
基于多尺度渐进融合网络的图像超分辨重建
2021-12-08 10:33张凯兵
湖北工程学院学报 2021年6期
崔 琛,黄 辉,张凯兵
(1.西安工程大学 电子信息学院,陕西 西安 710048;2.广西科技师范学院 职业技术教育学院,广西 来宾 546100)
图像超分辨是一种利用同一场景下获得的一幅或多幅低分辨率(low-resolution,LR)图像重建出一幅高分辨率(high-resolution,HR)图像的图像恢复技术[1]。一般而言,目前主流的超分辨算法主要分为四种要类型:基于插值的方法[2-4]、基于重构的方法[5-8]、基于传统的实例学习的方法[9-12]和基于深度学习的方法[13-15]。
基于插值的方法主要是利用特定的基函数或插值核估计高分辨率图像中的未知像素。尽管这类方法简单、高效,但它们难以恢复低分辨率图像中丢失的高频细节,导致重建的图像视觉效果模糊,通常情况下难以满足实际应用要求。基于重构的方法通过求解图像生成的逆问题实现高分辨率图像的估计,但该方法重建图像的质量很大程度上依赖于应用的先验知识。因此,学习并利用有效而全面的图像先验知识进行正则化求解,是成功解决该问题的关键。基于传统实例学习的图像超分辨方法主要借助于机器学习技术,从给定的大量实例图像对中学习低分辨与高分辨图像块之间映射关系,实现低分辨图像到高分辨图像的变换。虽然基于传统实例学习的方法能有效恢复低分辨图像中丢失的高频细节,但是该类方法对数据集的依赖性较强,当输入图像与训练数据集中的图像在结构上差异较大时,重建出的超分辨图像并不能达到令人满意的效果。
近年来,随着深度卷积神经网络在计算机视觉中的成功应用,基于深度学习的超分辨方法得到了人们广泛的关注,出现了很多有效的深度学习超分辨重建算法。Dong等[5]首次应用卷积神经网络模型建立低分辨与高分辨图像间的非线性映射关系,提出了卷积神经网络的超分辨方法(super-resolution convolutional neural network, SRCNN)。该方法首先利用卷积层对低分辨图像进行特征提取,然后利用获得的映射特征重建出需要的高分辨图像。之后Dong等[7]对SRCNN进行了改进,在低分辨率空间进行图像特征的提取和非线性映射,最后使用反卷积实现图像超分辨重建。受大规模图像识别深度卷积神经网络的启发,Kim等[8]提出了一种基于深度卷积神经网络的精确图像超分辨率(very deep convolutional neural networks,VDSR)重建方法。为扩大超分辨网络的感受野,该方法使用了更深的残差网络结构,其性能较基于SRCNN的超分辨方法具有明显的优势。为缓解过深的网络结构而导致网络在训练过程中出现梯度消失或梯度爆炸问题,He等[9]提出了一种深度残差网络(residual network,ResNet)的图像识别方法,该方法通过设计残差连接网络结构,能在网络层数较深的情况下仍能获得较好的训练效果。