
融合注意力与深度因子分解机的时间上下文推荐模型
2021-12-09 06:04刘亦欣王家伟李自力
计算机与现代化 2021年11期
刘亦欣,王家伟,李自力
(重庆交通大学信息科学与工程学院, 重庆 400074)
0 引 言
随着网络信息量的不断增长,信息过载现象越来越严重,推荐系统作为一种信息筛选的方法变得越来越重要。推荐系统可以帮助用户在繁杂的数据中快速发现自己想要的信息,能够针对主流商品对所有用户进行推荐,根据二八原则,八成的交易数据都是由20%的用户产生的,因此80%的用户都没有得到更满意的推荐,所以对所有人使用同一套推荐系统变得不再可行,个性化推荐系统便出现了。近年来,越来越多的电子商务公司利用个性化推荐系统[1]对用户的购买行为进行预测,但大多数方法都忽略了用户与商品交互时的时间上下文信息[2],因为用户的时间上下文信息是动态变化的,所以推荐效果不尽人意,推荐结果的单一化的问题亟待解决。
在众多推荐算法中,基于模型的混合推荐[3-4]是当前应用最广的一种推荐算法,它通过组合后能避免或弥补各自推荐技术的弱点。因子分解机[5](Factorization Machines,FM)主要是解决稀疏数据集下的特征组合问题,对连续和离散特征有较好的通用性。场感知分解机[6](Field-aware Factorization Machine,FFM)通过引入场(field)的概念,FFM把相同性质的特征归于同一个场。这样每一维特征都会针对其他特征的每个场,分别学习到一个隐变量,该隐变量不仅与特征相关,也与场相关。深度因子分解机[7](Deep Factorization Machines,DeepFM)通过加入多层神经网络,解决了FM只用到了特征的二阶组合的缺陷,使用多层神经网络对由输入的一阶特征进行全连接等操作形成的高阶特征进行特征的提取,达到了更好的推荐效果。
尽管混合推荐算法取得了巨大的成功,但传统的推荐系统忽视了用户的偏好是随时间而变化的。在这种情况下,用户在特定时间点的意图很容易被他或她的历史购物行为所淹没,从而导致不可靠的推荐。本文提出一种基于时间上下文,并融合注意力机制和深度因子分解机算法来建立推荐模型。
