
基于雷达和相机融合的目标检测方法
2021-12-07 10:09朱元陆科
计算机应用 2021年11期
高 洁,朱元,陆科
(1.同济大学中德学院,上海 200092;2.同济大学汽车学院,上海 201804)
0 引言
对于自动驾驶汽车的感知系统,目标检测是最非常关键的任务。近年来的目标检测算法大多使用了深度学习的方法,且这类方法皆显示出了良好的检测性能,其中最常用的是卷积神经网络(Convolutional Neural Network,CNN)模型。
这些目标检测方法中可分为两类:one-stage 算法和twostage 算法。one-stage 算法使用端到端网络来训练网络,这类方法将目标检测视为分类回归问题,直接从输入图像中提取特征并学习出类别置信度和边界框[1]。在one-stage 算法中,YOLO(You Only Look Once)[2]和SSD(Single Shot multibox Detector)[3]是最常用的两种网络。YOLOv2[4]和YOLOv3[5]相继被提出,其检测性能也相继提高。与one-stage 算法不同,two-stage 算法由两部分组成:一部分是候选区域生成网络,用于生成包含目标的候选区域;另一部分是分类和回归网络,它使用候选区域生成网络生成的候选区域框来完成边界框的分类和回归。Girshick 等[6]提出了R-CNN(Region-CNN)模型,它是two-stage 检测算法的基础模型。随着R-CNN 的发展,相继提出了Fast R-CNN[7]和Faster R-CNN[8]。后续提出的Mask RCNN[9]在Faster R-CNN 边界框回归的现有分支基础上并行添加了一个用于预测分割mask 的分支。这两类方法各有优点,适用于不同的情况。由于端到端网络的计算较快,one-stage算法相较于two-stage 算法具有更好的实时性能。相反,由于候选区域生成网络需要在第一阶段预测含有目标的候选区域,因此two-stage 算法检测速度较慢,但是,相应的检测结果也会更准确。另一方面,two-stage 算法会非常依赖于候选区域生成网络的预测准确性。
相机、雷达和激光雷达最常用于自动驾驶汽车和先进驾驶辅助系统(Advanced Driving Assistance System,ADAS)的传感器。相机可以像人眼一样感知周围的环境,毫米波雷达可以提供准确的距离信息。对于某些驾驶环境,如恶劣天气、障碍物遮挡等情景,仅使用一种传感器的感知系统精度是没有多传感器融和感知好的。传感器融合可以充分利用各传感器的优势,对不同传感器的数据共同加工处理的融合感知也有助于使感知系统具有鲁棒性,可以做出精确的控制决策。因此,传感器融合也是自动驾驶汽车和ADAS 研发中的重要方法。
本文针对自动驾驶汽车和ADAS 中的融合感知系统提出了一种基于雷达和相机融合的目标检测方法——PRRPN(Priori and Radar Region Proposal Network)。PRRPN 结合了雷达测量信息和上一帧检测结果来生成先验候选区域和雷达候选区域,可以使检测网络更加关注图片上极大可能存在目标的像素,候选区域也能尽可能地接近目标真实位置,并使前后检测更具连贯性,因为该方法不涉及繁杂的深度计算,一定程度上可以提高目标检测的速度。因为nuScenes数据集[10]不仅提供了相机传感器的数据还提供了雷达传感器的测量信息,因此选择在该数据集上对本文方法进行测试验证。本文采用了Faster-RCNN 的特征提取层和分类回归层作为基本架构,再加入PRRPN 形成完整检测网络,通过实验验证了该检测方法的可行性,同时还验证了通过Faster-RCNN 的区域生成网络(Region Proposal Network,RPN)生成的候选区域与PRRPN检测结果的融合可以提高Faster-RCNN的平均检测精度。
1 相关工作
基于雷达和摄像机信息的融合有多种方法,包括目标级融合、ROI(Region Of Interest)融合和特征级融合。目标级融合通常应用于目标跟踪[11-14],它直接使用相机检测结果和雷达测量值来获取目标的轨迹。从这些研究中,可以看到目标跟踪任务主要是从时间的尺度根据目标运动模型,如匀速运动、匀加速运动模型等对目标在不同时刻的运动状态进行估计,根据传感器的测量结果对目标运动轨迹进行预测和更新。本文在雷达数据处理方面,采用了类似的方法。
此外,也存在一些采用目标级融合方法的目标检测的研究。文献[15]提出了一种加权方法,将相机视觉网络识别结果与雷达目标估计结果相加权,获得最终的目标检测结果。文献[16]使用相机标定信息将雷达速度信息匹配给基于YOLOv3 的相机检测结果。文献[17]将YOLOv3 模型的输出与雷达数据进行匹配,以得到用于车辆控制和导航任务的目标距离和角度信息。综上所述,目标级融合首先要匹配雷达点和图像检测结果,然后选择更准确的参数作为最终检测结果,例如雷达的距离、速度、方位角信息和图像检测的分类信息。
特征融合是指在特征空间中融合来自不同传感器的数据的过程,例如组合两个传感器法的特征向量为单个特征向量[18]。文献[19]提出了一种相机雷达融合网络CRF-Net(Camera Radar Fusion Net),雷达网络作为附加分支对雷达数据进行处理,并将雷达特征提取到图像中。文献[20]中也使用了类似的方法。在文献[21]中,每帧的雷达点云用于生成具有六个高度特征和一个密度特征的鸟瞰图图像,然后使用3D 候选区域生成网络基于相机图像和鸟瞰图图像生成候选区域。除了有基于监督学习的融合网络研究外,还有关于无监督学习的融合网络的研究。例如,Lekic等[18]提出了一种基于目标检测的无监督学习融合网络条件生成对抗网络(Conditional Multi-Generator Generative Adversarial Network,CMGGAN),使用该网络利用雷达测量生成视觉图像,再提出特征进行目标检测。由于雷达点云太过稀疏,在深度学习方面比较受限,因此基于深度学习的雷达和相机的特征级融合的相关研究相对来说要少得多。
ROI 融合则是指使用雷达检测在摄像机图像中创建感兴趣区域,然后将感兴趣区域输入到图像分类网络中。文献[22]将雷达点投影到图片中,并根据车辆的尺寸大小画出ROI,再将ROI 输入至神经网络对图像中的目标进行分类。在文献[23-25]中,也采用了ROI 融合方法来进行图像目标检测任务。通常在划分ROI 时,是通过目标经验尺寸或者固定ROI 大小确定其位置的,所以容易出现ROI 过大或者过小的情况。
2 PRRPN结构
将雷达点云投影到图像上后,可以将注意力更多地放在一张图像的重要部分,即雷达点云所投影的图像位置,因为这些位置大概率存在待检测目标。一般车辆行驶时,前一时刻出现的大多数目标仍会在下一时刻出现。因此,前一时刻的检测结果可用于为下一时刻的检测提供先验信息,包括检测框的大小和类别。而雷达测量的距离、雷达散射截面积(Radar Cross Section,RCS)提供了目标的物理属性。通过融合这两类信息,可以为检测网络提供具有准确中心点、大小和比例的候选区域。
本文所提出的方法PRRPN 的检测网络结构如图1 所示,主要分为三个部分:特征提取层,候选区域生成层,以及分类回归层。特征提取层和回归分类层选取Fast R-CNN 的架构,其中特征提取层的骨干网络为ResNet50(Residual Network 50)+FPN(Feature Pyramid Network)。候选区域生成层又分为两部分:一部分是根据上一时刻的检测结果生成先验候选区域。首先选择类别置信度高于阈值的检测框作为先验框,将这些框与当前时刻的雷达点进行关联;然后在下一帧的检测开始时,将当前帧的雷达点与上一帧的雷达点进行关联,通过关联关系,每个雷达点可以得到与其匹配的先验框信息;接下来,将雷达点投影到图像上,并根据关联结果,将选定的先验框作为锚框分配给相应的雷达点,以生成先验候选区域。另一部分是根据雷达测量距离和RCS生成不同尺寸和不同高宽比的雷达候选区域。最后将雷达候选区域和先验候选区域进行融合,输入到分类回归层,进行最后的分类和回归。

