
基于人眼状态的瞌睡识别算法
2021-12-07 10:09袁玉波
计算机应用 2021年11期
孙 琳,袁玉波
(1.华东理工大学信息科学与工程学院,上海 200237;2.上海大数据与互联网受众工程技术研究中心,上海 200072)
0 引言
如今,人工智能+医疗、人工智能+交通、人工智能+教育的模式在生活中随处可见。如何有效地预防瞌睡情况成为不少学者的研究重点,这项技术不仅可以应用于交通上,还可以对学生的课中状态进行分析[1]。在交通上,美国国家公路交通安全管理局的调查结果表明,33%以上的受访者承认他们在驾驶时会感到疲劳,而10%的人承认在过去一个月中出现过昏昏欲睡的情况[2];在因瞌睡而导致事故的发生的事件中,超过94%的司机都提到当时他们是独自一人在车内[3]。通过使用瞌睡识别算法,可以检测出驾驶员瞌睡的情况,从而采取相应的预防措施,减少意外事故的发生。在课堂上,如果学生上课时出现瞌睡的情况,瞌睡识别算法会对这名学生进行提醒,使其继续集中注意力学习。在当今快节奏的社会,人们似乎没有足够的时间来完成他们每天的必要活动,只能减少睡眠时间,导致睡眠不足,在一些需要集中注意力的地方瞌睡,造成了难以挽回的损失。而瞌睡识别可以减少这些情况的发生,在人们出现瞌睡情况之前及时制止。
在瞌睡识别应用中,人眼定位是瞌睡识别的基础,直接影响瞌睡识别结果的准确性。目前,国内已经有很多关于人眼定位的研究,并提出了大量的研究方法。何春[4]提出使用积分投影的方法进行人眼定位,首先通过肤色特征检测人脸,然后再使用积分投影函数定位人眼;虽然该方法计算快,但是准确率不高。为了提高准确率,并解决肤色检测人脸易受光照影响的问题,周立宇等[5]结合边缘检测和肤色检测定位人脸,然后利用几何位置关系、灰度投影和曲线拟合的方法对人眼进行二次定位;该方法虽然优于传统的肤色检测方法,但是当人脸图像受到噪声影响严重时,人眼定位准确率也会降低。为了进一步精确地定位人眼,侯向丹等[6]用改进后的Adaboost方法检测人脸,根据“三庭五眼”的方法去除人眼之外的噪声,融合积分投影和差分投影确定人眼的纵坐标,最后利用垂直积分投影确定人眼的横坐标,实现人眼定位。本文的研究工作之一是对人眼进行精确分割。在闭眼数据集CEW(Closed Eyes in the Wild)[7]以及公开的人脸表情识别(Face Expression Recognition,FER)数据集[8]进行人眼定位之后,本文决定基于人脸上的68个特征点进行人眼分割。
目前关于瞌睡识别的算法大多数是基于深度学习或者机器学习的方法,利用卷积神经网络(Convolutional Neural Networks,CNN)提取特征,再用Softmax 等分类器将选定的特征分类为瞌睡和不瞌睡,而没有充分考虑到人眼的闭合状态序列与瞌睡之间的关系,并且基于深度学习的瞌睡识别算法依赖大量的数据集,对实验设备的要求高。针对上述问题,本文提出了基于人眼状态的瞌睡识别算法,利用闭合状态序列与瞌睡之间的关系,完成瞌睡识别。本文所提的瞌睡识别方法中数据的输入用电脑摄像头即可完成,相较于用心电图(ElectroCardioGram,ECG)、肌电图(ElectroMyoGraphy,EMG)和脑电图(ElectroEncephaloGraphy,EEG)[9]等测试节省了较多的应用成本。现有公开的现实生活中的瞌睡数据集不足,而本文算法在不依赖于大量数据集的情况下,也能完成瞌睡识别。
1 本文算法
1.1 算法流程
本文提出了一种基于人眼状态的瞌睡识别算法,算法流程如图1 所示。本文算法的关键思想是在人脸检测的基础上将人眼分割出来,根据分割出来的人眼区域,计算人眼面积以及采样后标准状态帧的人眼面积;通过构造睁眼状态度量函数得到人眼评价度量值;利用人眼评价度量值与睁眼阈值比较的结果来标注人眼状态标签,最后通过瞌睡判别模型来进行瞌睡状态识别。
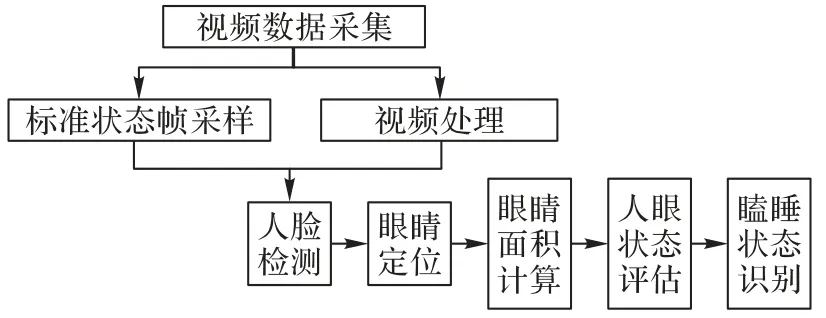
图1 瞌睡状态识别流程Fig.1 Flow chart of drowsiness state recognition
首先,对输入的视频数据进行标准状态帧采样和视频处理。标准状态帧是利用关键帧检测算法将具有代表性的视频帧抽取出来,这是为了解决每个人人眼大小不同的问题,并且作为之后人眼状态得分的基准,视频处理是进行视频帧的采集。其次,进行眼睛定位,将人眼区域分割出来。利用级联回归模型[10]检测人脸68个特征点,从中获取12个有关人眼的特征点,进而实现对人眼图像的分割。然后,计算人眼面积,构造睁眼状态度量函数。人眼面积的计算主要是统计人眼区域内的像素点数,再结合左眼状态度量值和右眼状态度量值,以此为标准来检测人眼状态。最后,建立瞌睡判别模型,进行瞌睡状态识别:若实验对象的眼睛在连续的时间段内都处于闭合状态,则处于瞌睡状态。
1.2 人眼分割
人眼分割是从一段视频帧F={F1,F2,…,}中,提取出每一帧的人眼区域,N0是视频帧的数量。因为人眼分割是基于面部检测的基础之上,所以利用级联回归树模型的人脸特征点算法检测人脸上的68个特征关键点。视频帧Fi表示为:
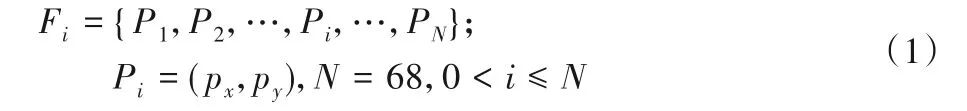
其中Pi为特征点的位置。在已检测到68个特征点中,有12个特征点用来标记眼睛区域,其中,37~42 为左眼上的关键点,43~48号特征点为右眼上的关键点,分别记为

