
基于Kubernetes云原生的弹性伸缩研究
2021-12-09 06:04赵树君
计算机与现代化 2021年11期
赵树君,黄 倩
(河海大学计算机与信息学院,江苏 南京 211100)
1 背景介绍
1.1 云原生的弹性伸缩
随着云服务[1]的不断兴起,各公司的软件应用都开始向云上迁移,可以是公有云、私有云或者混合云。新研发的软件应用在设计开发之初就为了部署到云平台,利用云平台的特性来服务应用开发,这些应用就是云原生的应用。根据云原生计算基金会(CNCF)的定义,云原生[2]技术使组织能够在现代动态环境(例如公共云、私有云和混合云)中构建和运行可伸缩应用程序。容器[3]、服务网格[4]、微服务[5]、不变的基础结构和声明性API就是这种方法的例证。可以看出,云原生是一种方法论,旨在帮助企业构建高可用、高可靠、易用、易于管理的松耦合的系统,让工程师不用特别关注系统环境的变化,而更专注于系统本身特性的开发和维护。
云原生的一个很重要的特性就是支持弹性伸缩[6],弹性伸缩可以满足业务需求,保证系统服务质量。弹性伸缩还可以让系统的部署规模根据业务量进行实时调整,业务高峰的时候自动扩容系统资源,保证系统平稳运行;业务低谷时自动收缩系统资源,保证资源利用率,不浪费系统资源。利用云系统资源按需获取、按量计费的特点,可以节省企业成本,开发人员仅需关注于系统业务需求的开发,不用过多关注系统在分布式环境下的伸缩问题,而这些问题都交由云平台来完成。
弹性伸缩又分为水平伸缩和垂直伸缩。垂直伸缩是指伸缩单个服务器的硬件资源来实现的,对应用系统本身无感,但是对云服务器提供商要求较高,另外单台服务器的资源有限,业务高峰时可能无法满足要求。水平伸缩则是依靠增减服务器数量来实现弹性伸缩,但是要求应用系统是无状态的,伸缩过程中系统之间的调用关系要进行实时调整,这正是微服务架构可以解决的问题。
1.2 云原生的5G核心网的弹性伸缩
5G[7]网络是继4G网络之后又一划时代的网络,不仅在4G的基础上提升了网络传输速度,而且增加了很多面向垂直领域的支持,例如IoT[8]、汽车自动驾驶[9]、智能家电[10]等。随着5G网络的不断建设和普及,企业和个人对于5G网络的需求在不断增加,个人可以获得更好的网络体验,企业可以更好地利用5G网络服务自身的发展。
5G核心网是终端用户与基站的桥梁,核心网的系统负载有自己的独有特性,终端使用越多则负载越大。以个人5G手机[11]为例,每天早晚、节假日是负载增加的时候,早晨手机关闭飞行模式、刷朋友圈等都要经过核心网;节假日手机使用更频繁,负载更大;午夜过后使用人数减少,负载变小。不难看出,5G核心网的负载在不断变化,云原生中的核心网则更需要根据负载的变化来进行系统资源的调整伸缩,确保系统资源能够得到最大限度的使用并且不浪费资源、节约系统资源。
随着5G网络的不断普及和使用,研究5G核心网的弹性伸缩意义重大,不仅可以助力企业更高效地使用5G网络,而且可以帮助5G网络的运营商更好地将5G网络部署到云端,并按需提供系统资源。
5G核心网的负载有自己的独特特点,早晚负载大,节假日负载大,而且5G网络运营成本巨大。云原生的5G核心网动态伸缩研究,不仅可以帮助网络运营商在云平台上实时动态调整资源,提高资源利用率,解决运营成本,而且可以帮助企业更好地融入5G网络,利用5G网络助力企业发展。本文研究基于云原生5G核心网的弹性伸缩,从图1不难看出,5G核心网功能众多,本文以其中的一个网元功能PCF[12](Policy Control Function)为例来研究弹性伸缩,可以推广到整个5G核心网乃至其他云原生应用的弹性伸缩。
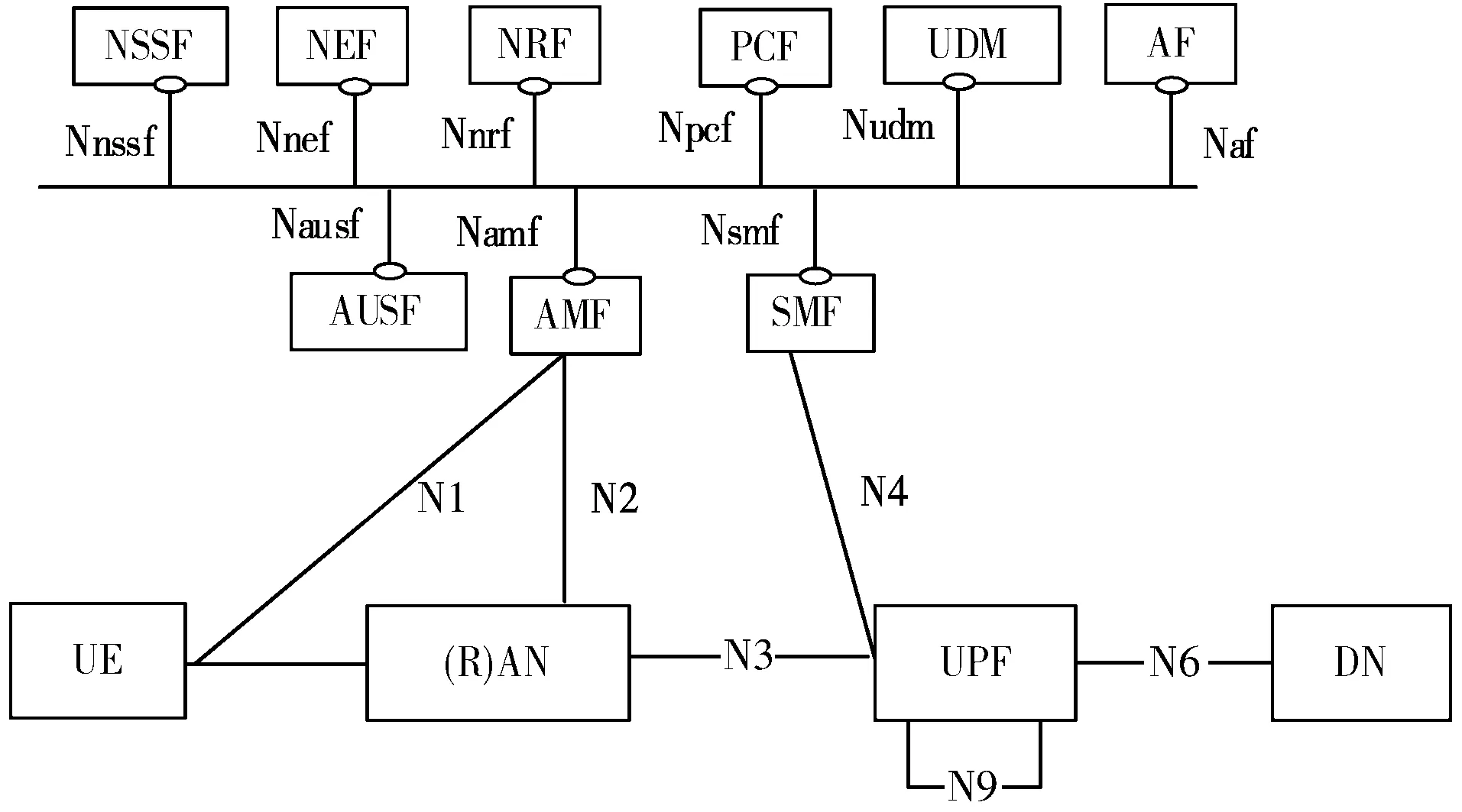
图1 5G核心网整体架构图
2 基于Kubernetes的弹性伸缩现状
2.1 当前Kubernetes弹性伸缩现状及原理
5G在设计之初就借鉴了服务化[13]的思想,5G核心网系统中的功能网元众多,导致整个系统的微服务个数较多,这样每个微服务容器化之后,容器的个数很多,在进行持续集成部署的过程中如果使用人工进行容器管理,很容易出错。容器是云原生系统中的基石,服务要支持进行单个升级更新,这样就在无形之中增加了部署运维的成本和难度。所以需要利用容器的管理编排[14]平台来实现自动化运维,而目前容器编排的事实标准就是谷歌的Kubernetes[15]。
