
基于PCA-NBC算法的上市企业财务风险预警研究
2021-12-08 20:23陈启城
中小企业管理与科技·中旬刊 2021年12期
关键词:主成分分析
陈启城
【摘 要】企业因经营和财务杠杆不合理导致资金链断裂等情况时有发生,进而形成财务危机。财务风险预警模型能够在财务风险转化为危机前及时预警,帮助企业尽早应对。基于此,论文以基于PCA-NBC模型的财务风险预警模型为研究内容,采用沪深主板A股上市企业的t-3年的财务报告为数据样本,综合主成分分析法与朴素贝叶斯的优势构建了财务风险预警模型。通过测试数据集的检验,结果表明PCA-NBC算法具有较高的预测准确性,适用于制造业上市企业风险预警。
【Abstract】Unreasonable operating and financial leverage of enterprises often leads to broken capital chain, which leads to financial crisis. The financial risk early warning model can give early warning before financial risks turn into crises, and help enterprises to respond as soon as possible. Based on this, this paper takes the financial risk early warning model based on PCA-NBC model as the research content, takes the financial reports for the first three years of the t-year of A-share listed companies in Shanghai and Shenzhen main boards for the data samples, and constructs the financial risk early warning model by combining the advantages of principal component analysis and Naive Bayes. Through the test data set, the results show that PCA-NBC algorithm has high prediction accuracy and is suitable for risk warning of listed manufacturing enterprises.
【關键词】主成分分析;朴素贝叶斯;财务风险预警
【Keywords】principal component analysis; Naive Bayes; financial risk early warning
【中图分类号】F275 【文献标志码】A 【文章编号】1673-1069(2021)12-0085-03
1 引言
企业财务风险从开始到量变以及质变为危机是一个持续的过程,是各种不良因素不断积累到最终的结果。因此,企业财务风险实际上是可以预先检测,提前防治的,企业如果能在财务风险质变前及时发现并采取措施,就有机会挽回损失。