图1 PRRPN的检测网络结构Fig.1 Detection network structure of PRRPN
3 特征提取层及分类回归层
特征提取层采用卷积网络提取图像特征,由若干卷积、修正线性单元(Rectified Linear Unit,ReLU)和池化层组成。本文采用了ResNet50+FPN 的骨干网络对输入的图像进行特征提取,其网络结构如图2 所示。其中,左半部分自底而上的网络为ResNet50,右半部分自上而下的网络为FPN。P2~P5 为网络最终提取的特征,之后将根据候选区域所对应的各层特征进行目标框的回归和分类。图2中ResNet50的结构参数如表1所示。
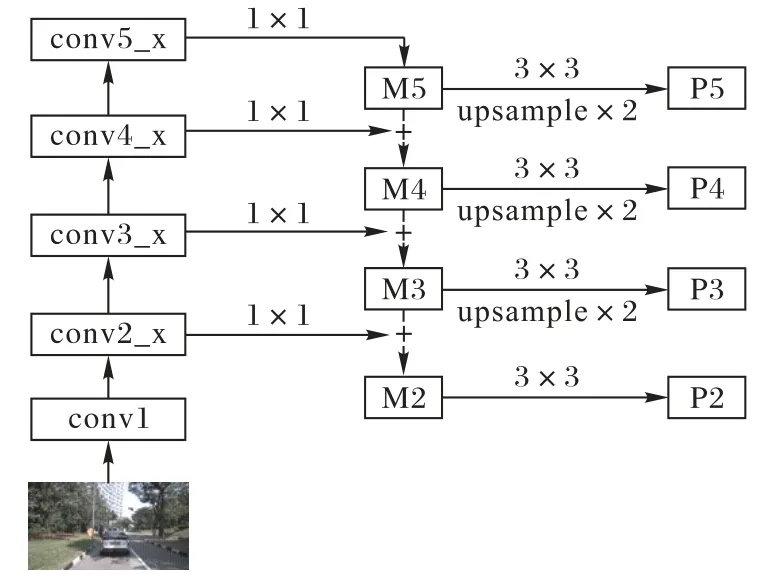
图2 特征提取层网络结构Fig.2 Network structure of feature extraction layer

