
基于光谱技术的双孢蘑菇新鲜度量化检测技术研究
2021-12-08 09:41姬江涛赵凯旋
光谱学与光谱分析 2021年12期
马 淏,张 开,姬江涛*,金 鑫,赵凯旋
1. 河南科技大学农业装备工程学院,河南 洛阳 471003 2. 机械装备先进制造河南省协同创新中心,河南 洛阳 471003
引 言
双孢蘑菇富含蛋白质、氨基酸、多糖以及多种矿物质元素,备受广大消费者喜爱[1-3]。双孢蘑菇的新鲜度是大多数消费者购买时考虑的重要因素。现有鉴别方式大多通过其外观品质特征对不同新鲜度的双孢蘑菇进行区分,作为贮藏、销售的依据。而低温恒湿环境下保存的双孢蘑菇在一定存储天数内其新鲜度很难通过其外部变化进行判断,因此亟需一种双孢蘑菇新鲜度量化检测方法,对于其存储与销售具有重要指导意义。
近年来,基于光谱分析技术的双孢蘑菇营养成分检测、保鲜以及硬度分析得到了广泛应用,刘燕德等[4]使用拉曼光谱技术建立了不同成熟度的双孢蘑菇硬度无损检测模型,结果表明直径为3~5 cm的样本可预测性更佳,预测集精度达到89.6%。孟德梅等[5]开展了双孢菇采后感官品质变化因素分析与保鲜技术研究,对双孢菇采后品质变化因素进行了系统概述。刘灿等[6]使用原子发射光谱技术对不同成熟度的双孢蘑菇主要营养元素与矿物质进行了分析,发现直径在3 cm以下的双孢菇富含蛋白质以及矿物质元素,具有更高的营养价值。上述研究在鉴别双孢蘑菇内外部品质方面取得了一定的研究成果,但对于存储过程中双孢蘑菇新鲜度的量化检测研究仍有不足。
近红外光谱技术(near infrared reflectance spectroscopy,NRS)具有分析速度快、效率高、测试重现性好、适用范围广、对样品无损伤等优点,该技术在农产品及食品检测中已得到广泛应用[7-8]。王文秀等[9]利用近红外光谱技术对猪肉新鲜度进行检测,分别使用模拟退火算法和粒子群优化算法作岭参数寻优,进行岭回归运算,相关系数分别为98.19%和97.81%。