在Kubernetes中管理的最小部署单元是Pod,一个Pod包含有一个或多个容器,这些容器共享存储网络等资源,所以在Kubernetes中的水平伸缩都是以Pod为单位的。但是Pod随时可能被删除或者重启,这样就需要将一个或多个Pods抽象暴露成网络服务(Service),Service负责将请求转发到Pod并进行一些负载均衡的工作。Kubernetes中存在一个水平Pod自动缩放器HPA[16](Horizontal Pod Autoscaler),HPA根据观测到的CPU或者其他定制的指标来计算副本数量,并与由开发者设定的CPU或内存的目标使用率与部署的副本数区间进行比较,并设定最终副本数,达到自动伸缩的效果。
从图2不难看出,HPA会从Resource Metric API或者自定义Metric API读取统计信息,并根据配置的HPA Yaml文件来动态伸缩。文件中定义伸缩的统计指标条件以及伸缩原则,这样HPA就能根据读取的统计信息来实现伸缩。
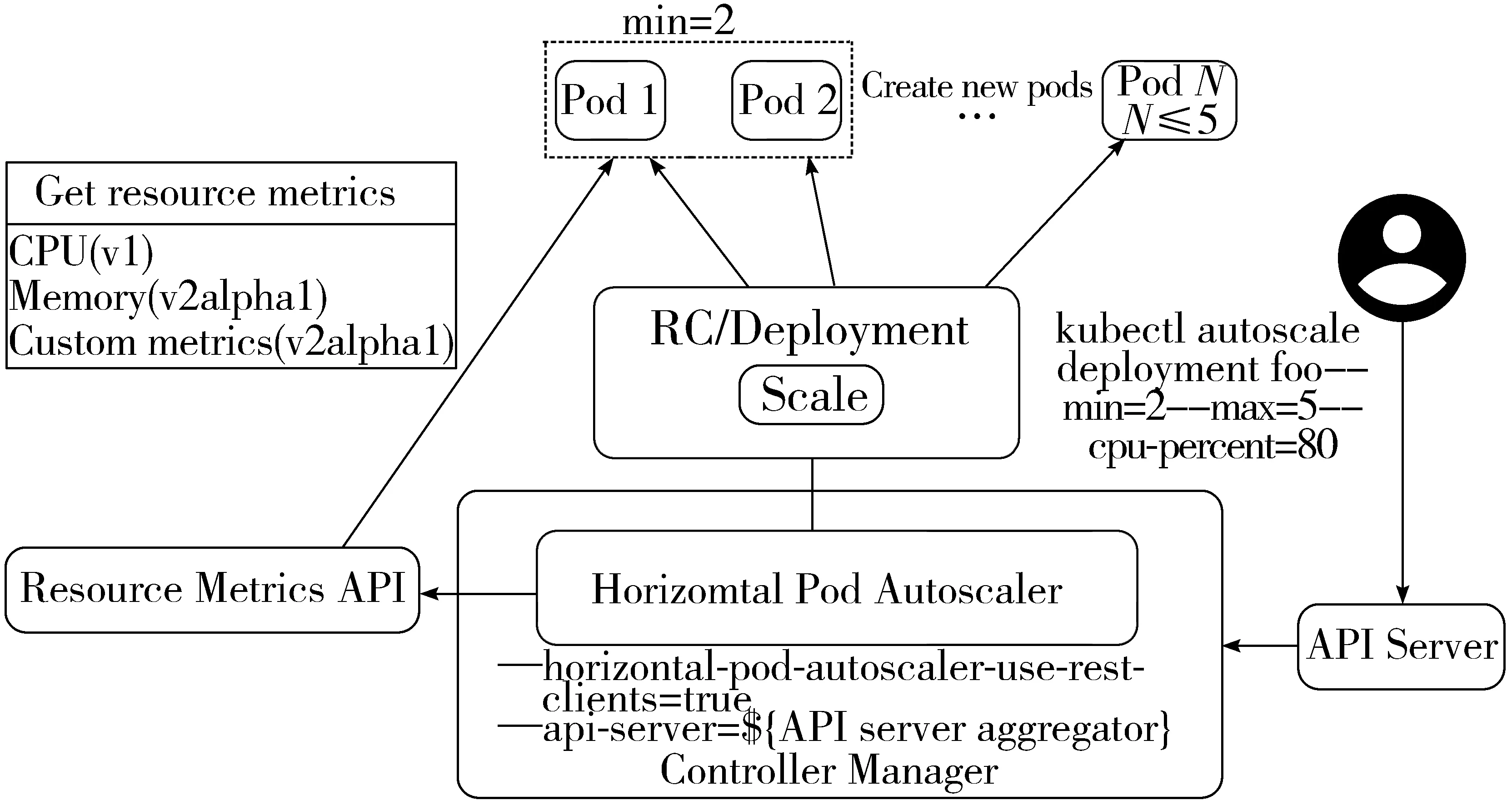
图2 Kubernetes HPA示意图
计算副本的基本算法如公式(1):
desiredReplicas=ceil[currentReplicas×(currentMetricValue/desiredMetricValue)]
(1)
期望副本数=ceil[现在的副本数×(现在的指标值/期望指标值)]。例如设置内存指标值为100 MB,副本数为2个,若当前的内存指标值为200 MB,则系统自动将Pod数扩展为4个。这些统计的指标值是由统一部署在Kubernetes集群中的指标服务(Metric Server)提供的。当然,用户也可以增加自定义的指标来为系统伸缩提供决策依据。
2.2 存在问题和研究方向
Kubernetes集群目前的自动水平收缩方法看起来可行,但是其中却蕴含着一些问题,例如Pod的自动缩放需要时间,在缩放的这段时间内,系统已经资源紧张饱和,若此时请求流量不降反增,系统服务响应时间增加,会引起请求的拥堵并引发服务调用链中的连锁反应,直接影响上下游业务系统,甚至会直接导致服务的不可用,破坏了系统的可用性。另外,在Kubernetes的HPA中提供了集群平台层面的CPU和内存的数据指标,但是没有基于应用的具体的业务处理统计指标,例如某个系统服务单位时间的请求和业务处理量,这些数据往往更能反映系统当前的业务健康情况,系统对于这些业务指标往往也更敏感,在动态收缩的时候这些数据是必不可少的,也应该是重要参考依据。这些问题在分布式系统中的影响显而易见,在5G核心网中的影响更甚,例如某个系统服务的暂时不可用会导致5G网络的暂时中断,不仅会导致普通移动设备用户的体验不佳,而且在一些垂直应用领域,例如汽车无人驾驶等领域,5G网络的不稳定或者稍许抖动都会导致无法预测的严重后果,危及设备乃至人身安全。
从图2不难看出,水平自动伸缩器以一定时间间隔定期读取统计信息并作出相应动作。如果读取时间间隔设置过长,系统资源已经严重不足需要扩容,但是还未到最新的读取时间,导致读取不到最新数据,可能会导致系统的崩溃;如果将读取时间设置得过短,会带来很多不必要的请求,影响系统性能。
由于Kubernetes HPA自带统计信息缺失很多重要统计数据和统计信息,可能读取不及时从而会导致一些问题。为此,本文针对基于Kubernetes的云原生5G核心网找到一种智能的、平滑的、提前感知的、基于具体应用统计指标的动态弹性伸缩方法,让系统在缩放过程中既不会导致系统的不稳定或者抖动,更不会影响现有业务请求的处理,并且可根据系统资源要求提前伸缩。
3 弹性伸缩方法研究
Kubernetes本身就有扩展性,可以进行二次开发,但是开发难度较大,成本大,需要深刻了解Kubernetes的核心原理和实现;另外Kubernetes作为平台型工具,很多情况下作为应用系统提供商只有使用权限,没有定制权限,特别是在多租户的Kubernetes环境中;而且二次开发可能需要根据Kubernetes版本的不断变化进行同步更新。基于以上原因,本文不进行Kubernetes的二次开发,而是针对目前Kubernetes中HPA的问题,设计一套基于预测未来系统负载,并根据预测的系统负载数据的变化值来提供系统伸缩决策依据进行动态伸缩的方法,并提炼为一个云原生的微服务,跟应用系统同时工作。这样既解决了要提前感知资源消耗情况来伸缩,防止系统长期过载或空闲的问题,又可以顺滑地伸缩,不影响业务逻辑的处理。
