
基于数据挖掘技术的心理障碍预测模型
2021-12-09 06:37李永明
微型电脑应用 2021年11期
李永明
(渭南职业技术学院 师范学院, 陕西 渭南 714026)
0 引言
心理障碍可利用“心理病理学”的概念来解释,大范围的心理与行为异常即未按照社会认为的合适方式活动[1-2]。身体疾病只是自己受到某方面的伤害,而严重的心理疾病不仅会伤害到自己,还可能会涉及危害到其他人和社会[3-4]。
针对目前大众心理障碍现状,蔡飞亚等[5]设计了基于社会心理因素的产后抑郁症模型,付遥银等[6]设计了基于决策树的抑郁障碍预测模型,两种模型在预测抑郁症方面具有一定有效性,但两种模型仅仅针对抑郁症展开预测,具有片面性,心理障碍涵盖心理疾病种类众多,抑郁症仅为其中一种,因此有必要对心理障碍进行准确预测。在人工智能领域,数据挖掘技术为从数据库内发现知识的过程,可实现用户与数据库内知识的交互[7],通过分析数据库内各个数据,从中寻找其规律[8],因此本文结合数据挖掘技术构建基于数据挖掘技术的心理障碍预测模型,对心理障碍展开有效预测。
1 基于数据挖掘技术的心理障碍预测模型
1.1 心理障碍样本提取
为合理解决分类和回归问题,以投票或计算平均数的决策方法将随机森林生成的分类树进行重组[9]。心理障碍数据集的随机抽样是建立随机森林模型的先决条件,Bagging算法利用Bootstrap从心理障碍数据集内重复抽取子心理障碍数据集,心理障碍样本为该不同的子心理障碍数据集。Bootstrap重复抽样流程如下。
假设总样本数据集由G表示,在总样本数据集G内存在m个样本,对总样本数据集G进行抽取采样,生成的数据集为D,将所采集的样本复制到数据集D内,重复抽取的样本n次,此时数据集D内可能存在重复样本或部分存在总样本数据集G内未出现在数据集D内。假设由(1-1/m)n表示样本在n次抽取中都未被抽取到的概率,取其极限值计算式为式(1)。
(1)
