进行合理布局,制作能够实现本项目功能的硬件系统。
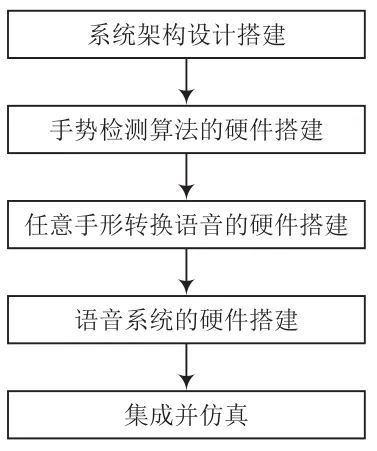
图7 硬件系统搭建
2.6 库的建立与补全
(1)图像库的建立:搜集较为完备的手语图像数据(标准手语),将已有资源导入库,使用适当的分类器对于图像进行特征分类,与计算机运用算法处理后的图像相匹配,转为二维矩阵的二进制代码。
(2)语音库的建立:搜集较为完备的语音数据,将已有资源导入库,通过插入交互平台的语音系统(单片机等部件)端口连接,运行时与计算机识别结果相匹配。
3 作品创新点
本产品从八大维度进行创新。
(1)技术:开创性提出六大算法,支持弱光等环境,实现高鲁棒性算法支撑。
(2)应用:已研发面向聋哑人群的,包含《蔚蓝时代》在内的三款产品。将在未来5年内实现1.0~5.0的更新。
(3)产品:采用更加贴合生活用品形式的眼镜作为载体,更加便携;手语同传,轻量级硬件。
(4)集成:以本产品为突破口,将人工智能与助老助残紧密结合,开创算法以及嵌入服务式设备,带动高科技助老助残、人机交互、嵌入式医疗、仪器定制生产等领域的再发展,实现技术的消化吸收和再创新。
(5)设计:首次提出“内核+”的设计理念,融入不同载体,在不改变用户日常生活的情况下满足多环境需求。
(6)模式:“点面结合”进行宣传销售。
(7)服务:定制化服务,根据用户职业和身份,量身打造语音包、手语库(如方言、外语版),根据场合定制设备载体形态;进行“一对一”指导服务,提供良好的用户体验。
(8)兼容性:增加定位、监测、图像识别等功能;提供耐高湿、高温等特殊材料;多种载体形态,进一步扩大兼容性。
4 发展前景及市场空间
自国家号召助老助残以来,我国助老助残创新项目大量涌入,在国家的大力关注和资金投入大背景下,助老助残项目逐渐增多,但针对聋哑人的产品却很少。而我们研发的这一产品填补了聋哑人语音交互系统的部分市场空缺,前景广阔。
由于产品开发地在北京朝阳区,在产品推广初期,可以与朝阳区残联以及朝阳区的中国聋儿康复研究中心启聪幼儿园建立合作意向,向他们销售产品,待其试用无异常后,与残联达成合作,在残联的帮助下进行推广。
根据调查,北京的聋哑人学校多集中在城区,如西城区的北京第一聋人学校、北京第二聋人学校,海淀区的北京第三聋人学校,北京市健翔学校等。同时我们可以向大型商场、车站和机场推广产品,由商场、车站、机场购买产品,在其业务办理窗口前放置产品,免费提供给聋哑人使用。后期经过产品的不断改进与推广,期望产品可以覆盖北京市场。而随着用户群的增加,潜在客户也越来越多,市场占有率也将得到进一步提升。
猜你喜欢
疯狂英语·新阅版(2023年5期)2023-05-31
作文周刊·小学三年级版(2020年36期)2020-10-15
红领巾·萌芽(2019年9期)2019-10-09
活力(2019年15期)2019-09-25
小学科学(学生版)(2018年12期)2018-12-19
快乐语文(2017年8期)2017-05-18
青少年科技博览(中学版)(2015年8期)2015-10-28
湖南警察学院学报(2015年3期)2015-03-28
