
基于改进SVM算法的车牌识别研究
2021-12-10 02:48唐瀛闫仁武
现代计算机 2021年30期
唐瀛,闫仁武
(江苏科技大学计算机学院,镇江 212003)
0 引言
随着我国经济的持续良好发展,机动车保有量持续增长[1]。汽车在给人们带来便利的同时也带来了交通拥挤、环境污染等一系列社会问题,这些问题随着汽车数量的增加日益严重[2]。车牌识别系统[3]不仅可以实现车辆快速进出,减少碳排放量和车辆损耗,降低PM值,而且可以显著降低交通管理中的运营成本,节约人力资源,提高服务速度[4]。车牌识别系统性能最重要的影响因素就是车牌字符识别的算法选择。在一些小样本分类问题上,SVM表现非常好,因此,本文提出了一种优化SVM算法[5-6]的方案并进行深入研究。
1 车牌识别系统
在一个车牌识别系统中,一般按流程可分为以下4个步骤:①车牌图像获取;②车牌定位;③车牌字符分割;④车牌字符识别。主要流程如图1所示。

图1 车牌识别系统流程
1.1 车牌图像获取
车牌图像获取又分为图像灰度化[7]、平滑处理、边缘检测与提取[8]和形态学处理四个步骤,有助于车牌的定位与识别。
1.1.1 车牌图像灰度化
图像预处理包含许多方法,目的是让后续的操作与程序运行具有更快的处理速度或者得到更符合识别信息的图像,对整个系统的识别效能影响重大。一张普通的彩色图像由很多像素点组成,而每个像素点都是由红、绿、蓝(RGB)三元色组成,而一张包含车牌的图像除了车牌以外,还存在其他的颜色信息所干扰,所以本文选择首先对车牌图像进行灰度化处理,以过滤掉图像中存在的其他信息,提高运算速度。其灰度化公式为:

其中,xyz是灰度化的处理系数,当取值为x=2.99,y=0.587,z=0.114时,原图以及得到的图像如图2和图3所示。

图2 原图

图3 灰度化处理后结果
1.1.2 平滑处理
“平滑处理”也称“模糊处理”(blurring),是一项简单且使用频率很高的图像处理方法。平滑处理的用途很多,但最常见的是用来减少图像上的噪声或者失真。通过提取边缘和形态学处理能够获得大致的车牌区域,但还是会受到一些噪声和其他因素的影响。高斯滤波的通用性与性能都比较好,并且由于是线性滤波,算法的时间复杂度很小。因此在实际项目中我们使用高斯模糊去噪对图像进行平滑处理,来消除噪声和其他因素的影响。得到的图像如图4所示。

图4 平滑处理后结果
1.1.3 边缘检测
边缘检测本质上就是一种滤波算法,通过滤波来提取图像特征,消除图像数字化时所混入的噪声。常用的边缘检测算子有Soble算子、Rob⁃erts算子、Canny算子等。Roberts算子常用于获取图像的边缘,而且定位准确,所以我们选择它来进行边缘检测。Roberts算子是利用局部差分寻找边缘线条,利用对角线方向相邻两元素之差近似梯度幅值来检测边缘,对于原始图像f(x,y),Roberts边缘检测输出图像为g(x,y),该算法处理在图像边缘接近于+45°或-45°时效果最佳。在像素点P5处使用Roberts算子对x和y方向上的梯度大小gx和gy的计算原理如图5所示。

图5 Roberts算子原理
处理后的图像效果如图6所示。

图6 提取边缘结果
1.1.4 形态学车牌图像处理
数学形态学主要用于从图像中提取对表达和描绘区域形状有意义的图像分量,在图像处理领域是应用最广泛的技术之一。二值图像的基本形态学运算有膨胀、腐蚀、开运算和闭运算[9]。使用形态学操作可以消除图像中的干扰边缘像素点,方法是通过形态学运算,找到可能包含车牌信息的矩形区域。形态学处理基本运算有:

处理后的图像效果如图7所示。

图7 形态学处理结果
1.2 车牌定位
在我们进行处理之后会有许多区域,我们需要在其中找出最符合车牌轮廓的区域,然后筛选出车牌轮廓信息,最后确定车牌图像的位置。我们通过设置车牌长宽比参数范围来筛选确定车牌位置。首先分别计算这些图形区域水平方向与垂直方向上不为0的像素点个数,作为其长与宽,通过设置长宽比取值范围进而确定矩形尺寸是否满足要求,最终确定车牌位置;其次根据车牌位置把只包含车牌信息的图像从原图中提取出来。提取出的图像效果如图8所示。

图8 车牌定位结果
1.3 车牌字符分割
车牌字符分割[10]是根据车牌的特点对字符进行分割,将车牌区域划分为单个独立的字符,所以获得精确的单字符图像对字符识别有着重要的影响。因为车牌字符存在间隔,所以在分割时不会出现多字符连接在一起的情况,然后去寻找具有连续文本的区域,字符分割效果如图9所示。