通过式(1)可知,Bootstrap重复抽取样本后,初始数据集内大概有37%的样本未出现在新生成的数据集内,此类数据样本称为Out-of-Band样本,简称OOB样本,可利用此类样本为单颗分类数进行后剪枝,且可提升随机森林分类精确度[10]。特征子空间的随机抽样是建立随机森林模型的第二步,特征变量从所建立的分类树的各个节点内抽取,且与节点数量相同,通过该方法进行特征变量提取后可提升心理障碍样本特征划分准确性[11],弱化各个分类树之间关联性。
1.2 选择构建分类树模型
构建分类树的决策树算法是随机森林模型的第三步,随机森林模型由分类树组成,决策树算法构建分类树是基于每个子心理障碍样本集和抽样特征子空间。本文构建的随机森林内分类树使用C4.5决策树算法。该算法从样本数据集内寻找从属性值到分类的相关关系,且利用该相关关系对新的未知类别展开分类[12],计算样本数据集特征变量的信息增益以及增益率,依据数据集特征变量的信息增益以及增益率数据选择样本数据集的分裂节点,构建其分支并生成叶节点。使用OOB样本数据并对其进行剪枝,构建决策树。决策树算法流程如下。
设总样本数据集G通过Bootstrap重复抽取样后,pk(k=1,2,…,|y|)表示所得到的心理障碍样本集D内的第k类样本所占比例,心理障碍样本集D的信息熵计算式为式(2)。
(2)
假设离散型数据是特征a,且特征a有V个可能的取值,V={a1,a2,…,av},心理障碍样本集D的划分通过离散特征a展开,心理障碍样本集D划分后产生V个分支节点,Dv表示第V个分支节点上样本集D中特征值为av的样本。心理障碍样本集D的划分通过离散特征a实现,其划分的信息熵计算式为式(3)、式(4)。
(3)
(4)
式中,分裂点划分左部分子集由DL表示;分裂点划分右部分子集由DR表示。特征a最优的分裂点与划分最优的信息熵相对应,特征a划分训练样本集D的熵值为最优分裂点信息熵。则不同数据类型特征的信息增益计算式如式(5)。
Gain(D,α)=Ent(D)-Entα(D)
(5)
增益率计算式为式(6)。
Gain ratio(D,α)=Gain(D,α)/IV(α)
(6)
式中,IV(α)为式(7)。
(7)
综上所述,依据C4.5决策树算法构建的随机森林分类计算步骤如下。