周娇娇等[10]使用近红外光谱技术对团头鲂新鲜度进行新鲜度检测,在使用竞争性自适应重加权算法提取特征波长的基础上采用多元线性回归分类方法,识别精度最高达到93.88%。段宇飞等[11]基于近红外光谱技术,使用非线性降维局部线性嵌入算法对原始光谱降维,建立了LLE-SVM鸡蛋新鲜度检测模型,训练集检测精度达到91.1%。以上研究表明近红外光谱技术在农产品新鲜度检测方面具有重要研究价值。目前,关于近红外光谱分析技术在双孢蘑菇新鲜度量化检测中的应用尚未见报道。
本文提出一种基于近红外光谱技术的双孢蘑菇新鲜度量化检测方法。以双孢蘑菇贮藏天数作为其新鲜度量化评价指标,对预处理后的原始光谱分别使用主成分分析以及连续投影算法完成数据降维,基于极限学习机分类器结合不同优化算法构建预测模型,以期能在保证预测精度的同时有效提高检测速度。
1 实验部分
1.1 材料及数据采集
实验选用当天采摘的新鲜A类双孢菇,2020年7月购于洛阳市奥吉特食用菌工厂并采用分层、分块包装且恒温箱内低温保存快速运至实验室。选择海洋光学4000+近红外光纤光谱仪,有效光谱范围为345.89~1 040.49 nm,光谱间隔为0.21 nm,共计3 648个波段。
筛选出200个菇盖直径4 cm且无表面应力损伤、菇体开裂的样本,在洁净的工作台处理后,将样本分为1~5组,每组40个样本。各组实验样本模拟超市保存条件,放置在0 ℃恒温恒湿试验箱中贮藏,每天依次从1~5组恒温箱内取出40个双孢蘑菇样本,使用近红外光谱仪进行光谱数据采集,每次实验前光谱仪预热20 min,单个样品数据采集时间历时30 s,实验历时5 d。
1.2 光谱预处理
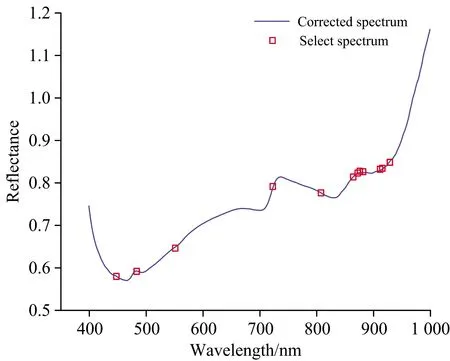
在近红外光谱信号采集过程中,受电源稳定状态、采集角度等因素影响,获得的光谱数据存在不同程度的噪声干扰。故选用SG平滑滤波与MSC校正的方式消除原始光谱噪声、基线平移以及光散射的影响。此外,光谱数据在采集初始与结束阶段,光谱波动较大,噪声明显,为避免这一影响,故选取399.81~999.81 nm作为数据处理范围,原始光谱及校正后的光谱如图1所示。