利用眼睛位置上的特征点分割出人眼区域之后,分别计算左眼面积和右眼面积。

其中:El、Er分别代表左眼区域,右眼区域。C(pj)是计数器,统计人眼区域内像素点数目,计算式如下:

1.3 眼睛闭合
为了能够精确地检测出眼睛闭合的状态,本文构造了一个睁眼状态度量函数L(e),基于L(e)标注人眼状态标签,L(e)定义为:

其中:d(e)为睁眼状态度量函数,用来表示睁眼程度。

其中:k代表从视频中提取的前k帧。(i=1,2,3,4)是睁眼状态模型中的睁眼阈值,分别是由关键帧挑选算法挑出最能代表睁眼程度的4帧所决定的,计算式如下:

其中,di为前后两帧颜色直方图的距离差。di表达式如下:
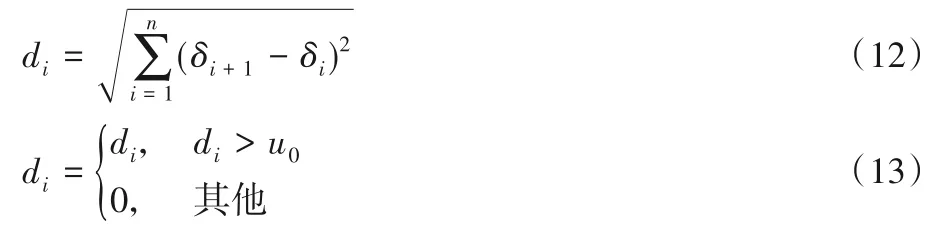
其中:δi+1、δi是选取的视频里连续两帧的颜色直方图。式(12)是di的计算过程,式(13)表示通过与阈值u0比较,得到最终的结果di。n是该图像颜色直方图的维度;u0是决定候选帧的距离阈值。