1 相关工作
个性化推荐算法经过了20多年的发展,从传统的协同过滤、基于内容的推荐和混合推荐发展出了上下文感知推荐系统、动态推荐系统、标签感知推荐系统等新式推荐系统。以上推荐系统都有着一个共同的特点,就是加入了额外的数据和信息对传统的推荐系统进行补充,对不同的数据采用不同的建模方法与预测方法,从而提高推荐效果。窦羚源等人[8]通过标签信息来构造用户和资源的特征矩阵,进一步融合到基于邻域的协同过滤推荐算法中,预测用户对资源的评分。黄文明等人[9]使用词嵌入模型表达数据集评论中的语义,引入注意力机制对输入内容进行重新赋权,通过并行的卷积神经网络挖掘用户和项目评论数据中的隐含特征,将2组特征耦合输入并采用因子分解机进行评分预测。但是该模型只是将注意力机制用在了评论文本的识别,并没有用在时间上下文的处理上面。郁豹等人[10]使用DeepFM模型来实现社交广告的个性化推荐,其中因子分解机部分主要是提取一阶二阶特征,深度神经网络部分主要是提取高阶特征,实验表明了DeepFM相比逻辑回归模型和因子分解机效果都更好。黎丹雨[11]利用Word2Vec算法对电影简介信息进行处理后,使用卷积矩阵分解ConvMF算法得到对电影的预测评分矩阵,再使用AFINN得到电影评论情感倾向特征,接着考虑到导演和演员的信息对电影评分的影响,利用KNN算法对其进行建模处理,然后使用协同过滤得到用户-电影评分矩阵,最后对这4种因素进行加权融合得到最后的推荐模型。谢浩然等人[12]使用改进后的TF-IDF算法对用户评论信息进行建模,再利用协同过滤算法对新型广播电视节目进行推荐。吴韦俊等人[13]提出了一种基于交叉网络的因子分解机模型,降低模型复杂度,提高模型泛化性能,但是该模型只是将FM的思想融合进入了神经网络,也就是DeepFM的串行表达方式。崔鑫[14]对用户和问题的元路径计算其相似度,再使用协同过滤算法计算用户-问题评分矩阵,最后分别对其进行融合并实验,进而实现了异构信息网络的推荐系统。汤小月等人[15]提出了一个概率生成模型JUMBM(Joint User Mention Behavior Model)来发掘语义和空间上下文因素对用户提及行为的联合影响,解决社交媒体中的目标用户推荐问题。