
动态场景下基于语义和光流约束的视觉同步定位与地图构建
2021-12-07 10:09徐和根张志明齐少华
计算机应用 2021年11期
付 豪,徐和根,张志明,齐少华
(同济大学电子与信息工程学院,上海 201804)
0 引言
随着计算机科学和传感器技术的发展,机器人进入快速发展阶段。同步定位与地图构建(Simultaneous Localization And Mapping,SLAM)是机器人导航与定位的基础技术之一[1]。由于相机具有丰富的场景感知能力和价格低廉等优势,近年来,采用相机作为主传感器的视觉SLAM 受到了广泛的关注[2]。在最近的研究中,大多数SLAM系统都采用了静态场景假设,即假设场景不随时间变化[3]。然而在实际的机器人应用场景中,不可避免地会存在动态物体。同时,为了让机器人完成更复杂的任务,机器人对场景的理解能力受到了研究者的广泛关注[4]。因此,在动态环境下建立更利于机器人理解的语义地图成为一个研究热点。
为了解决动态环境下的机器人定位问题,Fang 等[5]和Wang 等[6]采用光流法过滤场景中的移动物体;Bakkay 等[7]采用基于光流法的改进场景流来过滤移动物体;Zhao 等[8]使用深度图像和多视角几何方法检测动态物体。这些算法对光照等环境变化敏感,鲁棒性较差。深度学习的发展为这个问题带来了新的解决方案。基于卷积神经网络(Convolutional Neural Network,CNN),有许多优秀的语义分割算法被提出,如SegNet[9]、DeepLab[10]、Mask-RCNN(Mask Region-based CNN)[11]等。语义分割算法可以实现图片的像素级分类,从而获得图片中物体的边界以及语义信息。在深度学习的基础上,Zhong 等[12]使用SSD(Single Shot multibox Detector)检测图片中的物体,对于先验标记为动态的物体种类,过滤其上的所有特征点,再进行后续的相机位姿估计。Bescos 等[13]利用Mask-RCNN 和多视角几何方法检测动态物体,并在ORBSLAM2 系统的基础上提出DynaSLAM 算法,通过Mask-RCNN和多视角几何方法检测动态特征点,并将其过滤。Yu等[14]利用SegNet 获取图像中的语义信息,并结合运动一致性检测来过滤动态物体上的动态点,在ORB-SLAM 的基础上提出DSSLAM 算法。这些算法都需要先验性假设哪些种类的物体会发生运动,如人类。在地图构建上,DynaSLAM 建立了稠密的点云地图,不利于机器人的存储与使用,DS-SLAM 建立了语义八叉树[15]地图。
本文针对动态场景下的相机位姿估计以及语义地图构建问题进行研究,主要的工作如下:
1)结合了语义分割和光流,提出了一种新的动态特征点过滤算法,在取得较好的过滤效果的同时降低了对先验知识的依赖性。
2)提出了一种动态环境下的静态语义地图构建算法。在保留主体信息的同时,极大降低了存储空间的需求,能够更好地应用于后续地任务。
在公开的TUM 数据集上将本文提出的算法与ORBSLAM2、DS-SLAM 以及DynaSLAM 作对比,实验结果验证了本文算法的有效性。
1 系统设计
1.1 系统框架
ORB-SLAM2 系统作为目前最为完整、稳定的开源视觉SLAM 系统之一,得到了研究人员的广泛使用。本文所提出的动态场景SLAM 算法也是在该系统框架上进行改进的。图1 是本文提出的SLAM 算法的完整框架,在原有的跟踪、局部建图和回环检测线程的基础上,增加了动态物体检测和语义地图构建线程。图中短虚线框选的部分为本文添加的线程,长虚线框选的部分为ORB-SLAM2 原有线程。首先,摄像机获取的每一帧在进行跟踪线程之前要经过语义分割网络,得到包含物体语义标签的掩模,并联合光流法计算物体的动态概率。局部建图和回环检测线程与ORB-SLAM2 相同。最后,根据本文提出的关键帧选择策略挑选部分关键帧用于构建静态语义地图。本文算法通过物体动态概率去除动态点,建立静态点云图,并利用语义信息更新语义八树图;基于语义分割,对场景中的物体点云进行分割与聚类,建立稀疏语义地图。
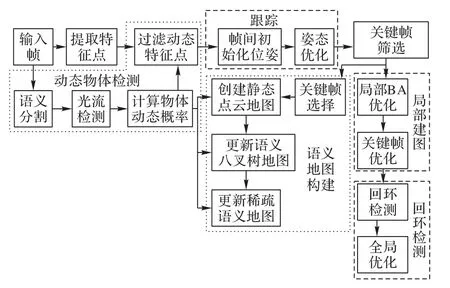
图1 本文算法总体框架Fig.1 Overall framework of proposed algorithm
1.2 动态特征点过滤
本文提出基于语义和光流约束的动态特征点过滤算法,整体框架如图2所示。
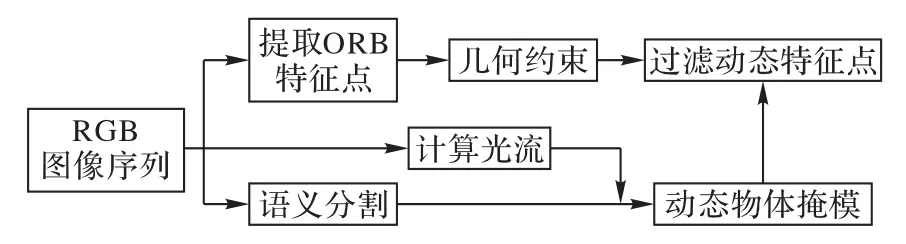
图2 动态特征点过滤算法的框架Fig.2 Framework of dynamic feature point filtering algorithm
该算法首先提取当前帧的ORB 特征,同时通过语义分割网络得到物体的掩码;接着,采用多视角几何方法初步过滤当前帧中不符合极线约束的特征点;然后,通过滑动窗口法计算出当前帧和5 帧前的稠密光流;最后,结合语义分割与光流得到物体的动态概率。在有人、显示器和椅子的图中,人的动态概率为0.971,显示器的动态概率为0.047,椅子的动态概率为0.014。因为人的动态概率大于阈值0.5,得以确定人是动态物体。对人身上的特征点也进行过滤,得到最终的静态特征点。
1.2.1 语义分割网络
本文采用DeepLab v3语义分割网络。网络采用编解码结构,并通过空洞卷积平衡精度和耗时。
本文在PASCAL VOC 数据集上训练DeepLab v3,该数据集包含20 个类别,如车辆、人类、椅子、显示器等。使用TUM数据集中的RGB 图片进行测试,图3 显示了语义分割算法的结果。其中,红色代表人类,绿色代表显示器,蓝色代表椅子。这些都是室内场景下可能具有移动属性的物体。

