
不规则任务在图形处理器集群上的调度策略
2021-12-07 10:09汤小春潘彦宇李战怀
计算机应用 2021年11期
平 凡,汤小春*,潘彦宇,李战怀
(1.西北工业大学计算机学院,西安 710129;2.工信部大数据存储与管理重点实验室(西北工业大学),西安 710129)
0 引言
随着制造工艺的进步,计算机体系架构发生了巨大变化,从单核处理器架构逐步演变为多核处理器架构。然而进入信息时代后,需要处理的计算也呈指数增长。面对海量数据存储和计算,中央处理器(Central Processing Unit,CPU)难以满足计算需求,图形处理器(Graphics Processing Unit,GPU)由于其性能/成本效率比的优势被广泛使用。现阶段,CPU-GPU异构系统成为高性能集群的主流模式,CPU 和GPU 属于不同类型的计算资源,分别负责不同类型的计算任务。CPU 负责执行复杂逻辑处理和事务处理等计算,GPU 相较于CPU 具有众多计算单元和简单的缓存结构,更适用于密集型的大规模数据并行计算,两者相互配合能够极大提升数据处理的计算速度[1]。
虽然GPU 可以提高大多数通用任务的计算性能,但是实际生产环境中经常存在大规模的有限并行性作业,例如在线传感器的过滤、交通摄像头画面的质量检测等。这些作业的并行度一般由注入数据的大小决定,计算复杂度由任务的计算模式决定。它们的最大特点是线程数一般小于1024,需要的存储大小不超过2048 MB,任务与任务之间基本没有依赖关系,这类任务被称为不规则任务。针对这类大规模的不规则任务集合,如何减少任务的处理时间和提高GPU 资源利用率,是目前迫切需要解决的问题。
然而,现有的多数研究着重于将这类程序从CPU 移植到GPU 上进行,从而获取程序并行化带来的性能提升。由于GPU 和CPU 体系架构的不同,现有的任务调度方法并没有充分利用整个集群上GPU 之间的并行能力和GPU 处理器自身的并行能力,造成了GPU 计算资源的浪费,使得系统整体吞吐量并没有大幅提高。
根据GPU 体系结构的特点,其性能/成本效率比的优势会随着计算任务并行度降低而降低。针对大规模的不规则任务集合,Parboil2 的测试结果显示,传统调度方式在GPU 资源方面的平均利用率只有20%~70%[2]。本文分析了现有的针对GPU 集群中调度不规则任务集合的策略,发现其未充分考虑GPU 计算特性、需求不规则特点以及如何实现GPU 共享等关键问题,从而导致系统的资源利用率不高。
针对使用GPU 集群加速大规模不规则独立任务集合的调度问题,本文提出了一种新的调度框架GSF(GPU Scheduling Framework),采用统一计算设备架构(Compute Unified Device Architecture,CUDA)流并行以及GPU 显存细粒度共享的方式,使得不规则任务能够在CPU-GPU 异构高性能集群上高效地调度执行。模型的输入为一组并行度有限的不规则独立任务,任务数目可达到上千,每个任务具有独立计算数据并且GPU 计算资源的需求(包括显存、线程等)均已知。GSF采用参数传递的方法将CPU线程与CUDA流[3]绑定,通过指定流编号将CPU 线程启动的核函数添加到对应流中执行,在同一GPU 上形成了多任务并行的执行流水线,有效实现了任务级别的并行和GPU 资源利用率的提升。然后,在模型基础上,设计并实现了一种适配不规则独立任务的调度算法,通过任务分组的方式合并不规则任务并调度到满足资源需求的GPU 设备上执行,以提升GPU 显存利用率。最后,利用测试程序与现有调度算法进行比较以验证本文所提出的调度策略的可行性和有效性。
