
基于Siamese-YOLOv4的印刷品缺陷目标检测
2021-12-07 10:09楼豪杰郑元林廖开阳雷浩李佳
计算机应用 2021年11期
楼豪杰,郑元林*,廖开阳,雷浩,李佳
(1.西安理工大学印刷包装与数字媒体学院,西安 710048;2.陕西省印刷包装工程重点实验室,西安 710048)
0 引言
印刷品缺陷检测是印刷生产中一项重要的生产流程。一方面,人工缺陷检测主观性较强,长时间的缺陷检测工作会产生视觉疲劳现象,降低质检员对印刷缺陷判断的准确性;另一方面,人工质检投入成本高,缺陷检测不连续。传统人工质检方法的诸多弊端已经不能适应现代化工业生产发展,因此开发新的算法并进行应用显得尤为重要。在以往的研究中,红外探测技术[1]、电磁超声[2]检测技术得到了较早的应用,但这些技术所需的设备门槛高,不能得到广泛的应用。随着图像处理技术的发展,机器视觉的缺陷检测方法逐步登上舞台,但由于人工设计特征耗时费力,基于深度学习的缺陷检测方法应运而生。本文的研究就是使用深度学习的方法对印刷品缺陷图像进行缺陷的定位与识别。
传统的人工缺陷检测效率低下,严重的还会造成漏检和误检,给印刷生产带来了诸多负面效应。因此国内外专家学者致力于机器质检的研究,在基于计算机视觉的缺陷检测方面,如:Li 等[3]提出了一种能有效提取织物纹理信息的方法,通过采用稀疏结构对缺陷进行建模,从而区分出背景纹理和缺陷信息。袁野等[4]使用目标检测的方法对复杂环境下的冰箱金属表面进行缺陷检测,能够较好地应用于金属制品的缺陷检测中。He等[5]提出了一种端到端的钢铁表面缺陷检测方法并取得了较好的结果,但需要大量的人工标注。印刷品缺陷检测的不同之处在于,印刷品缺陷检测有着复杂的背景信息,不存在像织物一样的固定纹理结构,因此使用提取纹理信息的方法,效果会不尽人意。此外,印刷品中包含各种颜色以及亮度信息,图片分辨率往往较大,且缺陷占整幅图像的比例也很小,这给缺陷检测带来了巨大的困难。在进行图像下采样操作时,容易丢失细小的缺陷信息,这时候就会出现漏检和误检问题。因此,在印刷品缺陷目标检测方面,Luo 等[6]提出了一种基于彩色直方图和神经网络的特征提取方法用于印刷品的表观缺陷检测,但在检测小目标缺陷时只提取颜色特征远远不够。章毓晋等[7]采用了逐像素的图像配准手段进行分区检测,极大提高了检测的精度,但印刷图像分辨率高,逐像素的分区检测效率低。随着目标检测算法的发展,现有的目标检测网络都有很好的检测效果,基于深度学习的目标检测网络大体可以分为两阶段和一阶段,其中:两阶段有R-CNN(Regional Convolutional Neural Network)[8]、Faster R-CNN[9]、SPP-Net(Spatial Pyramid Pooling Net)[10]等,两阶段目标检测算法首先进行边界框的搜索生成一系列的候选区域,利用卷积神经网络从原图中提取特征,从而进行定位和分类。一阶段目标检测算法有SSD(Single Shot multibox Detector)[11]、EfficientDet(Efficient Object Detection)[12]、YOLO(You Only Look Once)系列等,这类算法是将目标检测问题当成一个回归问题进行处理,可直接通过回归模型进行目标的定位和分类。其中YOLO 系列的目标检测算法在速度和时间效率上要优于两阶段算法。