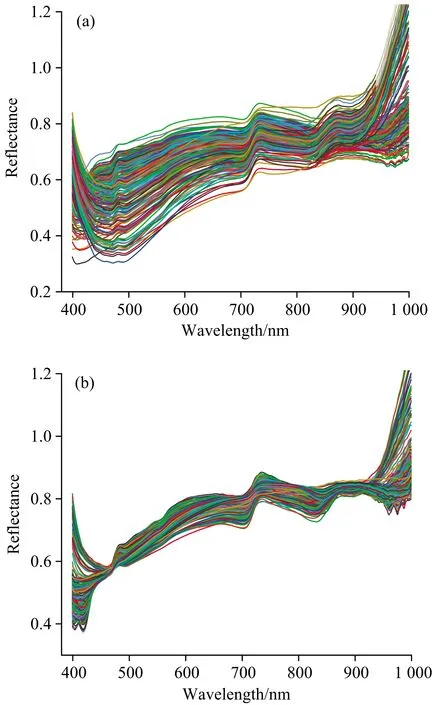
图1 光谱预处理(a): 原始光谱; (b): 平滑+多元散射校正Fig.1 Spectral pretreating(a): Original spectra; (b): Smoothing+MSC
1.3 数据降维与分类器
算法流程如图2所示,首先使用连续投影算法对原光谱进行降维处理,优选最优光谱波段组合; 然后将降维后的优选光谱组合输入到不同分类模型中,进行分类预测。利用分类准确率作为模型的评价指标,其定义如式(1)所示。
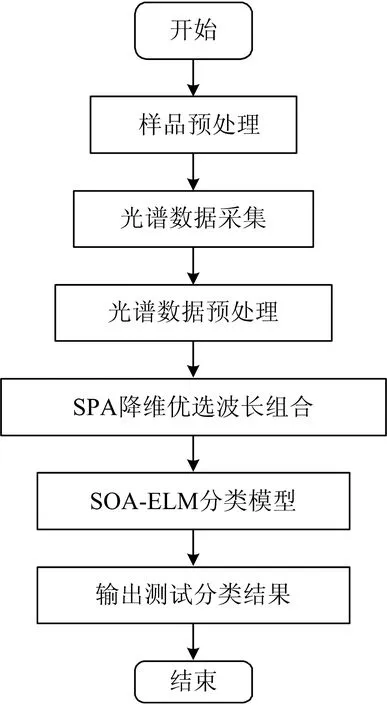
图2 算法流程图Fig.2 Flowchart of data processing
(1)
式(1)中,X为测试集样本数量,Xi为第i类识别分类正确的样本数量。
1.3.1 数据降维算法
连续投影算法(SPA)是一种前向循环特征选择方法[12],通过分析迭代向量的投影,使变量之间的共线性达到最小,最终优选出最优波长组合M及最佳波长变量数N。SPA具体计算步骤如下:
(1)迭代开始前,设定循环次数N,在全光谱Xm×p(m个样本,每个样本有p个波长数据)下,任选一光谱波长不同样本数据记为列向量xi,未选列向量记为集合
S{i, 1≤i≤p,i∉{k(0),k(1), …,k(n-1)}}
(2)逐个计算Xi在剩余列向量上投影
(3)记录、提取最大投影向量的光谱波长
q(n)=arg(max(‖Pxi‖)),i∈S
(4)令:Xi=Pxi,i∈S;
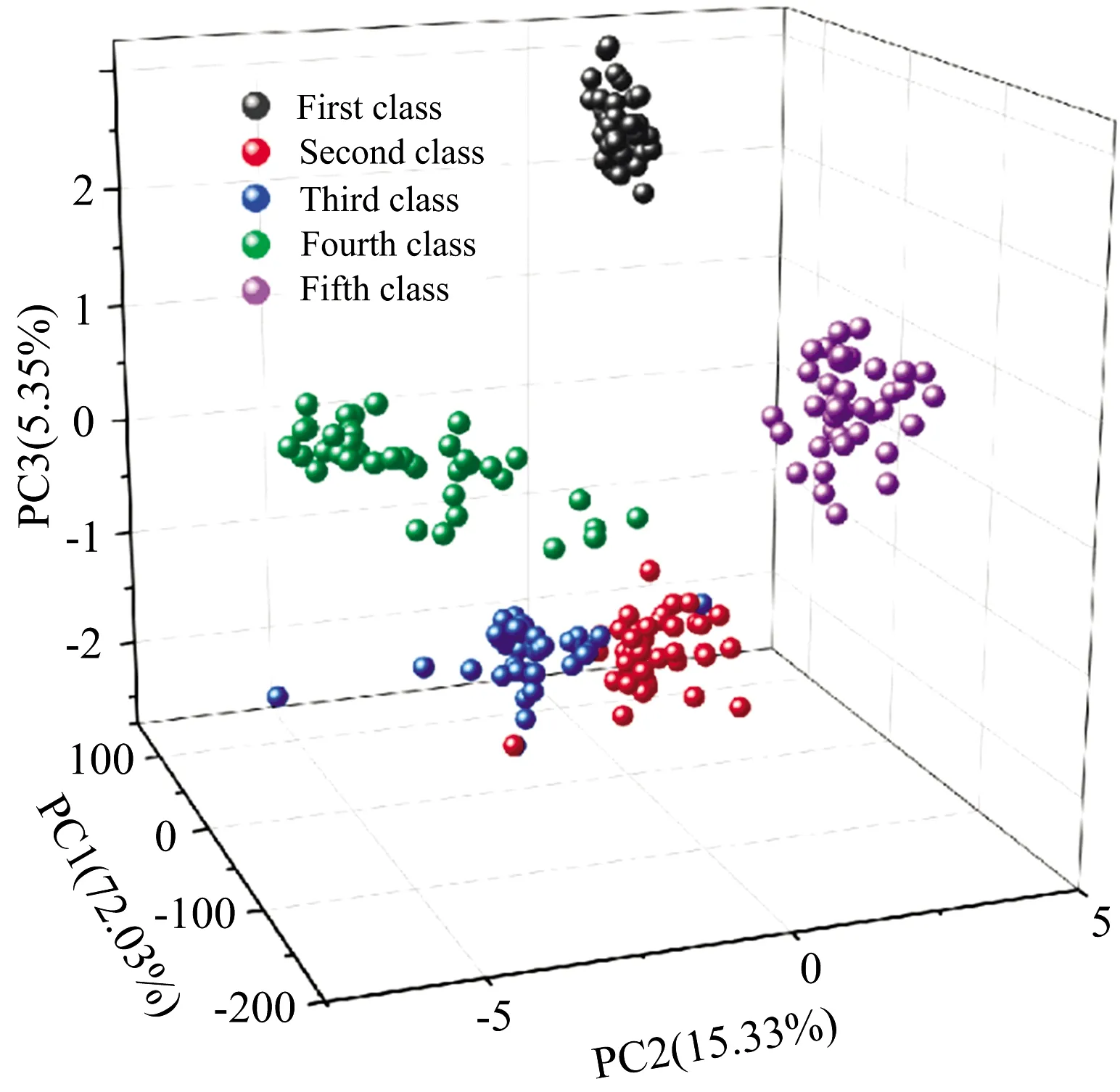
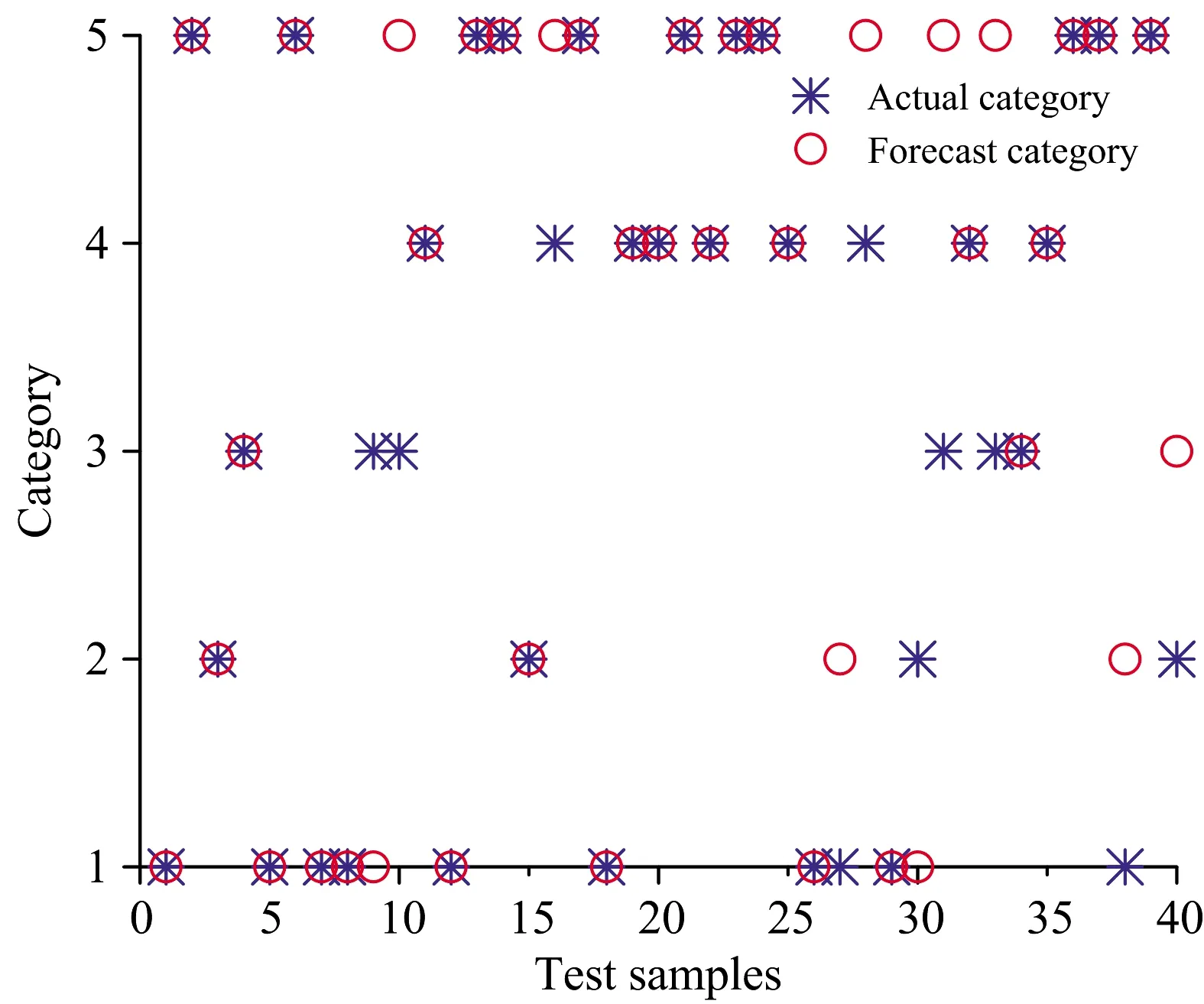
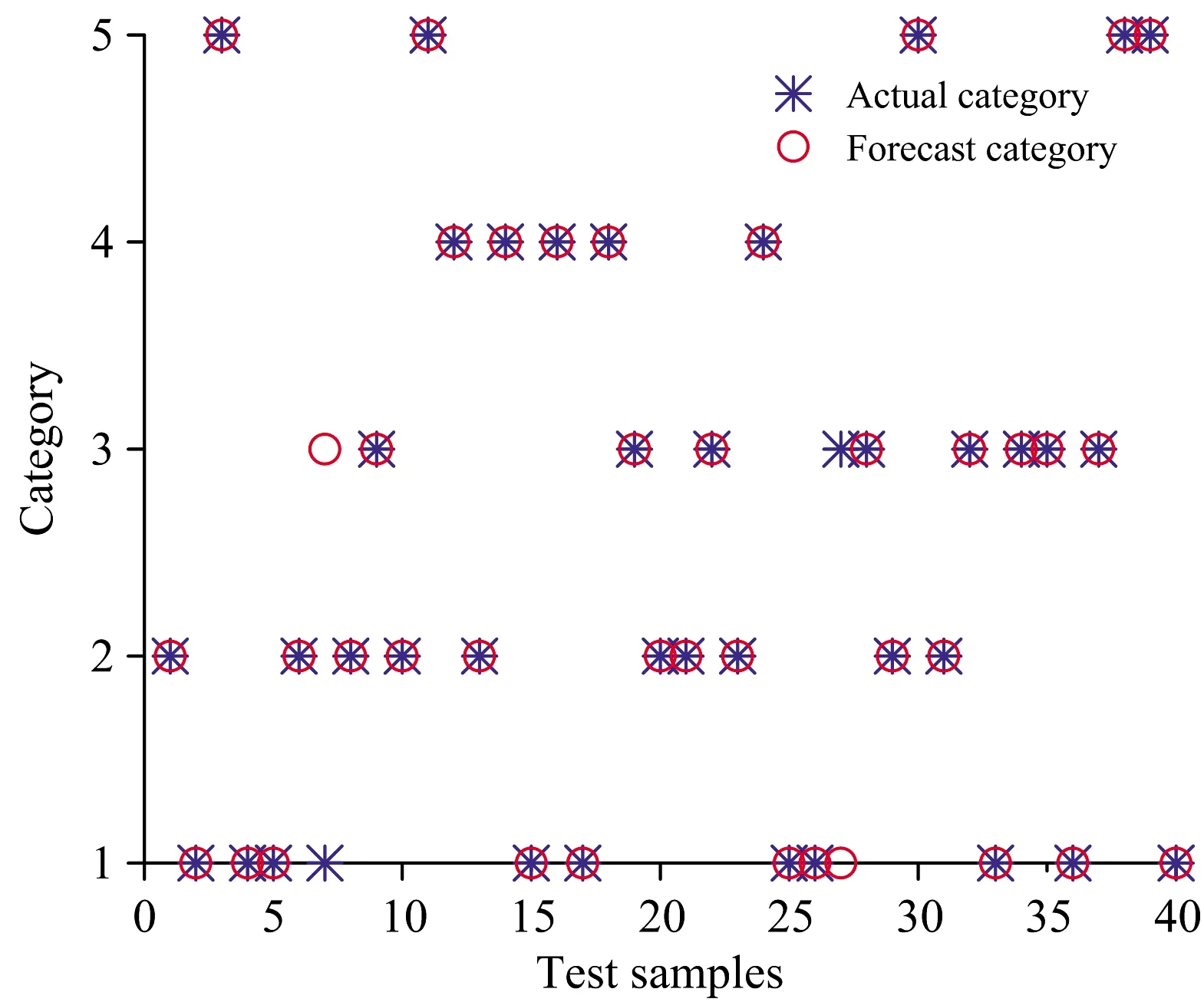
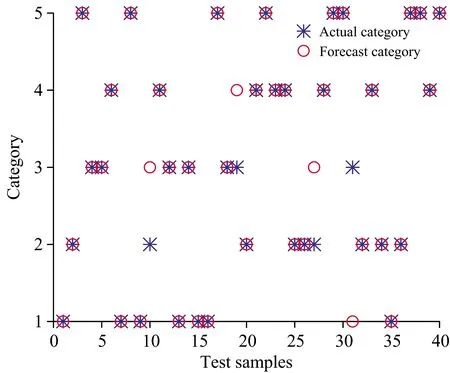