1 相关工作
已有研究工作表明,异构集群中GPU 任务的有效调度对于提高资源利用率和最小化执行时间至关重要。文献[4-5]分别设计了运行时的多任务调度框架,实现多任务共享GPU资源,但这些解决方案只关注单GPU 调度问题,无法扩展到集群环境中。文献[6]为解决GPU 低利用率问题提出以线程束为基本单位虚拟化和动态调度GPU 的计算核心,通过持续运行一个内核守护进程实现高利用率,但这种方法同样无法扩展到集群环境。文献[7]针对云环境运行执行时间较短的GPU 任务问题,提出了一种基于优先级的非抢占式先入先出(First In First Out,FIFO)任务调度策略,能够减少平均响应时间和总执行时间,然而这种方法没有实现多任务共享GPU,对资源利用率提升效果不明显。一些研究工作[8-9]试图通过改进硬件设计来提升GPU 资源利用率,比如文献[8]动态地定制线程束以减少不规则应用带来的影响,这些方法都很难立即部署在现有GPU 上使用。因此,通用软件方法[10-14]是解决问题的关键。文献[11]分析了现有研究中调度不规则任务时忽略的关键因素,提出了一种两级任务调度模型以实现在所有GPU 上计算资源的统一分配和共享,同时将计算数据重合的任务合并为任务组进行调度。这种模型能解决不规则任务带来的负载不均和资源利用率低的问题,但调度大量独立任务的效果并不突出。
异构集群中的任务调度可根据是否存在相互依赖关系分为独立任务调度和关联任务调度,独立任务调度又可分为在线模式和批处理模式,本文研究属于独立任务调度批处理模式,即提交的任务集合统一调度。经典算法包括最小完成时间(Minimum Completion Time,MCT)算法[15]、Min-min 算法[16]和Max-min 算法[16]等。MCT 算法将每个任务分配到使其具有最早完成时间的处理器上计算,保证各处理器的负载均衡,但并非每个任务的实际执行时间都是最小的。Min-min 算法核心思想是优先调度具有最快执行完成时间的任务,并将该任务映射到最快完成的处理器。Max-min 与Min-min 算法的思想正好相反,选取最大最早完成时间的任务优先调度,可能造成短任务的调度延迟非常大。上述算法在计算调度方案时都只考虑任务执行时间的因素,没有考虑到如何提升GPU 资源利用率,很难适用于本文研究的不规则独立任务集合场景。文献[17]中针对利用GPU 加速计算的大量独立任务提出了一种动态调度算法,能够将任务分散到CPU 或GPU 上执行以减少总的执行时间,但这种方法只适用于特定程序。
本文旨在设计实现一种通用的调度框架,按照合理的调度策略将不规则的独立任务集合分散到集群中不同的GPU上计算,通过软件机制实现多任务共享GPU 资源计算,目标是实现GPU 资源利用率和任务处理效率的提升。首先,调度框架通过配置文件来设置输入的任务详情,可同时混合调度多种不同计算内容的任务;其次,通过参数传递建立执行节点CPU 线程和CUDA 流之间的联系,CPU 线程加载的GPU 计算会加载到绑定的流中顺序执行,不仅实现了多任务并行而且避免多个任务计算相互影响;最后,调度算法中采用任务组的形式调度,能减少调度延迟并缩短总执行时间。
