
基于同等注意力图网络的视觉问答方法
2021-12-09 06:04王天星袁家斌
计算机与现代化 2021年11期
王天星,袁家斌,2,刘 昕
(1.南京航空航天大学计算机科学与技术学院,江苏 南京 211106;2.南京航空航天大学信息化处(信息化技术中心),江苏 南京 211106)
0 引 言
随着人工智能相关的应用逐渐走进人们的日常生活,智能系统通过不断观察人与人、人与物体、人与环境以及人与AI之间的交互来获得越来越多样化的信息。当人们致力于开发大规模、高水平且适应性强的智能系统时,能够有效利用这些信息将变得越来越关键。而视觉与语言是人类获取现实世界信息的2大核心元素,也是人工智能研究的重点。因此两者相结合的跨模态任务——视觉问答(Visual Question Answering,VQA)被认为是实现人工智能最高的目标之一。VQA是一种涉及计算机视觉和自然语言处理的综合性学习任务,要求图像与自然语言的联合理解,即场景理解与语义理解,其目标是让模型自动回答有关视觉内容的问题。如今随着计算机视觉与自然语言处理2大领域的快速发展,视觉问答已经成为了近几年最热门和活跃的研究方向之一[1-4]。具体来说,根据给定的图像和关于图像的开放式的自然语言问题,VQA系统需要分析并生成对应的自然语言答案作为输出。在现实应用方面,VQA也有着巨大的潜力,如聊天机器人、视障人群的生活助手以及儿童早教产品等。因此,开发出接近人类水平的VQA系统是实现人工智能的重要一步,并将大大促进人机交互的发展。
当前大部分VQA方法利用预训练的CNN模型提取图像特征,再结合注意力机制进行问题解答。尽管这些方法证明了它们的价值,但它们没有去关注如何建模场景目标间的交互关系,因此在大规模交互的关系推理中面临着挑战。而应对这个问题的一个很好的方法是利用场景图结构[5],它能捕捉到目标之间重要的语义关系,更好地理解图像。场景图概括了图像的内容,由一定数量的节点及关系边组成,可以此构建图网络。其中,节点代表着图像中的目标对象,而节点之间的边决定了它们的交互关系表示。
首先提出在VQA领域使用图结构的是Teney等人[6],它利用图网络结合问题的依存解析和抽象图像的场景图表示。它的出现表明了利用图网络的VQA方法的巨大潜力。但是该方法在开始就将关系边特征与节点特征融合,没有考虑到关系在解答问题中的作用。之后使用图网络的方法有的在节点注意力的基础上辅以关系注意力,问题解答的落点在节点上,如Haurilet等人[7]提出的模型和Shi等人[8]提出的XNM模型;有的先对节点应用图注意力机制再生成关系边,并进一步应用注意力机制在关系边上,如于东飞[9]提出的VQA-GAT模型。但根据图像提出的问题是未知的,并不只有与物体对象相关的如属性等问题,也可以询问对象间的关系如动作、空间位置等问题。问题解答不应该只聚焦在对象或关系上,而应该两者相结合。