图3 语义分割网络的分割结果Fig.3 Segmentation results of semantic segmentation network
1.2.2 几何约束
语义分割网络不能识别场景中的所有物体。为了过滤网络无法识别的物体种类上的动态特征点,本文采用几何约束。对极几何约束是摄像机运动学的重要组成部分,只与摄像机的内参和相机位姿有关,如图4所示。

图4 对极几何示意图Fig.4 Schematic diagram of epipolar geometry
假设相机从不同的角度观测到同一个空间点p。根据针孔相机模型,它在两个图像上的像素坐标x=[u v1]T,即x1、x2符合约束:

其中:K代表相机的内参矩阵;R、T分别表示两个相机坐标系间的旋转与平移矩阵;s表示像素点的深度信息。
在理想情况下,两张图片中匹配的点对的坐标符合约束:
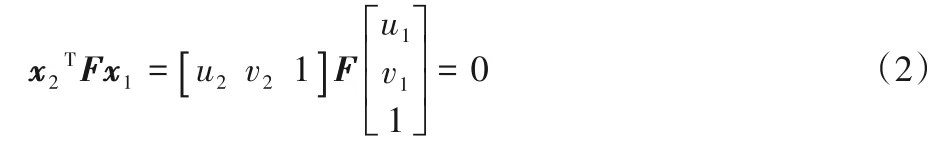
其中,F为基础矩阵(Fundamental matrix)。而在真实的场景下,由于相机采集的照片并非理想图片,存在一定程度的畸变和噪声,使得相邻帧间的点无法完美匹配上极线l:

其中:X、Y和Z为极线的向量。点x2到极线l1的距离D为:

若距离D大于阈值,则认为该点不符合极线约束。有两种原因造成这种结果:首先,这些点本身是不匹配的;其次,这些点存在于动态物体上,这些点随着物体的运动而移动,造成了不匹配,这些点为动态点。因此,过滤所有不符合极线约束的特征点。
1.2.3 光流约束
光流法是运动检测中的常用方法。光流法计算图像序列中的像素在时间域上的变化以及帧间的关联性,从而得出相邻帧中物体的运动关系。光流法主要有以下三个假设:图像中的像素亮度在连续帧间不会发生变化;帧间的时间间隔相对较短;相邻像素具有相似的运动。从而有:

其中:I(u,v,t)代表像素点(u,v)在t帧的光强度。式(5)表明像素点(u,v)在dt时间内移动了(du,dv)像素距离。
U、V定义了光流值在单位时间内横纵坐标下的像素偏移:

由于相机的采样频率较高(通常为30 frame/s),关联的两帧之间物体运动通常不明显,为此,本文采用滑动视窗法,设置视窗为5。前端采集当前帧与5帧以前的图像计算光流场。
本文采用DeepFlow 算法[16]计算稠密光流。由于摄像机的不规则运动会造成前景和背景的同时运动,因此很难判断像素点的偏移是由摄像机运动还是物体运动引起的。如图5所示,直接计算光流时,由于摄像机本身的运动,整个画面都有较大的光流值。为了使光流可视化,每个点的像素值被填充为

图5 直接计算光流的结果Fig.5 Results of direct calculation of optical flow
由于为了尽可能消除背景运动对光流的影响,根据1.2.2 节得到的静态特征点对,采用随机抽样一致算法(RANdom SAmple Consensus,RANSAC)算法,计算两帧间的基础矩阵F。根据基础矩阵,求解前第5帧的射影变换,之后,对变换后的图片计算稠密光流,结果如图6 所示。经过变换后,计算出的光流场基本只包含运动物体,在这两帧中只有部分人体被检测出来。光流的可视化方法和图4相同。