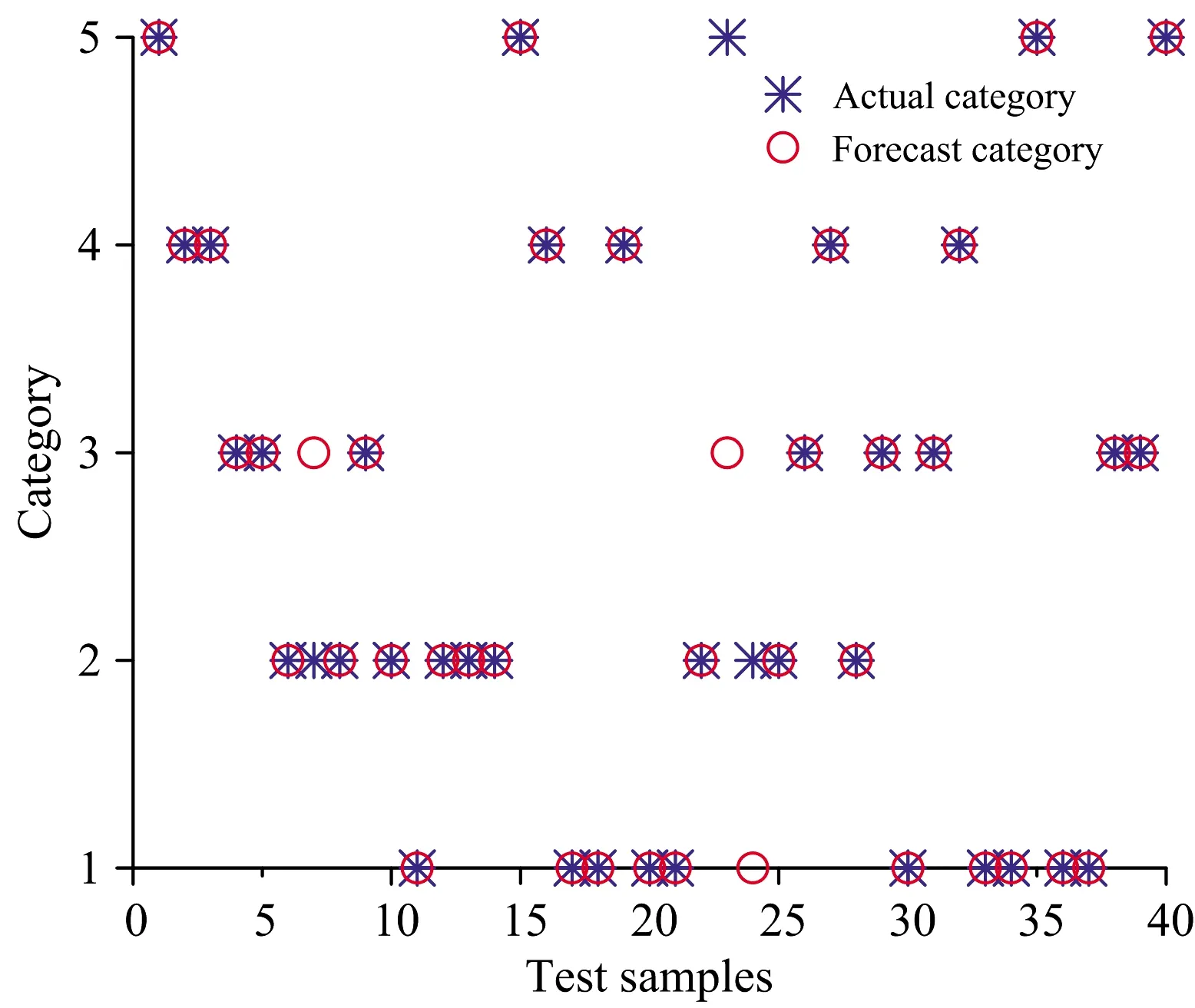
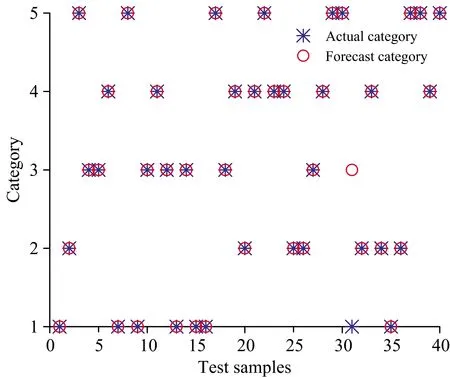
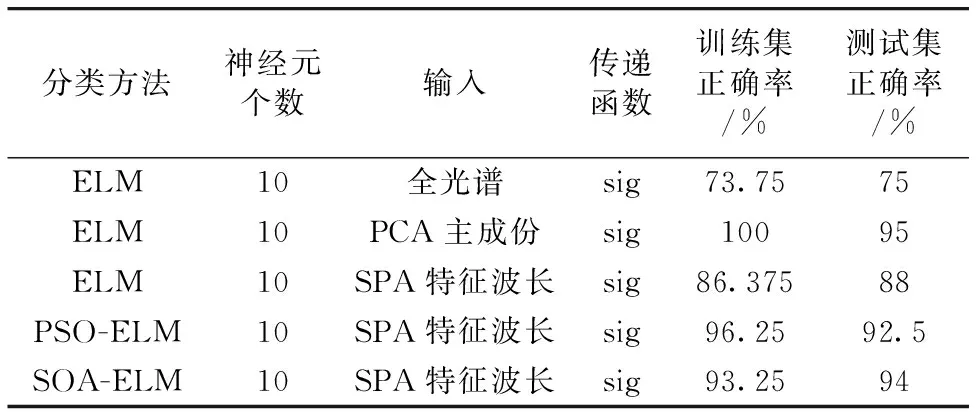
(5)令i=i+1,如果i (6)最后,提取出的特征波长变量集合为 M={Xq(i);i=1, 2, …,N-1} 连续投影算法在全波段下提取的特征波长,能够最大限度消除原始光谱数据矩阵中的冗余信息,建模过程中,能够显著提高模型计算的准确率、运算速度以及模型的稳定性。 1.3.2 分类器 极限学习机(ELM)算法最早由Huang等针对传统神经网络容易陷入局部最优解、参数设置多、训练时间长等固有缺点提出的一种单隐含层前馈神经网络的神经网络算法[13]。ELM训练模型内的输入层与隐含层间的连接权值以及隐含层神经元阈值是随机生成的,其模型预测精度主要由隐含层节点个数决定,因此ELM具有极快的学习速度以及泛化性。但是在给定模型参数下,存在随机数值为0的情况,导致隐含层的输出矩阵不为满秩,进而使部分隐含层神经元节点失效,最终造成模型预测精度较低、稳定性较差的后果。 粒子群优化(PSO)是一种常用的寻优算法,是通过控制种群规模、速度、以及运动方向计算得到局部最优解,进而得到全局最优解的过程。 海鸥优化算法(SOA)是一种新颖的生物启发式元启发算法,其模仿自然界中海鸥的迁徙和攻击行为,采用仿生智能算法进行参数寻优,目前已广泛用于函数优化、约束优化等问题[14]。SOA有较好的寻优能力,能够为学习模型寻找最优的初始值,从而得到最优的ELM训练模型,SOA-ELM算法流程如图3所示。 图3 SOA优化ELM算法流程图Fig.3 The flowchart of the ELM algorithm optimized with SOA 为实现对双孢蘑菇新鲜度快速精准的检测,本研究分别采用主成分分析(PCA)和SPA特征波长选择的方式对原始光谱数据进行降维处理,最后通过对比分析模型找出最优的解决方案。 