
基于文本信息补充的图像描述模型
2021-12-08 01:57仪秀龙郑杜磊王志余
山东科技大学学报(自然科学版) 2021年6期
花 嵘,仪秀龙,郑杜磊,王志余
(1.山东科技大学 计算机科学与工程学院,山东 青岛266590;2.山东省青岛市黄岛区第一人民医院,山东 青岛 266555)
自动生成图像的描述是计算机视觉的一项基础任务,其目的是识别图像内突出的目标、理解目标之间的关系,最终以人类可以理解的自然语言对其进行表达。自然语言与机器语言的巨大差异使得图像描述成为一项困难的任务,但其在图像视频检索、协助视障群体感知环境等领域具有广泛的应用价值,吸引了学术界和工业界的广泛兴趣。图像描述任务作为跨学科领域的交叉研究问题,将计算机视觉与自然语言处理联合起来,其目标是自动生成图像的描述,难点在于要使计算机“看到”可见的目标并“理解”不可见的目标关系,难度超过图像分类和目标检测。
机器翻译任务采用编码解码的框架,利用循环神经网络(recurrent neural network,RNN)进行编码及解码,最大化P(S|T),将源语言中的语句T转化为目标语言的语句S。受其启发,图像描述任务考虑到卷积神经网络强大的图像特征提取能力,选择卷积神经网络(convolutional neural network,CNN)作为编码器,RNN作为解码器。长短时记忆(long short term memory,LSTM)[1]因具有良好的解决梯度消失的能力成为解码器的首选。LSTM创造性提出了“门控”思想,依靠记忆单元和遗忘门可以有选择地记忆和遗忘信息,但门控结构对信息的筛选会导致信息的遗失,使LSTM隐藏单元的表达能力不足。LSTM隐藏单元表达能力不足会产生两个问题:一是输入信息缺失,二是预测信息不充分。本研究针对LSTM对文本信息的提取问题,提出两种文本信息补充模型,两种模型均强调文本信息在模型中起到的重要作用。
1 相关工作
近年来,研究者们提出了很多生成图像描述的方法,主要分为以下3类:①基于模板的方法。利用固定的模板和空白槽来生成标题,把检测到的对象、动作、属性对空白槽进行填充。例如,Kulkarni等[3]在填补空缺之前利用条件随机场来预测对象以及属性,Li等[4]利用提取与检测到的对象属性及相关关系的句子来生成图像的描述。该类方法可以生成语法正确的标题,但由于模板是预定义的,因此生成标题较为死板,不具备良好的泛化性;②基于检索的方法。把视觉上相似图像的标题作为候选标题,从候选标题中选择并进行简单调整以生成目标标题[5-7]。