表1 ResNet50结构参数Tab.1 Structural parameters of ResNet50
卷积网络浅层能提取到目标的位置、颜色、纹理等特征,深层能提取到更抽象、语义更强的特征。通过自底而上和自上而下的网络计算使得深层特征和浅层特征进行了融合,即每一层特征图都融合了不同语义强度的特征,使得不同分辨率的候选区域都能获得丰富的特征以进行分类和回归。
候选区域生成见第4~5 章。分类回归层先将候选区域所对应的P2~P5 层特征通过ROI Align 下采样为7× 7 大小的特征图,再通过4 个全连接层实现对目标的分类和对目标框的回归,结构如图1 中的分类回归层所示,网络参数见表2。因为本文中进行识别的目标种类为人、自行车、小汽车、摩托车、公共汽车和卡车共六种,所以fc3的输出为每个类别目标框的4个位置偏移参数,fc4输出为“6+1(背景)”种类别的置信度。

表2 全连接层参数Tab.2 Parameters of fully connected layer
4 先验候选区域生成
4.1 先验检测框与雷达点关联
检测框与雷达点之间的关联包括三个步骤:检测框筛选,将雷达点投影到图像中,以及将雷达点与先验检测框进行关联。
首先设置置信度阈值以筛选上一时刻检测到的目标。因为各个时刻检测到的目标数量和目标精度是不确定的,如果将所有目标作为先验框输入,则会导致无效候选区域过多,而置信度较低的检测框则可能会对检测网络产生负激励。因此,需要筛选置信度高于阈值的检测框用作先验框,以生成相关的先验候选区域。
雷达传感器输出的是标定在车辆坐标系中包含位置、速度等信息的稀疏点云。而检测框是像素坐标系中具有相关预测类别和类别置信度的二维边框。要将雷达点与检测框关联起来,首先要根据相机雷达的标定参数将雷达点从车辆坐标系映射到像素坐标系。如图3 所示,在摄像机与雷达的安装位置之间是存在一定偏差的,并且由于相机的成像原理,在成像位置与光学中心之间存在一定距离长度(即焦点),因此需要建立从车辆坐标系到像素坐标系的坐标变换关系。首先是将雷达点从车辆坐标系转换到相机坐标系,然后再从相机坐标系转换到像素坐标系。