在经济全球化的大背景以及近年经济压力的影响之下,我国企业各方面都面临着严峻的挑战,虽然我国市场经济制度正在逐步完善,政府的监管力度也在加强,但是依然有许多企业面临财务风险。尤其制造业企业作为我国国民经济的重要组成部分,由于重资产、重设备的特点,比其他企业更有可能遇到流动资金短缺等财务风险,严重的可能出现资金断裂,濒临破产[1]。要想在激烈的市场竞争中占有一席之地,如何对财务风险进行预警,在面对来自外部风险的同时,抵御自身风险,显得尤为重要。因此,本文以制造业上市公司作为研究对象,通过建立客观、适用的财务风险预警指标体系,结合主成分分析法与朴素贝叶斯构建了财务风险预警模型。实验结果表明PCA-NBC财务风险预警模型预测准确率高,适用于制造业上市公司的财务风险预警,具有使用价值。
2 PCA-NBC财务风险预警模型构建
2.1 数学模型的选择
2.1.1 主成分分析
主成分分析(Principal Component Analysis, PCA)是Hotelling在1933年提出的一种使用广泛的数据降维方法。其原理是通过正交变换,用相同数量的线性不相关变量来替代原来可能存在线性相关的变量,并且变换前后信息没有损失,这些变换后的变量又叫主成分。原始数据的信息量一般用方差来衡量,因此为了实现降维的目的,通常根据实际需要选取方差贡献率最大的前几个主成分来代替原始变量,在降维的同时尽可能保留原来变量的信息[2]。如果研究数据有m个样本和n个维度的属性,则可以用X来表示样本的数据集,其中xij表示第i个样本的第j个维度的属性。然后可以通过公式求C=XTX得X的协方差矩阵,最后求出特征值与特征向量。
2.1.2 朴素贝叶斯
朴素贝叶斯法是贝叶斯分类中使用较为广泛的算法,该算法本身来源于贝叶斯定理。
2.2 财务风险指标体系设计
企业财务风险状况一般会体现在公司的财务指标中,财务指标体系的构建对提高最终财务风险预警模型的准确性十分关键。为保证财务风险指标的评估及选取的客观与适用,需要理解指标的功能并遵循一定的选取原则。预警指标的功能涉及比较功能、反映功能、评价功能、预测功能[4]。除了这四大功能外,还应遵从重要性原则、系统性原则、可操作性原则、动态性原则、定性和定量相结合原则[5]。
2.3 PCA-NBC财务风险预警模型建立
上述2种方法(主成分分析和朴素贝叶斯)各有优势,主成分分析能提取主要信息,降低数据维度,朴素贝叶斯模型有稳定的分类效率,对小规模的数据表现很好,能处理多分类任务。因此,综合考虑2种方法的优势建立组合预测模型,即主成分分析与朴素贝叶斯模型。
3 基于PCA-NBC的企业财务风险预警模型应用
3.1 数据来源及样本选择
为保证样本数据的可靠性,论文将受到监管与审计的上市公司年度财务报告作为数据来源。同时因为沪深A股与B股企业区别较大,A股遵守的是国内会计与审计准则,B股遵守的则是国际会计与审计准则,2种不同准则下的各财务报表项目和财务指标会有较大的区别[6]。因此,本文将选用沪深A股主板上市的制造业企业进行分析。实验数据取自国泰安CSMAR数据库,将选取的样本(ST、*ST样本、非ST样本)随机划分为训练样本集与测试样本集2类,用训练样本集训练财务风险预警模型并用测试样本集测试模型。根据相关文献发现,财务风险预警模型的构建以第t-1年与第t-2年有关数据进行研究虽然能有效提升财务风险预测准确率,但是对于企业财务风险预警来说过晚,意义不大[7]。因此,本文的财务风险预警模型研究将同样遵守该原则,采用制造业上市企业t-3年年度财务报告作为实验样本。