此类方法可以生成较为灵活的描述,但过于依赖现有的人工描述,难以生成新颖的描述,同样不具备良好的泛化性,并且该方法需要收集大量且全面的人工描述,训练集也需要多样化;③基于神经网络的方法。该类方法受到机器翻译的启发,将图像描述视为从图像到文本的翻译任务,利用LSTM作为解码器,克服上述两类方法的局限性。深度神经网络在计算机视觉、自然语言处理等领域得到广泛应用,并取得了突出的成果。
注意力机制在目前主流的深度神经网络方法中得到了广泛应用,其核心目标是从众多信息中选择出对当前任务目标最关键的视觉信息。Xu等[8]将Soft-Attention应用在图像描述任务中,让模型在预测某个单词时,将视觉的重点放在图像的某一部分而不是整幅图像。Lu等[9]提出的Adaptive Model让模型进行预测时判断依赖文本信息或是视觉信息。Anderson等[10]提出的Bottom-Up and Top-Down Attention将候选图像特征变为用目标检测之后得到的属性特征。Wang等[11]提出的Hierarchical Attention使注意力可以同时在多个特征上进行层次计算。You等[12]提出Semantic Attention,使模型能够最大化的获取语义信息。以上模型基于LSTM提取文本信息,使用注意力机制对模型注入视觉信息,模型性能取决于对视觉信息的利用,但均忽视了文本信息的重要作用。
为了解决LSTM隐藏单元表达能力不足导致的两个问题,本研究提出两种基于文本信息补充的图像描述模型:一种输入信息补充(input information supplement,IIS)模型,利用信息提取函数提取更多的文本信息作为输入,赋予LSTM更多的输入信息,解决LSTM的输入信息缺失问题;另一种输出信息补充(output information supplement,OIS)模型,通过信息提取函数,在多个时间步的隐藏单元中获取所需要的预测信息,解决LSTM预测信息不充分问题。最后,在Neural Image Caption[2]的基础上,实现了上述两种模型并评估了两种模型的有效性,实验证明,两种模型均可以明显提高各项评价指标。
2 基于文本信息补充的图像描述模型
为解决现有的LSTM存在的输入信息缺失和预测信息不充分问题,本研究在Neural Image Caption[2]的基础上,提出两种基于文本信息补充的图像描述模型。
2.1 图像描述的传统encoder-decoder架构