2 调度框架设计与实现
2.1 GSF系统架构
GSF 系统整体架构如图1 所示,运行在CPU-GPU 异构集群上,整体上采用主从模式,由一个调度框架进程和多个执行器进程组成。调度框架就是系统控制节点,负责集群管理和任务调度;其余节点为从节点,负责启动并运行执行器。调度框架会按照内置的调度算法将用户提交的任务集分发到选择GPU 对应的执行器。执行器在接收到任务后,将其加载到GPU 中计算。每个从节点可运行的最大执行器数量与GPU设备数量相等。假如,某个从节点包含两块GPU,那么最多可运行两个执行器进程,节点上包含的CPU 计算资源会被平均分配。执行器中采用操作系统提供的CGroup[18]的资源隔离功能,将计算资源与执行器进程绑定,能防止执行器间的资源竞争。
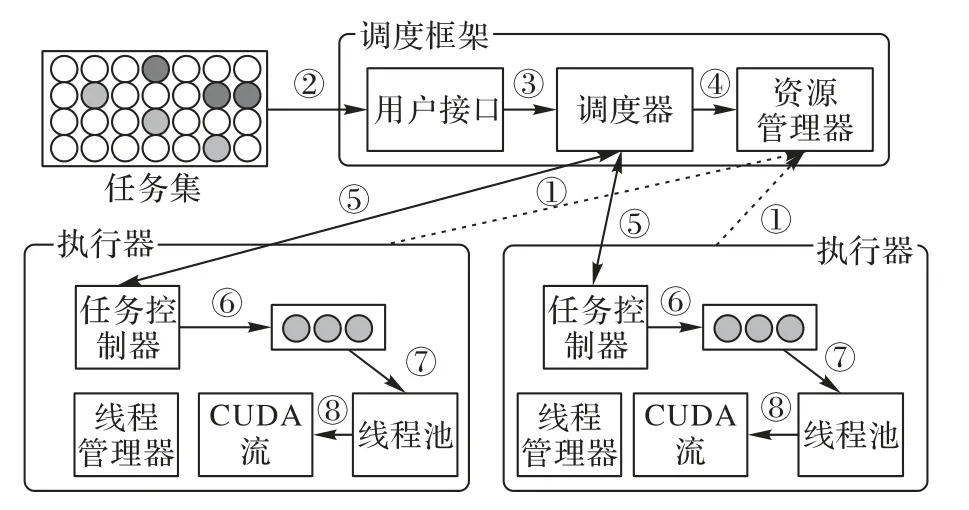
图1 GSF系统架构Fig.1 GSF system architecture
2.2 调度框架
调度框架由用户接口、调度器和可感知GPU 的资源管理器[19-20]三部分组成。用户通过接口提交任务信息,包括可执行程序路径、运行参数和GPU 资源需求等,接口负责将信息转换为规定格式消息转发给调度器。可感知GPU 的资源管理器是调度框架运行的重要支持,通过周期性地从各个从节点收集资源来管理和监控集群的资源状态,包括CPU、内存、磁盘和GPU 等,资源管理器以Resource Offer 方式向调度器分配当前可用资源。当调度器收到任务和资源信息,通过调度算法将任务与资源合理地匹配,以实现集群资源利用率和任务处理效率最大化。另外,调度器通过执行器返回的状态信息对任务进行监控,当某个任务出错时立即重新调度。
2.3 执行器
执行器是运行在从节点的进程,根据调度框架发出的指令启动和结束,由线程管理器、任务控制器、任务队列和工作线程四个模块构成。执行器的作用是将接收的任务加载到GPU 上计算,原因是GPU 程序需通过CPU 进程加载启动,因此执行器运行时只需利用CPU 资源。线程管理器负责在执行器进程启动后创建指定数量的工作线程,在进程结束前销毁所有线程。任务控制器负责将接收的任务添加到任务队列中,并监控其执行状态,当执行成功或出错时返回状态信息给调度器。任务队列是线程安全的,可同时被多个线程访问,但一个任务只能被一个线程得到,队列中的任务则按照到达的顺序依次排列。工作线程是持续运行的多个CPU 线程,每个线程对应一个CUDA 流,线程抢占到的任务会被添加到对应的流中执行核函数利用GPU计算。
执行器的运行场景如图2 所示,多个线程运行任务相当于在多个CUDA 流中计算。每个流是一个顺序操作队列,不同流之间的计算是并行的。这种方式在保证GPU 中每个流执行的任务所需资源被满足的情况下,显著提高资源利用率和任务处理效率。
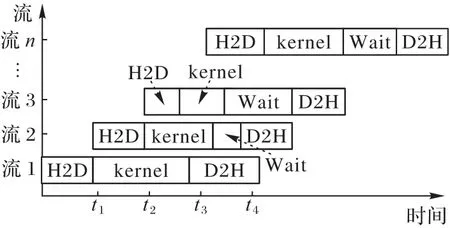
图2 多线程执行示意图Fig.2 Schematic diagram of multi-threaded execution
2.4 系统运行流程
调度模型按照以下步骤运行(步骤序号与图1 中序号对应):
①各个执行节点上的执行器定时向可感知GPU 的资源管理器汇报当前执行器上的可用资源信息,包括GPU 可用显存大小、可用内存大小等;