图3 雷达坐标系和相机坐标系示意图Fig.3 Schematic diagram of radar coordinate system and camera coordinate system
车辆坐标系和相机坐标系之间的转换关系可以推导为:

其中:R是三阶旋转矩阵;T是三维平移向量。相机坐标系和像素坐标系之间的转换关系可以推导为:
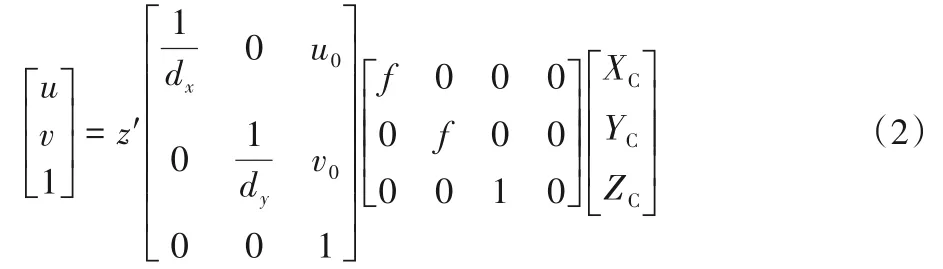
其中:f是相机的焦距;dx、dy分别为x、y方向上的像素宽度;u0、v0是图像中心;z′是比例因子。这些参数可以通过传感器联合标定获得。
以检测框尺寸作为关联条件,将雷达点投影到图像中后,若雷达点落在某一检测框中,则认为雷达点与该检测框相关联,若雷达点没有落在任一检测框中,则认为该雷达点没有相关联的检测框。
通过上一帧和当前帧的雷达点关联,可以获得来源于同一目标的雷达点,从而可以通过关联关系将雷达点与上一帧的检测框进行匹配以继承对应的检测框的属性。
本文使用目标跟踪架构来实现雷达点的关联。目标跟踪主要利用雷达输出的距离和速度等测量来对目标运动轨迹进行预测和更新。典型的目标跟踪系统架构包括文献[26-27]中所提到的四个部分,分别是传感器时空同步、运动状态估计、数据关联和航迹管理。传感器时空同步,是指进行融合的各传感器的数据需要处在同一时间同一坐标系中,通过式(1)、式(2)的坐标转换已完成空间同步,即所有数据皆处在像素坐标系。因为传感器的采用频率是不一致的,所以常用的数据时间同步方法包括外推、差值等。因为本文所采用的nuScenes 数据集中已包含雷达和相机时间同步的关键帧数据,因此可以直接对关键帧数据进行处理和计算。运动状态估计主要运用的是卡尔曼滤波(Kalman Filter,KF)、扩展卡尔曼滤波(Extended Kalman Filter,EKF)、粒子滤波(Particle Filter,PF)等估计理论与算法。通过滤波算法可以根据目标运动模型对雷达在上一帧中检测到的目标运动状态进行预测和更新。数据关联则是指将当前时刻测量与上一时刻目标进行匹配,找到属于上一时刻的目标在当前时刻的测量。
因此,实现关联首先需要完成的是利用目标运动模型根据目标上一时刻的运动状态预测下一时刻的运动状态。本文中,假设目标在纵向和横向上均做匀速运动。根据卡尔曼滤波相关知识,雷达上一帧检测到的目标在下一时刻运动状态的预测如式(3)中所示:
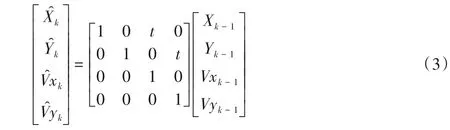
其中:Xk-1、Vxk-1是目标在第k-1 帧中的纵向位置和速度;Yk-1、Vyk-1是目标在第k-1 帧中的横向位置和速度是预测的目标在第k帧中的纵向位置和速度是预测的目标在第k帧中的横向位置和速度;t为第k-1 帧到第k帧的时间间隔。
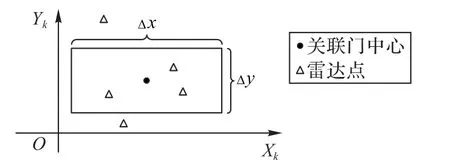
图4 关联门Fig.4 Association gate
如果一个雷达点落在关联门内,则认为该雷达点与关联门对应的前一帧雷达点相关联,关系如式(4)所示:

其中,Xk、Yk是第k帧中雷达点的位置。
当前帧的雷达点可以通过上述关联关系继承相应检测框的属性。因为目标实际运动规律不一定符合匀速直线运动模型,每个时刻也无法避免新目标的出现,所以一些雷达点没有关联上任一先验检测框。由于此时无法确定与雷达点相对应的目标信息,因此将所有先验检测框属性继承给该雷达点。
4.2 候选区域生成
获得了雷达点与上一帧图像检测结果之间的关联关系之后,就大致获得了当前时刻目标的位置和大小信息。投影的雷达点相当于为网络引入了注意机制,因为投影到图像上的雷达点的位置存在目标的可能性很高,并且由于时间的连续性,上一帧存在的目标极大可能仍在当前时刻存在,因此构造一个以投影到图像上的雷达点为中心、以雷达点相关联的先验检测框的大小为尺寸的先验候选区域,可以有效检测上一帧存在且在当前帧仍存在的目标。
投影在图片上的雷达点并不总是在目标的中心,因此本文借鉴了文献[30]中对候选区域进行平移调整、使候选区域更能全面覆盖目标的思想。如图5 所示,在上、下、左、右方向上移动以投影到图像上的雷达点为中心,以其匹配的先验框为锚框的先验候选区域,得到能够覆盖目标的候选框。

图5 先验候选区域生成Fig.5 Generation of prior region proposals
平移距离如式(5)所示,以使平移位置尽可能精确。

其中:dshift为平移距离,d为雷达点的距离;a为比例因子。a通过最大化先验候选区域和标注真值的交并比(Intersectionover-Union,IOU)得到,如式(6)所示:
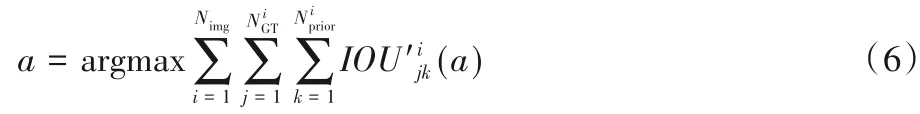
其中:Nimg为图像的数量;为第i张图像的真值数量;为第i张图像的先验候选区域的数量;为第i张图像中第j个真值和第k个先验候选区域的IOU。
对于关联上同一个先验检测框的雷达点,取其平均位置作为先验候选区域最终中心点,如式(7)所示,在有效减少候选区域数量的同时,也确保了候选区域的有效性。

其中:m为与同一个先验检测框关联上的雷达点的个数;xi、yi为第i个关联点的位置。
5 雷达候选区域生成
除了先验检测框的信息,雷达测量的距离、RCS信息也隐藏了待检测目标的属性,根据这些信息,可以生成雷达点的锚框。根据相机成像原理,目标在图像上的高和宽与距离成反比。即:目标距离越远,则投射到图像上的面积会越小;反之,目标距离越近,投射到图像上的面积会越大。此外,不同种类的目标,即使是处于同一距离处,也会呈现出不同的面积大小。因此本文根据雷达测量距离选择了5 个不同面积数量级的锚框来生成雷达候选区域,如式(8)~(9)所示:
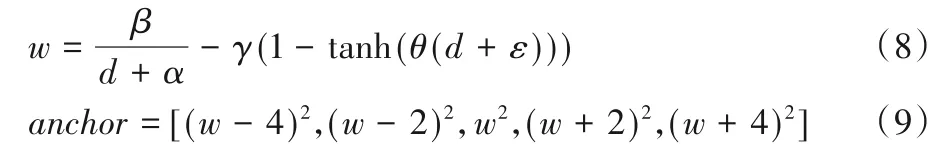
其中:d为雷达点的距离;w为基础尺寸;anchor为最终选取的锚框;α、β、γ、θ、ε为尺寸比例因子。
RCS 是目标在雷达接收方向上反射雷达信号能力的度量。一个具体目标的RCS 与目标本身的几何尺寸、形状、材料、目标视角、雷达工作频率及雷达发射和接收天线的极化有关。毫米波雷达探测的目标种类不同,对应目标的雷达截面积也自然不同。一般来说,人的RCS要比车辆、金属物体等低得多。对于车辆驾驶场景的待检测目标来说,RCS 低的目标如“人”的高宽比要比RCS 高的目标如“车”的高宽比大。因此,本文采用雷达点的RCS 信息来决定上述锚框的高宽比参数ratio,如式(10)所示:

其中:σ、τ、υ为高宽比比例因子。上述尺寸比例因子和高宽比比例因子通过最大化真值和雷达候选区域的IOU 得到,如式(11)所示:

其中:Nimg为图像的数量;为第i张图像的真值数量;为第i张图像的雷达候选区域的数量;为第i张图像中第j个真值和第k个雷达候选区域的IOU。同样为了使雷达候选区域更全面地覆盖待检测目标,根据式(5)对每个雷达候选区域进行平移。
6 实验与结果分析
6.1 数据集
将本文方法应用于同时含有相机和雷达数据的nuScenes数据集。该数据集涵盖了在波士顿和新加坡采集的1000 个场景的数据,是最大的具有三维目标标注信息的自动驾驶汽车多传感器数据集。为了将此数据集应用于二维目标检测任务,需要将三维标注转换为COCO(Common Objects in COntext)格式的二维标注。本文选择了在新加坡采集的数据来进行训练和测试。由于nuScenes 数据集的标注种类多达25 种,且很多种类非常相似,比如“adult”“child”“police_officer”“construction_worker”等,因此本文对nuScenes 数据集相似的标注种类进行了合并,共合并成6 个种类,分别为人、自行车、小汽车、摩托车、公共汽车和卡车。nuScenes 数据集以2 Hz 的频率对各传感器采集的数据进行了同步,并打包成了数据集中的关键帧数据。不同传感器之间的时间同步是实现关联的重要前提,利用时间同步频率,可以有效地计算关键帧数据中前后帧雷达点的关联关系。因此本文选择了关键帧数据进行训练和测试。nuScenes 具有完整的传感器套件,包括1 个激光雷达、5 个毫米波雷达、6 个相机、1 个惯性测量单元(Inertial Measurement Unit,IMU)和1 个全球定位系统(Global Positioning System,GPS)。其中,6 个相机分别安装在自车的前、后和两侧,5 个毫米波雷达分别安装在车的前方和4 个角。在这些传感器中,本文选择了前置摄像头和前置雷达的数据来进行训练和测试。最终,训练集一共包含了53910 张图片,其中,“人”的标注包含105320 个,“自行车”包含5286 个,“小汽车”包含262953 个,“摩托车”包含了5742个,“公共汽车”包含了10131个,“卡车”包含了46860个。
6.2 实验设置
本文采用网络骨干为ResNet50+FPN 的Faster-RCNN 来进行训练。训练时采用detectron2[31]提供的基于COCO 数据集的预训练模型进行训练。训练阶段一共迭代了12 个epoch,初始学习率为0.01,同时采用学习衰减策略,学习率衰减倍数为0.05,每经过10000 次迭代学习率衰减1 次。图像输入到网络前进行随机裁剪,短边尺寸在900~1600,长边最大尺寸不超过1600。训练收敛曲线如图6所示。
因为特征提取层和分类回归层的网络是一致的,所以测试过程中采用Faster-RCNN 的训练权重来对本文的方法进行测试。挑选了十字路口的驾驶场景样本作为PRRPN 的测试示意图,如图7所示。
图7 中:图(a)为上一帧检测结果;图(b)为当前帧的标注真值;图(c)中的点为投影到图片上的雷达点,加粗的点为当前帧与上一帧关联上的雷达点在图片上的投影,其他的点则为未关联上的雷达点在图片上的投影;图中的候选框为根据已关联上的雷达点生成的候选区域,图(d)中候选框为将先验检测框信息赋予所有雷达点后生成的先验候选区域;图(e)为根据投影到图片上的雷达点的位置以及雷达测量到的距离、RCS 信息生成的雷达候选区域;图(f)是将先验候选区域和雷达候选区域输入到分类回归网络后的检测结果。由检测结果可以看出,PRRPN方法能有效完成目标检测任务。
此外本文还设置了3 个对比实验:实验一为采用本文提出的候选区域生成方法PRRPN 进行目标检测;实验二为采用Faster-RCNN 进行目标检测;实验三为采用PRRPN 和RPN 进行融合来完成目标检测,即将PRRPN的检测结果和RPN生成的候选区域进行非极大值抑制(Non-Maximum Suppression,NMS),NMS 阈值为0.7,再输入到分类回归网络进行分类回归。三个实验中,分类回归网络中回归框的NMS 阈值皆等于0.5。
6.3 结果评估
本文使用COCO 数据集中使用的12 个评估指标[32]来对结果进行评 估,即AP(Average Percision)、AP50、AP75、APS、APM、APL、AR(Average Recall)、AR10、AR100、ARS、ARM、ARL,各评价指标含义见表1。