陈劲松等人[16]利用LDA主题模型挖掘用户和POI的潜在语义特征,提出了一种基于多维上下文感知的图嵌入模型的移动推荐方法,该算法重新定义图中顶点的关联规则,提升了模型在数据稀疏情况下的推荐性能。
Hidasi等人[17]采用RNN中的GRU单元作为基本结构,组建了一个深层的神经网络来预测该session下一个点击的item的概率。使用多层GRU算法,得到的隐状态向量通过一个前馈层预测对商品的得分。Liu等人[18]提出了适用于跨域推荐的可迁移上下文强盗(TCB)策略算法,迁移学习改善了对上下文强盗策略的利用,并加速了其在目标领域的探索。Bendada等人[19]将轮播个性化建模为具有多个播放、基于级联的更新和延迟批处理反馈的上下文多臂赌博机问题,并利用其算法实现了音乐的个性化推荐系统。Ma等人[20]利用带有元数据的分层递归网络(HRNN-meta)对事件的时间上下文信息和冷启动用户上下文信息以及有关项目的元数据信息进行整合与训练,以满足实时和多样化的元数据需求。Hansen等人[21]利用最近的消费和会话级别的上下文变量信息,提出了CoSeRNN算法,通过使用近似最近邻居搜索算法,将此优先级向量用于下游任务,生成上下文相关的即时推荐。Wu等人[22]不同于以前将会话看成一个序列,而是将会话序列建模为图结构数据,使用GNN去捕获项目的复杂转换;然后,使用注意力网络将每个会话表示为该会话的全局偏好和当前兴趣的组成。Santana等人[23]提出了基于上下文“元强盗”的推荐算法,这是一项针对选项的策略,其中每个选项都映射到一个经过预先培训的独立推荐系统。该算法在线学习并根据情况选择推荐者,以适应情况。Jarv[24]使用稀疏的训练数据来限制其性能,发现基于会话的k最近邻在比较中受到的限制最少,并且在所有分析的数据集中都有改进的空间。He等人[25]提出了一种上下文组合强盗方法,称为UBM-LinUCB,采用用户浏览模型(UBM)来解决与推荐位置相关的问题。