图9 字符分割结果
1.4 车牌字符识别
使用字符归一化处理可以使字符大小统一,使字符识别更加快捷准确。本文调用opencv中的cv.resize函数将字符图像统一尺寸大小,接着对字符进行特征提取,对于图像都需要经过特征提取之后才能使用相应的识别算法进行识别,本文采用的是基于HOG的特征提取,将提取的字符图像黑白像素的特征参数用于SVM算法的分类标准,HOG特征在识别目标的形状信息具有明显的优势,该方法在提取过程中先将图像划分为小的连通区域,然后再从各区域上采集各像素点边缘方向上的直方图,接着将这些直方图的数据组合,再由SVM算法识别特征数据。车牌识别结果如图10所示。
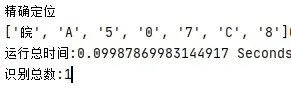
图10 车牌识别结果
2 SVM算法及其优化
2.1 支持向量机算法(SVM)
基于统计学习理论的支持向量机算法(SVM)是处理小样本数据集问题的机器学习分类算法。假设训练样本集为(xi,yi)(i=1,2,…,m),其中xi为输入变量,yi是对应的预期值,m是样本的数量,在线性回归的情况下,利用SVM构造一个目标函数,可获得最优分割超平面的函数为:

式中:x∈Rm为权值矢量,b∈R为偏差量,求权值ω和偏差b可以通过下面的求解最优问题来解决:

式中,Q是优化目标,C是惩罚因子,δi,是松弛系数,ε是精度参数。
对于处理非线性回归问题的情况,SVM的处理方法是选择一个核函数,通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。使用拉格朗日函数可获得线性回归函数:

式 中:αi、是拉格朗日因子,K(x i,y i)是核函数。
本文采用高斯核函数来映射数据并求取最优分类面,高斯核函数的计算公式为:

2.2 改进支持向量机算法
2.2.1 对关键参数C和核参数g使用网格搜索算法
为避免惩罚因子C和核参数g过学习和欠学习的发生,通过网格搜索算法优化惩罚因子C和核参数g,把SVM算法中的惩罚因子C和核参数g在给定的范围内划分为网格,遍历所有网格节点的取值,然后获得最高的分类准确率的点,并将该点对应的因子C和核参数g作为最优参数,提高SVM分类准确率。网格搜索算法[11]分为4步:
(1)设定C和核参数g的取值范围都设为[2-8,28]以间隔为1构造基于(C,g)坐标系的网格;
(2)顺序选取一组参数(C,g),用于模型训练和测试中;
(3)将训练样本集均分,共分为K个子集,从中任选一个训练样本子集作为测试集,剩余的K-1个训练样本子集作为训练集,对选取的测试集中的(C,g)进行K倍交叉验证,然后更换训练集和测试集,直至每一组子集都作过测试集,计算K组分类准确率的平均值;
(4)重复(2)和(3),直至网格参数组合全部被选取,然后对各参数组合下准确率平均值由大到小排序,筛选出最大准确率平均值对应的(C,g)作为所求最优参数。
2.2.2 基于密度的训练样本裁剪方法
基于密度的样本裁剪[12]分为两步:
设Dist(X,Y)为样本集中X与Y之间的距离,定义X的ε邻域为Nε(X)=Dist(X,Y)≤ε。
设定样本集M=C1⋃C2⋃C3⋃C4⋃…Cm(i=1,2,…,m)代表一个样本类别,且C i⋃Cj=∅(i,j=1,2,…,m),任意的X∈Ci,如果X的ε邻域的所有样本都属于Ci,则X位于类内区域,否则X位于类边界区域。
给定邻域半径ε和最少样本数值Minpts(Minpts>0)。对于任意的样本X和X邻域内的Y,若|Nε(X)|=Minpts,则X处于均匀密度区域;若|Nε(X)|>Minpts,则X处于高密度区域,且Y与X高密度可达;若|Nε(X)| (1)对训练样本X进行裁剪,当X位于类边界区域,则将与样本X高密度可达的样本裁剪掉;若X位于类内区域,则保留X的ε邻域内的所有训练样本,由此去除了样本集的噪声和冗余样本,提高了分类准确率和降低了计算量; (2)给定邻域半径ε和整数low,对于任意从第一步中筛选出来的样本X,如果|Nε(X)|>low,则将与X高密度可达的样本裁剪掉,直到|Nε(X)|=low时停止裁剪;如果|Nε(X)|≤low,保留X的ε邻域内的所有训练样本。 为验证改进SVM算法在汽车识别系统中的有效性,对互联网上下载的500张不同条件下的车牌图像,在配置为Windows 10系统I7 7700@2.9GHz CPU,16G内存的计算机,使用Python 3.4版本,Pycharm工作运行环境中进行了车牌识别实验,图10为本文示范车牌识别的批量识别结果。 图10 批量车牌识别 然后统计数据,与神经网络法[13],传统SVM算法在识别率和识别总时间上进行对比,在相同的实验数据集上,实验结果如表1所示。由表1中可以发现,SVM改进算法与神经网络法相比具有更快的识别速度,且识别率差不多,与传统SVM算法相比在识别速度和识别率上都有了较大的提升。 表1 实验结果对比 本文介绍了车牌识别系统和SVM算法,并对SVM算法进行了改进,使用密度裁剪算法裁剪训练样本,适度的减少了训练样本的数量,去掉冗余数据,降低了计算量。同时在裁剪后的新的训练样本集上对惩罚因子C和核参数g进行优化,对SVM算法中的惩罚因子C和核参数g使用网格搜索算法获得最高的分类准确率的点,并将该点对应的因子C和核参数g作为最优的参数组合(C,g),提高SVM分类准确率,并在实际项目中获得了较好的实验结果,说明该优化方案能够提高车牌识别的性能。3 实验结果


4 结语
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
齐鲁艺苑(2022年1期)2022-04-19
电脑报(2021年41期)2021-11-04
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
科技视界(2016年26期)2016-12-17
农机使用与维修(2014年10期)2014-10-23