②用户通过接口向调度框架提交任务集合信息,包括任务类型、计算信息和资源需求等;
③接口将输入的任务集合信息转换为规定格式并发送给调度器;
④资源管理器收到资源变更,通知调度器当前可用资源;
⑤调度器将根据内置的调度算法将任务调度到可用的GPU计算资源对应的执行器;
⑥执行器接收到任务后,首先将其添加到任务队列;
⑦线程池中活跃的线程抢占队列新添加的任务;
⑧抢占成功的线程将任务的核函数加载到对应的CUDA流中执行。
3 调度策略
3.1 问题描述
假设不规则独立任务集由n个相互独立的GPU 任务组成,每个任务都具有有限并行度,GPU 资源需求较低。定义T={t1,t2,…,tn} 代表任务集,每个任务可细化为ti={tid,tsize,tres}。其中:tid表示任务编号;tsize表示任务计算数据量大小;tres表示任务的资源需求,主要考虑任务的GPU 显存需求。由于实际场景中,多个任务之间的资源需求和计算数据量都可能不同,认为任务集合具有不规则特性。调度集合T时必须考虑GPU 任务的计算特性和资源需求,否则会造成GPU 资源浪费和负载不均衡。定义G={g0,g1,…,gm}代表GPU 处理器集合,组成一个分布式异构GPU 计算集群,每个GPU 由向量gj={gid,gcapacity}表示。其中:gid表示GPU 处理器编号;gcapacity表示GPU 可用资源集合,可细化为gcapacity={gid,gmem,gcore},分别代表GPU 编号、可用显存和流多处理器等资源情况。
GSF研究的任务调度问题可以概括为:将集合T的n个任务按照策略分别调度到m个不同的GPU 上执行,任务资源需求不同、没有关联依赖并且可以并行计算。调度目标是实现高效的批量GPU 任务处理,保证了调度效率和显存利用率的提升。定义S={s1,s2,…,sm}来表示最终的调度方案,可视为不相交的任务划分问题,其中sj表示调度到第j块GPU 上的任务集合,∀si∩sj=∅,∀si,sj⊆T。
由于GPU 任务计算所需的资源和时间与输入数据量正相关,若采用一般的调度策略很容易造成资源浪费,并造成任务执行出错。本文研究的调度算法就是针对这类不规则任务集合的调度问题,为了便于研究和实现,算法中忽略了寄存器、GPU数据传输宽度效率等因素的影响,认为只要任务的显存需求被满足,对应的GPU 就能将其正确执行。原因是如果显存未被满足,任务会直接执行出错,而线程、流多处理器等资源未被满足,只会造成延迟等待直到可以执行。
3.2 针对不规则独立GPU任务集的调度算法
一般情况下,采用贪心算法来调度不规则的GPU 任务集,按照任务编号顺序依次将任务调度到第一个满足显存需求的GPU 上,每个任务调度后就更新对应GPU 的可用资源情况,如此循环直到所有任务执行完成。此算法逻辑简单易于实现,但时间复杂度与可用GPU 数量和任务数量正相关,对于不规则任务集合来说,贪心算法可能无法得到最优分配结果。假设存在两个可用显存分别为10 GB 和8 GB 的GPU,有6 个显存需求分别为6 GB、3 GB、3 GB、2 GB、2 GB 和2 GB 的不规则任务。按照贪心算法进行分配,第一个GPU 上的任务为{6 GB,3 GB},第二个GPU 上分配的任务是{3 GB,2 GB,2 GB},6 个任务中将有1 个任务无法分配。如果按照{6 GB,2 GB,2 GB}、{3 GB,3 GB,2 GB}分配,则6个任务都可以正常执行。