上述的这些方法或多或少在过程中流失了部分信息,使答案预测的依据不够充分。本文提出基于同等注意力图网络的视觉问答模型EAGN,充分利用场景图中的目标对象及其关系表示。与这些方法忽略关系边与问题间关联的重要性不同,EAGN不局限于关注节点与问题之间的关联,也同样关注与问题最相关的关系表示,并让其参与到最终答案的生成。EAGN模型的处理过程如图1所示。由图1可以看出,首先将输入的图像转换成场景图表示,对问题进行编码,再送入模型执行。之后具体的执行过程主要由同等注意力模块、图特征融合模块以及最后的答案生成部分组成。最后分别在GQA与VQA2.0这2个数据集上进行实验,表明了EAGN模型的有效性,展示了其有竞争力的性能。
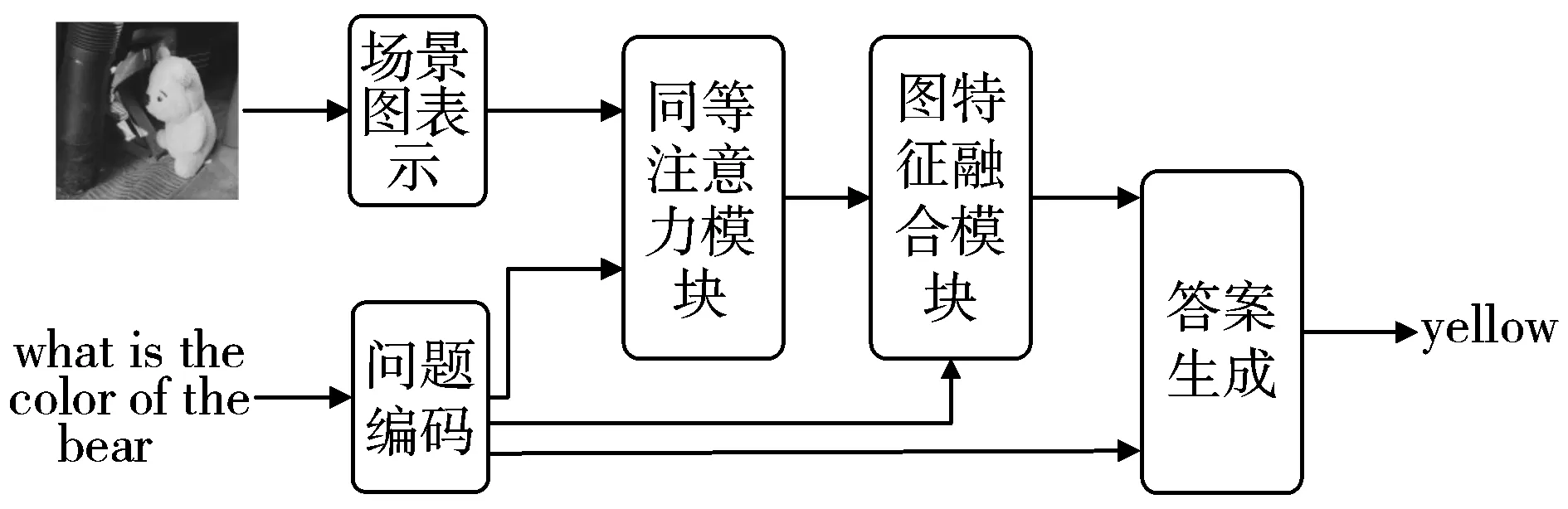
图1 EAGN模型的处理过程
1 方 法
1.1 总体框架
简单来说,本文方法的流程就是在图像内容上构建由目标节点和目标间关系边组成的场景图结构,并以此建立在图结构上进行问题解答的视觉问答模型。场景图来源于原本的图像,但并不是所有图中的元素都与问题有关。所以模型使用多个注意力层来迭代每个节点及其关系边表示,这样得出场景图与问题之间的对应关系。具体来说,模型通过同等注意力机制赋予关系边与目标节点同等的重要性,充分利用图结构中所有元素。最终对应的节点和关系边与问题一起用于推断答案。EAGN模型设计的具体结构如图2所示。

图2 EAGN模型的具体结构图
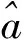

(1)

1.2 输入特征表示
1.2.1 场景图表示
为了在VQA任务中使用图网络,要将输入图像转换成场景图表示。本文将图像I代表的场景图G定义如下:
G=(V,E)
(2)
V={v1,…,vN}
(3)
E={eij∈D|i,j=1,…,N}
(4)
其中,V表示图像中N个目标对象代表的节点的集合,vi∈m表示第i(i=1,…,N)个目标对象的m维节点特征表示向量;E表示N个目标对象之间的关系对应的关系边集合,eij表示对象i到对象j的D维关系特征表示向量。为了计算方便,将节点特征与关系边特征映射到同一维度的特征空间,如公式(5)、公式(6):
vi=W1vi+b1
(5)
eij=W2eij+b2
(6)
其中,W1∈h×m和W2∈h×D是权重参数矩阵,b1和b2是偏置项。这样得到了新的节点特征vi∈h和关系边特征eij∈h。