本文的S-HPA相对于Kubernetes自带的HPA的优势在于:
1)S-HPA不采用Kubernetes自带的Metrics Server,而是自研的Metrics Server,是一个独立部署的服务,以Side Car的形式跟PCF一起运行。Metrics Server不仅包含CPU、内存等简单的统计信息,还包括系统交易量、带宽使用情况等更能反映应用健康状况的负载统计要素,且Metrics Server可以单独更新,而不受限于具体的Kubernetes版本。
2)S-HPA的Metrics Server不仅收集应用的负载信息,而且会根据历史负载信息使用LSTM来预测未来的负载情况,并根据预测的负载情况判断是否需要动态伸缩。S-HPA核心功能有负载收集、负载预测、根据条件通知Kubernetes进行伸缩。
3)不同于HPA的定期拉取负载统计数据,S-HPA会在需要动态伸缩的时候直接调用Kubernetes API立即进行动态伸缩,这样就很好地避免了可能由于拉取时间间隔导致的动态伸缩不及时的问题。
如图3所示,Metrics Server获取PCF的负载信息,并使用LSTM根据历史负载信息预测未来负载,并根据未来预测负载决定是否需要伸缩,如果需要伸缩则调用Kubernetes API来进行伸缩。

图3 S-HPA简单示意图
本文设计的弹性伸缩方法是一套智能的、提前感知的、不影响系统业务的、顺滑的弹性伸缩方法。下面介绍具体实现细节和实验验证。
3.1 动态智能负载指标模型定义
首先,在负载指标模型的定义中,不仅需要考虑内存使用、CPU使用情况,更要考虑系统的单位时间请求处理量、系统网络带宽利用率,这些都是重要的负载指标,这些负载指标所占的权重根据具体情况而定。在本文中,系统的当前负载定义为L,内存使用情况定义为M,CPU的使用情况定义为C,系统业务请求量定义为T,网络带宽利用率定义为B,它们的权重定义为λ,其中:M,C,T,B∈[0,1]。系统的负载情况就是:
L=λ1M+λ2C+λ3T+λ4B
(2)
λ1+λ2+λ3+λ4=1
(3)
在公式(2)、公式(3)中,4个计量参数的权重根据指标重要性不一样进行调整,但是权重的和是1,而且在计算过后的负载量L∈[0,1]。其中L越大说明系统负载越大,系统越需要动态扩容。图4为系统负载因子图。
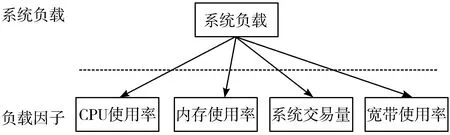
图4 系统负载因子图
在实际情况中,需要根据应用类型的不同来动态设置每个负载因子的权重,例如,计算密集型的加重CPU因子的权重,在本文中,为了研究数据的普遍性,故将每个负载因子的权重都设置为25%,4个因子权重一致。
定义了负载指标之后,就要解决如何动态智能地监控指标的变化,并根据监控指标的实时变化来决定是否进行动态伸缩的问题。
3.2 基于LSTM的负载预测
目前时序预测方法有很多种,例如自回归模型[17](Autoregressive Model)、移动平均模型(Moving Average Model)以及两者的结合体自回归滑动平均模型(Autoregressive Moving Average Model)等,以及最近研究十分火爆的基于神经网络的预测、卷积神经网络[18](Convolutional Neural Network, CNN)、BP[19](Back Propagation)网络。预测的方法和模型多种多样。这些方法各有优缺点,例如自回归模型预测虽然所需要的历史数据不多,但是需自相关,适用于预测与自身前期相关的现象和场景。本文研究的负载历史数据之间没有必然联系,是根据CPU等使用数据实时得到,而且在预测的时候,要考虑到历史数据的变化,且要具有记忆功能,为此本文选择了LSTM[20]来进行负载预测。
3.2.1 负载预测的描述
随着系统的运行,时序性的负载指标也就产生了。这些负载指标由当前运行的CPU、内存、系统交易量和带宽占用情况共同组成。基于这些负载指标数据,可以预测出未来某段时间的系统负载情况,并根据预测的未来负载来进行资源的弹性伸缩。