图6 矫正后的光流计算结果Fig.6 Results of optical flow calculation after correction
从图6 中可以看出,利用光流法难以得到物体清晰的轮廓,而采用语义分割的方法难以判断物体是否处于运动状态。本文算法对语义和光流约束进行结合,对于图片中的每一个像素点n,计算其动态概率pn:
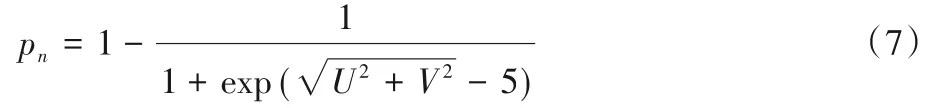
因此对于每一个物体,其动态概率pobj为物体上所有像素点动态概率的平均值:

在没有先验的情况下(事先不指定运动物体的类别),如果pobj>0.5,则认为该物体是动态的,需要对该物体上的特征点进行过滤;否则,则认为该物体是静态的,可以用于后续的跟踪以及地图构建任务。
1.3 语义地图构建
地图构建是SLAM 系统的重要组成部分。在ORBSLAM2 系统中,只构建了基于特征点的稀疏地图,不利于机器人导航等任务的使用。本文算法使用RGB-D 图像,结合语义信息和稠密运动概率,构建静态点云地图,并更新语义八叉树地图,最终构建出稀疏语义地图,便于后续任务的使用。
1.3.1 关键帧选择
对于SLAM 系统来说,视觉传感器传入的图像数量非常多,为了减少系统资源的消耗,ORB-SLAM2 采取选择关键帧的策略方法。但是,这种选择策略是针对ORB-SLAM2 设计的,并不完全适合本文算法的语义地图构建。在本文中,对ORB-SLAM2的关键帧序列进行了二次筛选。
对于关键帧序列,第一帧直接构建地图,后续的每一帧都需要满足以下两个条件:
首先,在一个新的关键帧传入后,计算当前关键帧和前一个地图构建关键帧的相机平移和旋转。当摄像机平移大于0.3 m 或旋转角度大于5°时,将该关键帧加入到地图构建帧序列中,否则跳过该关键帧。
其次,在动态场景中,物体可能会发生移动。当发生移动时,即使摄像机位置保持稳定,也需要更新地图中的物体。采用了常用指标交并比(Intersection over Union,IoU)评测物体检测。在新增加的关键帧Fi与上一帧Fi-1中,计算所有静态物体掩模的IoU:
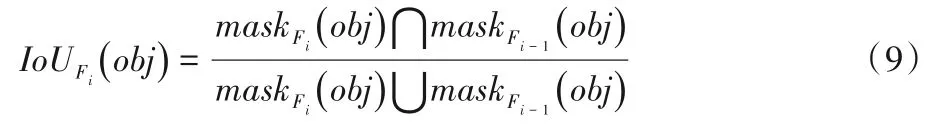
1.3.2 静态点云地图构建
本文在ORB-SLAM2 基础上新增点云构建线程。经过1.3.1 节的关键帧过滤后,得到用于地图构建的关键帧序列。对于序列中的每一帧,利用式(10),结合SLAM 系统在运行过程中获得的相机位置姿势信息和图像的深度值,将点p从图像坐标系转换到世界坐标系中,构建点云。

其中:K代表相机的内参矩阵;R和T分别代表相机的旋转和平移;d代表像素点的深度值;[u v1]T代表点p在图片坐标系下的位置;[a b b]T代表点p在空间坐标系下的位置。
如果地图中包含动态物体,地图将难以使用。在常见的抓取或避障任务中,包含动态物体的地图使得算法难以判断物体是否还存在,障碍物是否可以通过。因此,结合1.3.1 节得到的动态物体掩模以及光流值,对动态物体进行过滤。
对输入图像中的每一个像素点n,如果n是某个物体上的点,那么其动态概率pn=pobj,否则按照式(7)计算。如果pn>0.5,该点被视为动态点,不能用于点云地图构建。从图7中可以看出,经过过滤后的静态点云地图几乎不包含动态点。通过联合多视角下的不同关键帧,对背景进行填充,构建静态点云地图。
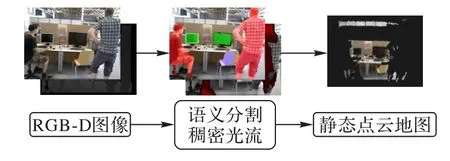
图7 根据动态物体掩膜和光流过滤动态点建立静态点云图Fig.7 Using moving object masks and optical flow to filter out dynamic points for constructing static point cloud map
1.3.3 语义八叉树地图构建
虽然点云的表示方式很直观,但点云图也会存在一些不足。点云地图占用存储空间,而在大部分情况下,很多点的位置信息都是冗余的。点云地图不能直接用于导航任务。因此,本文将点云转化为八叉树地图,构建全局语义八树图。
八叉树地图使用八叉树来存储地图,最小节点大小由分辨率决定。由于存在摄像机的噪声和动态物体等干扰因素,同一个体素在不同时间处于不同的状态。因此,每个体素的占用概率应结合多次观测的联合概率得到:
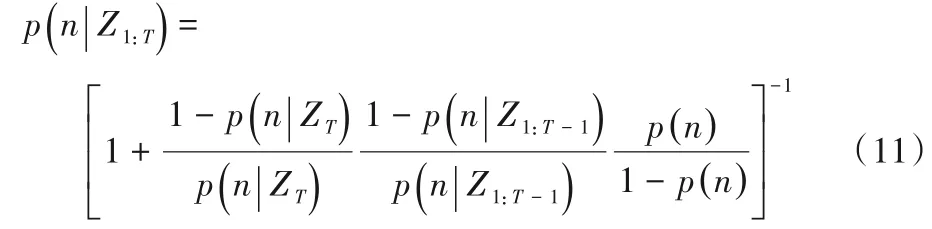
将占据概率进行Logit变换:

体素被占据的更新方式可以表示为:

其中:ZT=1 表示该体素在时间T被观察到,ZT=0 表示该体素在时间T没有被观察到;locc=0.8为预设值。当一个节点被反复观察到时,其体素的占用概率会增加,与此同时,其语义信息也被赋予,当一个节点没有被观察到时,其占用概率会降低。而动态物体的运动概率越高,其占用概率会降低,反之则会增加。当一个体素的占用概率大于预设阈值(0.8)时,该节点将在地图中显示出来。
1.3.4 稀疏语义地图构建
在某些情况下,系统更关注场景中目标物体。例如,在抓取任务中,机器人手臂更关注待抓取目标的位置信息。为了方便后续任务能够更方便地搜索目标,本文建立了一个稀疏语义地图。
直接对点云进行分割是难以得到准确结果的。基于算法性能的限制,语义分割得到的掩模与物体也并不完全对应,尤其是在物体边界处。在大多数情况下,二维图像中难以精确划分的物体边界在三维空间中距离较远,容易区分。因此,本文采用了一种基于语义分割的点云分割方法。该方法的步骤如下:
步骤1 利用关键帧投影到世界坐标构建三维点云;
步骤2 对构建的点云进行体素化滤波,过滤由图片噪声产生的点云;
步骤3 根据点云和图片的对应关系,将语义信息绑定到点云中;
步骤4 基于语义信息对点云进行欧氏聚类,分割出每一个物体。
基于语义分割的点云分割结果如图8所示。