受该思想的启发,Lim等[10]将残差网络结构引入到超分辨率重建网络中,提出了一种增强深度残差网络的超分辨方法(enhanced deep residual network based super-resolution,EDSR),该方法通过去掉归一化层,使用更深更广的网络结构实现对SR网络的增强。Zhang等[11]使用密集残差块和所有卷积层的层次特征,提出了基于残差密集网络(residual dense network,RDN)的超分辨网络模型。他们利用残差中的残差结构和通道注意机制构建了一个残差通道注意力网络(residual channel attention network,RCAN),该方法能有效缓解深层网络的训练难度,提高了超分辨网络的重建能力。尽管上述网络模型在解决超分辨问题中取得了较好的效果,但他们都忽略了如何利用低分辨图像中多尺度相似性信息来进一步提高超分辨重建的性能。由于自然图像在同一尺度和不同尺度之间均存在相似性结构,相同尺度的自相似性有助于提高超分辨估计的鲁棒性,而不同尺度的相似性有助于恢复图像中更精细的纹理结构信息。
最近研究者除了研究超分辨网络的结构外,还提出了许多针对超分辨重建的特征提取模块块,具有代表性的有残差块[11]、密集块[13]和Inception块[14]。Li等[15]引入Inception块来提取低分辨图像的多尺度特征。Kim等[16]提出了一种增强的残差块,从而减轻网络训练的难度。Li等[17]提出了一种带有门控选择机制的残差块,可以自适应地学习高频信息而过滤低频信息。Wang等[18]提出了多记忆残差块,将长短时记忆嵌入到该模块中,有效地学习了连续低分辨图像帧之间的相关性。Tong等[19]引入了密集块,提出了一种将低维特征和高维特征有效相结合的方法,从而提升重建性能。Zhang等[11]提出了一种残差密集块,该模块结合残差块和密级连接块的优点,充分利用了低分辨图像的所有分层特征。不过,残差块和密集块都只使用单一大小的卷积核,不仅很难检测到不同尺度的图像特征,而且增加了计算复杂度。为了解决上述方法中存在的不足,Li等[20]将大小不同的卷积核加入到残差块中,并提出了多尺度残差块(multi-scale residual block,MSRB),并且在不同尺度特征之间使用跳连接实现特征的共享和重用。尽管基于MSRB的方法能检测到不同尺度的图像特征,但该方法应用大尺寸卷积核会会导致网络计算复杂性的显著增加,而且该模型没有充分利用浅层和深层局部图像特征,导致该方法仍存在一定的局限性。