主成分分析是常用的一种数据压缩特征提取方法,其优势在于简化原始高维变量的同时能最大限度保留原始数据的信息。采用主成分分析法对双孢蘑菇原始光谱数据进行降维分析,样品在主成分空间的分布如图4所示。 图4 主成份分析结果Fig.4 Results of principal component analysis 从图中可以看出前三个主成分的贡献率分别为72.03%,15.33%和5.35%,累计贡献率为92.89%,故可以认为三个主成分能够较好的代表原始光谱数据信息。此外,由散点图的分布可知,主成分分析法能有效区分样本的新鲜度,其中,第1天与第5天的聚合效果最好,区分度最高,这与第1天与第5天的样本差异性较大紧密相关。此外,由于样本本身差异的不明显及奇异值的存在导致第2天到第4天的样本出现个别样本重合,聚合效果相对较差,但主体部分仍有显著的区分度。故通过主成分分析结果可以看出,所选择样品具有明确的可分性,且效果较好。 实验所用仪器为高分辨率近红外光谱分析仪,波长较多,共计3 416个波段,若将所有波段输入分类模型,波长间冗余信息繁杂,不仅输入量大,训练时间过长,而且精度较低。SPA算法是通过最小化变量间共线性来选择最优波长组合,若通过SPA特征提取的降维方式对原始光谱提取特征波长,则所提取的特征波长具有相互独立、互不影响的特点且优化波长组合能有效代表全光谱的数据特征。故选用SPA算法对原光谱进行降维处理,图5是采用SPA算法对预处理光谱提取的特征波长组合。 图5 优选特征波长分布Fig.5 Preferred characteristic wavelength distribution 对所采集的200条光谱曲线,随机选择160个样本为训练集,40个为测试集,以不同天数的双孢蘑菇为输出,根据测试集的内部交叉验证均方根误差值作为筛选波长组合的选择标准。