第一步:计算心理障碍样本集D的信息增益、增益率。
第二步:从计算得到的增益率中选取最高数值,以该数值所对应的样本数据作为分裂节点,决策树根节点选择初始选择特征,从而确定分裂节点。
第三步:依据分裂节点不同特征划分心理障碍样本集,构建决策树分支。
第四步:决策树分支内心理障碍样本同属一类,将该类生成决策树叶节点。
第五步:所有叶节点生成后,利用剪枝方法对其进行剪枝处理。
在此基础上生成随机森林算法伪代码如下。
输出:选择后的数据
1:初始化Tree←NULL
2:IfD为空或遇其他结束条件则终止
3:End if
4:For数据集中所有属性ado
5:计算信息增益率
6:End for
如何对系统发电后的余热进行有效回收利用,成为推动燃气分布式能源系统应用的关键。本文对不同种类余热利用设备的特点和选用原则进行了分析和讨论。
7:Dv←信息增益率最大的属性
8:Tree← 为根决策节点
9:Dv←基于a划分的子数据集
10:For allDvdo
11:Treev←C4.5(Dv)
12:将TreeV加到Tree相应分支上
13:End for
14:Return Tree
15:Find Last Child Node(Tree Node node, ArrayListpk(k=1,2,…,|y|)
16:If 没有子节点 then
17:dopk.Add(node)
18:Ifpk样本个数<初始限制值 then
19:dok++
20:End if
21:Else
22:Return Tree
集成分类树的构建是随机森林模型的最后一步,通过投票方法将所有分类树集成,对通过随机森林形成的全部分类树进行预测投票处理,得票数量最高的预测结果为最后输出数据。随机森林模型预测流程图,如图1所示。
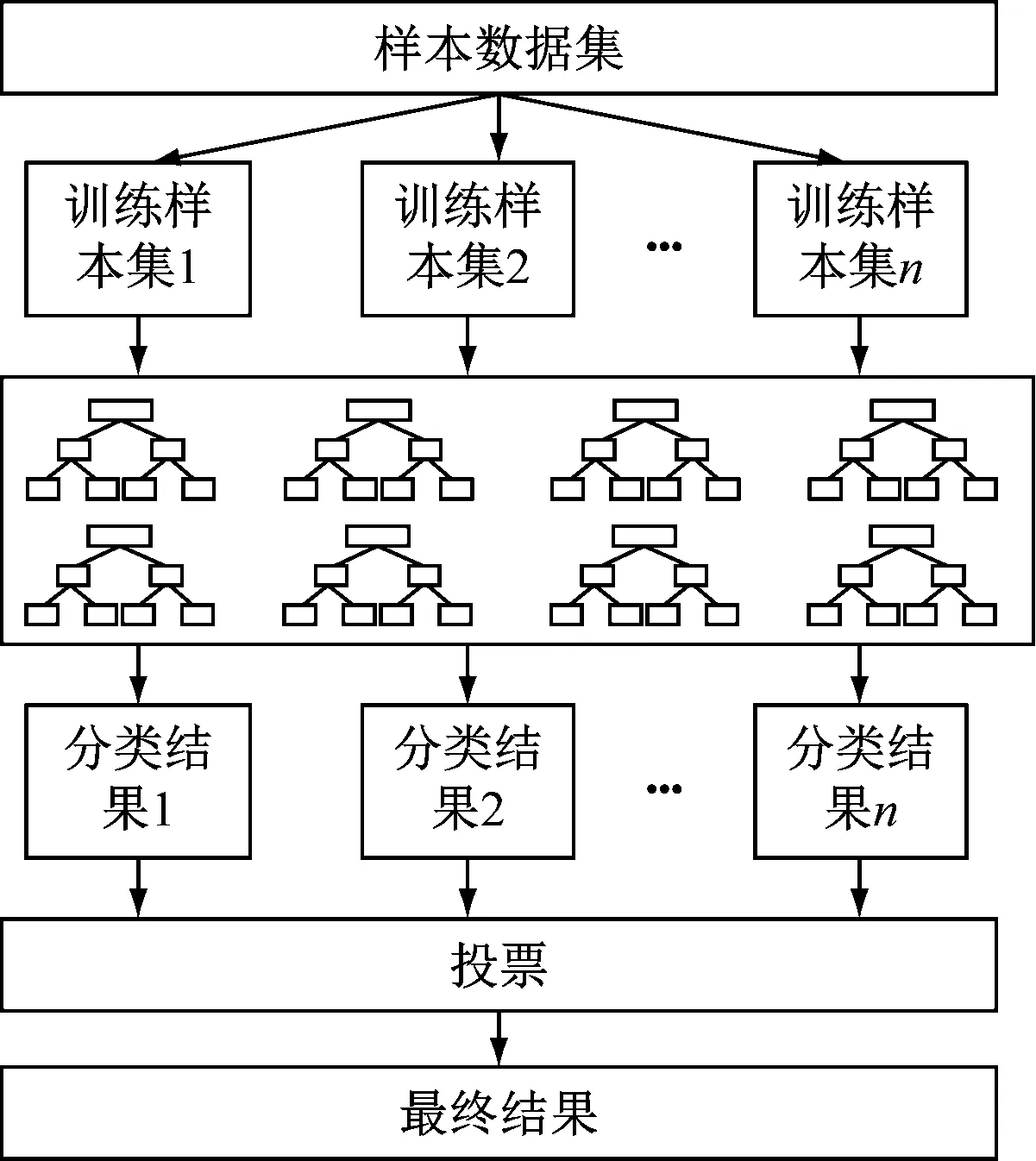
图1 随机森林模型预测流程图
1.3 随机森林泛化误差
随机森林的泛化性是指正确分类未知数据的能力。泛化误差则指分类未知数据集的错误率。提升随机森林的泛化能力和缩小其泛化误差是优化该分类器的目的。随机森林分类器的间隔函数通过Leo Breiman定义,依据大数定律,随机森林中随着分类树数量的增加,随机森林的泛化误差逐渐趋于固定数值。