针对贪心算法存在的问题,将任务按照GPU 数量划分为多个不相交的子集,分别调度到满足资源约束的处理器上,在显存满足的前提下保证每个GPU 的计算单元被充分使用。本文提出了一种扩展贪心调度(Extended-grained Greedy Scheduling,EGS)算法,利用回溯搜索的思想将n个任务划分成m个子集,根据显存约束尝试将任务添加到合适的子集中,保证每个子集的显存之和不超过GPU 集群的显存最小值,然后将子集整体调度到某个GPU 上计算。由于回溯划分会得到多种调度方案,因此为每种方案计算一个负载权重,计算方法如式(1)所示:
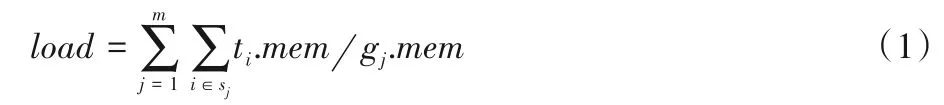
其中:ti.mem表示第i个任务所需的显存大小;gj.Mem表示第j个GPU 的显存大小。负载权重等于每个GPU 已用显存与可用总显存比例的和,权重越大代表显存资源越被充分利用。
另一方面,为了降低计算最优解的时间复杂度,算法中设置了一个优化算法的精度值β。利用β与任务数目相乘得到划分子集的任务数目count,从任务集合中挑选count个任务按照上述步骤进行划分,每次按照负载权重最大的方案调度,重复操作直到集合中所有任务都被调度。EGS算法将任务调度粒度从单个任务提升到任务集合,不仅能显著提升GPU 的显存资源利用率,还能降低任务集总执行时间。EGS 算法的伪代码如算法1所示。

算法1 扩展贪心调度算法。明了EGS 算法工作流程。算法中首先利用输入的精度值β计算每次划分子集的任务数目(第1)行),然后循环任务集合分别计算调度方案,直到所有任务均被调度算法结果(第2)行~第12)行)。在计算过程中,首先初始化变量和保存中间结果的数组(第3)行~第5)行),紧接着从T中随机挑选count个任务组成T'(第6)行)并计算任务分组的显存上限即集群中单个GPU 的显存最小值(第7)行),然后调度divide 函数得到所有划分方案和对应的负载权重(第8)行)。在得到所有方案后,找出负载权重最重的方案(第9)行),将T'按照其结果进行调度(第10)行),最后从T中删除此次计算中已被调度的任务进行下一次判断(第11)行)。
EGS 调度算法的核心功能由divide 函数实现,核心思想是按照回溯遍历思想将每个任务尝试划分到多个不同集合,最终得到多种不同的划分方案。函数结束条件为是否遍历到集合边界,如到达边界则利用式(1)计算此方案对应的调度权重保存到weight数组对应位置并结束此次递归。每个任务递归计算时,首先将GPU 集合按照当前可用显存降序排列,其目的是保证将任务优先调度到当前显存使用率最低的GPU上。然后遍历集合依次判断是否能满足任务的显存需求,如满足则添加到对应的方案中递归处理下一个任务,不满足则回退到上一层递归。该函数的伪代码如算法2所示。
算法2 divide方法。
综上所述,通过分组调度的思想,EGS算法有效地解决了不规则独立GPU 任务集的调度问题,其时间复杂度为O(n*2count),其中,n是集合包含的任务总数,count指由精度值确定的每次划分子集的任务数目。
4 实验与结果分析
4.1 实验设置