图8 基于语义分割的点云分割结果Fig.8 Point cloud segmentation results based on semantic segmentation
为了更简单地表示物体,针对每一个物体的点云,通过主成分分析(Principal Component Analysis,PCA)获取特征向量,构建方向包围盒(Oriented Bounding Box,OBB)。通过具有方向性的最小包围盒表征物体,它很容易用于导航中的碰撞检测等任务,结果如图9(a)所示。
在得到每一类物体的边界框后,根据1.3.3 节得到的物体动态概率,去除动态物体。如果pobj>0.5,则算法认为该物体是动态的,不能添加到地图中。在这一帧中,pchair=0.03,pmonitor=0.07。因此,判断人是动态物体,将其过滤掉。如图9(b)所示,利用显示器和椅子的边界框来构建静态稀疏语义地图。
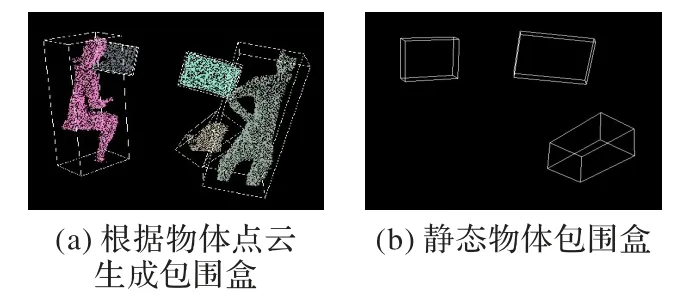
图9 物体包围盒Fig.9 Object bounding box
在动态场景中,物体的位置可能会发生变化,所以需要更新地图中物体的位置。本文算法将稀疏语义地图以物体数据库的形式存放,用于存储物体的类别和位置信息。数据库中包含以下信息:每一个物体的包围框世界坐标和它的物体种类属性。本文算法按照如图10所示的策略更新语义图。
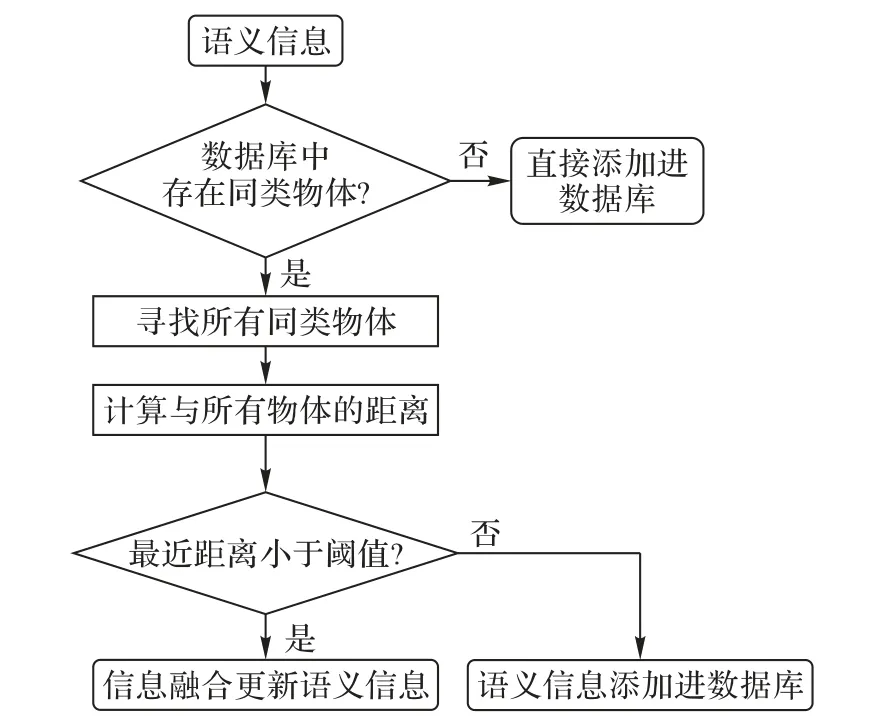
图10 语义地图更新流程Fig.10 Flow chart of semantic map updating
当获得一个新的静态物体语义时,如果数据库中没有同类物体,则直接将新物体添加到数据库中。当数据库中存在同类物体,如果新物体与数据库中所有同类物体边界框没有重合,则将新物体添加到数据库中。如果边界框重合,即与数据库中已有物体距离小于阈值,则算法认为物体发生移动,更新数据库中物体的位置。
2 实验与结果分析
2.1 实验设置
实验主要在TUM 数据集上进行测试,主要包括两个方面:一是SLAM系统的跟踪定位性能;二是地图构建任务。
TUM数据集是用于评估SLAM算法性能的经典RGB-D数据集。它被广泛用于测试SLAM 算法在动态环境下的定位准确性和鲁棒性。该数据集包含39 个不同的序列,每个序列有640 × 480大小的彩色图像、与之匹配的深度图像和摄像机的真实轨迹。其中,相机的真实轨迹是由高速运动捕捉系统确定的,以确保轨迹的准确性。它可以很容易地与SLAM 系统估计的轨迹进行比较,以评估算法的鲁棒性。
本测试运行在一台PC 上,CPU 为AMD 锐龙R52600,内存为16 GB,显卡为NVIDIA 1660。系统环境为Ubuntu 16.04,语义分割网络采用Python3.6 编写,SLAM 主程序使用C++编写。
2.2 定位精度测试
SLAM 系统的定位精度是评价SLAM 系统性能以及鲁棒性的重要部分。本文在TUM 数据集上进行了两类场景的测试,即高动态场景和低动态场景。在高动态场景中,人在场景中持续行走,因此,以下将高动态场景简称为W(walking);在低动态场景中,人坐在椅子上,没有明显的动作,因此,以下将低动态场景简称为S(sitting)。每个场景都包含四种不同的摄像机运动轨迹,分别是halfsphere、rpy、static 和xyz。在halfsphere(以下简称hs)轨迹中,相机沿着半球运动;在rpy 轨迹中,相机进行摇摆、俯仰运动;在static(以下简称s)轨迹中,相机的位置几乎没有变化;在xyz 轨迹中,摄像头沿着x、y和z轴运动。
本文使用绝对轨迹误差(Absolute Trajectory Error,ATE)和相对位姿误差(Relative Pose Error,RPE)来评估算法在定位上的性能。为了更好地反映SLAM 系统的鲁棒性,采用平均数、中位数、标准差(Standard Deviation,SD)和均方根误差(Root Mean Square Error,RMSE)作为评价指标。其中:平均数和中位数可以更直观地显示误差的整体情况;而标准差可以更好地反映系统的稳定性;RMSE 对异常值比较敏感,可以反映系统的鲁棒性。表1 为轨迹绝对误差,表2 为RPE 的平移误差,表3为RPE的旋转误差。
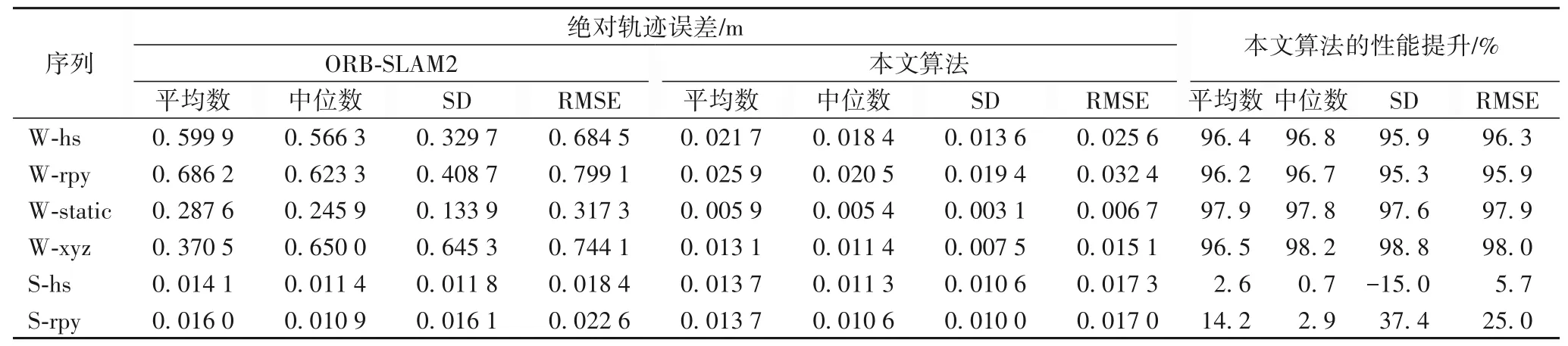
表1 绝对轨迹误差结果比较Tab.1 Result comparison of absolute trajectory error
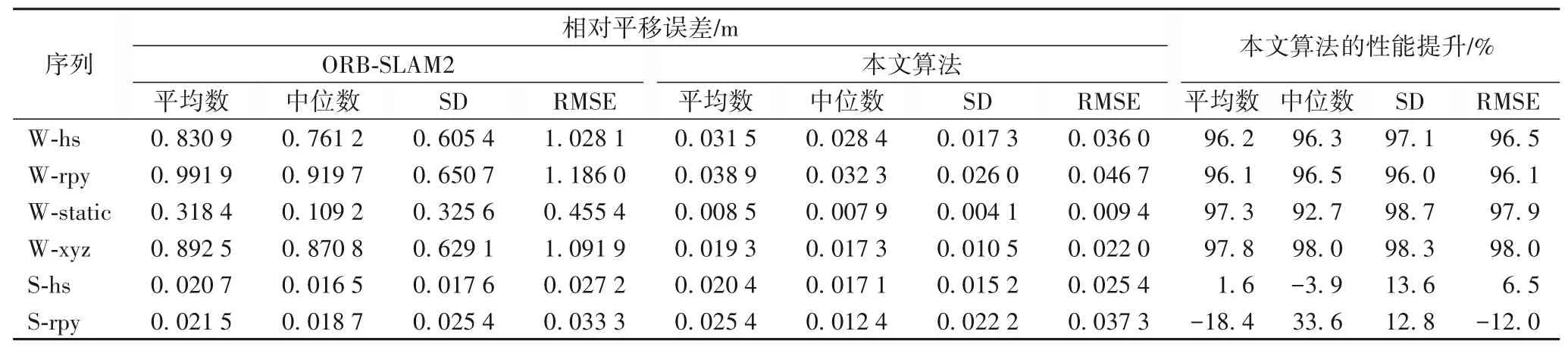
表2 相对位姿误差的平移误差结果比较Tab.2 Result comparison of translation error of relative pose error
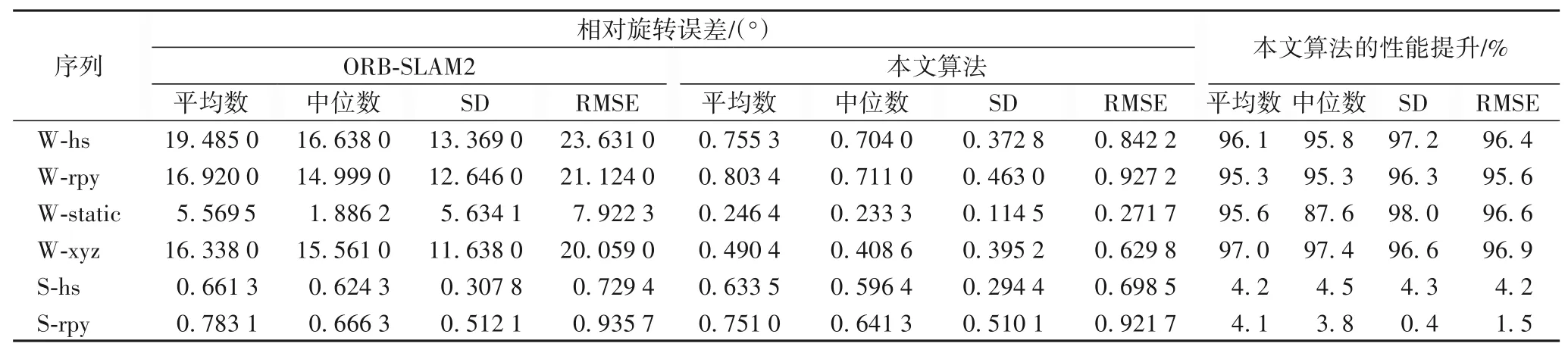
表3 相对位姿误差的旋转误差结果比较Tab.3 Result comparison of rotation error of relative pose error
表1~3 中,W 代表高动态场景,S 代表低动态场景,hs、rpy等分别代表对应的运动轨迹。W-hs 即代表在高动态场景下,相机以halfsphere 的轨迹进行运动,其余的命名方式以此类推。通过对ATE和RPE的评估,从表1~3中可以看出,本文所提出的算法在高动态场景下的性能相较ORB-SLAM2 有很大的提升。性能的提升Adv计算方法如式(15)所示:
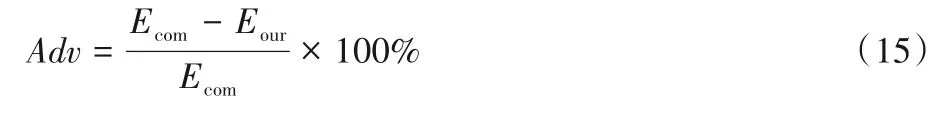
其中:Ecom表示用于比较的算法的误差;Eour表示本文所提出算法的误差。从表1~3 中还可以看出,在所有的高动态场景中,本文算法都有95%以上的提升。在W-xyz轨迹中,相机大范围的运动,场景中的人也在不断移动,这对SLAM 系统来说是一个很大的挑战。在W-xyz 轨迹的一些评价指标中,本文算法相较ORB-SLAM2减小了98%的误差。
在低动态场景中,由于ORB-SLAM2也具有一定的动态特征点过滤能力,本文算法表现与ORB-SLAM2相似。
同时,还将本文算法与最先进的动态场景下的SLAM 算法,即DynaSLAM 和DS-SLAM 在高动态场景下对系统的定位性能进行了比较,以ATE的RMSE作为比较项。
在实验室环境中,对本文算法进行测试。由于没有TUM数据集中的高速运动捕捉相机,难以确定相机的真实位姿,本文控制相机在实验室场景中沿着标准的矩形行走,矩形的大小为4 m×4 m。如图11所示,场景中有人员在不断走动。