1.4 瞌睡检测
根据眼睛闭合程度的标签,提出了改进衡量瞌睡的函数,单位时间内眼睛处于闭合状态的所占时间Perclos(Percentage of eyelid closure over the pupil),得到了瞌睡状态值k,即:

其中:L(e)的值是之前所判断的人眼状态的标签;n表示这段时间内视频的总帧数。利用所得到的k值进行瞌睡状态判断,瞌睡状态判断函数如下所示:

其中:β为瞌睡阈值,若在连续的3个时间段内,参与者都处于瞌睡状态,则将该名参与者识别为瞌睡。瞌睡识别函数如下所示:

图2 显示了不同角度下的人脸图像,并且在人脸图像上标注了68 个特征点。从图2 可以看出,即使人脸偏移了一定角度,68个特征点还是能在人脸上标注出来。
2 实验与结果分析
2.1 YawDD数据集
打哈欠检测数据集(Yawning Detection Dataset,YawDD)[11]分别包含了不同年龄、不同国家的57 名男性,50 名女性志愿者。视频是通过安装在汽车后视镜和汽车仪表盘上的摄像头在不同的光照条件下拍摄下来的。为了评估本文方法的实验结果,分别使用YawDD和NTHU-DDD数据集。第一个用于评估的数据集是YawDD,视频是安装在汽车仪表盘上的摄像头拍摄的,总共29 个视频,其中包含不同性别,戴眼镜、不戴眼镜的驾驶员。YawDD 视频数据集的部分视频样本帧如图3所示。

图3 YawDD视频数据集的样本帧示例Fig.3 Sample frame examples of YawDD video dataset
由于YawDD 数据集并没有标注相应的标签,所以数据集由本文手动标注。针对该数据集,将YawDD 数据集中视频分别被标注为“正常”“说话”“打哈欠”三类,这里将“正常”“说话”合为一类作为清醒状态。图4 是驾驶员在清醒状态(Nonyawning)下所提取的视频帧,图5 是驾驶员在瞌睡状态(Yawning)下提取的视频帧。

图4 清醒状态视频帧示例Fig.4 Non-yawning video frame examples

图5 瞌睡状态视频帧示例Fig.5 Yawning video frame examples
2.2 NTHU-DDD数据集
NTHU-DDD 数据集是关于学习者瞌睡检测的数据集,由训练数据集、测试数据集和评估数据集组成[12]。数据集中的实验对象是36 位来自不同种族、年龄在18~40 岁的成年人。视频是在不同的照明、模拟不同驾驶场景的情况下拍摄的。驾驶场景包括正常驾驶、打哈欠、慢速眨眼以及昏昏欲睡等情况。如图6所示,录制的视频分辨率是640 × 480,音频视频交错(Audio Video interleaved,AVi)格式,每秒30 帧。另外,与睡意相关的特征都被逐帧标注,其中包括睡意、头部姿态、眼睛和嘴巴等信息[13]。

图6 NTHU-DDD视频数据集的样本帧示例Fig.6 Sample frame examples of NTHU-DDD video dataset
2.3 评估指标与结果分析
实验的环境是:MacOS 操作系统,所使用的芯片是Apple M1,16 GB的RAM,在Python3.8的环境中编程实现。
在第2.2 节中,本文提出了睁眼状态度量函数来判断人眼状态。图7 是眼睛面积比(Square of Eye Ratio,SER)与眼睛纵横比(Eye Aspect Ratio,EAR)[14]的对比结果。某个参与者在清醒状态(波峰)与瞌睡状态(波谷)下的SER 值差距较大,而在EAR 值上差距并不是很大,因此SER 值有利于针对人眼状态标记多标签。