在得到这些监控指标之后,进行指标的收集处理、训练与预测,将某个Pod某段时间内的负载L可以记录为L={
3.2.2 LSTM简介
长短期记忆(Long Short-Term Memory, LSTM)是一种特殊的RNN[21],主要是解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。LSTM的特点是在RNN结构以外添加了各层的阀门节点。阀门有3类:遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。
LSTM的工作原理如图5所示。
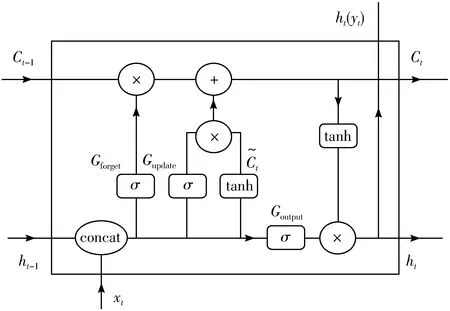
图5 LSTM工作原理图
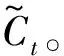
Gforget=σ(Wf[ht-1,xt-1]+bf)
(4)
Gupdate=σ(Wu[ht-1,xt-1]+bu)
(5)
Goutput=σ(Wo[ht-1,xt-1]+bo)
(6)
(7)
其中,Wf、Wu、Wo、Wc为权重参数,bf、bu、bo、bc为偏差参数,σ和tanh为Sigmoid和tanh激活函数。
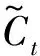
(8)
3)当前神经元隐藏状态Ct通过激活函数tanh并与输出门相乘,得到当前神经元的输出ht。
ht=Goutput×tanh(Ct)
(9)
LSTM多了一个隐藏状态Ct,用于在传递中选择遗忘和更新信息,是信息在神经元通道中传递的主要通路,由遗忘门和更新门算出。而ht是在隐藏状态产生后,通过Ct与输出门算出,作为当前神经元的输出。
3.2.3 云原生中的LSTM
云原生应用的目的是为了利用云平台的特性来更好地服务应用本身,云原生应用多是分布式的,这样就给系统数据的监控和采集带来了一定的难度。而LSTM要利用监控采集的数据来进行预测,这样就必须要将监控采集的数据聚合到一起,然后LSTM对聚合的数据进行处理等操作。监控数据的聚合工作可以依赖于消息队列将监控数据聚合到一起或者利用开源的日志采集框架例如ELK来完成这些工作。LSTM同样适用于云原生环境,只是要在使用LSTM之前做好数据的监控和采集工作。
3.2.4 数据准备与预处理
本文研究基于2020年9月1日—2020年9月7日真实网络采样点的5G核心网PCF网元的负载数据,以秒为单位聚合,最终得到时间粒度为1 s的负载数据100800条。
首先需要对数据进行预处理,原始数据可能存在缺失值与异常值。对于个别时间的缺失值,用前后时间点负载均值进行填补;如果一段时间缺失,则舍去这些缺失值。异常值在模型训练过程中会对模型效果产生偏差,根据拉依达准则,将[0.004, 0.996]区间外的值判定为异常值,然后进行平滑处理。然后将其中每条数据经过转换,去除无关的时间等信息,最后数值只包括当前负载值L。
关于异常值的剔除区间是统计了100800条数据的正态分布之后,假设一组数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。在正态分布中,σ代表标准差,μ代表均值,x=μ即为图像的对称轴,根据正态分布的基本原理,数值分布在(μ-σ,μ+σ)中的概率为0.6826,数值分布在(μ-2σ,μ+2σ)中的概率为0.9544,数值分布在(μ-3σ,μ+3σ)中的概率为0.9974。如图6所示。
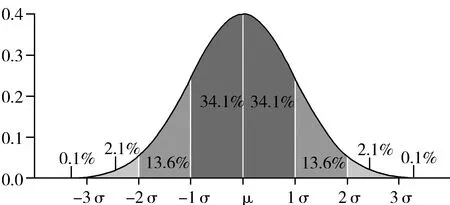
图6 拉依达准则示意图
根据拉依达准则剔除,一个正态分布的数据集的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%。而结合了本文采集的100800条数据的正态分布之后,剔除了小于0.004和大于0.996的负载数据。
本文模型的输入由2个部分组成,即序列数据与人为统计特征。序列数据是某个时间点的系统负载。设序列数据是长度为120(2 min即120 s)的负载数据,设置当前时间点为T,[T-119,T]共120个负载数据为序列数据输入,来预测下一个10 s的负载数据。
3.2.5 LSTM模型构建与训练