从图5可以看出,SPA算法提取最佳波长组合为: {556.87,445.51,481.15,885.10,802.25,720.90,861.34,909.79,905.58,924.44,873.17,879.06} nm,共计12个特征波长,RMSE为0.124 3,而近红外光谱仪在光谱采集过程中具有连续性的特点,相邻较近的波长具有一定的关联关系,因此可以选择相邻间隔较小波长组内,重要性较高的波长,作为该波段范围内最终选定波长。因此,最终选择特征波长为{556.87,445.51,481.15,885.10,802.25,720.90,861.34,909.79,924.44,873.17} nm,共计10个波段,其重要性依次递减,特征数量占原始全光谱的0.32%。此外,通过观察所选特征波长的分布可以看出,可见光波段范围内的特征波长数为3,近红外短波波段内的特征波长数为9,说明近红外短波波段对双孢菇新鲜度检测贡献值更大,并且特征波长选择多集中在900 nm处,这是因为特征波长在910 nm处对C—H键延伸具有吸收特性,说明双孢蘑菇贮藏过程中蛋白质在分解消耗。 利用训练集160个样本的光谱数据以及天数进行分类,使用SPA+SOA-ELM算法建立双孢蘑菇新鲜度检测的分类模型,以分类的准确度作为评价准则。分别与全光谱+ELM、PCA+ELM、SPA+ELM和SPA+PSO-ELM进行对比,考虑到ELM分类模型存在一定随机性,取5次运行结果的平均值作为最终预测精度,得到的测试集分类结果对比如图6—图10所示。 图6 全光谱+ELM检测结果Fig.6 Full spectroscopy and ELM detection results 图7 PCA+ELM检测结果Fig.7 PCA+ELM detection results 图8 SPA+ELM检测结果Fig.8 SPA+-ELM test results 图9 SPA+PSO-ELM检测结果Fig.9 SPA+PSO-ELM test results 图10 SPA+SOA-ELM检测结果Fig.10 SPA+SOA-ELM test results 为了比较不同预处理方式与分类算法的优劣,将模型参数设置和测试结果统计如表1所示。