表1 实验用评价指标及其含义Tab.1 Evaluation indexes for experiment and their meanings
不同检测方法的AP、AR 和检测到的各种类的AP 分别如表2~4所示。
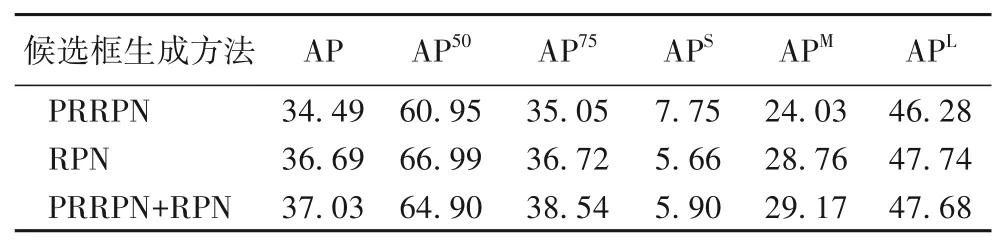
表2 不同检测方法的AP 单位:%Tab.2 APs of different detection methods unit:%
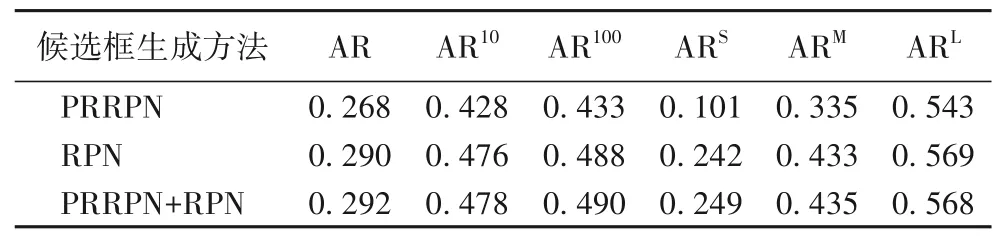
表3 不同检测方法的ARTab.3 ARs of different detection methods
因为nuScenes 数据集中的一些距离比较远,尺寸非常小的目标没有被标注,所以由三维标注信息转为二维标注信息时也没有包含这部分目标信息;但是检测网络仍检测到了这部分目标,加上遮挡、边角目标较多,所以检测结果的AP会相较其他数据集低一些。
由表2~4 可以看出,PRRPN 的AP 略低于RPN,但是对小目标的检测效果会更好,PRRPN 的APS相较RPN 提高了2.09个百分点;而将所提PRRPN 与RPN 进行融合的方法,与单独使用PRRPN 和RPN 相比,平均检测精度分别提升了2.54 个百分点和0.34 个百分点。另一方面,由于PRRPN 无需进行网络计算,因此计算速度优于RPN,每张图像平均检测时间能达到0.0624 s,而RPN的每张图像平均检测时间为0.0778 s。此外,PRRPN+RPN 的检测结果要比单独使用RPN 或PRRPN更好,几乎所有指标都得到了提高。