由于所用的数据集没有提供测试集的场景图标注信息,而与相对成熟的目标检测技术相比,现实世界图像的场景图生成仍然是正在研究的课题,想要获得质量良好的场景图是困难的。所以本文的场景图的表示有2种形式。第1种形式使用数据集提供的包含标签的真实场景图的标注信息。具体地,将对象标签的嵌入作为节点特征,关系标签嵌入作为关系边特征。在这样的设定下,对象标签和关系标签所使用的词汇被限定了范围。先收集所有的标签,将其保存为字典形式,再使用一个嵌入矩阵O∈C×d将标签映射成d维的向量,其中C表示标签的个数。最终用对应的标签嵌入的拼接来分别表示节点特征vi和关系边特征eij。第2种形式就是利用预训练的Faster R-CNN模型[10]提取的区域目标特征作为节点特征,节点特征之间的融合作为关系边特征。
1.2.2 问题表示
除了对图像进行预处理之外,问题文本也要处理成模型可以接收的形式。首先将问题中所有单词都转换成小写,并且删去如句号、问号等不影响问题本意的符号。然后将问题Q进行分词,接着将这些单词进行词嵌入处理。词嵌入是一种将文本中的词转换成实数向量的方法,可以方便用于计算。处理后的问题嵌入表示为:
Qemb={w1,…,wt}
(7)
其中,t为问题Q包含的单词个数,wr(r=1,…,t)即为对应单词的词嵌入。本文使用预训练的GloVe[11]向量初始化词嵌入。GloVe(Global Vectors of Word Representation)是一个基于全局词频统计的词表征工具,它能有效利用全局语料库统计数据,使各个词向量之间能够尽可能多地包含语境内的语义和语法信息。接着将处理好的问题嵌入Qemb送入GRU[12]进行编码,这里使用双向GRU,如下所示:
[h1,…,ht]=BiGRU(Qemb)
(8)
q=[h1;ht]
(9)
1.3 具体设计与实现
接收了输入的场景图表示和问题表示之后,由于不是场景图中所有的元素都与问题有关,为了更准确地锁定目标,模型在图上应用同等注意力机制,分别找出对解答问题关键的节点与边。首先将节点注意力权重向量表示为a∈[0,1]N,其中第i个节点的权重为ai。计算过程如下,为简洁起见,省略了偏置项:
τ1=relu(W3V)⊙relu(W4q)
(10)
a=softmax(τ1)
(11)
其中,⊙表示对应元素相乘,W3和W4是权重参数矩阵,relu为线性整流函数,下文若重复出现将不再赘述。这样得到了节点注意力权重a。接着更新应用了注意力机制之后的节点特征v′i:
v′i=aivi
(12)
V′={v′i|i=1,…,N}
(13)
除了节点注意力之外,同样要对关系边施加注意力层,因为关系对于问题的解答一样重要。接着将边注意力权重矩阵表示为W∈[0,1]N×N,其中Wij代表了节点i到节点j的边权重。为了捕捉节点间的交互关系,找到与问题相关的关系边,使用如下公式计算出边注意力权重:
τ2=relu(W5E)⊙relu(W6q)
(14)
W=softmax(τ2)
(15)
然后同样更新关系边特征e′ij:
e′ij=Wijeij
(16)
E′={e′ij|i,j=1,…,N}
(17)