图11 实验室环境图片Fig.11 Photograph of laboratory environment
DynaSLAM 和DS-SLAM 算法的性能采用其原文中的数据,对比结果如表4 所示。从表4 可以看出,本文算法在所有数据集中的定位误差都小于DS-SLAM;在W-rpy 和W-xyz 轨迹中,相较于DynaSLAM 有一定的定位性能提升。对比算法都需要先验地指定场景中的运动物体种类,而本文的算法无需先验知识,也能实现较好的性能。
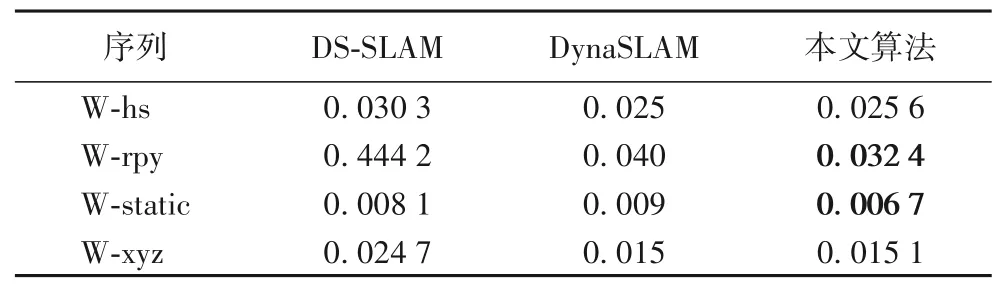
表4 不同算法的绝对轨迹误差对比 单位:mTab.4 Comparison of absolute trajectory error of different algorithms unit:m
图12 显示了ORB-SLAM2 和本文算法在高动态场景下估计的轨迹。ORB-SLAM2 简称为ORB,W-hs-ORB 表示ORBSLAM2 算法在高动态场景下,算法对hs 轨迹的估计结果,其他图片的命名规则相同。图中,黑色线条是真实的轨迹(ground truth),红色线条(深灰)是SLAM 系统估计的轨迹(estimated),蓝色线条(浅灰)是估计轨迹与真实轨迹之间的误差(difference)。
从图12 可以看出,ORB-SLAM2 算法在高动态场景下,估计轨迹与真实值有较大的误差。相比之下,本文算法与真实轨迹更加接近,可以有效去除动态环境下的干扰,鲁棒性较好。