基于以上研究,同时为了考虑时间上下文信息,并进行有效的融合,本文提出一种融合Attention与DeepFM的时间上下文推荐模型(DeepAFM),将用户与商品交互时间通过注意力机制的方法融合到DeepFM模型中。实验结果表明,该推荐算法相对于DeepFM算法,能有效地预测用户是否对商品进行购买,提高了推荐的精度。
2 DeepAFM模型
本文基于DeepFM提出一种融合注意力机制对时间上下文深度建模的推荐方法,整体模型结构如图1所示。本文的工作主要包括以下2点:
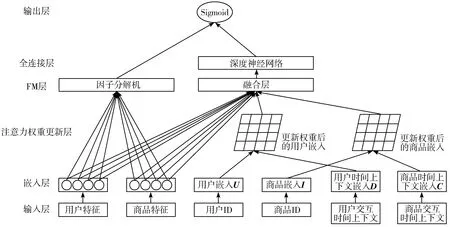
图1 DeepAFM模型结构
1)时间上下文深度建模。将用户与商品的交互时间通过Embedding的方法嵌入,实现推荐系统对时间上下文数据的充分利用。
2)引入注意力机制。将注意力机制引入到DNN中,提升对重点商品的关注,实现对时间上下文数据更准确的建模。
2.1 时间上下文深度建模
为了更好地训练模型,对用户u和商品i定义独热码表示向量,由于表示为独热码后,数据极其稀疏,所以将它们分别预处理为嵌入式向量U和I,使得数据更为稠密,更加利于模型进行计算。
除了嵌入了用户和商品的向量之外,嵌入层对时间上下文数据进行了嵌入,考虑了用户与项目时间上下文向量的交互、商品与用户时间上下文向量的交互。DeepAFM根据时间t中观察到的u和i的交互作用,如果用户和商品在时间t有交互,便组合交互作用向量D和C。
2.2 注意力机制
注意力机制被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,其本质为根据另一组输入向量对本向量进行加权。
DeepAFM的交互向量D和C分别被视为与用户u的时间动态du和项目i的ci关联的另一组潜在因子。用户u在不同的时间t与项目i互动,定义为:
(1)
(2)
其中,ci是根据fi隐向量计算出来的商品时间上下文嵌入,du是根据gu隐向量计算出来的用户时间上下文嵌入。用于不同商品可能会干扰不同用户的偏好,不同用户对不同商品的偏好也不同。DeepAFM使用注意力机制对商品与用户交互重写为:
mi=tanh(Wjfi+ba)
(3)
(4)
(5)