作为图结构的组成部分,目标对象的节点与对象间的关系边对答案预测同样重要。为了与问题特征q共同推断答案,需要将节点特征与关系边特征进行融合。首先通过收集整合节点周边与它关联的上下文信息获得与此节点相关的关系信息:
ni=e′i,:⊙V′
(18)
其中,e′i,:表示节点i与其他节点间的关系边特征,ni表示得到的节点i的上下文信息,包含了与自身节点有关联的关系边和节点的信息。接着将节点特征与上下文特征融合,整合成完整的图特征:
xi=W7[v′i;ni]
(19)
其中,[v′i;ni]表示特征拼接操作,xi为得到的图特征。接着对融合后的图特征也应用注意力机制,进一步确定与问题最相关的信息:
a′i=softmax(relu(W8xi)⊙relu(W9q))
(20)
(21)
加权求和之后得到的X′代表了获得注意力权重之后的新图特征,最后用新的图特征X′去预测最终的答案。
与大多数方法一样,本文将VQA视为多标签分类问题。先将图特征X′与问题特征q进行特征融合操作,这里采用了Zhang等人[13]的方法,如下:
Z=relu(W10X′+W11q)-(W10X′-W11q)2
(22)
这样得到了融合后的最终特征Z,并将其送入softmax分类器,得到各个候选答案的概率。模型从中选出概率最大的标签,作为最终预测的答案。
2 实 验
2.1 数据集
2.1.1 GQA
GQA数据集[14]是一个针对真实世界图像的大规模视觉推理数据集,2019年由Stanford大学的Hudson等人所创建。GQA数据集中的图像来自Visual Genome数据集[15],共有超过2000万个问题。GQA的训练集和验证集中每幅图像配有场景图的信息标注,描述了场景里的目标对象的标签和属性,还有目标实体间成对的关系信息。而由于目前场景图生成技术还没有完全成熟,无法达到应用的标准。所以在GQA上的实验分为2种,一种实验的场景图表示使用自带的真实的ground truth场景图标注,另一种则将区域目标特征作为节点特征,节点特征的连接作为边特征。
2.1.2 VQA2.0
VQA2.0是Virginia Tech大学Goyal等人[16]于2017年发布的自然图像的基准数据集,也是使用最广泛的数据集。VQA2.0总共包含1105904个问题和约204721幅图像。数据集的现实世界图像来自另一数据集MS COCO(Microsoft Common Objects in Context)[17],这是一个大规模的图像标注数据集。VQA2.0中每一幅图像平均对应3个问题,每一个问题提供10个人工标注员给出的答案。VQA2.0考虑到了评估标准的鲁棒性,提出了如下公式计算准确率:
Acc(ans)=min(na/3,1)
(23)
其中na表示与预测答案ans相同的人工标注答案的个数。具体来说,如果至少3个人工标注答案和预测的答案一样,这个答案才被认为是100%正确的。
2.2 实验设置