先介绍用于图像描述的传统encoder-decoder架构,模型结构见图1。主要计算公式如下:
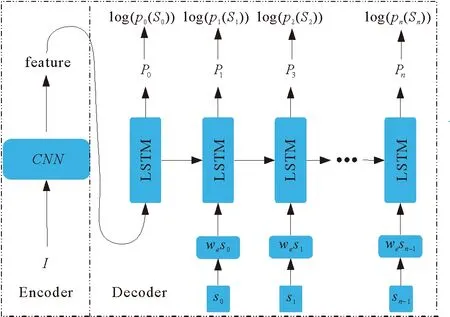
图1 图像描述的传统编码解码模型Fig. 1 Traditional encoding and decoding model of image description
x-1=CNN(I),
(1)
xt=WeSt,
(2)
Pt+1=LSTM(xt)。
(3)
其中:I代表输入的图像,图像经过卷积神经网络得到特征向量,并作为解码器的第一次输入,用来告诉解码器图像的内容;每个词汇St用one-hot向量表征,向量的维度等于词典的大小,但由于词汇向量的维度太大,研究者将词汇通过词嵌入We映射到低维度空间,得到每个时间步的输入xt;Pt+1为模型在每个时间步得到所有单词的概率分布。
采用如下损失函数描述预测标题与人工标题的差别:
(4)
通过对卷积神经网络、词嵌入、LSTM的所有参数进行优化,使上述损失最小。
2.2 基于文本信息补充的图像描述模型
通过公式(5)用端到端的方式最大化给定图像的正确描述概率:
(5)
其中:S代表图像的描述,I代表图像,θ代表需要学习的参数。理论上图像描述的生成过程如下:
(6)
以链式规则计算S0,…,Sn上的联合概率。实际操作中使用RNN对式(6)进行建模:
ht=RNN(St-1,ht-1),
(7)
p(St|St-1…S0)=p(St|ht)。
(8)
即
p(St|St-1…S0)=p(St|St-1,ht-1)。
(9)
RNN在时刻t得到了St-1的信息,St-1,…,S0的信息是通过RNN的隐藏状态ht-1进行表达的。考虑到LSTM具有良好的解决梯度消失的能力,研究者将RNN替换为LSTM。LSTM提出了“门控”的思想,通过输入、输出、遗忘门来获得所需要的信息。LSTM核心公式如下:
it=σ(Wixxt+Wihht-1),
(10)
ft=σ(Wfxxt+Wfhht-1),
(11)
ot=σ(Woxxt+Wohht-1),
(12)
ct=ft⊙ct-1+it⊙tanh(Wcxxt+Wcfht-1),
(13)
ht=ot⊙ct。
(14)
LSTM模拟人类大脑的遗忘记忆过程,其记忆由前一时刻的记忆经过遗忘处理和当前时刻的输入信息组成。门控结构使得LSTM可以对信息进行有选择的筛选,解决了梯度消失和长期依赖问题,但门控结构对信息的筛选会导致信息遗失,使得LSTM隐藏单元表达能力不足,进而使得LSTM输入信息缺失和预测信息不充分。事实上,在t时刻可以直接得到前K个状态的信息而不需要通过LSTM的记忆单元。通过信息提取函数f1提取K个状态的信息,作为对记忆单元的补充信息输入LSTM,图像描述的IIS 模型为:
Si=WeSi,
(15)
xt=f1(St-k,…,St-1),
(16)
ht=LSTM(xt)。
(17)
式(16)中采用的信息提取函数f1为拼接函数,即:
xt=[St-k,…,St-1]。
(18)
本研究提出的IIS模型结构见图2。考虑到t时刻的输出最可能与t时刻之前的K个状态有关,将这K个状态用信息提取函数f1提取所需要的信息后作为输入。通过使用更多时间步的文本信息,解决由门控结构导致的LSTM输入信息缺失问题。IIS证明了记忆单元会遗忘之前时刻的记忆信息,使得LSTM隐藏单元信息缺失,那么利用LSTM的隐藏单元进行预测必然是不合理的。为此考虑通过信息提取函数提取更多时间步的隐藏单元信息来进行信息补充,为模型的预测提供充足的信息,保证模型预测的准确性。

图2 输入信息补充模型结构图Fig. 2 Structure diagram of IIS model
OIS模型结构图见图3,具体计算方式如下:在t时刻得到当前时刻及之前时刻共L个隐藏单元值,通过信息提取函数f2来获得这L个时间步的信息,得到OIS补充模型:
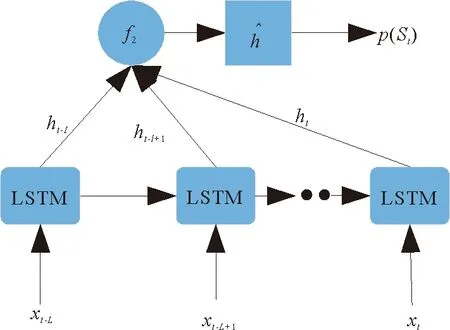
图3 输出信息补充模型结构图Fig. 3 Structure diagram of OIS model
(19)
(20)
式(19)采用的信息提取函数f2也是拼接函数,即:
(21)
可见,OIS模型通过更多的隐藏单元进行预测,可以较好地解决LSTM预测信息不充分问题。
3 实验
3.1 实验细节
在2017年提出的人为标注的AI CHALLENGER大规模中文数据集上分别评估了本研究提出的两种模型。该数据集有训练集21万张图片,验证集3万张图片,每张图片有5个描述。去除出现次数低于2次的词汇,最终得到9 813个词汇,使用BLEU1-4[13]、CIDER[14]、ROUGE-L[15]等不同的度量指标来评估,并与其他经典模型进行比较。为更好地与各种经典模型对比,所有实验都采用同样的参数。用预训练的Resnet-50[16]来获得图像的2 048维特征向量,并将其投影到一个新的维数为256的空间,这也是解码器双层LSTM的隐藏单元维数,在训练过程中使用的目标函数为交叉熵损失函数[17],使用ADAM优化器,学习率设置为0.001,权重衰减设置为0.000 1,批量大小设置为64,Epoch设置为40。两种模型在单个NVIDIA-Tesla K80 GPU上训练大约34 h。