3.2 数据收集与标准化处理
3.2.1 数据收集
数据样本将选取2017年到2020年沪深A股上市的ST、*ST制造企业共45家,同时去除样本中含有缺失值的5家制造业上市企业,剩下40个ST或*ST企业样本。对于制造业非ST、非*ST企业样本,主要的选择依据是资产规模要相同或接近,共选取70个样本,因此总共取得研究样本110份。在模型训练的过程中,针对预警模型的训练与检验,将样本按照比例划分为训练集和验证集,采用随机划分的方式将80%左右的样本分训练样本,20%样本分为验证样本,循环10次。
3.2.2 标准化处理
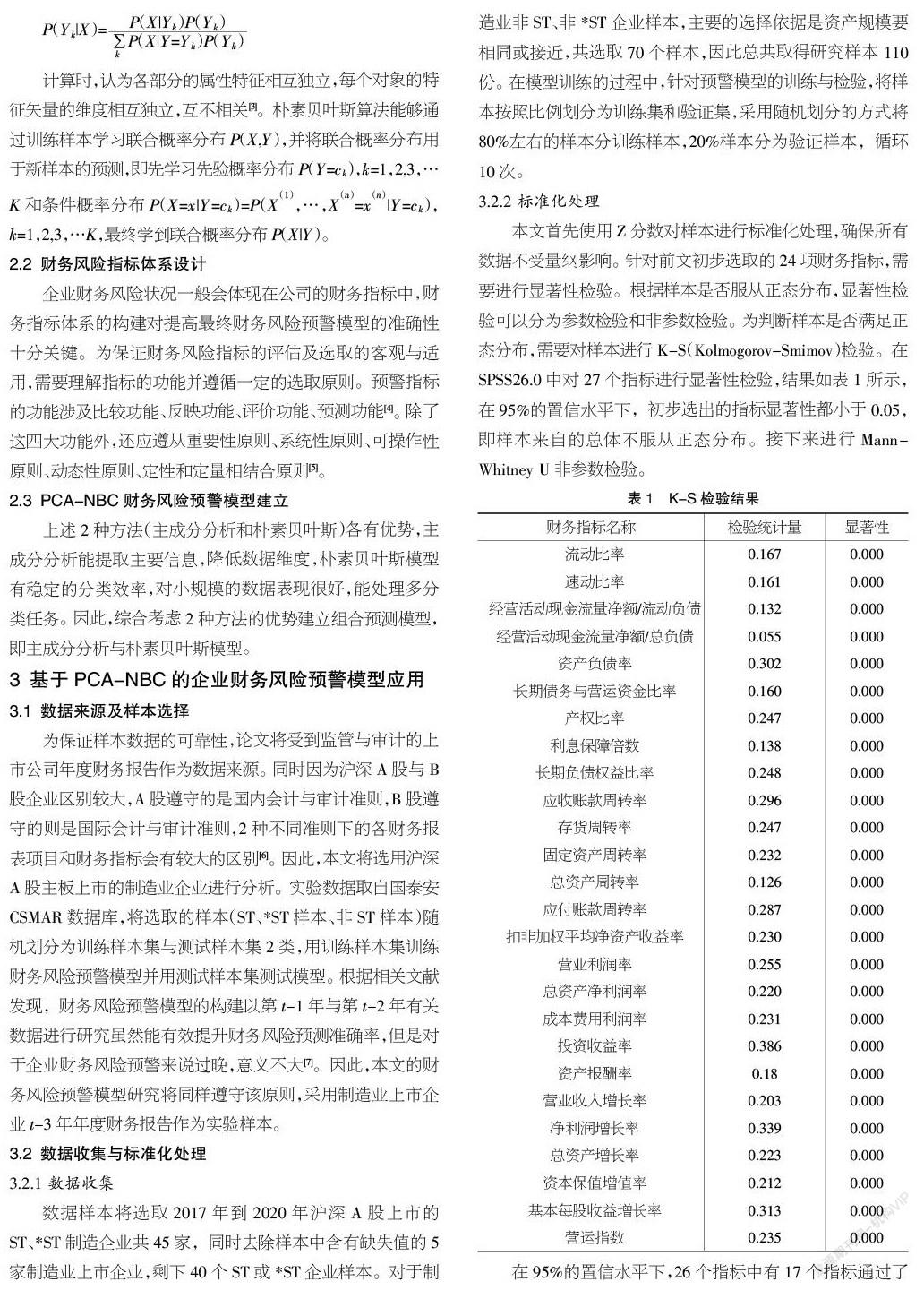
本文首先使用Z分数对样本进行标准化处理,确保所有数据不受量纲影响。针对前文初步选取的24项财务指标,需要进行显著性检验。根据样本是否服从正态分布,显著性检验可以分为参数检验和非参数检验。为判断样本是否满足正态分布,需要对样本进行K-S(Kolmogorov-Smimov)检验。在SPSS26.0中对27个指标进行显著性检验,结果如表1所示,在95%的置信水平下,初步选出的指标显著性都小于0.05,即样本来自的总体不服从正态分布。接下来进行Mann-Whitney U非參数检验。
在95%的置信水平下,26个指标中有17个指标通过了显著性检验。为使预测更加客观和有效,剔除了不符合Mann-Whitney U检验的财务指标。
3.3 基于PCA-NBC算法的财务风险预警分析
3.3.1 使用PCA提取主成分
①KMO与巴特利特球形检验。KMO与巴特利特球形是主成分分析法适用性的2种常见的检验方法[8]。KMO检验是用于比较变量间简单相关系数和偏相关系数的指标,取值在0和1之间。KMO值越接近1,意味着变量间的相关性越强。检验结果KMO值为0.671,说明相关性较强,原有变量适合使用因子分析。巴特利特球形检验则需要通过显著性检验,检验结果巴特利特的自由度为136,近似卡方为6073.419,显著性水平为0.000,说明原变量具有相关性,适合使用因子分析。
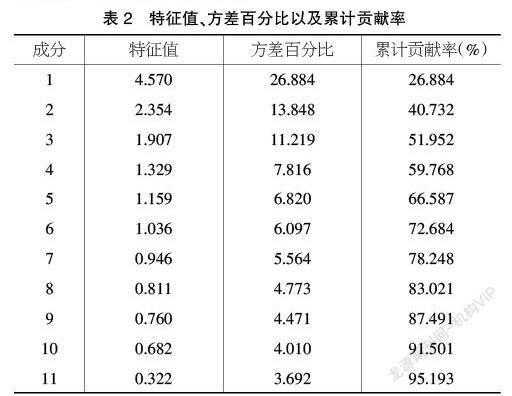
②主成分选取。主成分分析的特征值与方差贡献率如表2所示,从表中可以看到特征值大于1的主成分有6个,这6个主成分的累计贡献率只有72.684%,一般来说,累计贡献率至少要达到80%以上,才能较好地代替原来变量。因此本文提取前8个主成分代替原变量。
3.3.2 基于PCA-NBC算法的财务风险预测
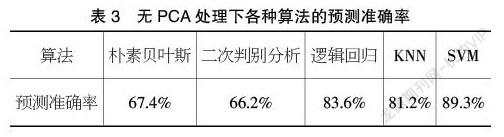
将预处理后的样本随机划分为80%的训练样本和20%的预测样本,每次训练与预测循环10次,结果取平均值。第一组实验不采用主成分分析方法提取主成分,只使用处理后的数据来训练朴素贝叶斯、二次判别分析、逻辑回归KNN(K-Nearest Neighbor)算法、SVM(support vector machine)模型,并列出预测结果。第二组实验,模型采用主成分分析提取前8个主成分,然后进行模型的训练和预测,同样列出预测结果,如表3、表4所示。