图12 不同算法在高动态场景下估计的轨迹对比Fig.12 Comparison of trajectories estimated by different algorithms in highly dynamic scenes
不同算法估计的轨迹结果如图13 所示。由于缺少实际轨迹的绝对世界坐标,算法的性能难以量化。但从图13 中可以看出,与ORB-SLAM2 相比,本文提出的算法估计的轨迹更接近4 × 4的矩形,算法在真实环境也有较好的表现。
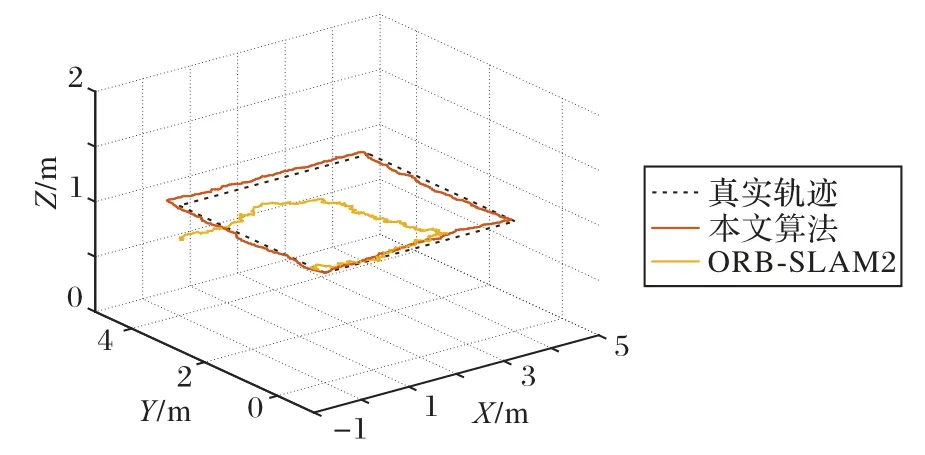
图13 实验室环境下不同算法估计的轨迹Fig.13 Trajectories estimated by different algorithms in laboratory environment
2.3 运行时间
本文在ORB-SLAM2 的基础上新增了动态物体过滤以及语义地图过滤线程。由于地图构建只对关键帧作处理,且该线程与主线程并行执行,对算法运行效率影响不大。对于每一帧输入图像,动态物体过滤线程每一模块的运行时间如表5所示。
从表5 中可以看出,对于算法的实时性影响最大的是语义分割模块。在目前的测试平台下,算法还无法实现实时检测。在未来,更换硬件条件更好的测试平台或采用高精度且快速的语义分割网络,系统的实时性可以得到进一步提升。