其中,Wj表示权重矩阵,ba表示偏移量,ha是时间上下文向量,mi表示由嵌入层训练的fi的潜在表示。αi表示项目i在时间t时刻与用户u交互的重要程度,即为项目i经过注意力机制权重更新后的得分,它通过softmax函数计算mi和时间上下文向量ha之间的相似度。同样地,将用户与商品交互重写为:
nu=tanh(Wjfu+ba)
(6)
(7)
(8)
其中,nu表示由嵌入层训练的fu的潜在表示;αu表示用户u在时间t时刻与商品i交互的重要程度,即为用户u经过注意力机制权重更新后的得分,它通过softmax函数计算nu和时间上下文向量ha之间的相似度。
2.3 因子分解机
在DeepAFM中,因子分解机主要是解决稀疏数据下的特征组合问题,对连续和离散特征有较好的通用性。在只考虑二阶交叉时,具体模型如下:
(9)
其中,n为用户和商品的特征数量,xi是第i个特征的值,w0、wi、wij是模型参数,这里要注意,若xi和xj中有一个为0,则交叉无意义。由于稀疏数据集中满足交叉项w0不为0的样本会很少,导致训练不够充分而影响模型参数的准确性。那么,交叉项参数的训练问题可以用矩阵分解来近似解决,有下面的公式:
(10)
模型需要估计的参数即是:
w0∈,w∈n,V∈n×k
(11)
其中,〈·,·〉表示2个k维向量的内积:
(12)
3 实验及结果分析
本章首先介绍实验环境和所用数据集,然后对评价指标进行说明,最后给出DeepAFM模型与其他方法的对比实验结果,并对实验结果进行相应的分析。
3.1 实验环境
本文的实验环境为:操作系统为Windows 10;处理器为Intel i7-9700,8个CPU核心;内存为32 GB;实验平台:Visual Studio Code,Python 3.7.3,TensorFlow 2.0。
3.2 实验数据集
本文采用真实的公开数据集,使用Yelp(https://www.yelp.com/dataset)数据集,这是美国点评网站Yelp公司开源的真实数据集,通常用于推荐系统研究的经典数据集。