鉴于上述分析,本文将研究如何充分利用不同尺度的浅层和深层局部图像特征来解决上述方法存在的不足,以提高基于深度学习超分辨网络的重建性能。为了充分利用低分辨图像中多尺度图像特征之间的互补性,本文提出了一种基于多尺度渐进融合网络(multi-scale progressive fusion network,MSPFN)的图像超分辨方法。该方法首先利用高斯核对LR图像依次进行下采样,生成高斯金字塔序列图像。然后,设计一种粗融合模块(coarse-fusion module,CFM)实现多尺度图像特征的提取和融合,之后利用细融合模块(fine-fusion module,FFM)进一步对CFM中特征进行整合,并且在FFM模块中引入通道注意力机制选择性地学习不同尺度的特征,以有效地减少特征冗余。利用多个FFM模块以级联形式构建渐进多尺度融合网络,最后通过重建模块(reconstruction module,RM)对来自CFM模块和FFM模块的特征进行融合,以生成高质量的超分辨图像。提出的基于MSPFN的网络结构图如图1所示。

图1 基于MSPFN的网络结构图
1 多尺度渐进融合超分辨网络
1.1 多尺度粗特征提取与融合
首先对输入图像使用高斯核生成不同尺度的高斯金字塔图像。将金字塔图像作为输入,并通过多个并行的卷积层提取浅层特征。在粗融合模块中,将不同尺度的浅层特征输入到几个并行的残差递归单元(residual recurrent units,RRU)中,实现多尺度图像深度特征的提取。残差递归单元如图2所示。设计粗融合模块的作用包括三个方面:1)引入Conv-LSTM来模拟空间维度上的纹理信息,并采用递归计算和残差学习来获取互补的图像信息。2)对于多尺度图像来说,不同尺寸的图像能够提供不同的感受,使得网络在浅层结构上能捕获到更多的图像内容和细节。3)有利于提取多尺度图像特征,实现更加鲁棒的超分辨重建。
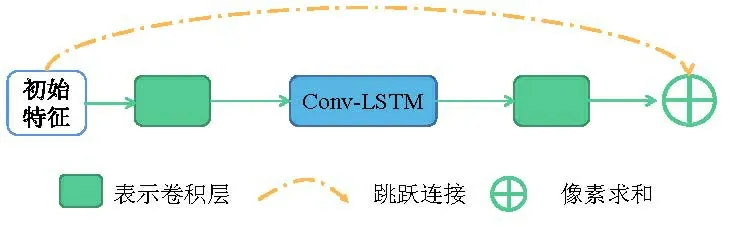
图2 残差递归单元
1.2 多尺度细特征提取融合
为了获得更加精细的图像特征,将CFM模块输出的结果输入到FFM模块中。为了便于观察,将CFM模块设计成与FFM模块具有相似的多尺度结构,如图2所示。与CFM模块不同,在FFM模块中加入了通道注意力机制,增强了网络对重要特征的学习能力,从而为每个通道分配不同的权重,让网络更多地关注重要的图像特征抑制不重要的特征。最后,为了避免信息丢失,利用反卷积来提升分辨率,从而构成U型残差注意力模块(U-shaped residual attention block,URAB)。URAB结构如图3所示,URAB由多个通道注意力单元组成,利用短跳跃连接学习同一尺度下的相似信息,而且在级联的细融合模块中利用长跳跃连接,不仅实现不同尺度下的图像信息融合,而且有利于反向传播。

图3 URAB结构图
1.3 损失函数