对于第2种实验使用的预训练的Faster R-CNN模型,本文使用和Bottom-Up[18]相同的设置。对输入的图像提取目标特征,得到K个置信度最高的目标区域的特征。这里设置K=36,每个目标区域都由一个2048维的向量表示。为了包含空间信息,本文将目标特征与它关联的边界框坐标信息进行拼接。问题嵌入向量维度设置为300,双向GRU的输出维度为1024。训练时使用Adam优化方法,batch size大小设置为128。在VQA2.0上实验时,本文将训练集和验证集一起用于模型训练。
2.3 实验结果与分析
2.3.1 对比实验的结果与分析
本文提出的EAGN模型围绕着同等注意力的思路将节点注意力与关系边注意力都进行考虑。为了验证其有效性,利用另外2种方式的模型与EAGN进行对比。整体注意力模型表示在输入之后就将图的节点与关系边融合为整体,再进行后续操作;无边注意力模型表示没有对关系边应用注意力机制,其他过程则与EAGN相同。本文在GQA的验证集上进行对比实验,结果如表1所示。

表1 对比实验结果 单位:%
表1中括号内标注为GT的实验表示使用了真实的场景图标注。从表1可以看出,使用了真实的场景图标注比直接使用图像区域特征效果要好很多,表明带有语义信息的场景图标签可以更好地和问题交互,使答案的准确率明显提高。不过从结果来看,即使有所提高,也并没有达到很高的准确率。本文推断一方面是因为数据集自带的场景图标注也不是面面俱到的,如问题“What is the bear looking for?”所对应的图像的标注信息中没有出现“looking for”这个关系的信息。另一方面,由于真实世界图像的复杂性,场景图标注信息可能会包含很多元素,模型在嵌入和编码时容易丢失关键信息。不过即使这样,也可以得出结论,即场景图结构确实有助于帮助解决视觉问答任务。此外,通过表中的对比实验可以看到,EAGN比整体注意力模型准确率高约3百分点,比无边注意力模型高约2百分点。这说明比起对整体图特征应用注意力机制,对图结构的元素应用注意力机制更能细粒度地锁定关键信息;并且考虑边注意力能够带来性能的提升,也验证了EAGN的同等注意力机制是有效的。
2.3.2 与其他模型的对比与分析
接着将EAGN与其他模型进行对比。首先在GQA数据集上的结果如表2所示。
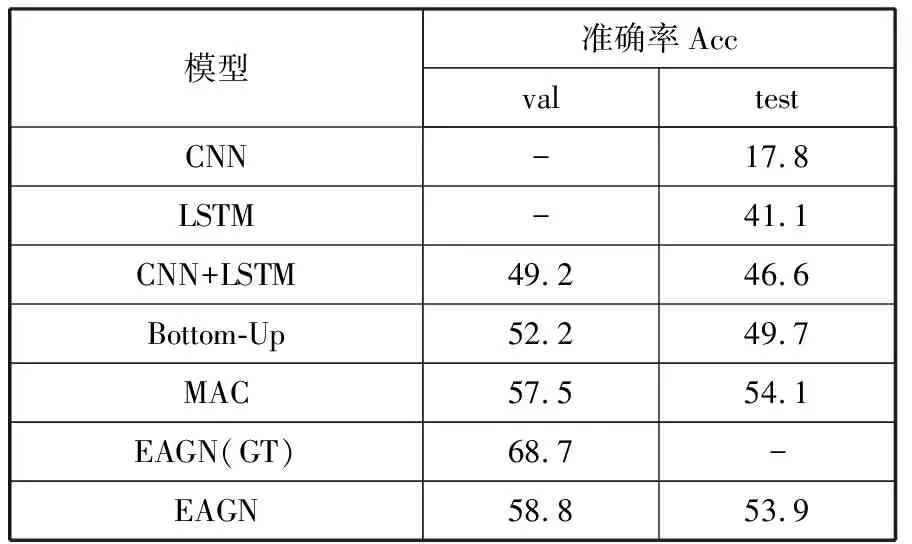
表2 在GQA数据集上的实验结果 单位:%
表2中前3种模型是简单的基线模型。CNN表示只使用图像特征来预测答案,LSTM是只使用问题特征来预测答案的模型,而CNN+LSTM则是前两者的结合。Bottom-Up是Anderson等人[18]在2018年提出的基于自底向上注意力的方法,使用了Faster R-CNN提取的区域目标特征。MAC[19]采用了多步注意力和记忆单元。从表2中的结果可以看出,EAGN比Bottom-Up表现要好,跟MAC的结果也接近,说明了图结构的有效性。