按照8∶1∶1的比例设置训练集、测试集以及验证集。本文采用Keras[22]来进行模型构建,参数采用Keras的默认值,例如激活函数为tanh等。LSTM模型的层级设置为3层,综上,本文的LSTM模型如图7所示。
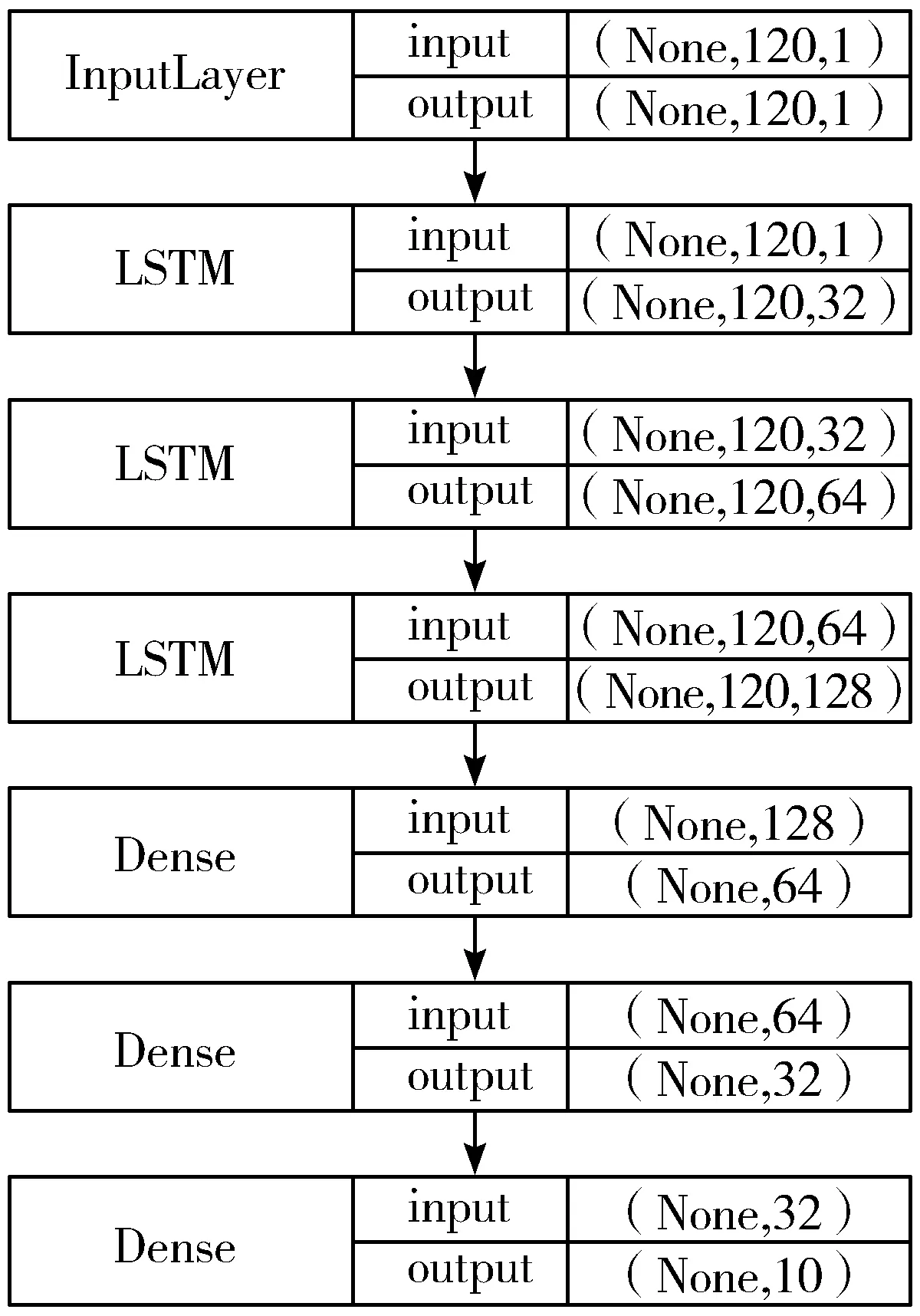
图7 LSTM预测模型
由于资源负载的预测结果不是绝对准确,预测值和真实值之间会存在一定的误差,因此需要对预测结果进行验证。本文使用平均绝对误差MAE、均方根误差RMSE和预测准确率FA(Forecast Accuracy)作为评判预测结果的3个指标,来验证预测的准确性。
1)平均绝对误差MAE:
(10)
平均绝对误差是指预测值与真实值的误差绝对值的平均值,反映预测值与真实值的误差。
2)均方根误差:
(11)
均方根误差是指预测值和真实偏差的平方和次数比值的平方根,能够很好地反映预测的精度。
3)预测准确率:
(12)
预测准确率可以很好地验证预测的准确率,直到准确率达到预期的标准。
3.3 LSTM预测实验
3.3.1 实验环境
本实验环境采用基于Python语言的神经网络API Keras,并采用TensorFlow[23]为后端,实验机器环境配置如表1所示。本文实验代码都是使用Python实现,代码量较大,本文中没有一一展示,只列举了实验环境的基本配置。
表1 实验环境配置
3.3.2 实验数据
本文基于2020年9月1日—2020年9月7日真实网络采样点的5G核心网PCF网元的负载数据,以秒为单位聚合,最终得到时间粒度为1 s的负载数据100800条。其中负载数据集均为标准的csv文件。
3.3.3 实验结果与评价
为了与本文方法的结果做参照和比较,将同样数据使用于CNN进行预测和统计,如图8和表2可以直观地感受两者预测结果指标。不难看出,LSTM在各项指标中均领先于CNN,且预测结果准确率符合事先预期,为后续根据预测结果来进行动态伸缩提供了强有力的数据支撑。
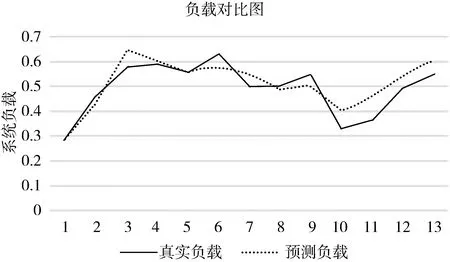
图8 LSTM预测结果
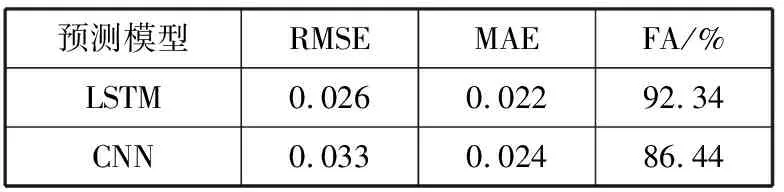
表2 预测结果指标
3.4 基于负载预测的动态弹性伸缩方法介绍
在LSTM预测了未来10 s的负载数据之后,需要根据这些预测数据来判断核心网某个服务Pod所需的资源要求,从而进行动态的、提前感知的、顺滑的动态伸缩,在不影响现有交易数据的情况下实现服务Pod的动态伸缩。而资源利用率每秒变化属于正常现象,因为每秒系统处理的交易量和资源使用情况不一样,而且任何预测(包括LSTM)的预测准确度不可能达到100%,这样就不能简单地根据某一秒的预测数据进行资源伸缩,而是要通过计算比较未来几秒负载的变化率来决定是否进行动态伸缩。除了进行变化率比较之外,还需要设置一个阈值,若负载到达了这个阈值临界值,不论变化率如何都要进行伸缩,防止某一单项资源被耗尽系统仍然未进行伸缩。
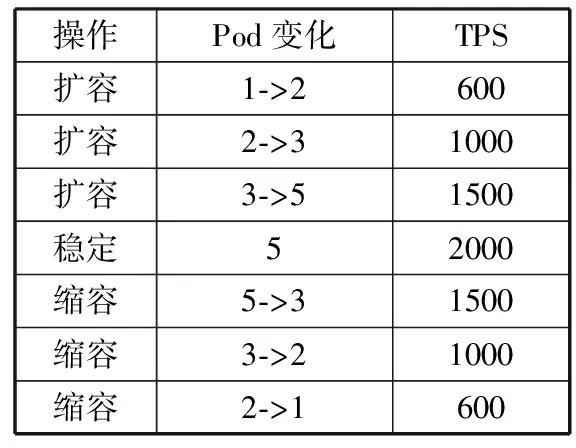
在介绍扩缩容的算法前,需要说明一下阈值的设置和扩缩容副本变化量的取值标准。在Kubernetes环境中的测试和实验,主要测试的是动态扩容的时间消耗和扩容副本数量的关系,以及伸缩后的Pod数量会不会又立刻触发新一次伸缩,同时也是为了充分利用资源,提高Pod的响应效率。本文设置动态扩容的阈值为0.6,动态扩容的副本数量为原先副本值的1.5倍,向上取整;动态缩容的阈值为0.1,动态缩容的副本数量为原先副本的75%,向上取整;如果达到阈值则立刻触发伸缩;未达到阈值时,伸缩的判断时间为未来5 s,每秒的变化率为10%,这样就在未到达阈值也会动态触发伸缩。
由于本文中的LSTM预测的是未来10 s的负载数据,那阈值必然在1~10之间产生。为此本文针对这些数值都进行了测试,阈值为1~4时扩缩容的效率很高,达到了提前感知的效果,但是准确性不高,导致了不必要的伸缩,浪费了系统资源;阈值为6~10时扩缩容准确性较高,但是提前感知的效果不佳,跟Kubernetes自带的HPA差距较小。而阈值为5时取得了提前感知的效果与准确性的平衡,两者兼顾,故本文中的阈值设置为5。