为了分析本文所提出的调度算法,将其分别与贪心调度算法、MCT 调度算法和Min-min 调度算法进行对比。利用表1列举的基准程序进行评价,程序来源于一些实际应用和GPU基准集合,包括Rodinia、YOLOv3 和NVIDIA 编程指南[21]。实验时通过一个随机任务生成器混合指定数量和输入配置的各类程序,得到最终的任务集提交到调度框架,集合中每个任务计算数据相互独立、资源需求不同,满足引言中提出的不规则独立任务集合定义。

表1 基准程序详情Tab.1 Benchmark program details
实验将部署在一个由8 台NF5468M5 服务器组成的GPUCPU 异构集群上,每个服务器由2 块型号为Intel Xeon Sliver 4110的CPU,内存为32 GB ECC Registered DDR42666,磁盘为2 TB 3.5"7200 r/min SAS硬盘;每个服务器中配置2块型号为NVIDIA GeForceRTX 2080TI 的GPU,每块GPU 的显存大小为10989 MB;使用的CUDA版本为cuda_10.1.105_418.39。
4.2 评价指标
实验中将利用任务集合总调度时长和GPU 设备使用率、显存使用率来评价算法的优劣。
1)调度时长。GPU 任务的执行效率,即时间越短效率越高,其计算方法为任务集初始提交到最后一个任务执行完成整个过程的间隔时间。
2)设备使用率。由NVIDIA SMI工具测量得到,指采样周期内GPU 设备计算核函数的活跃时间占比,利用率越高代表该设备越活跃,初始时置为0。
3)显存使用率。由NVIDIA-SMI工具测量得到,指此GPU当前已用显存与可用显存的比例,利用率越高代表该GPU 资源越被充分利用,初始时置为0。
4.3 结果分析
4.3.1 EGS算法参数对比
从算法1的伪代码可知,EGS算法初始根据精度值β与任务总数相乘得到每次划分子集的任务数目,以降低算法的时间复杂度,精度值对调度结果具有重要影响。利用随机任务生成器提交包含1000 个不同计算数据量的矩阵乘法任务组成的不规则GPU 任务集合来验证不同β值对算法的影响。实验设置如下:调度框架运行在主节点,集群的两个从节点分别启动2 个执行器,并设置执行器的并行任务数目为2。β数值分别设置为0.1、0.2、0.4 和0.6,每种数值情况运行任务集3次。图3 给出了不同精度值对应的评价指标结果,每条曲线代表一个精度值对应的集群GPU 平均显存使用率变化和总执行时长。
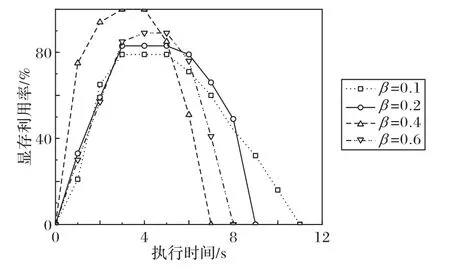
图3 不同精度值的结果对比Fig.3 Comparison of results with different precision values
从图3 可以看出,β设置为0.4 时,EGS 算法调度效果最优,整体维持了较高的显存使用率,并且总执行时间最短。原因是每次划分子集的任务数目为400,只需要3次划分即可完成调度,每次划分到单个GPU 上至多有50 个任务,GPU 的显存资源被占满的同时充分利用了其他计算资源,没有资源竞争的冲突出现。当β设置小于0.4,单次划分的任务数目较少,导致GPU资源空闲浪费;当β设置大于0.4,单次划分任务数目较多,在单GPU 中产生了资源竞争,因此虽然显存使用率较高,但总执行时间较长。综合来看,精度值β主要影响了任务集合循环次数和划分子集递归次数,设置合理的β能充分发挥EGS算法调度优势。