实验结果表明,在没有使用PCA处理数据时,朴素贝叶斯算法的预测准确率只有67.4%,要远小于逻辑回归、KNN和SVM算法,但是在使用PCA处理数据进行降维后,朴素贝叶斯算法的预测准确率取得了较大的提高,已经优于KNN算法,与逻辑回归和SVM相当接近,已经具有实际的应用价值。
4 结语
本文以沪深A股的制造业上市企业为研究对象,选取的实验数据样本为t-3年上市公司年度财务报表。通过数据标准化处理、K-S检验、Mann-Whitney U检验,分析并构建了客观、适合的财务指标体系。经过KMO与巴特利特球形检验确定主成分分析方法的适用性。最终使用主成分分析提取8个主成分,降低变量间相关性,提高了预测结果的准确性。
主成分分析与朴素贝叶斯的有效结合消除了样本间的线性相关关系,既降低了数据维度,又提高了模型的泛化性能,对样本数量偏少同时数据维度较高的财务数据有很好的适用性。最后,PCA-NBC上市公司财务风险预警模型预测准确率已经达到87.8%,超过二次判别分析和KNN模型,与PCA-逻辑回归、PCA-SVM模型的预测准确率十分接近,适用于制造业上市企业的财务风险预警。
【参考文献】
【1】任广乾.企业财务危机的董事会决策行为因素及其预警[J].中南财经政法大学学报,2018(6):52-61.
【2】操玮,李灿,朱卫东.多源信息融合视角下中小企业财务危机预警研究——基于集成学习的数据挖掘方法[J].财会通讯,2018(5):95-99+129.
【3】Yang, Chen, Wenping, et al. Using Bayesian model averaging to estimate terrestrial evapotranspiration in China[J]. Journal of Hydrology, 2015, 528:537-549.
【4】张亮,张玲玲,陈懿冰,等.基于信息融合的数据挖掘方法在公司财务预警中的应用[J].中国管理科学,2015,23(10):170-176.
【5】康洋平.企业财务指标体系构建及其运用[J].科技经济导刊,2021,29(19):237-238.
【6】刘玉敏,刘莉,任广乾.基于非财务指标的上市公司财务预警研究[J].商业研究,2016(10):87-92.
【7】石先兵.基于PCA-SVM的企业财务危机预警模型构建[J].财会通讯,2020(10):131-134.
【8】刘玉敏,申李莹,任广乾.基于PCA-PSO-SVM的上市公司财务危机预警[J].管理现代化,2017,37(3):12-14.
猜你喜欢
计算机教育(2016年8期)2016-12-24
商场现代化(2016年29期)2016-12-23
现代经济信息(2016年27期)2016-12-16
湖北农业科学(2016年18期)2016-12-08
时代金融(2016年29期)2016-12-05
中国房地产·学术版(2016年10期)2016-11-18
大学教育(2016年11期)2016-11-16
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
考试周刊(2016年84期)2016-11-11
商业经济研究(2016年14期)2016-09-14