此弹性伸缩算法同样也适用于其他根据变化率来弹性伸缩的场景,例如根据网站用户量的变化来伸缩等。
3.4.1 动态扩容
为了更好地利用和扩充资源,首先设置一个动态扩容的阈值,如果某一秒的负载数据到达或大于此阈值,必须立即进行扩容;否则,如果未来5 s的资源利用率提升变化均超过10%,则提前进行扩容。扩容流程如图9所示。
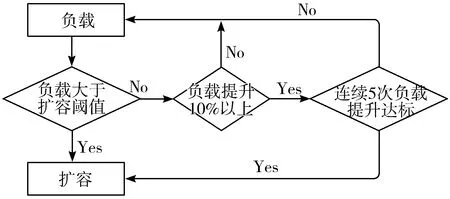
图9 扩容流程图
算法1 Pod动态扩容算法
输入:LSTM预测的负载序列L,长度为10
1.number←0
2.whilei<=10
3.ifLi>scaleOutThreshold /*判断负载是否大于扩容阈值*/
4.triggerScaleOut /*触发扩容*/
5.else
6.if(countRate()>percent) /*增长变化比较*/
7.number++
8.if(number>=5)
9.triggerScaleOut /*触发扩容*/
10.end while
算法中的triggerScaleIn和triggerScaleOut就是调用Kubernetes API修改Deployment文件进行Pod 数量变更。可以直接通过脚本调用kubectl apply命令来实现,或者在服务很多的时候通过helmchat来实现,这样就能实时进行资源的伸缩。
其中,一旦新Pod创建成功,Service就能立即选择到它,并会把请求转发给Pod,但是,一个Pod启动和加载是需要时间的,如果Pod还没准备好(可能需要时间来加载配置或数据,或者可能需要执行预热程序),这时把请求转给Pod的话,Pod也无法处理,造成请求失败。Pod扩容就绪图如图10所示。

图10 Pod扩容就绪图
如果想解决这个问题,可以给Pod加一个业务就绪探针[24](Readiness Probe, RP),当检测到Pod就绪后才允许把Service请求转给Pod。
下面的实验统计了100000次请求,从图11中不难看出,使用了就绪探针的Pod的水平伸缩(HPA)失败的请求是0,原因就是Service会等Pod完全准备好了才会转发请求,没有使用就绪探针就会出现不少的失败请求。当然使用了就绪探针的请求的平均响应时间要比没有使用就绪探针的要长(见图12),因为更多的请求流量被路由到了现有的Pod中,所以使用就绪探针是一种妥协折中策略。
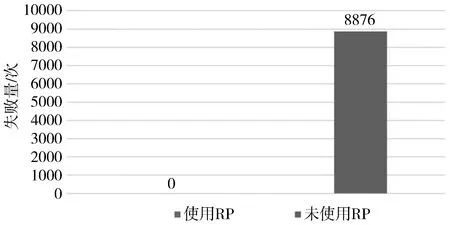
图11 失败请求统计
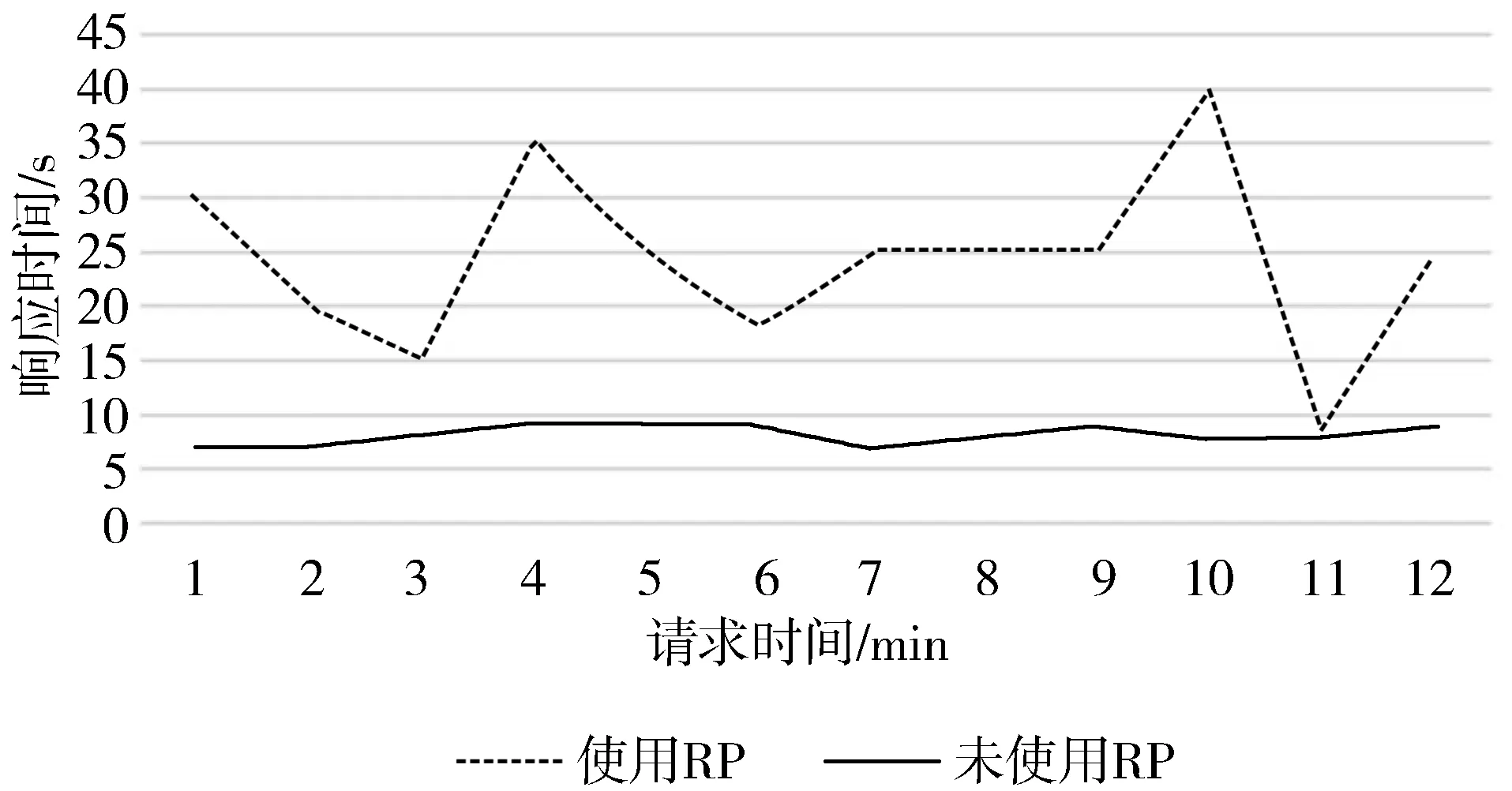
图12 响应时间统计
3.4.2 动态缩容
为了更好地利用和缩容资源,首先设置一个动态缩容的阈值,如果某一秒的负载数据到达或小于此阈值,必须立即进行缩容;否则,如果未来5 s的资源利用率减少变化均超过10%,则提前进行缩容。缩容流程如图13所示。
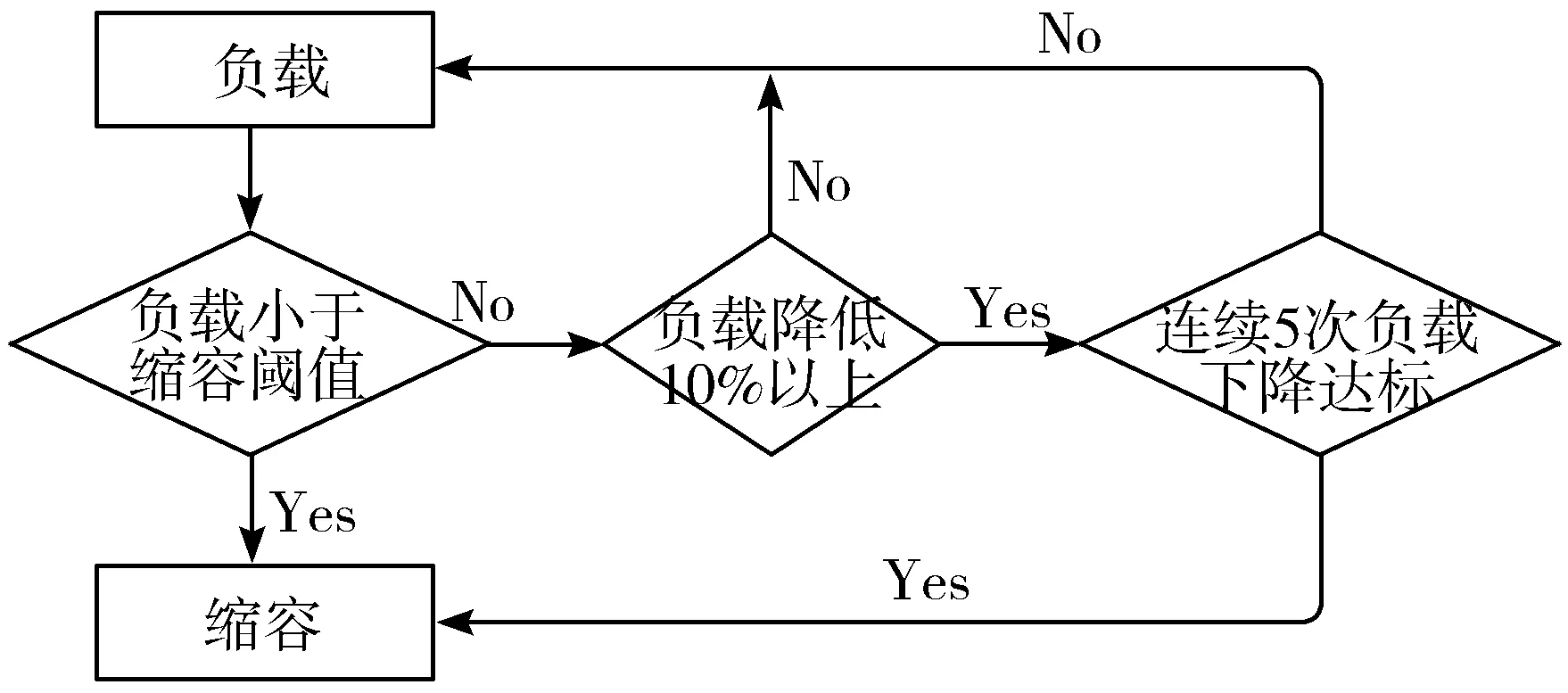
图13 缩容流程图
算法2 Pod动态缩容算法
输入:LSTM预测的负载序列L,长度为10
1.number←0
2.whilei<=10
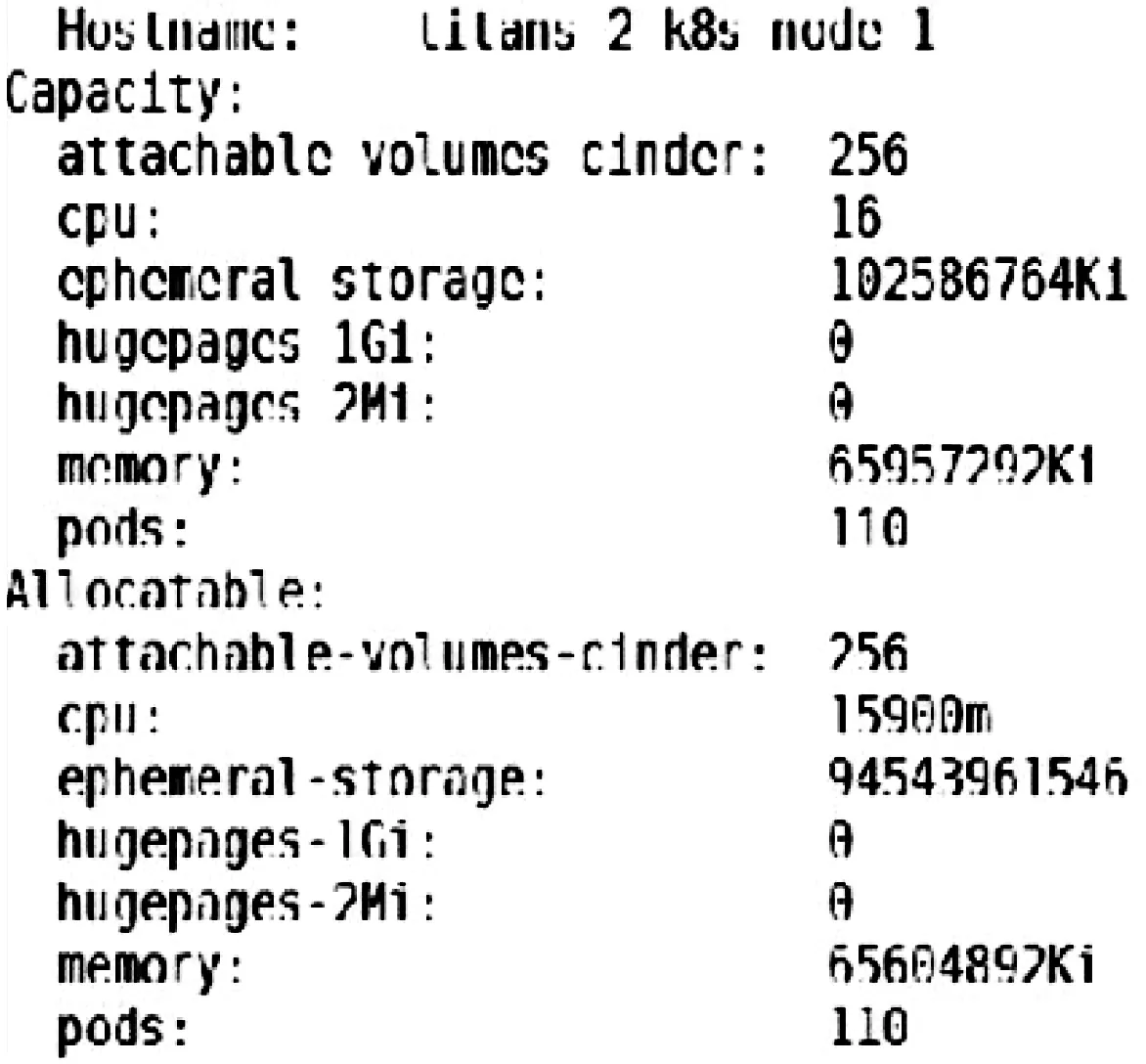
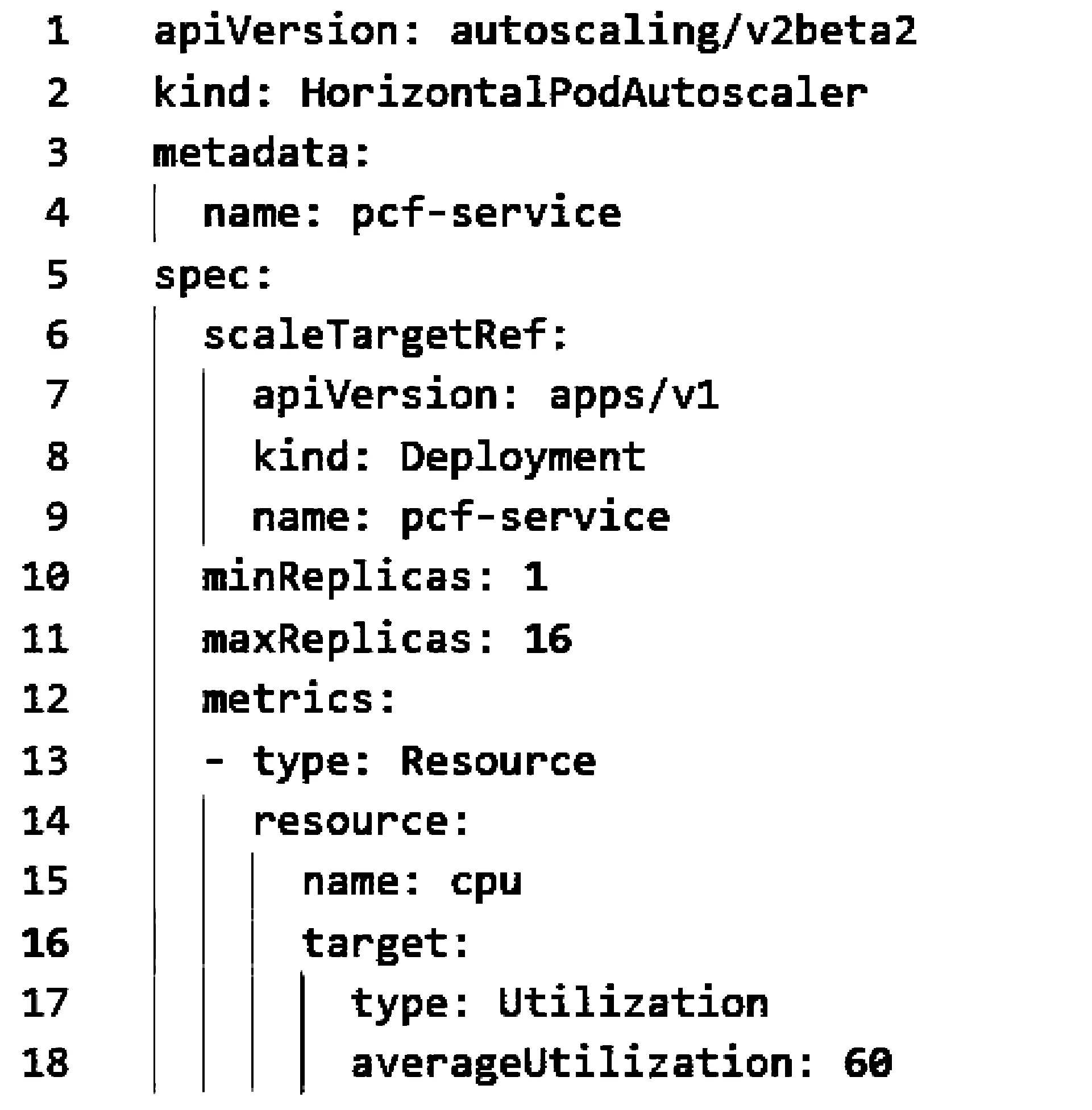
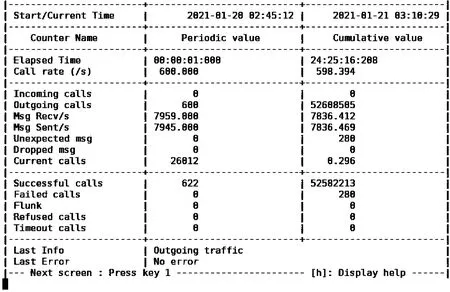
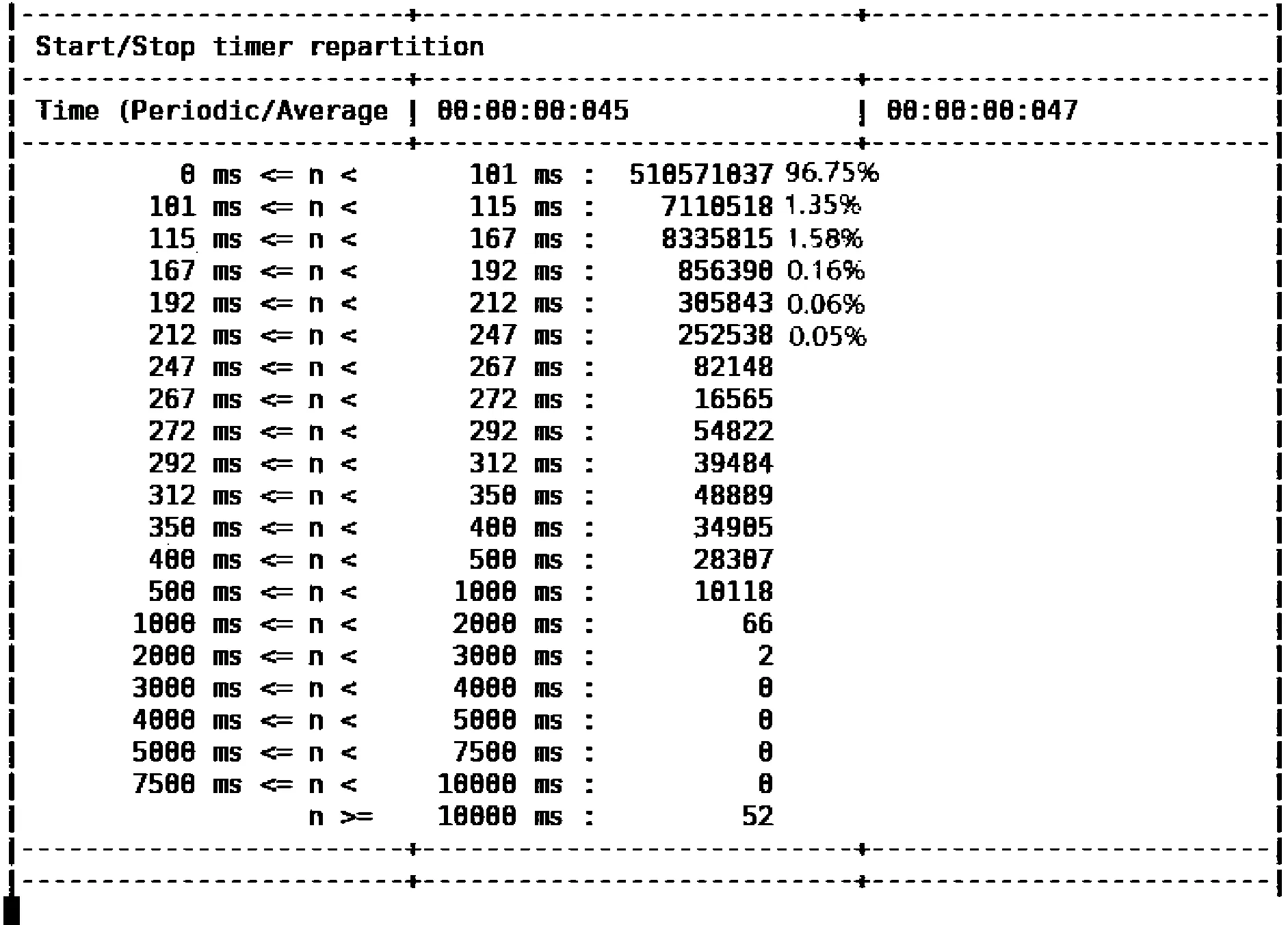
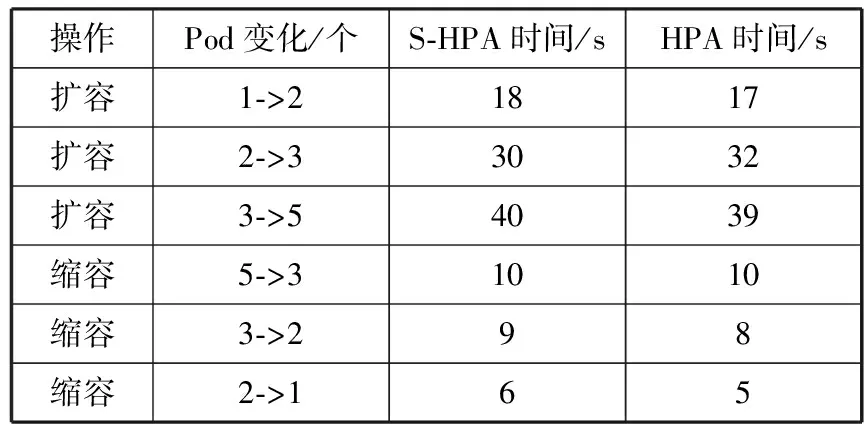
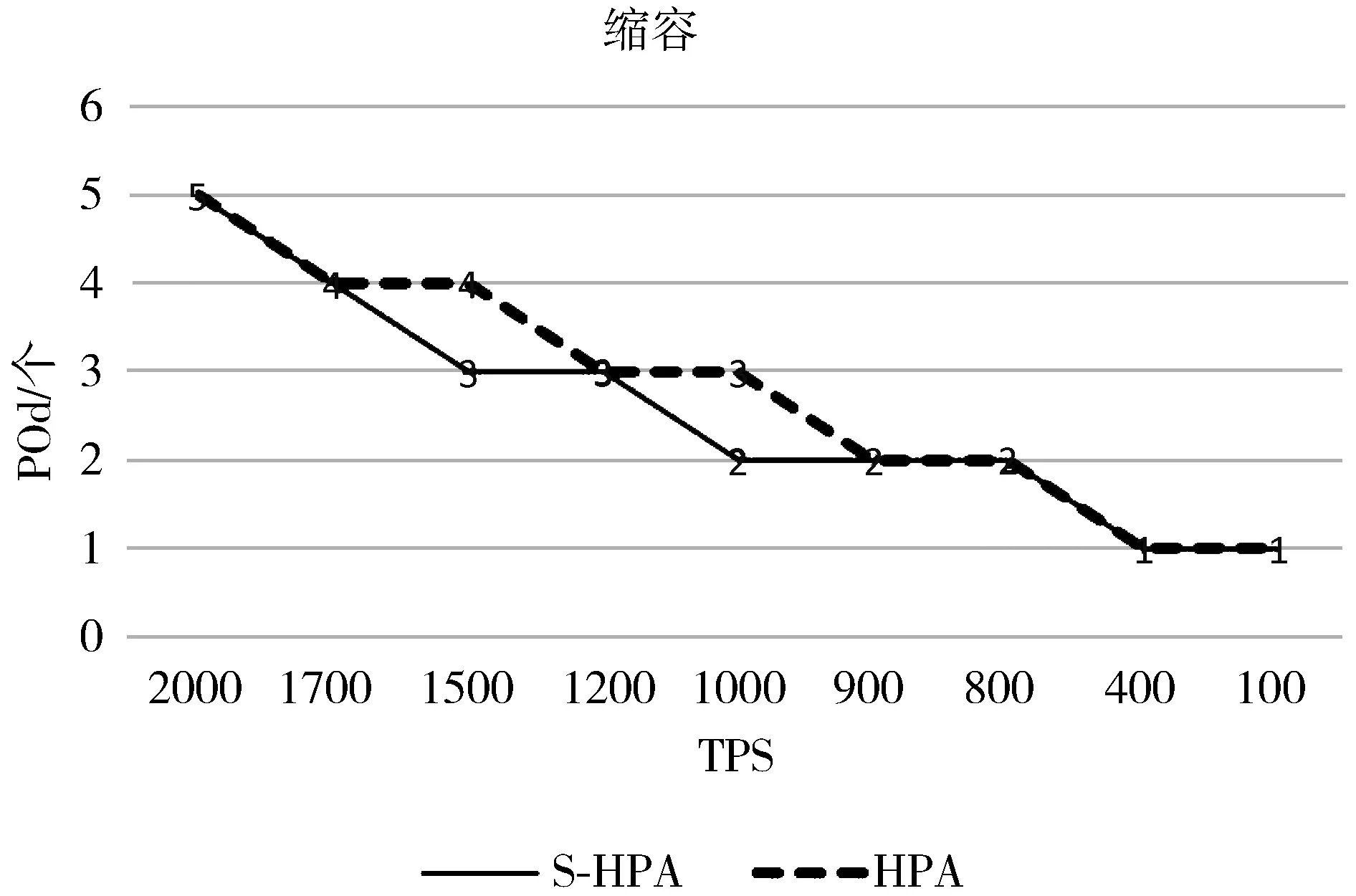
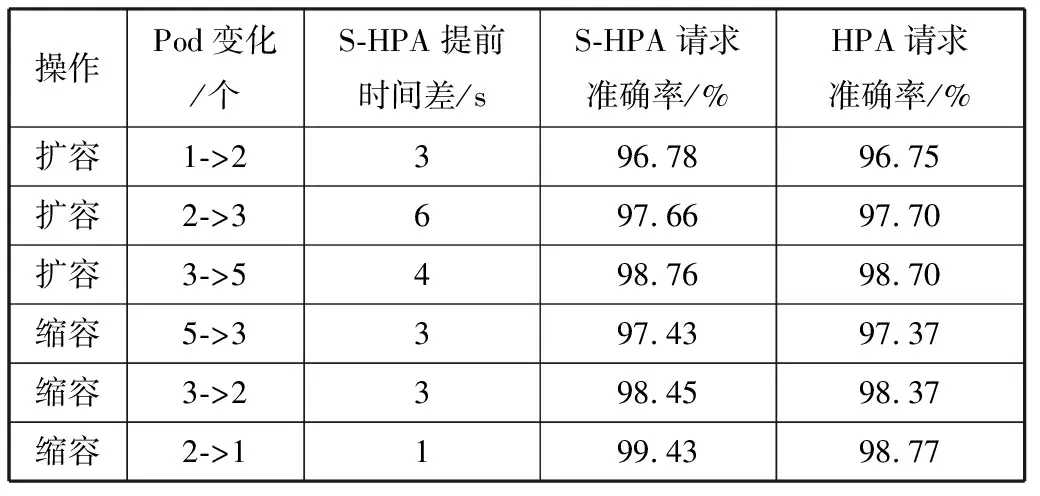