因此本文在众多目标检测网络里面选择了YOLOv4(You Only Look Once version 4)算法[13]及其对应的主干特征提取网络,对模型结构进行改进。孪生网络(Siamese network)由于具有比较两幅图像匹配程度的作用,同时也非常适合比较图像块之间的差异,因此引入孪生网络,增加缺陷候选区域选择的操作,针对候选区域进行目标检测。缺陷候选区域选择操作剔除了非关键的冗余信息,提高了计算机的运算效率,使得模型可以快速收敛,既保留了YOLOv4 算法在速度方面的优势,又提高了印刷品缺陷检测的准确率。
本文的主要工作如下:
1)在孪生相似性检测网络中引入宽核卷积核,在目标识别网络中引入特征金字塔结构,提高了小目标缺陷的特征提取效果,解决卷积过程中特征消失的问题。
2)引入Siamese网络,对标准样张和缺陷样张进行分块处理后,进行相似性检测,将检测结果转化为热度图,得出缺陷定位候选区域,提高了印刷缺陷检测的精度。
1 训练集的生成和数据增强
1.1 数据生成
对于印刷生产来说,缺陷样本的数量是有限的;而收集一些常见的印刷品缺陷样张,进行数据集的再生成,是扩增样本的一种有效途径。截取印刷样张中的缺陷内容,对缺陷内容进行提取,去除非缺陷图文部分,得到缺陷图像,对缺陷图像进行随机形变操作,得到新的缺陷图像。形变操作过程可由如式(1)表示:

式中:T为随机形变运算;D(x,y)为截取的缺陷图片;D'(x,y)是由形变操作后得到的新的缺陷图像。
对图像执行0°~180°随机旋转操作,随机旋转操作可以增加样本的多样性。每种缺陷类型随机生成若干张图像,并保存成含有透明度信息的PNG(Portable Network Graphics)格式图片。缺陷类型可大致分为漏印、脏点、卫星墨滴,这三种都是印刷生产中常见的印刷故障。选取一张用于检测的标准印刷样张,将随机生成的缺陷图像随机叠加在标准印刷样张的不同位置上,生成4000张含有不同缺陷的印刷品缺陷样张数据集,可用式(2)表示为:
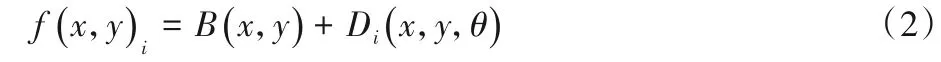
式中:i∈{1,2,…,n},n为生成数据集的数量;(x,y)表示图像像素点的位置,f(x,y)i是叠加后生成的图像;B(x,y)表示无缺陷的样稿图;θ为缺陷图片旋转的角度,Di(x,y,θ)是经过随机形变以及旋转后得到的缺陷。生成的印刷品缺陷数据集如图1所示。
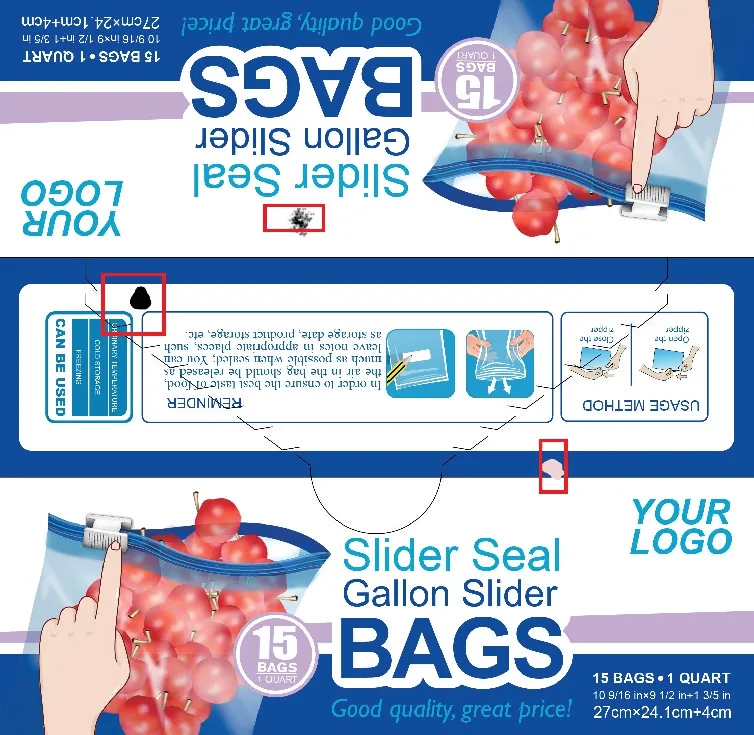
图1 生成的印刷品缺陷样张Fig.1 Sample of generated printed matter defect
由图1 可以直观地反映出,缺陷可以在任意的位置进行叠加,从而生成各式各样的缺陷图像,在短时间内,部分生成的缺陷图像甚至无法轻易地被定位与识别,生成的印刷品缺陷数据集可以较好模拟真实的印刷品缺陷情况。
1.2 数据增强
对随机生成的印刷品缺陷数据集进行添加噪声处理,添加的噪声类型有椒盐噪声和高斯噪声。为了模拟生产上的镜头抖动,在添加噪声的基础上还对图像进行了模糊。图像模糊采用了两种方式:一种是均值滤波,另一种是中值滤波。数据增强可用一个简化的模型表示:
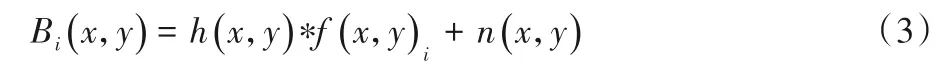