本实验选取了由24146个用户提交了14696个商户的232118条点评数据,由Yelp数据集中的yelp_oh_review表得到。时间跨度是2010年1月—2018年11月。
表1为交互数据集,将用户在商店的消费记录作为正样本,然后对用户没有消费过的商店作为负样本,随机生成和正样本一样的数据,最后正负样本比例为1∶1。实验任务为预测用户是否会在当前商店进行消费。实验过程中,将原始数据进行拆分,其中,80%作为训练集,20%作为测试集,得到训练集和测试集。
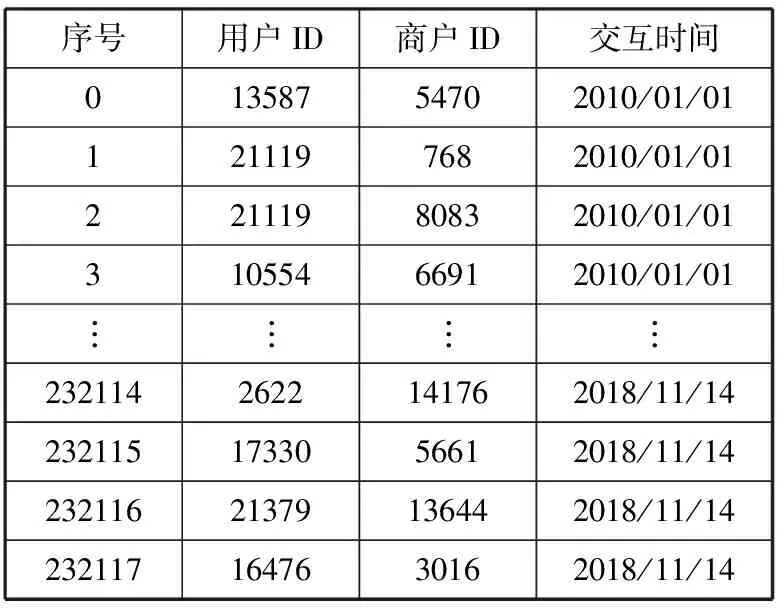
表1 用户-商户交互数据
3.3 评价指标
本实验使用了分类模型常用的评价指标,包括交叉熵损失(Cross Entropy Loss)、AUC(Area Under Curve)和F1分数(F1-Score)。对于交叉熵损失,评价的是训练数据的目标分布p与测试数据的预测分布q之间的相似程度,如公式(13)所示,其中,p表示目标分布为0的概率,q表示预测分布为0的概率。
H(p,q)=-(plogq+(1-p)log(1-q))
(13)
对于AUC,评价的是预测为正的概率值比预测为负的概率值还要大的可能性,它的本质是ROC曲线下面积。计算方法是首先将测试集样本按照预测出来为1的概率降序排列,然后将实际为正样本的排序值rank和正样本预测概率p1进行计算,再除以正样本预测概率p1与负样本预测概率p0的乘积。具体计算方法如公式(14):
(14)
对于F1分数,评价的是精确率(precision)和召回率(recall)的调和平均数,它是根据混淆矩阵来计算的,混淆矩阵如表2所示。
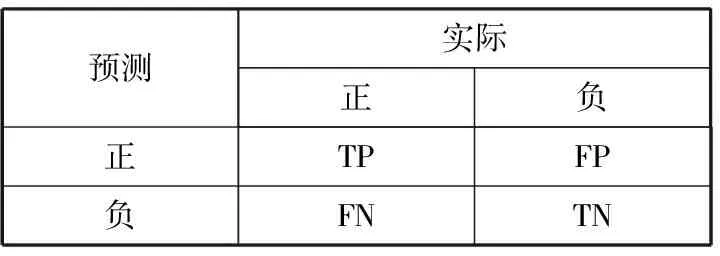
表2 混淆矩阵
于是F1分数的计算公式如公式(15):
(15)
其中,P为精准率,计算公式见式(16)。R为召回率,计算公式见式(17)。
(16)
(17)
3.4 实验对比分析
实验选用传统的因子分解机算法(FM)和深度因子分解机算法(DeepFM)进行对比分析。
实验中,参数设置都是统一的,都采用Adam算法作为优化器,自动调整学习率,隐向量长度均设置为16,batch size设置为128。表3展示了不同评价标准下的实验结果,其中,Epoch表示迭代次数,表中粗体表示最佳效果。