表4 不同检测方法检测到的各种类的AP 单位:%Tab.4 APs of different detection methods for different classes unit:%
通过对比PRRPN 与RPN 的检测结果,可以发现PRRPN对于雷达探测范围内目标的检测效果是很好的,如图8(a)所示,PRRPN 的检测结果图中的点为投影到图像上的雷达点,PRRPN 在加快检测速度的同时,也能达到很高的检测精度。此外,PRRPN 对于如目标镜像、广告牌等不会产生雷达反射点的虚假目标不会产生误检。而基于上一时刻检测结果生成先验候选区域的思想,会使得上一时刻出现的目标在下一时刻不会漏检,特别是目标驶离自车的场景,此时目标会出现在图像上的边角,一般的检测方法对于边角目标的检测还存在一些问题,但是PRRPN 方法会改善边角目标的检测效果。如图8(b)所示,在市区玻璃建筑区域或者邻车具有大车窗等会产生目标倒影的场景,因为PRRPN 是基于雷达信息来实现目标检测,而倒影不会产生雷达反射信号,因此不会产生RPN对目标镜像的误检现象。同样如图8(b)所示,当邻车驶离自车时,RPN 方法没有检测出该目标,但PRRPN 检测到了该目标。因为PRRPN 是根据雷达的距离和RCS 信息来生成一定尺寸的雷达候选区域,综合了雷达的空间信息和图像的平面信息,对于雷达探测的近距离目标的误检会相较RPN 少得多,如图8(c)所示。当然,PRRPN 对于部分远距离目标,如远距离人的检测效果是有所欠缺的,如图8(d)所示,因为一些远距离的人已超过雷达检测范围,且雷达对于远距离的人对雷达波的反射信号也较弱,所以雷达的检测短板也是PRRPN的短板。

图8 PRRPN和RPN检测结果对比Fig.8 Comparison of PRRPN and RPN detection results
综合而言,PRRPN 运用了雷达传感器的优势并且将上一帧的信息运用到下一帧的检测,在具有良好检测效果的同时,还能提高检测速度,在一些场景下甚至能达到更好的检测效果。PRRPN+RPN 的方法,综合了PRRPN 和RPN 的检测优势,对于雷达检测范围内的目标,因为综合了雷达的空间距离信息和图像的像素特征,检测结果更加精确,且因为由上一时刻检测结果而得的先验框的应用,也减少了一定的漏检,同时两者的融合也使得雷达检测范围外的目标也能很好地被检测到。
如图9 所示,PRRPN 的检测结果和RPN 的检测结果图中的点为投影到图片上的雷达点。从图9 可以看出,PRRPN 和RPN 的融合可以借助PRRPN 的检测结果减少被遮挡目标的漏检,同时也使得部分目标的边界框的范围更加精确,边界框的置信度也会提高。

图9 PRRPN+RPN和RPN的检测结果对比Fig.9 Detection result comparison of PRRPN+RPN and RPN
7 结语
本文提出了一种融合雷达数据和相机数据来生成候选区域进行目标检测的方法——PRRPN。实验结果表明PRRPN可以快速且有效地检测到雷达探测距离内的目标,还可以在RPN的基础上进一步提高融合检测精度。通过将前一帧的检测结果与下一帧的雷达数据相关联,可以为当前时刻的检测提供具有先验信息的候选区域,根据雷达的距离和RCS 信息可以估计待检测目标的尺寸、大小信息,生成蕴含相应信息的雷达候选区域。PRRPN 可以作为附加候选区域生成网络与任一two-stage 检测网络进行融合,提高其检测精度。PRRPN还将目标检测与目标跟踪两个任务结合起来,为未来对目标跟踪和目标检测集成到一个网络以及自动驾驶汽车的多任务融合提供了参考。接下来,可将传统的后融合方法[33-34]运用到前融合的特征融合中,进一步提高目标检测任务的效率。
猜你喜欢
军民两用技术与产品(2022年5期)2022-06-28
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
海外文摘·艺术(2020年22期)2020-11-18
当代陕西(2019年15期)2019-09-02
电子制作(2019年15期)2019-08-27
小学生学习指导(低年级)(2018年12期)2018-12-29
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
小学生导刊(高年级)(2016年11期)2016-11-14