式中:i∈{1,2,…,n},n是生成数据集的数量;h(x,y)表示滤波系统;n(x,y)表示给缺陷图像添加的噪声。椒盐噪声的噪声比例设置为0.0005,高斯噪声均值参数设置为0,方差设置为0.001。两种噪声随机选取并添加在生成数据集f(x,y)i的不同位置。Bi(x,y)为生成的缺陷印刷品数据集。
将上述处理好的图像数据集Bi(x,y)进行分块处理,分割块的大小为100 × 100 像素,不满足尺寸大小的图像块用255的像素值进行填补操作,使之能够满足尺寸大小要求。将分割好的图像块进行数据清洗,清除含有缺陷目标的图像块,并按照相似程度进行分类,分类好的数据集用于Siamese-YOLOv4网络的训练。
2 Siamese-YOLOv4框架
2.1 YOLOv4算法
YOLO 算法最早是Redmon 等[14]提出的,该算法在很多领域都得到了广泛的应用。如:李云鹏等[15]将YOLO 算法应用到了汽车自动驾驶;Ren 等[16]将YOLO 算法应用到了行人计数之中。YOLO 系列算法是经典的单阶段目标检测算法,有着较好的识别速度和识别精度。YOLO 训练和检测都是在一个网络中进行的,它将物体的检测和分类问题作为一个回归问题进行处理,通过求解图像中所有物体的位置和类别及相应的置信概率,使得检测速度得到了很大的提升。随着时间的推移,Redmon 等[17-18]对YOLO 进行了迭代更新,YOLOv2、YOLOv3相继问世,YOLOv4也随后被提出,YOLOv4的算法框架如图2所示。

图2 YOLOv4算法框架Fig.2 Framework of YOLOv4 algorithm
YOLOv4 算法采用了CSPDarkNet53(Cross Stage Partial Dark Network 53)作为主干提取网络。主干网络引入了残差网络结构[19],随着网络的加深,网络的表现能力会逐渐增加,然后慢慢达到一个饱和值,最后迅速下降,而残差结构解决了网络退化的问题。在该网络中,使用Mish 激活函数[20]去代替ReLU(Rectified Linear Unit)激活函数,Mish 激活函数的速度要比ReLU 快,且占用的内存比较小,Mish 激活函数的梯度要更加的平滑。Mish激活函数如下所示:

SPP(Spatial Pyramid Pooling)[10]网络结构应用在特征提取网络的最后一层,对CSPDarkNet53 的最后一个特征层进行三次卷积后,分别利用三个不同尺度的最大池化进行处理,对处理结果进行数据拼接。该结构解决了建议框的尺寸问题,是一种可以不用考虑图像大小、输出图像固定长度的网络结构,在不同图像形变的情况之下,表现比较稳定,该结构可以适应印刷缺陷中缺陷大小形状不一的情况。将得到的特征进行上采样,与CSPDarkNet53 相同尺度的特征进行特征融合,这种反复提取特征的方法用到了PANet(Path Aggregation Network)[21]的结构。通过自底向上的路径增强,利用准确的底层定位信号增强整个特征层次,从而可以缩短底层与顶层特征之间的信息路径。提取CSPDarkNet53 倒数第三层与倒数第二层特征并与SPP 得到的特征进行数据拼接,作为第一个输出特征;主干提取网络的倒数二层与SPP 网络提取的特征上采样后融合,并与第一个输出特征下采样后进行融合,得到第二个输出特征;第三个输出特征则是通过融合倒数第二、三层以及SPP网络提取的特征得到的。