1.3.1 随机森林的收敛性
假设{f1(x),f2(x),…,fn(x)}表示随机森林分类器序列,输入向量、输出向量分别由x、y表示,样本点(x,y)之间的间隔函数由mg(x,y)定义,则有式(8)。
(8)
式中,I()、avk分别表示指示性函数数值、对函数数值的平均分,函数mg(x,y)可衡量样本x分到正确和错误类别平均票数间的差值,随机森林分类越准确则函数mg(x,y)数值越大。
(9)
式中,X,Y表示空间。在随机森林中,fk(x)=f(x,θk),当分类树数量足够大时,式(9)符合强大数定律。
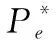
(10)
式中,Θ表示随机森林Bootstrap取样次数。
通过以上计算式可知,过拟合现象随着随机森林内分类树数量的增加不会发生。
1.3.2 分类效能与相关度
影响随机森林泛化误差受森林内任何两棵树之间的相关度和分类树的分类效能影响。随机森林的整体误差随着决策树之间的相关度增加而增加,反之则降低,一棵决策树的分类能效随着随机森林的整体误差增加而降低。设随机森林分类器集合{f(x,θ)}的分类能效如式(11)。
s=EX,Ymg(x,y)
(11)
式中,E表示能效计算函数。
若s≥0,使用Chebyshev不等式实施演算,如式(12)。
(12)
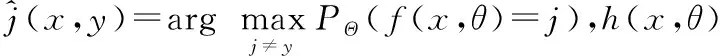
(13)
设元分类器的间隔函数计算式如式(14)。

(14)
其中,mg(x,y)是rmg(θ,x,y)在Θ中的期望值。
对上述思路实施扩展,则有式(15)。
[EΘh(θ)]2=EΘ,Θ′h(θ)h(θ′)
(15)
其中,θ与θ′分布形式为独立同分布。则计算式为式(16)、式(17)。
mg(x,y)2=EΘ,Θ′rmg(θ,x,y)rmg(θ′,x,y)
(16)
var(mg)=EΘ,Θ′(covX,Y(rmg(θ,x,y),