表5 不同模块的运行时间Tab.5 Running times of different modules
2.4 建图测试
本文算法构建了三种类型的地图,分别是点云地图、语义八树地图和稀疏语义地图。本节将会构建三类地图并进行评估。由于本文的算法主要针对高动态场景,所以本节只对算法在高动态场景下的性能进行比较。
2.4.1 点云地图
在本节中,测试了三种方法的地图构建性能,分别为:直接根据ORB-SLAM2 建立点云地图,根据光流过滤动态物体,以及本文的基于语义和光流约束的静态点云构建算法。数据集的表示方法和前文相同,ORB-SLAM2 简称为ORB,OF 代表只用光流过滤动态点。从图14 来看,本文算法构建的地图更接近真实场景,而由ORB-SLAM2 构建的地图有很多动态点。在W-static(W-s)轨迹中,摄像机位置相对固定,在ORBSLAM2 构建的地图中可以看到背景的大致轮廓。由于光流难以得到物体的完整轮廓,使得只使用光流时无法过滤掉所有的动态点,其结果如图14(b)、(e)所示,地图中仍可以看到人体。本文算法利用语义约束提供了更好的物体边界分割,使得过滤大部分动态点成为可能。从图14(c)、(f)中可以看出,本文算法建立的点云图几乎不包含动态点,可以更好地表现静态场景。

图14 稠密点云地图Fig.14 Dense point cloud map
2.4.2 语义地图构建
动态场景下生成的语义八叉树地图如图15(a)、(d)所示。为了便于可视化,代表显示器的体素用绿色显示,而代表椅子的体素用蓝色显示,其余体素显示物体本身的颜色。图中不存在典型的动态物体如人类,说明较好地完成了静态地图的构建工作。从图中的体素颜色覆盖区域可以看出,显示器部分体素的语义得到较好的赋予,可以从图中识别出来,但椅子部分相对较差。这主要是因为语义分割网络不能很好地分割出椅子。本文分割网络在VOC 数据集上进行训练,其中的椅子与TUM 数据集中的椅子差异较大,这使得算法对于椅子难以得到较好的分割结果。

图15 语义地图Fig.15 Semantic map
基于点云图和语义信息,本文生成了一个稀疏语义地图,如图15(b)、(e)所示。图中绿色(浅灰)包围框代表显示器,而蓝色(深灰)包围框代表椅子。该图可以更直观地了解物体的位置。由于缺乏数据集中的物体真实位置信息,本文将目标的三维包围框以覆盖在点云图的形式展示,可以用来直观地了解检测的准确性,如图15(c)、(f)所示,显示器的边界框相对准确,而椅子的边界框只包含椅子的一部分,主要原因是在语义分割网络中很难获得椅子的准确像素级分割。如果对于场景中的物体有完整的数据集可以供网络有监督地学习,算法的性能可以得到一定程度的提升。
稀疏的语义地图在保留主要信息的同时,可以极大降低存储空间的要求,地图文件的存储需求如表6所示。从表6中可以看出,相较点云地图,八叉树地图所需的存储空间显著降低,而本文建立的稀疏语义地图存储空间进一步减少,更有利于嵌入式系统的存储。
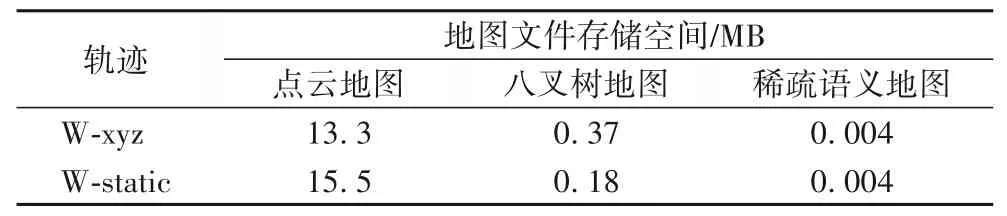
表6 地图文件存储空间对比Tab.6 Comparison of map file storage space
3 结语
为了减少动态物体对SLAM 系统的干扰,本文提出了一种针对动态环境的更为鲁棒的视觉SLAM 算法。该算法建立在ORB-SLAM2的基础上,利用语义和光流约束来过滤动态物体。首先,利用语义分割网络来获取帧中每一类物体的像素级掩码;然后,通过光流匹配得到每个物体的动态概率,动态概率高的物体将被过滤。在公共TUM 数据集上对本文算法以及其他先进的SLAM 算法进行对比,验证了本文算法在高动态场景下具有更好的定位精度和鲁棒性。在地图构建方面,本文构建了静态点云图、语义八树图和稀疏语义图。实验结果表明,本文算法有效地过滤掉了动态物体,构建了静态地图。同时,构建的稀疏语义地图在保留主要信息的同时,极大降低了存储空间的要求。但是本文算法的性能受到语义分割结果的影响,不准确的分割结果将对后续工作产生不利影响。在以后的工作中,考虑采用点云分割网络来提高分割结果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
现代计算机(2022年4期)2022-04-24
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
软件导刊(2018年4期)2018-05-15
电脑知识与技术(2017年3期)2017-03-27
现代电子技术(2016年24期)2017-01-19
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