3.ifLi 4.triggerScaleIn /*触发缩容*/ 5.else 6.if(countRate()>percent) /*减少变化比较*/ 7.number++ 8.if(number>=5) 9.triggerScaleIn /*触发缩容*/ 10.end while 3.5.1 实验配置 本文的扩缩容实验环境为Linux平台,Kubernetes集群为3个master节点、10个worker节点,每个节点为16核CPU,64 GB内存,每个Pod的内存为1 GB,1个CPU。集群信息如图14所示,其节点配置信息如图15所示。 图14 集群信息 图15 某节点配置信息 3.5.2 实验准备 1)基准HPA配置准备。 为了验证本文动态伸缩S-HPA的准确性,不仅要统计S-HPA的相关实验数据,还要统计基于Kubernetes的HPA的实验数据,通过统计和分析这2种方法在相同负载数据下的表现,来验证S-HPA的可行性和正确性。 为此设置了一个节点,使用Kubernetes自带的基于Metrics Server的HPA,这是目前广泛使用的一种HPA,如图16所示,伸缩范围是从1个Pod~16个Pod,指标是CPU的平均使用率60%。配置的Yaml文件如图16所示。 图16 基于Kubernetes的HPA配置 以此HPA伸缩数据为基准,并和本文设计的S-HPA使用相同的服务器节点配置,运行相同的应用,使用相同的压测数据,统计Pod随TPS的变化而变化的情况,为后续的比较打下坚实的基础。 2)Pod触发扩缩容的边界条件设置准备。 扩缩容的触发条件根据Pod数的不同,请求数、CPU等条件也会不同,此处以触发单Pod扩容为例详细讲述如何确认和设置扩缩容的边界条件。 为了确认单PCF服务单Pod发生动态扩容的TPS,首先在某个未设置动态伸缩规则,系统不会自动伸缩的服务中,以某个TPS不断发请求,确定CPU使用率达到扩容阈值且应用没有大面积错误返回。从图17不难看出,当TPS为600时,24 h内的错误率为0.005%,错误率极低。从图18可以看出,96.75%的请求在100 ms内返回,运行状况健康。图19中的core服务的CPU使用率维持在60%,到达设置的扩容阈值。可以确认此PCF服务的单个Pod扩容TPS为600。 图17 请求数量统计 图18 响应时间统计 图19 CPU使用率统计 同理可以统计出其他Pod变化的TPS数据。由于在Kubernetes环境中,请求到达PCF服务(Service),服务会进行负载均衡并发送给服务的各个Pod,本文统计的TPS是HTTP消息发送工具发送的TPS,也就是整个PCF服务的TPS,而不是单个Pod的TPS。表3为Pod扩缩容与TPS对应情况。 表3 Pod扩缩容与TPS对应表 3.5.3 实验方法和过程 为了统计2种HPA方法在不同请求数条件下触发扩缩容的触发时间、系统资源等使用情况,为后续比较论证提供数据支持,设置了2个相同的节点,2个节点中的服务具有相同的配置,包括内存、CPU等信息,只是动态伸缩的方法不一样,一个是基于本文的提前感知的动态伸缩S-HPA,另一个是基于Kubernetes自带的HPA。以相同的TPS向2个服务同时发送相同的HTTP Post请求,并统计它们的伸缩消耗时间和伸缩的时间差以及服务请求的准确性,以此来验证本文的动态伸缩是提前感知的、不影响业务的顺滑的动态伸缩。 下面以单个Pod扩容为2个Pod为例介绍具体的实验方法。 1)触发动态扩容。 因为有了大量充分的实验准备工作,从上面的实验准备表3中可以看出,单个Pod扩容条件为TPS达到600,为此使用jmeter向PCF服务发送HTTP Post请求,从TPS 100开始,逐渐增加TPS,确认在TPS达到600之前,系统运行一切正常,没有错误,直到600。 2)动态扩容及数据统计。 TPS达到扩容条件后,观察S-HPA的运行情况,统计S-HPA中节点的运行情况,收集运行过程中的CPU、内存、系统交易量等数据信息,以及Pod的数量、Pod变化的开始和结束时间。 3)数据验证。 分析应用的系统日志以及Pod的日志文件,分析Pod的数量变化以及系统当前负载的具体情况。统计出S-HPA的扩缩容数据以及系统请求准确率情况。 比较S-HPA的数据与基于Kubernetes的HPA的扩缩容统计数据,主要比较两者在伸缩过程中的请求准确率情况以及伸缩的时间差,从而来验证本文设计的S-HPA比HPA具有提前感知、平滑、不影响具体业务操作的特性。 4)多次实验。 为了验证数据的准确性,防止单次实验的数据偏差,需要进行多次实验,统计分析每次实验的相关数据,确保每次实验的数据不存在大的偏差。如果存在大偏差,分析是LSTM预测的原因还是算法的原因,并进行相应的调整。