rmg(θ′,x,y)))=EΘ,Θ′(ρ(θ,θ′)sd(θ)sd(θ′))
(17)
式中,var(mg)表示方差。当θ,θ′不变时,rmg(θ,x,y)与rmg(θ′,x,y)的相关度由ρ(θ,θ′)表示。当θ不变时,rmg(θ,x,y)的标准差由sd(θ)表示,则有式(18)。
(18)
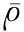
(19)
EΘvar(θ)≤EΘ(EX,Yrmg(θ,x,y)2-s2≤1-s2)
(20)
(21)
(22)
2 实验结果与分析
2.1 心理障碍数据样本及特征
本次实验选取某大型公司员工心理数据作为本次样本数据集,选取12种心理障碍以及其特征如表1所示。心理特征范围取0—2,分别表示员工心理障碍情况,很好、轻微、严重等状态。

表1 心理障碍及特征
2.2 实验结果
为验证本文模型实际应用效果,分别使用本文模型与文献[5]、文献[6]模型依据上述公司员工心理障碍样本数据集实施心理障碍预测,其中文献[5]表示基于社会心理因素的产后抑郁症模型,简称产后抑郁症模型,文献[6]模型表示基于决策树的抑郁障碍预测模型,简称抑郁障碍预测模型。
验证3种模型预测价值,绘制ROC曲线,通过ROC曲线评定各个模型预测价值,结果如图2所示。分析图2可知,3种模型的灵敏度与特异度成正比,其中产后抑郁症模型与抑郁障碍预测模型ROC曲线都呈现不同程度波浪上升趋势,显示该模型在预测过程中存在一定波动,稳定性稍差,本文模型的ROC曲线为较平滑上升趋势,其灵敏度随着特异度数值上升达到0.95,高于产后抑郁症模型与抑郁障碍预测模型,因此本文模型具有较高预测价值。
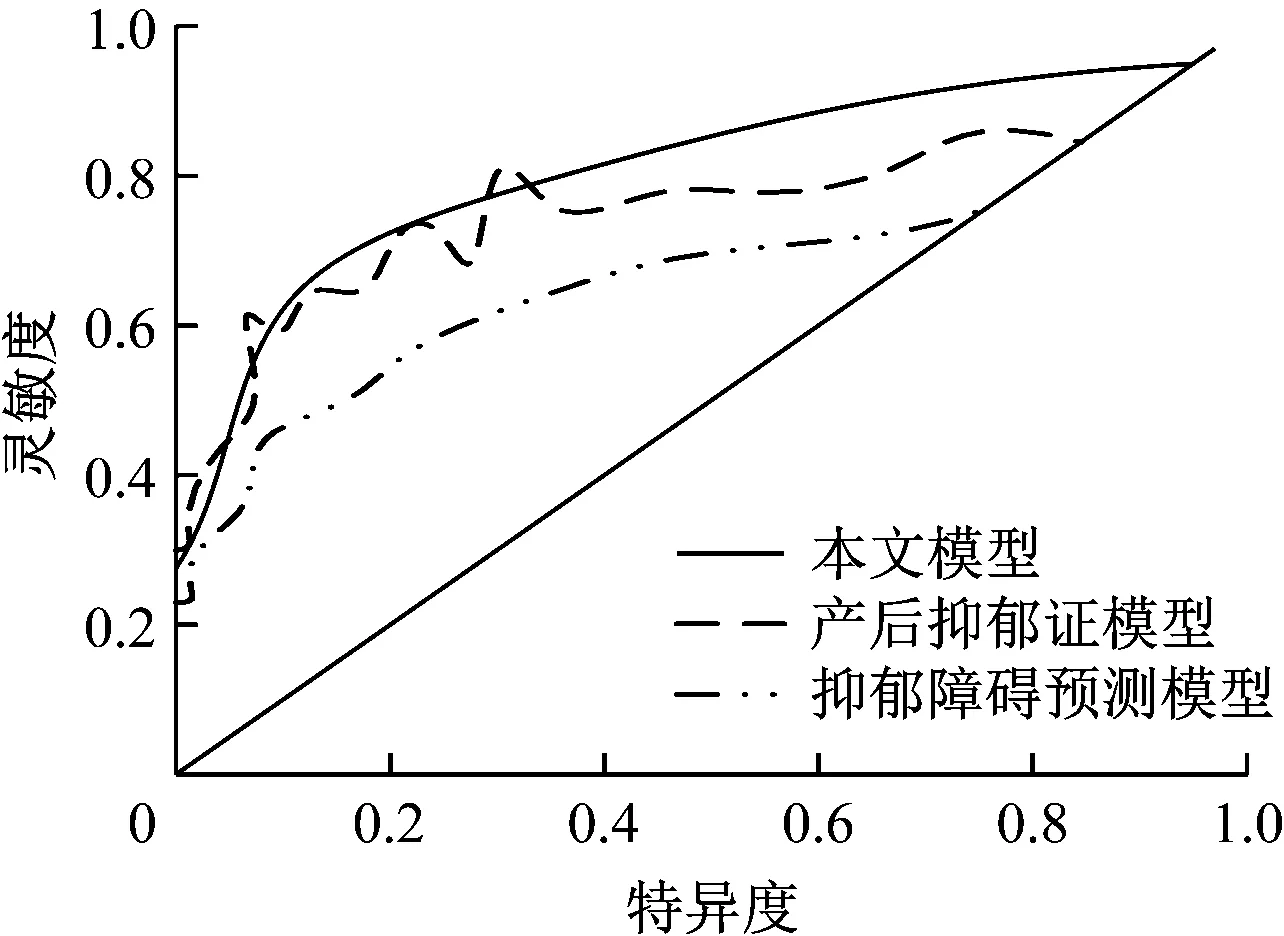
图2 3种模型ROC曲线
模型的舒适度与迭代次数关系可显示该模型的收敛能力,3种模型在对数据样本进行预测时的舒适度与迭代次数关系曲线如图3所示。
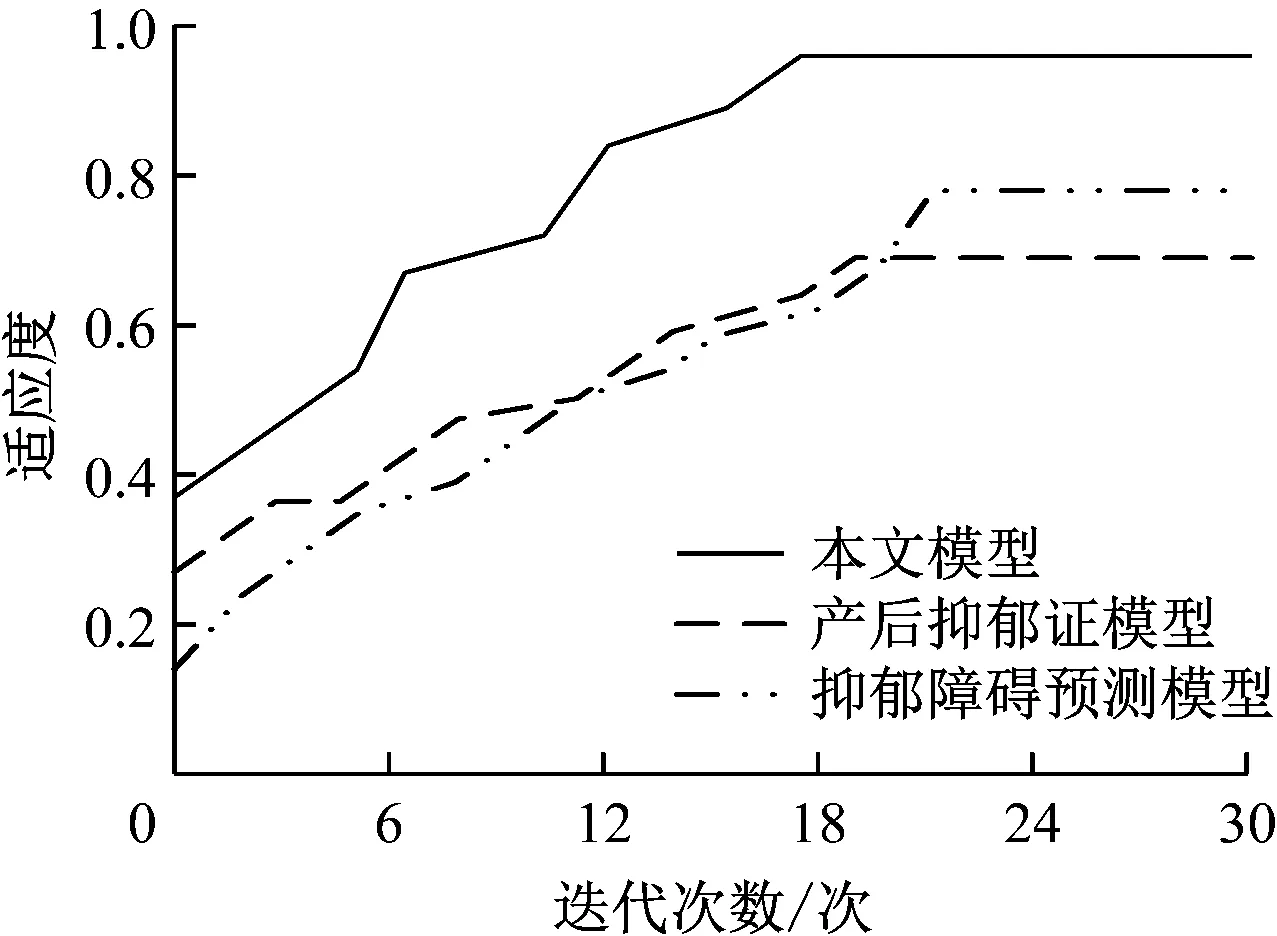
图3 3种模型的舒适度与迭代次数关系曲线