从表1可以看出,PCA+ELM模型测试集结果最佳,分类准确率为95%; 以SPA选择特征为输入的SOA+ELM、PSO+ELM与ELM分类模型识别准确率分别为94%,92.5%和88%; 而全光谱+ELM分类准确率最低为75%。由此可知,通过使用PCA提取主成份或SPA算法提取特征波长作为训练集输入时,其测试集精度均远高于全光谱训练模型,这是由于通过对样品分类选取合适的特征,能有效降低样本特征的维度和冗余性,增强了变量与因变量的关系。 表1 模型测试结果对比表Table 1 Comparison results of the classificationmodel testing 对于以SPA选择特征为输入的SOA+ELM、PSO+ELM、ELM算法来说,后两者模型相较于前者模型分别提高了5.1%和6.8%的识别精度,体现了元启发式算法具有较好的全局寻优能力,能够为ELM模型寻找较优的初始值。此外,也可以看出,SOA优化后的模型测试精度略高于PSO优化模型,且PSO训练集准确度高于测试集精度,存在过拟合现象。由此可知,PSO算法寻优过程依赖于参数设定,局部搜索能力较差、搜索精度不高,粒子在俯冲过程中可能错失全局最优解,而海鸥优化算法在全局搜索过程中,是根据当前最佳位置计算新位置、方向,并且在搜索过程中不断改变更新、寻找最佳位置和适应度值,表明SOA算法较优的鲁棒性。 由上述分析可知,在所有模型中,以PCA+ELM模型结果最佳,这是由于PCA提取主成份是通过构建全波段不同权重比例系数得出新特征的过程,能够最大限度保证原始光谱信息,同时去除冗余信息,但是以全光谱作为输入计算主成份过程计算量大、建模效率低,不利于便携式光谱仪的发展,而SPA+SOA-ELM模型输入仅为10个特征波长,建模速度快且精度较高,为研制新型便携式的光谱仪提供了理论依据。 (1)分析特征波长分布,可见光波段内的特征波长数为3,近红外短波波段内特征波长数为9,可知近红外短波区域的特征波长数量多于可见光区域,表明该处特征波长对双孢蘑菇新鲜度量化检测的贡献最大,也反映了双孢蘑菇贮藏过程中蛋白质成分变化较多。 (2)开展了基于近红外光谱的双孢蘑菇新鲜度量化检测方法研究,提出以贮藏天数作为双孢蘑菇新鲜度量化评判的综合指标。基于SG+MSC方法对双孢蘑菇原始光谱预处理的基础上,分别使用PCA和SPA算法对原光谱数据进行降维处理,继而通过比较全光谱+ELM、PCA+ELM、SPA+ELM、SPA+PSO-ELM和SPA+SOA-ELM模型可知,降维处理后的训练集和测试集精度均显著高于全光谱。 (3)为了提高模型检测速度,基于统计学方法,探索了可见-近红外短波光谱预测双孢菇新鲜度的有效方式,其中,SPA+SOA-ELM在全光谱3416个波长下提取了10个有效波长,进而基于SOA-ELM建立了双孢菇新鲜度检测模型,该模型训练集和测试集的正确率分别为93.25%和94%,该结果与采用主成分分析法基本保持一致,但极大的减少了计算量。故SPA+SOA-ELM成功用于双孢蘑菇新鲜度的量化检测,为进一步开发快速、便携式及无损双孢菇新鲜度量化检测仪器提供了理论依据。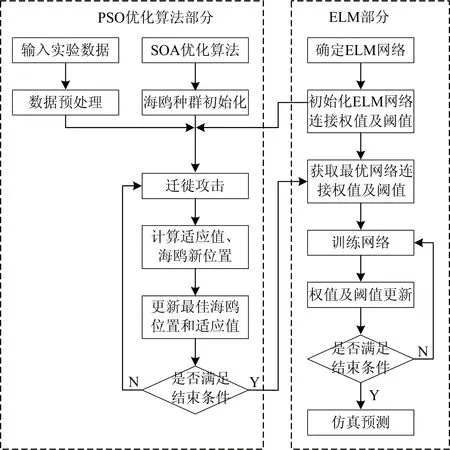
2 结果与讨论
2.1 主成分分析
2.2 SPA特征波长选择
2.3 分析模型对比
3 结 论
猜你喜欢
现代食品(2018年4期)2018-02-18
食用菌(2017年3期)2017-05-24
妇女之友(2016年9期)2016-11-07
西藏科技(2016年8期)2016-09-26
作文周刊·小学一年级版(2016年1期)2016-08-12
文理导航·科普童话(2015年2期)2015-06-16
食药用菌(2014年1期)2014-04-04
食品工业科技(2014年13期)2014-03-11
食品工业科技(2014年13期)2014-03-11
食品工业科技(2014年9期)2014-03-11