3.2 定量分析
3.2.1 IIS模型
针对由遗忘门所导致的LSTM输入信息缺失问题,上节提出了一种IIS模型,利用信息提取函数提取K个词向量的文本信息作为LSTM的输入。为找到最理想的K,进行了实验,结果见表1。
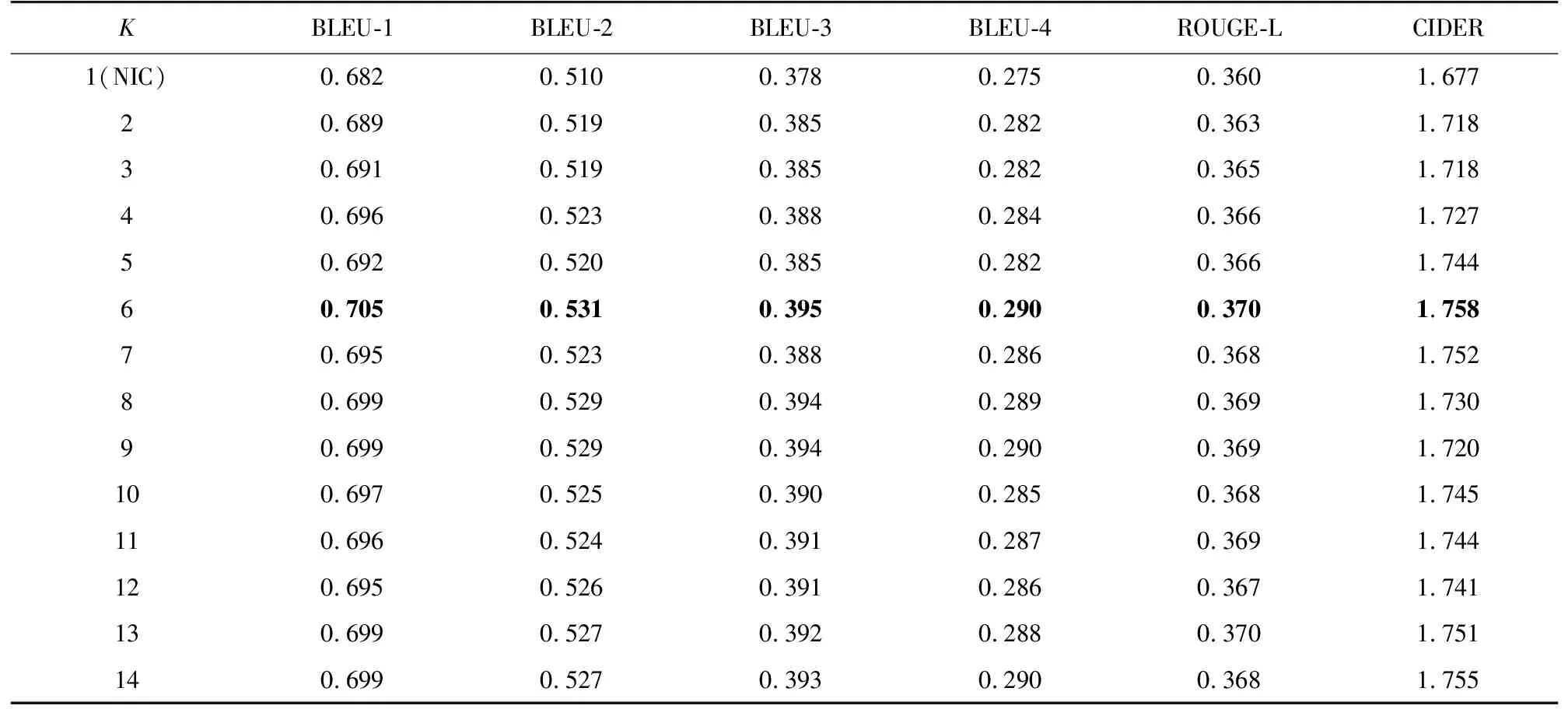
表1 LSTM各阶输入信息补充模型指标Tab. 1 Input information of each order of LSTM complements the model indexes
数据集的句子长度大多在15左右,为避免取到局部极值,进行了所有时间步的实验。由表1看出,随着K的增加,LSTM IIS模型在各指标上的表现越来越好,证明LSTM存在重要信息缺失,通过增加更多文本信息作为LSTM的输入,可以解决LSTM输入信息缺失问题;K=6时,模型性能达到顶峰;当增加过多的文本信息即K>6时,信息冗余对模型产生误导,导致K取更大值时,模型在各指标上的表现反而有所下降。故取K=6。
3.2.2 OIS模型
第二节针对用来预测的LSTM隐藏单元存在的信息缺失问题,提出了LSTM OIS模型,利用信息提取函数提取L个时间步的隐藏单元信息进行预测。通过实验找到最理想的L,完整的实验数据见表2。

表2 LSTM各阶OIS模型指标Tab. 2 Output information of each order of LSTM complements the model indexes
为避免取到局部极值,与IIS模型类似,OIS模型实验也取了所有时间步的值。由表2可以看出,当L=7时,OIS模型可以获得最好的实验效果。实验结果证明,通过采用更多的隐藏单元信息可以解决LSTM用来预测的隐藏单元信息缺失问题。
3.2.3 实验结果与分析
将本研究提出的模型与几种经典的图像描述模型进行性能对比,结果见表3。
由表3可以看出,IIS模型和OIS模型在原模型NIC的基础上, 性能都有了较大的提升。其中IIS模型效果更是超越了几种经典的注意力机制模型。因此,图像描述同时依赖文本信息与视觉信息,LSTM的信息缺失问题带来的性能瓶颈可以通过文本信息补充模型解决。
3.3 定性分析
为了对本研究得到的模型效果进行定性分析,对6个图像分别利用3种模型进行对比(如图4)。