分析图3可知,随着迭代次数的增加,3种模型的适应度也随之上升,适应度到达模型预测所需要求时,随着迭代次数增加,适应度保持水平状态。本文模型的适应度曲线在迭代次数为18次时,开始保持水平状态,较另两种模型迭代次数较少,且本文模型适应度数值始终高于另两种模型,因此本文模型可在实际预测过程中迅速收敛到最佳状态,具有较强收敛能力。
为验证本文模型预测能力,使用精确度(PRE)与召回率(REC)两个指标衡量各个模型预测能力,精确度表达模型预测准确性,召回率可表达预测结果的安全性,即所有员工心理障碍样本的查全率。分别使用3种模型对数据样本进行预测,其准确率与召回率结果如图4所示。
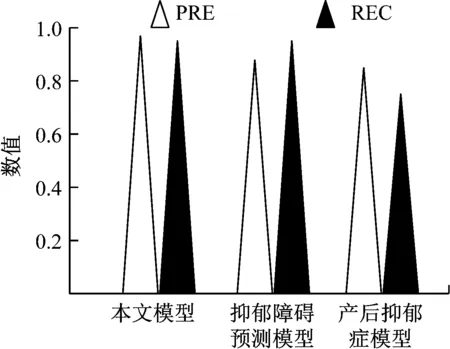
图4 3种模型准确率与召回率
分析图4可知,抑郁障碍预测模型的召回率与本文模型的召回率数值相同,但其准确率稍低,而产后抑郁症模型的准确率与召回率数值在3种模型中数值最低,预测能力较差,本文模型的准确率数值为0.98,为3种模型中最高数值,且召回率较高,可见本文模型预测能力强。
3 总结
本文利用随机森林分类器构建基于数据挖掘技术的心理障碍预测模型,该分类器可利用多棵树对心理障碍样本进行训练并预测,且在特征丢失情况下,仍可保持预测的准确性,可处理庞大复杂的数据。实验结果表明:本文模型的灵敏度0.95,预测价值较高,适应度曲线保持水平状态时的迭代次数低于对比模型,且舒适度数值较高,具有较强收敛性,准确率数值可达到0.98,召回率较高,预测能力强。
猜你喜欢
煤气与热力(2022年2期)2022-03-09
中学生数理化·高一版(2021年11期)2021-09-05
舰船科学技术(2021年12期)2021-03-29
中国民间疗法(2020年22期)2021-01-07
甘肃教育(2020年21期)2020-04-13
成都信息工程大学学报(2019年3期)2019-09-25
冰雪运动(2019年2期)2019-09-02
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
人间(2015年22期)2016-01-04