此外,本文也在VQA2.0数据集上进行了评估验证,结果如表3所示。由于VQA2.0数据集没有提供包含场景图的标注,所以在VQA2.0上只有一种实验,即使用Faster R-CNN提取的区域目标特征。
表3中前3种模型是数据集的基线模型,后面的MCB和ReasonNet是多模态融合方法,接着4种模型为基于注意力机制的方法,倒数第2种模型为与EAGN相似的模型。首先,从表3中可以看出,对比于大部分多模态融合和基于注意力的模型,EAGN模型的表现更好。其次,VQA-GAT也使用了图网络结构,不过它先对节点应用注意力机制再在此基础上应用边注意力机制。虽然本文的EAGN模型结果与它相差无几,但它在训练Faster R-CNN模型时额外添加了属性进行训练。最后,DCN模型是将问题中的每个单词与图像中每个区域相互交互后生成一个个注意力图,这样计算量会有所增多。
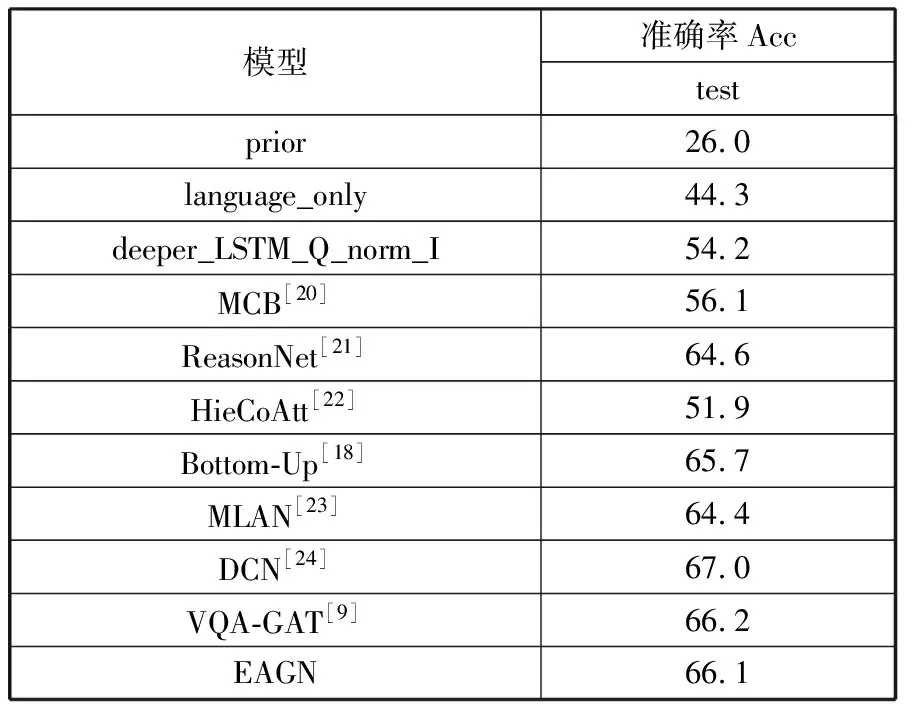
表3 在VQA2.0测试集上的实验结果 单位:%
一些预测结果示例如图3所示,包括了回答正确和回答错误的例子。由图中问题2和问题3可以看出,面对关系问题时,EAGN可以更好地利用场景图中的关系表示。综合来看,EAGN在以上2个数据集上的表现不仅说明了图结构由于能够捕捉对象间的关系而可以改善模型性能,而且也表明了本文提出的同等注意力机制的有效性。本文也为后续研究提供了新的思路,可以将基于图网络的同等注意力机制与其他优秀的模型相结合,获得更好的效果。不过,EAGN模型也存在不足之处,比如不能很好地应对逻辑、对比等类型的问题,后续工作考虑在处理过程中加入对输入问题的分析。

图3 预测结果示例
3 结束语
视觉问答是一个有趣的挑战,因为它代表了从简单的对图像的研究开始向更开放的人工视觉智能的转变,也意味着研究的难度与价值并存。本文提出了基于同等注意力图网络的视觉问答模型EAGN,在图网络之上进行问题解答。图结构能够将原图像分解,展现场景中存在的实体及其相互间的关系,有利于问题文本与图中元素进行深层次的交互。与一些基于图网络的VQA方法不同,本文的EAGN模型赋予了场景图中关系表示与节点表示同等的重要性,两者相结合为答案预测提供了更丰富的依据。实验结果展现了EAGN具有竞争力的性能,同时也表明了场景图在VQA领域的潜力,高质量的场景图可以大大提升VQA模型的表现。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
小雪花·成长指南(2022年1期)2022-04-09
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年12期)2015-11-10