图7 SER、EAR随时间的变化情况Fig.7 SER,EAR varying with time
图8 是在YawDD 数据集下瞌睡识别可视化的示例。图8(a)是驾驶员驾驶过程中抓拍的图片,下方数字序号标注的图片则是驾驶员眼睛的图片,显示了一段时间内驾驶员眼睛状态的变化。图8(b)表示驾驶员驾驶过程中的瞌睡检测结果:当眼睛处于“闭合状态”达到一定时间时,则标注为1,即出现有睡意的现象,0 则代表清醒状态;若在连续的时间段内一直保持这种睡意,则判定其为瞌睡。图8(b)中的序号对应图8(a)中的序号,表示与图8(a)状态相对应的瞌睡检测结果。
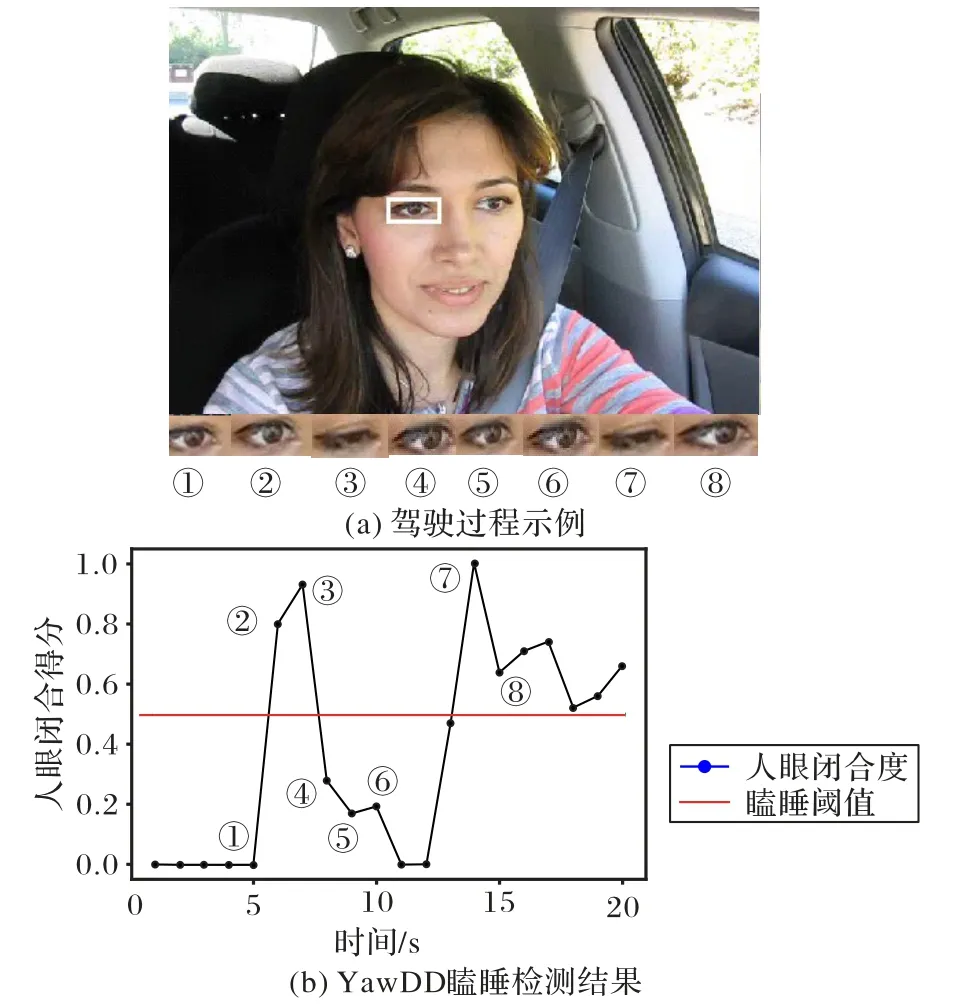
图8 YawDD数据集上瞌睡识别可视化示例Fig.8 Visualization example of drowsiness recognition on YawDD dataset
图9 是YawDD 数据集中部分视频的实验结果。图9(a)~图9(h)分别是在各个驾驶员驾驶过程中随机选取的瞌睡检测结果。从图9 中可以明显地看出,参与者瞌睡是发生在哪个时间段内。
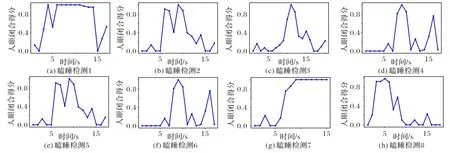
图9 YawDD数据集瞌睡检测部分结果Fig.9 Some results of drowsiness detection on YawDD dataset
图10显示了在NTHU-DDD 数据集下,瞌睡识别可视化的示例,其中图10(a)展示的是实验者瞌睡过程,分别用数字序号代表10(a)的相应状态。图10(b)是NTHU-DDD 瞌睡检测的结果,图10(b)中的序号对应图10(a)的相应状态。其中,图10(b)的瞌睡标签,0代表无睡意,1表示有睡意。
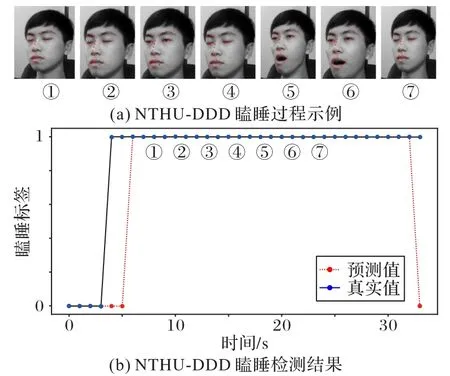
图10 NTHU-DDD数据集上的瞌睡识别可视化示例Fig.10 Visualization example of drowsiness recognition on NTHU-DDD dataset
本文分别采用了准确率、F1 作为实验结果的评价指标,准确率计算式定义为:

其中:TP表示预测正确的数量;FP表示预测错误的数量。F1计算式定义为:

其中:Precision为精准度;Recall为召回率。
表1 给出了本文算法在数据集YawnDD 上进行实验之后所获得的结果。根据表1 的结果可以看出,本文所提的算法在绝大多数情况下都能正确预测实验对象瞌睡的情况。

表1 本文算法在YawDD上的实验结果Tab.1 Experimental results of proposed algorithm on YawDD
图11 显示了在数据集YawDD 上,本文算法,分别与EAR、嘴部纵横比(Mouth Aspect Ratio,MAR)[15]、瞳孔大小(Size Of Pupil,SOP)[16]以及眼睛环度(Eye Circularity,EC)[17]等算法的特征值对比结果。图中的特征值与瞌睡状态相关,瞌睡越显著,各个算法的特征值越高。EAR 算法利用眼睛纵横比的方法构造了眨眼检测器,虽然该算法可以检测出人是否眨眼,但是由于简单的长宽比阈值设定,另外人出现瞌睡时,眼睛纵横比的效果不太明显,所以可能导致出现假阳性的效果。MAR 算法中的嘴部纵横比的计算方式类似于眼睛纵横比,主要计算的是嘴部特征,相较于EAR 算法更有利于检测出打哈欠行为,但是仅针对于嘴巴张大且保持这种状态时间较长的情况。SOP、EC算法更强调瞳孔面积,虽然瞳孔的大小可以很好地衡量人的疲劳程度,但并不是与瞌睡状态直接相关联。本文算法能很好地提取眼部特征,并根据眼睛闭合的程度对权重作出相应的更新。从图11 可以看出,在人瞌睡的情况下,本文算法相较于其他算法特征值更为明显,从而使得瞌睡状态的判定更为准确。
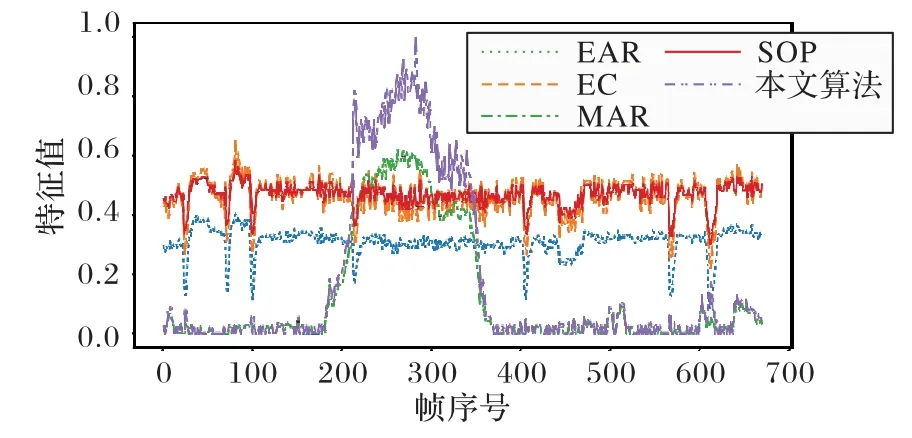
图11 不同算法的特征值对比Fig.11 Eigenvalue comparison of different algorithms
图12 给出了本文算法与其他算法的准确率对比。从图12 中可以看出,综合所有的视频,本文算法准确率高于其他算法的准确率。EAR 在检测视频过程中,由于多段视频存在眼睛长宽比变化不大的情况,因此平均准确率为82%。MAR 由于打哈欠过程中,嘴部特征相对明显,所以准确率有一定的提升,平均准确率为88%。SOP 结合瞳孔特征以及眼睛直径,所以在检测大多数视频时,具有一定的稳定性,平均准确率达到91%。本文算法,在检测这29 段视频中平均准确率提升到94%,但是当存在遮挡、视角偏移范围较大时,也会造成准确率下降。
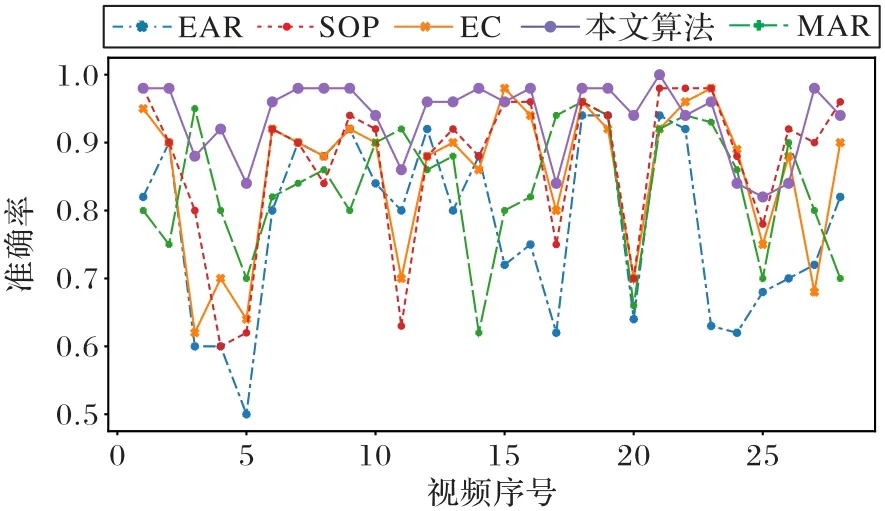
图12 不同算法的准确率对比Fig.12 Accuracy comparison of different algorithms
最后在NTHU-DDD 数据集上进行实验,因为NTHU-DDD数据集在每一帧都标注了有睡意、无睡意的标签,所以在不同场景下,随机选取部分视频,提取视频帧,针对睡意标签计算F1和准确率。
表2 的结果显示,本文算法在NTHU-DDD 数据集上的平均准确率达到80%以上,同样具有好的表现效果。