对图像超分辨重建模型中,损失函数用来计算真实的高分辨图像与超分辨图像之间的误差,以指导模型的优化。早期研究人员采用像素上的L2范数作为损失函数,尽管该损失函数能获得较高的峰值信噪比(peak signal-to-noise ratio,PSNR)和相似结构(structural similarity,SSIM),但主观视觉效果并没有提升。因此,该方法容易导致图像细节的模糊,产生过度平滑的视觉效果。为了避免上述问题,本文以Charbonnier损失函数为指导提出一种新的损失函数,表示为:
(1)
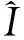
为了进一步改善高频细节的真实性,使用另外一种边缘损失函数来防止出现图像过度平滑的效果。边缘损失函数表示为:
(2)

L=L1+λ×Ledge
(3)
式中:λ为权重参数,本文实验中设置为0.05。
2 实验结果与分析
2.1 数据集
本文提出的MSPFN模型在DIV2K[21]数据集进行训练该数据集包含800幅训练图像,100幅验证图像和100幅测试图像。本文选择800幅图像进行训练,选择5幅图像进行验证。测试集选用Set5,Set10,Set14和Urban100,它们分别包含5、14、100、100幅图像。这些数据集中包含图像内容丰富,能充分评估超分辨重建算法的有效性。
2.2 参数设置
为了验证本文所提出算法的有效性,首先建立一个基准模型。在本文的基准中,金字塔图像的级别设置为3,即原始比例、1/2比例和1/4比例。在CFM中,每个循环Conv-LSTM的滤波器数量分别设置为32、64和128,FFM(M)和CAU(N)的深度分别设置为10和3。利用Adam优化器每批次处理16幅图像,初始学习率设为2×10-4,每20000步减小为原来的1/2,直到1×10-6,将上述参数设置迭代30次进行训练网络。本文实验均在英伟达2080Ti GPU和Ubuntu 18.04系统中进行训练和测试。
2.3 消融实验
1)基本模块验证。本文使用的基准模型中M=10,N=3,分别设计3个比较模型来分析基本模块CFM、FFM和多尺度金字塔框架对超分辨性能的影响。其中Model1是仅具有原始输入的单尺度框架,Model2代表从MSPFN去除所有CFM模块的网络模型,而Model3表示从MSPFN中去除所有FFM模块的网络模型。表1是Set14数据集在×2倍放大情况下不同模型的重建结果。由表1可知,本文提出的MSPFN相对于其他三种模型具有明显的优势,而且发现FFM模块对超分辨重建结果的影响显著高于CFM模块和单尺度框架。
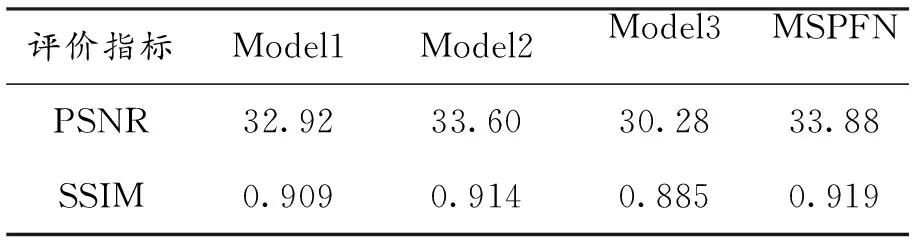
表1 基本模块验证结果
2)M和N参数分析。为了验证FFM的深度(M)和CAU(N)的数量对超分辨性能的影响,相对于基准模型(M=10,N=3)设计出4个比较模型,4个模型分别为MSPFNM5N3,MSPFNM8N3,MSPFNM10N1,MSPFNM10N5。表2列出了Set14数据集在×2倍情况下在不同模型的重建结果。

表2 不同M和N的比较结果