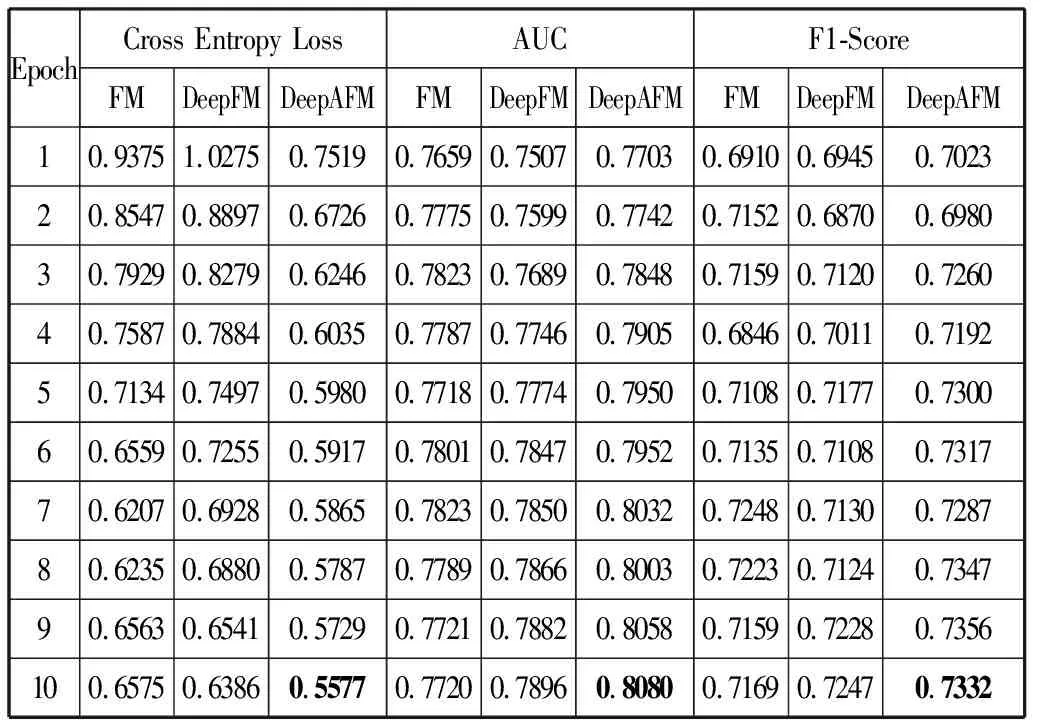
表3 不同评价标准下的实验结果
从图2可以明显看出,在交叉熵损失评价标准下,DeepAFM相较于其他2个算法有着明显的提升,而DeepFM由于过拟合的原因,效果开始还不如FM好,由于加入了时间上下文数据,DeepAFM很好地抑制了过拟合的问题。
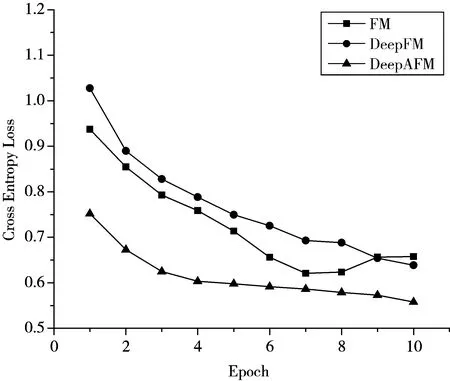
图2 不同迭代次数下交叉熵损失的变化
从图3可以看出,在AUC的评价标准下,FM表现平平,由于模型过于简单,所以拟合程度不够,有轻微的欠拟合,在训练次数增加的情况下,AUC上升困难。而DeepAFM相较于DeepFM,有着很大的提升,最后AUC的得分为0.808。相较于DeepFM的0.7896,提升了0.0184。
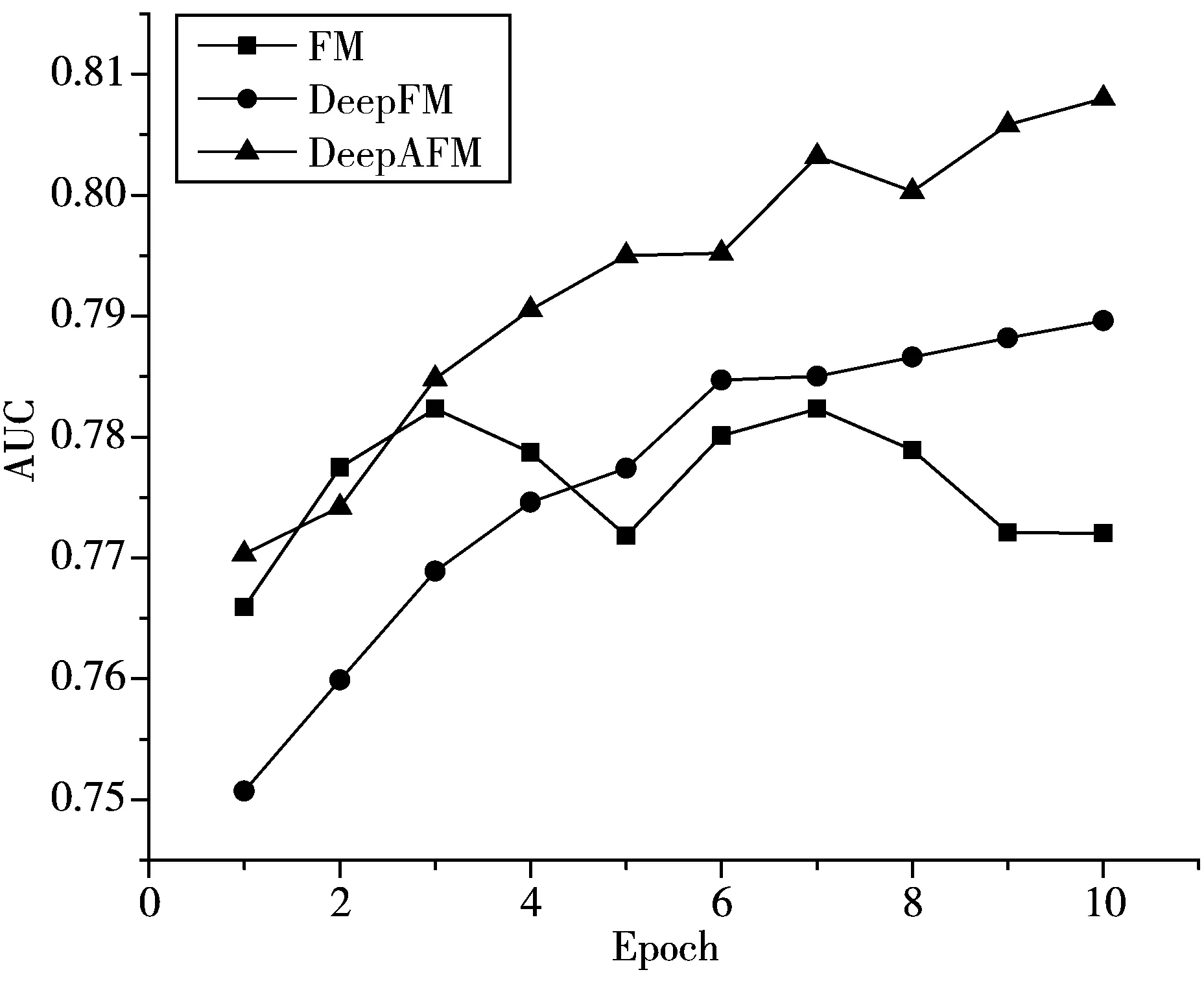
图3 不同迭代次数下AUC的变化
图4展示了不同迭代次数下F1-Score的变化,可以看出,3个模型的抖动都比较大,尤其是FM模型,不够稳定,而DeepAFM在训练几轮后趋于稳定,且相比于DeepFM效果更好。
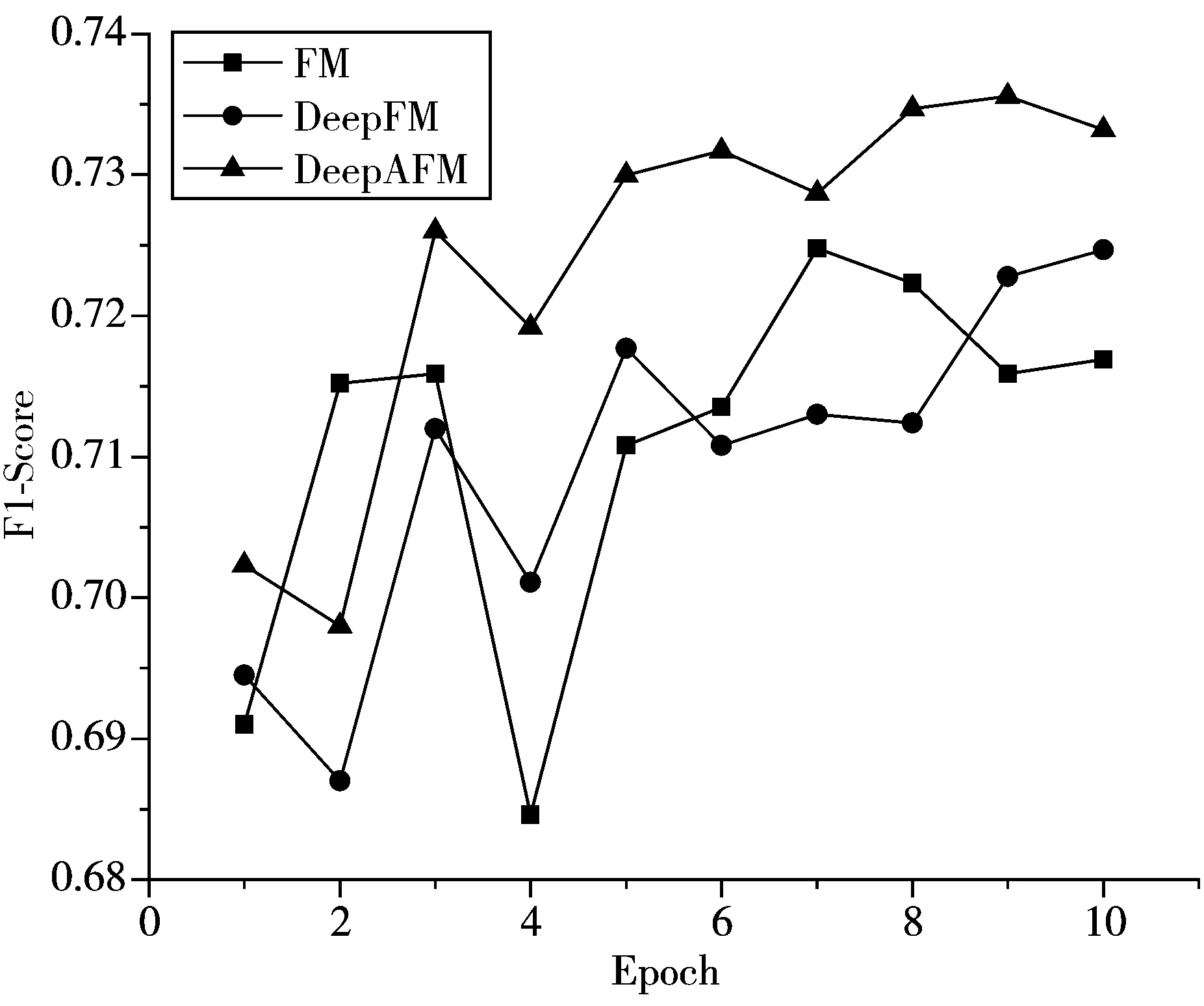
图4 不同迭代次数下F1-Score的变化
4 结束语
针对传统推荐系统无法对商品的购买时间进行学习的问题,本文提出了一种融合Attention与DeepFM的时间上下文推荐模型。本文方法的关键是引入了注意力权重更新层,该层对每个商品与其对应交互时间通过学习确定相关性。在Yelp数据集上的实验结果表明了本文提出的模型的有效性,同时也表明了该模型能有效防止过拟合。在未来的研究计划中,希望能找到更多影响用户偏好的信息,例如由于用户和用户观点的描述更广泛,因此可以将商品评论作为更丰富的上下文信息,来设计更加智能的推荐系统。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