本文的实验数据就是经过多次算法和方法调整及测试之后得到的数据。 3.5.4 实验数据验证 图20、图21中的数据均由实验数据统计而来。表4中S-HPA为本文提出的提前感知的平滑的HPA,HPA为基于Kubernetes CPU统计指标的HPA。 表4 扩缩容平均时间统计 图20 扩容Pod随TPS变化图 从图20不难看出,开始的Pod个数一样,最终的个数也一样,都是5个,但是在扩容的过程中S-HPA比HPA提前预知需要扩容,并进行了扩容。图21中的缩容也是如此,S-HPA提前感知并进行了缩容。 图21 缩容Pod随TPS变化图 从表4不难看出,S-HPA与HPA的扩缩容时间几乎一致,不存在明显差异,这是由于扩缩容动作都由Kubernetes本身完成。 从图20和图21可以看出扩缩容的Pod变化快慢,S-HPA提前于HPA,从表5可更清晰地看出Pod的两者变化的时间差和请求准确率统计。 从表5不难看出,S-HPA不管在扩容还是缩容阶段,都会提前于HPA感知到系统负载的变化并作出相应的反应。而两者的准确率相差几乎可以忽略,因此,S-HPA不会对现有的业务逻辑有任何不良的影响。 表5 扩缩容时间差与请求准确率统计 3.5.5 实验总结 本文实验的比较对象是Kubernetes自身的HPA与本文设计的S-HPA。本文的一位作者正在从事云原生5G核心网的开发和应用工作,另外,5G标准仍在不断改进中,云原生的5G开发整体还处于初始阶段,很多网络运行商都还没有大规模商用。就目前而言,国内外云原生的弹性伸缩在实际应用中多是使用了Kubernetes自带的HPA来进行弹性伸缩,所以本文实验将Kubernetes的HPA作为了比较对象,来验证本文设计的S-HPA的正确性和可用性。 经过多次实验并通过统计分析实验的数据结果可以看出,本文所研究云原生有提前感知的、顺滑的弹性伸缩S-HPA,比普通的HPA具有提前感知的特性,并实时进行伸缩,并且是顺滑的,不会影响系统的业务处理逻辑。因此,通过云原生5G网元PCF的实验,可以将此方法推广到整个5G核心网中,乃至其他的基于Kubernetes的云原生的应用当中去。 云原生应用越来越广泛,云原生应用的益处很多,但是也有一些限制,例如,如何更好地利用基于Kubernetes的云原生应用的弹性伸缩特性来服务云原生应用的研发和管理工作。由于5G核心网的服务化特性,适合开发云原生应用,加上5G应用领域的特殊性,例如自动驾驶等,要求核心网能够平稳运行,不能发生服务的中断或者剧烈抖动。如果发生中断或者抖动,影响巨大,为此本文选取具有云原生代表性的5G核心网中的PCF来研究弹性伸缩,从而推广到所有云原生应用。本文的S-HPA伸缩指标负载数据不仅考虑了CPU、内存等数据,而且加入了系统交易量数据、带宽使用率数据,让负载数据指标更加丰满、准确和多元化,然后利用LSTM来预测未来时间点的负载数据,并设计了一套基于LSTM预测负载数据的行之有效的扩缩容算法来进行实时的伸缩。这样就可以满足5G核心网网元的动态伸缩需求,让5G核心网系统更加健壮和高可用。并通过实验表明本文设计的S-HPA是可行的,不仅适用于5G核心网,而且适用于其他的云原生应用。 针对以基于Kubernetes的云原生5G核心网为例的弹性伸缩,本文进行了一系列的研究和实践。未来的研究将从如下几个方面入手:1)提高预测准确性,进一步优化负载指标以及LSTM的建模,另外还需要增加采样数据量,针对拉依达准则进行数据剔除时提高精准度,减少错误剔除的概率,减少由于预测不准确而导致的伸缩,提高伸缩准确度;2)伸缩算法的进一步优化,例如阈值的设置和扩缩容参数的设置,提高伸缩效率。3.5 弹性伸缩实验和数据验证


4 结束语
猜你喜欢
军事文摘(2021年18期)2021-12-02
军事文摘·科学少年(2021年9期)2021-10-13
家庭影院技术(2020年2期)2020-03-25
铁道通信信号(2019年6期)2019-10-08
制造技术与机床(2019年9期)2019-09-10
模具制造(2019年4期)2019-06-24
西南交通大学学报(2018年6期)2018-12-18
通信电源技术(2018年3期)2018-06-26
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