由图4可见,本研究提出的IIS模型由于采用更多的文本信息作为输入,模型获得更丰富的输入信号,生成的描述更加精细、饱满。图片中的草原、大厅、足球场、球场、男人等词汇前都有形容词来修饰。本研究提出的OIS模型,由于用更多时间步的隐藏单元信息进行预测,预测更加准确,对图片中的典型目标如草原、帽子、骑马、挎包、大厅、女人、四个、足球场、踢足球等都很好进行了识别。

图4 三种模型生成的描述对比Fig. 4 Comparison of the descriptions generated by the three models
3.4 讨论
将IIS模型与OIS模型联合起来得到联合模型,模型结构图见图5。
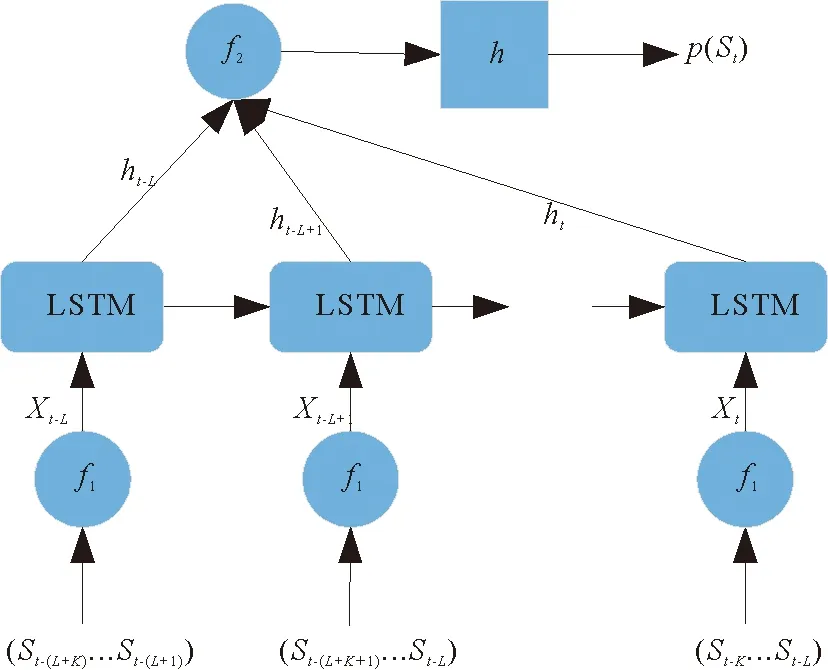
图5 IIS+OIS联合模型结构图Fig. 5 IIS+OIS joint model structure diagram
将表现最好的IIS模型(K=6)分别与各阶OIS模型联合起来进行实验,结果见表4。由表4可以看出,6阶IIS模型与5阶OIS模型联合可以获得最好的效果,该结果比单独使用OIS模型略好,比IIS模型略差,说明联合模型并没有起到很好的促进作用。分析原因是当采用LSTM输入信息补充模型后,由于获得了充足的输入信息,可以较好地进行预测,若此时再使用多个隐藏单元值进行预测,其他时间步提供的无用信息会大于有用信息,对模型产生误导,导致模型的效果不佳。实验结果再次证明信息冗余会导致模型的性能下降。
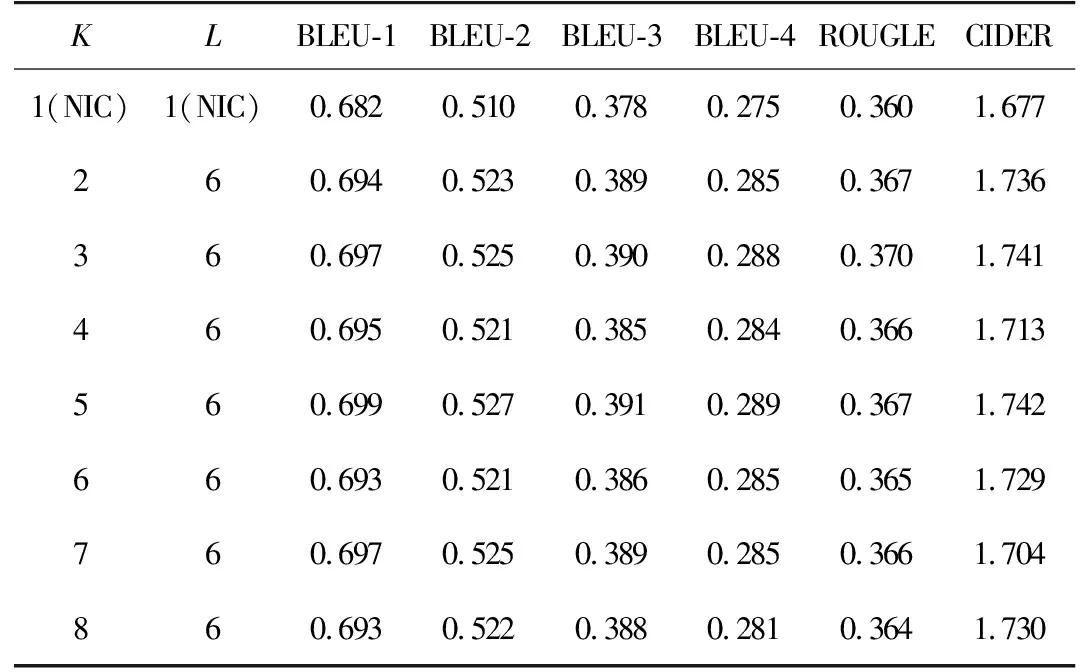
表4 IIS+OIS联合模型实验结果Tab. 4 IIS+OIS joint model experiment results
4 结论
针对视觉信息的缺失问题,目前已提出了众多基于注意力机制的图像描述模型,本研究证明以LSTM作为图像描述的解码器存在文本信息缺失问题,提出了两种基于文本信息补充的LSTM图像描述模型—IIS模型以及OIS模型,用来解决由门控结构所导致的输入信息缺失与预测信息不充分问题。实验结果表明,增加补充信息后模型性能得到提高,但同时,LSTM对补充信息的利用存在上限,在输入词向量达到6个和预测对于隐藏状态的个数依赖达到7个以后,模型性能不再提升反而有所下降,这表明冗余的信息会对模型的学习过程产生误导。该结论在两个模型的结合实验中得到了再次证实。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年7期)2015-10-22