另一方面,由于EGS属于批处理调度模式,当任务子集调度到某个节点所有任务可同时启动。利用GSF 系统调度时,并行任务数目可具体表示为CUDA 流数目,不同流中任务并行执行,核函数计算和数据传输并行隐藏了部分延迟开销。并行度较低,无法充分利用GPU 资源;并行度较高,可能出现资源竞争问题。因此,采用由100 个不同输入图片检测程序组成的不规则GPU 任务集合来验证并行任务数目对算法的影响。实验设置如下:调度框架运行在主节点,集群的两个从节点分别启动2 个执行器,算法初始输入的精度值固定为0.4,设置数目分别为1、2和4。每种情况运行三次,得到各项指标策略的平均结果如图4所示。
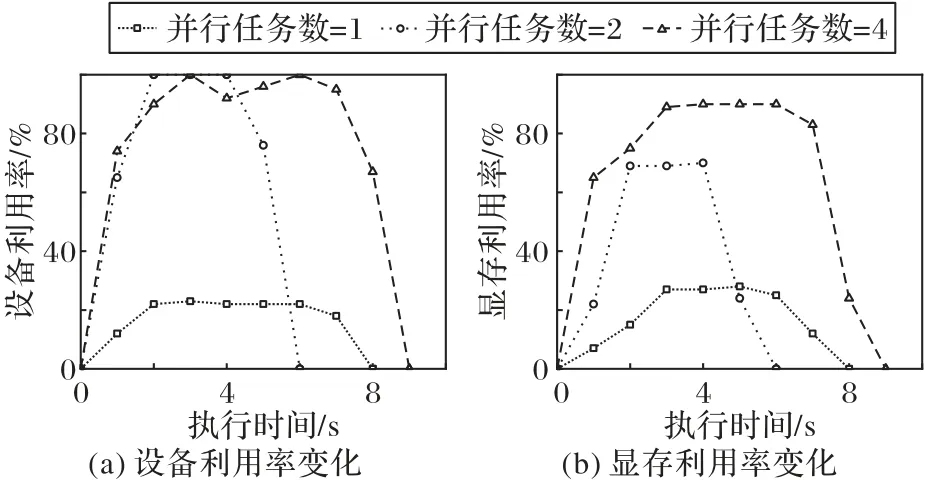
图4 不同并行任务数目的结果对比Fig.4 Comparison of results with different numbers of parallel tasks
图4(a)显示了不同任务并行度对应的集群GPU 平均设备利用率变化情况,图4(b)显示了不同任务并行度对应的集群GPU 平均显存利用率变化情况。当任务顺序执行时,两种利用率都保持在30%以下,造成了GPU 资源的空闲浪费。当并行任务数目等于2时,显存利用率维持在70%左右,GPU 设备被完全利用,集合总执行时长最短。原因是2 两个模型同时运行会充分利用资源,实现多任务并行效果,有效提升了执行效率。当并行任务数目等于4 时,显存利用率最优且维持在90%左右,设备利用率也处于较高数值,但执行时长最长。原因是图片检测程序使用的寄存器、流多处理器资源较多,当4 个模型同时在一个GPU 上检测时会造成资源竞争使任务执行阻塞,从而导致执行时间较长。值得一提的是,实验设置并行任务数目为5 时,任务会执行出错结束运行,因为此时分配到单个GPU 的任务显存总需求超过其可用显存,造成显存溢出无法正确执行。显存和设备利用率变化不是正相关的,必须根据任务的资源需求确定合适的并行任务数目才能达到资源利用率和任务处理效率提升的平衡。
4.3.2 调度算法性能对比
为了进一步评价算法的性能利用优势,在相同实验配置下将EGS 算法与贪心算法、MCT 算法和Min-min 算法整体对比,从不同测量指标综合评估算法性能。测试输入为表1 介绍的三种基准程序混合生成的独立GPU 任务集合,该集合满足不规则特点。通过随机任务生成器提交任务集合到调度器,采用四种调度算法分别调度集合到GPU计算。
首先,设计实验对比不同任务数目情况下各个调度算法得到的总执行时长。具体设置如下:调度框架运行在主节点,集群的两个从节点分别启动2个执行器,执行器精度值β固定为0.4、并行任务数目固定为2,设置集合任务数目分别为250、500 和1000。每种情况运行3 次,测量得到各种指标平均结果如图5所示。

图5 不同调度算法的执行时长对比Fig.5 Comparison of execution time of different scheduling algorithms
从图5 的执行时长对比结果来看,随着任务数量的增加四种算法的调度时长都保持增长,EGS 相较于其他策略具有明显的性能优势,并且这种优势持续保持。任务数量等于250时,EGS的调度时长相较于其他三种调度算法分别减少为原来的39%、50%和59%;任务数量等于500时,EGS的调度时长相较于其他三种调度算法分别减少为原来的52%、59%和66%;任务数量等于1000 时,EGS 的调度时长相较于其他三种调度算法分别减少为原来的58%、64%和80%。对于不同的不规则GPU任务集合,EGS算法的效果都保持最优,原因是EGS通过将不同数据规模的任务划分到同一任务集合中整体调度,得到全局最优调度方案,保证了多任务共享GPU 资源,有效发挥了GPU 的计算潜力,提升了任务处理效率。而其他三种调度算法都依次调度集合中的任务,将任务调度到最佳的GPU 上计算,调度结果只是局部最优解,无法实现多任务共享GPU资源,造成了GPU资源的极大浪费。