表2 NTHU-DDD数据集上的实验结果 单位:%Tab.2 Experimental results on NTHU-DDD dataset unit:%
2.4 时间评估
对数据集YawDD 中的其中一个视频进行时间评估,图13是本文算法与其他算法的耗时箱型图对比。

图13 不同算法的耗时箱型图对比Fig.13 Comparison of time consumption box plot of different algorithms
本文算法在瞌睡状态识别耗时多于MAR,但少于其他算法。EAR 识别每帧图片的平均时间是0.29 s,因为视频每秒30 帧,所以平均结果是8.94 s。MAR 平均结果是6.39 s,SOP平均结果是9.51 s,EC 平均结果是8.73 s,本文算法识别每帧所用时间是8.49 s。算法所用时间与视频的分辨率有关,分辨率越高,所耗时间越多。SOP与本文算法,在特征提取以及瞌睡状态建模上增加了时间的消耗。
3 结语
在瞌睡识别的场景中,根据人眼闭合状态序列与瞌睡状态之间的关系,本文提出了基于人眼状态的瞌睡识别算法。该算法通过提取视频序列中的闭合状态帧,结合人眼状态标签算法,自动生成人眼闭合状态序列,最后通过瞌睡识别模型进行瞌睡识别。
本文算法在YawDD、NTHU 数据集上进行实验,在数据集YawDD 上的29 个视频的准确率达到了94%,在NTHU-DDD数据集上的准确率达到了80%以上。虽然相较于其他对比算法,本文算法的性能较优,但仍有局限性。当人的头部姿态变化过大时,准确率将会较低,所以接下来的研究中,我们将结合头部姿态进行瞌睡识别。
猜你喜欢
东坡赤壁诗词(2022年3期)2022-05-29
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