由表2可知,随着M和N的增加,超分辨重建图像的质量也随之提升。但需要注意的是,随着M和N的增加,超分辨网络模型的参数量会增加,导致算法的计算效率变低。为平衡重建质量和计算效率,本文设置M=10,N=3。
2.4 对比实验
为了验证本文所提出方法的有效性,将本文方法与7种主流超分辨方法进行比较,包括A+[22],SelfExSR[23],SRCNN[5],FSRCNN[7],VDSR[8],DRCN[24]和MSRN[20]。图4~图6从视觉质量上分别展示8种算法对不同测试图像进行超分辨的视觉效果,并对比了4倍放大下各算法对Urban数据集中的3幅图像(包括img005、img061和 img074)中特定区域的重建效果。从图4~图6中的对比结果可以看出,本文所提出的算法重建出的效果最接近与原始图像。其中,A+和SelfExSR算法重建的图像视觉效果最差,出现了明显的模糊,且纹理细节缺失严重。SRCNN和FSRCNN相对与A+和SelfExSR性能有所提高,但是重建出来的边缘和纹理细节比较模糊,不能满足实际需求。VDSR,DRCN和MSRN相较于其他算法性能有明显的提升,但在纹理细节丰富的区域出现明显的扭曲失真。综合上述结果,可以看出本文所提出的算法恢复出来的图像纹理细节最清晰,视觉效果最好。

图4 img005放大4倍时SR结果对比

图5 img061放大4倍时SR结果对比

图6 img074放大4倍时SR结果对比
表3展示不同方法在Set5、Set14、Urbanl00和BSDl00 4个测试数据集上的3种放大倍数情况下的平均PSNR值和SSIM值。
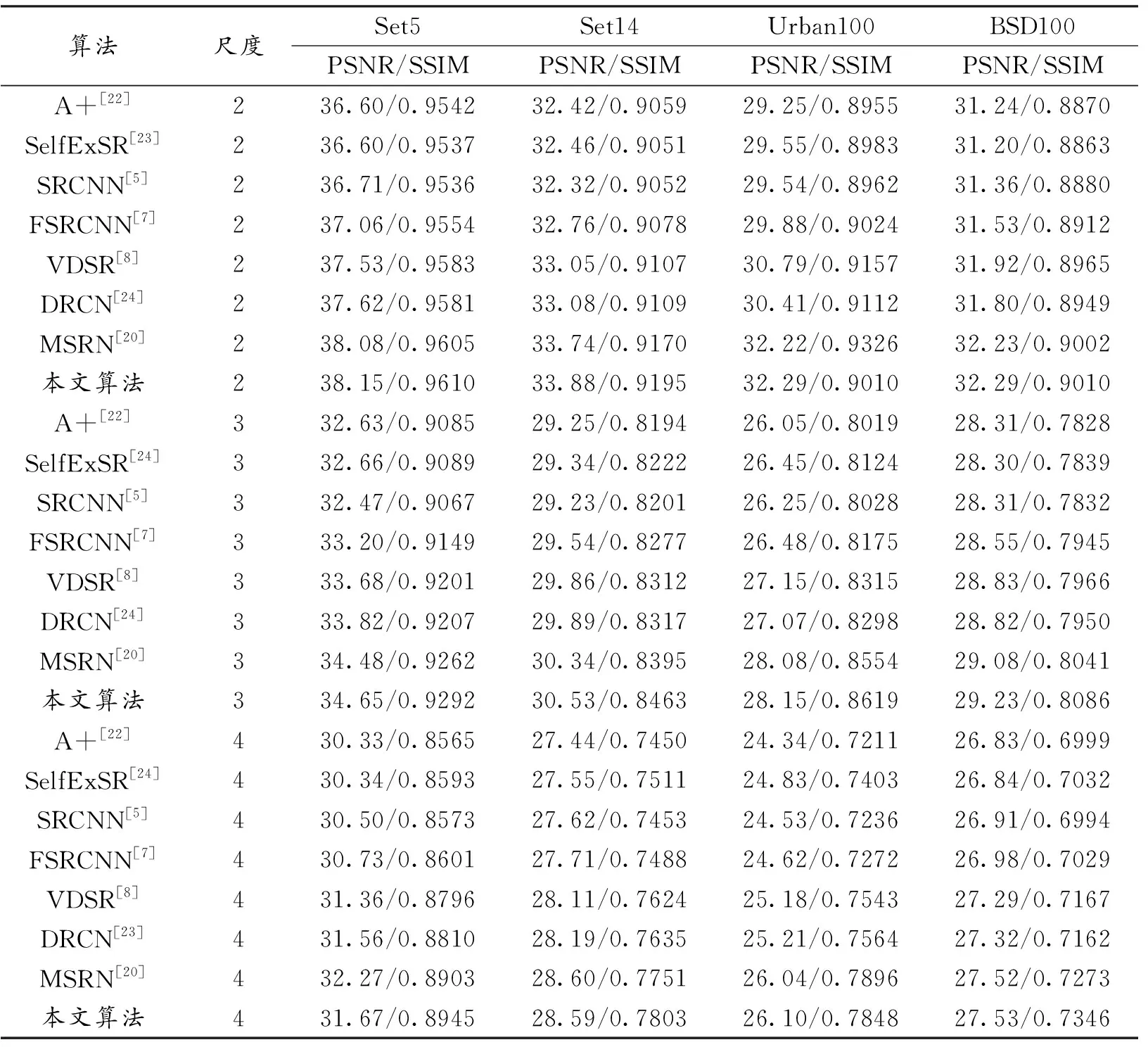
表3 不同尺度图像超分辨重建结果
由表3中的结果可知,本文提出的MSPFN方法在不同数据集进行放大2倍和3倍时,无论是PSNR还是SSIM的结果均优于其他7种算法。尽管在放大4倍时在个别数据集上的性能指标略低于MSRN算法,但综合所有数据集上的性能指标,本文所提出的方法具有最好的重建性能。
3 结论
本文提出了一种基于多尺度渐进融合的超分辨网络模型,该模型首先将生成的多尺度高斯金字塔图像输入到CFM对多尺度的图像进行特征提取并融合。然后利用FFM进一步对CFM中的特征进行整合,并且在FFM模块中引入通道注意力机制。通道注意力机制不仅可以选择性地学习不同尺度的特征,而且可以有效地减少特征冗余。此外多个FFM以级联形式形成渐进的多尺度融合。最后通过RM模块将来自CFM模块和FFM模块中的特征进行有效融合,从而重建出高质量的超分辨图像。与其他七种主流的超分辨算法的对比实验结果表明,所提出的基于多尺度渐进融合网络的超分辨方法能重建出主、客观质量评价方面更好的超分辨图像。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