接下来,通过实验进行不同调度算法得到的GPU 利用率对比。具体设置如下:调度框架运行在主节点,集群的两个从节点分别启动2 个执行器,执行器精度值β固定为0.4、并行任务数目固定为2,固定集合任务数目为1000。利用随机任务生成器提交集合,测量得到各种性能指标的平均结果如图6所示。
从图6 中利用率变化曲线可以看出,EGS 在调度不规则独立GPU 任务集合时集群整体的设备利用率和显存利用率表现最优,贪心调度的利用率表现最差。EGS 的设备利用率峰值可维持在100%,显存利用率峰值可维持在95%,相较于其他三种常见的独立任务调度策略具有明显优势。原因是EGS算法在计算时将不同资源需求的不规则任务组合形成集合整体调度,单个集合的资源需求更大,多任务共享GPU 计算资源,能最大限度发挥GPU 的计算潜力。而其他三种调度算法都是以单个任务为粒度执行调度,显存资源的使用情况不规律、波动较大且空闲率较高。综合执行时长和GPU 资源利用率两类指标的测量结果来看,EGS 算法在调度不规则的独立GPU任务集合时效果较好。
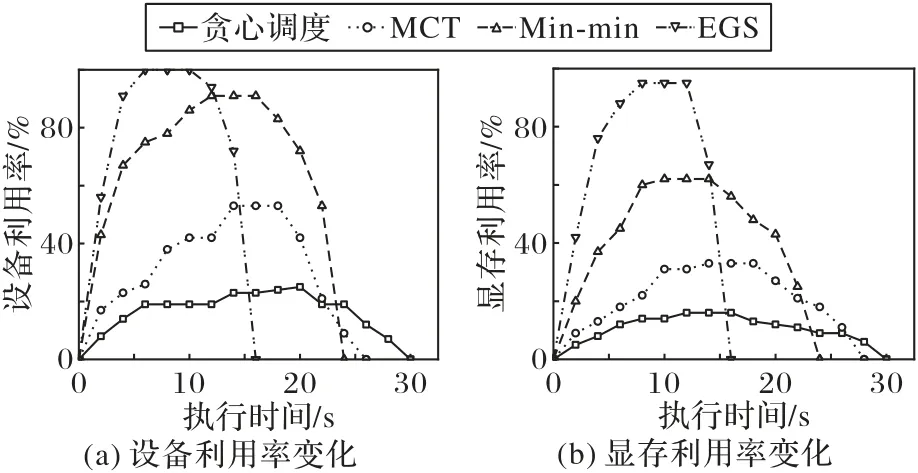
图6 不同调度算法的资源利用率对比Fig.6 Comparison of resource utilization of different scheduling algorithms
5 结语
本文研究了CPU-GPU 异构集群中不规则独立任务的调度策略,通过分析GPU 任务的计算特点和多任务共享GPU 资源的运行机制,分析不规则独立任务集合造成GPU 利用率低下的原因。在此基础上,设计并实现了一种扩展贪心调度算法,将调度粒度提升至任务集合,为集群中各个GPU 分配能满足资源需求的任务集合调度并运行,找到全局最优的调度方案。另一方面,提出了一种基于线程池和CUDA 流实现的调度系统,结合调度策略能保证资源利用率和任务处理效率的提升。但本文研究还存在一些不足:目前只考虑了任务信息已知的静态调度情况,无法反映实际生产环境中的调度,另外算法计算中只涉及显存资源约束,对于流多处理器、寄存器等资源没有考虑,可能造成同一GPU 中多个任务出现资源竞争问题。因此,未来要完善调度相关问题,进一步提升GPU资源利用率。
猜你喜欢
液压与气动(2022年10期)2022-11-27
电工技术学报(2022年20期)2022-10-29
计算机应用与软件(2022年9期)2022-10-10
汽车实用技术(2022年15期)2022-08-19
吉林大学学报(信息科学版)(2022年2期)2022-08-15
现代电子技术(2022年8期)2022-04-13
计算机测量与控制(2022年2期)2022-03-30
体育科技文献通报(2022年1期)2022-01-15
汽车维修技师(2019年2期)2019-08-23
科技与管理(2014年5期)2015-01-06