最后对融合后的特征进行卷积,将得到的卷积信息进行解码,可以得到不同大小建议框的预测结果。该方法既可以保留高层的语义信息,也可以保留低层的位置信息,有利于缺陷检测的精度。YOLOv4算法有着较好的识别速度和识别精度,但是直接应用YOLOv4 算法在印刷缺陷检测场景中效果不佳,这是由于印刷图片分辨率过大,多次卷积使得小缺陷特征消失,导致了印刷品缺陷检测准确率下降,通过引入孪生网络结构,改进YOLOv4网络,使得改进后的网络拥有更高的缺陷准确率。
2.2 Siamese网络
Siamese 网络最初是为人脸识别设计的,由Zagoruyko等[22]提出,用来检测两幅人脸图像是否相似。如果用两个不同的网络去提取两张图片的特征,提取到的特征维度很可能不同,即使维度相同,不同网络提取的特征所代表的语义信息也会存在很大的差异。因此使用一个神经网络对两张图像进行特征提取,然后进行比较,这样更容易得到两张图像的特征差异。因此Siamese 网络训练出来的模型可以用于计算两张图片的相似度,所以模型学习得到的是相似性函数。通过引入孪生网络结构的方式,对分割好的图像块进行相似性检测,得到整幅图像所有分割块的图像块相似度,提取符合相似度阈值范围的图像区域,通过这样的方式可以对缺陷位置进行一个粗定位。将所有可能存在缺陷候选区域输送到YOLOv4网络中,对缺陷进行一个更为精细的定位和分类。通过这样的方式,解决了YOLOv4 针对印刷品缺陷检测效果欠佳的问题,提高了定位的精度和检测的准确率。孪生结构如图3 孪生相似性检测网络所示。

图3 Siamese-YOLOv4网络框架Fig.3 Architecture of Siaese-YOLOv4 network
将分割好的无缺陷图像块和有缺陷图像块作为输入,输入图像的属性为100 × 100 大小的RGB 色彩模式的彩色图像。其中,原图是RGB 色彩模式的无缺陷图像,相当于印刷工艺流程中客户的签样稿。缺陷图是含有缺陷目标的RGB色彩模式图像,其中包含了印刷品的缺陷信息。这两部分在特征提取的过程中是权值共享的,特征提取网络中包含了4个卷积层、3个池化层以及1个全连接层。第一个卷积层的卷积核大小为10 × 10、步长为1,较大的卷积核可以增加感受野,提取更多的关键信息,紧接着跟一个最大池化层,将池化后的信息进行卷积核为7× 7、步长为1的卷积操作,再使用一次最大池化,为了减少特征的损失,池化核的大小为2 × 2、步长为2。接着,进行一次卷积核大小为4 × 4、步长为1 的卷积操作,将得到的信息进行相同的池化操作。将池化后的结果进行一次卷积核大小为4 × 4、步长为1的卷积操作,最后进行全连接的操作,将二维信息展平成一个4096 × 1 大小的向量。由孪生网络最终可以得到两个特征向量,对特征进行分析处理用于缺陷区域的粗略定位。
2.3 Siamese-YOLOv4网络
结合YOLOv4 网络较好的识别速度和识别精度以及孪生网络对差异的高敏感性特点,提出了Siamese-YOLOv4 网络,如图3所示。将两个输入图像块得到的输出向量作差计算L1范数,所得数值作为线性分类器的输入,经过全连接层以及使用Sigmoid 函数将输出值归一化至0~1,数值越接近0 表示差异越大,数值越接近1 表示两幅图像越相似。Sigmoid 计算式如下:

式中:S表示图像块之间的相似度得分;x表示线性分类器的输出。进行数据归一化的目的是为了将数据规范到一定的区间,便于模型的计算,一定程度可以提高模型精度,让训练的模型可以快速收敛。
如图4(b)所示,通过计算原图和缺陷图分割块的相似度得分,将得分转换成热力图的形式,把缺陷候选区域进行了可视化。使用固定阈值法,将区分阈值设定为0.5,如果两幅图像的相似度小于0.5,则认为两幅图像的相似度比较低,表明该区域可能含有缺陷信息,如图4(a)所示,将整幅图像所有相似度较低的图像块提取出来,该区域为存在缺陷的候选区域。通过这样的方式可以实现缺陷的粗略定位,剔除非缺陷区域部分的冗余信息。粗略定位的区域会输送到CSPDarkNet-53主干特征提取网络中,使用改进的YOLOv4 算法对预定位区域执行一个更为精细的定位和分类,对于YOLOv4 算法来说,改进后的模型有着更快的训练速度和更高的定位精度。
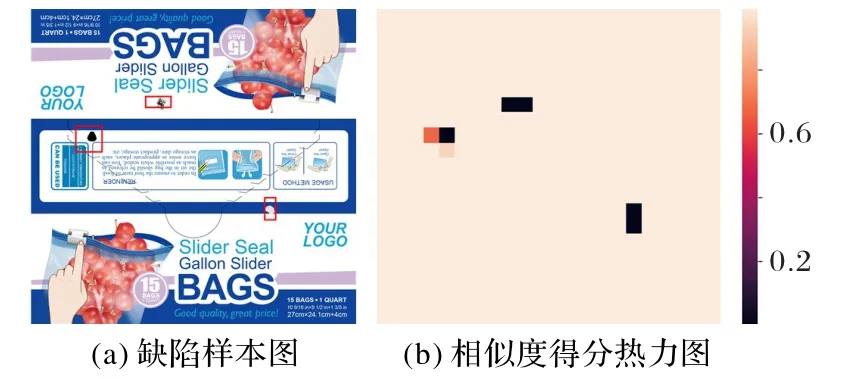
图4 缺陷样品图及其热力图Fig.4 Defect sample image and its heatmap
3 实验与结果分析
3.1 实验平台
本文所使用的训练设备的配置为GeForce RTX 2080Ti 显卡,Intel Xeon Gold 6248 处理器,256 GB RAM,软件的运行环境为Windows 10操作系统,深度学习框架版本号为torch 1.2,Python3.6用到的函数库包括cv2、matplotlib、numpy等。
3.2 训练过程
本次模型训练的过程中使用了原始生成的4000 张带缺陷样本的数据集,按照9∶1 的比例划分成训练集和测试集。经过图像分割后,训练数据集和测试数据集扩增到原来的144倍。因为印刷缺陷数据集与VOC 数据集提取的特征有共通之处,所以本文将使用VOC 数据集训练好的模型来进行迁移学习,首先在前25 批次进行冻结训练,在后25 批次进行解冻训练,初始的学习率为0.001,采用余弦退火衰减的方式,慢慢降低学习率。使用余弦退火衰减的方法后,可能会陷入局部最优解,这时候可以通过调大学习率的方法来跳过局部最优解。测试集的loss 值为每批次记录一次,当训练集和测试集的loss不再发生明显变化时,提前停止训练。
3.3 模型检测效果
本次实验使用平均准确率作为缺陷检测算法的评价指标。损失值用于度量模型的拟合程度,损失值越小,表明该模型拟合数据的能力越好。Siamese-YOLOv4 模型在测试集上损失值的变化如图5所示。
从图5 中可以看出,随着训练迭代次数的增加,Siamese-YOLOv4 模型的损失值逐渐下降。在第25 次之后,模型的损失值都逐渐趋于平稳,损失值在0.9 左右。在训练集和测试集上,损失值的下降趋势趋于同步,因此可以认为模型没有出现过拟合的情况。

图5 Siamese-YOLOv4模型在测试集上损失值的变化Fig.5 Changes in loss of Siamese-YOLOv4 model on test set
平均准确率是指每一类缺陷检测的准确率的平均值,通常用平均准确率来衡量一个模型的优劣。Siamese-YOLOv4模型的检测结果如图6 所示,从图6 中可以看出,三种缺陷类型都实现了定位与准确分类,因此该模型对于缺陷目标检测任务来说是有效的。

图6 Siamese-YOLOv4的检测结果Fig.6 Detection result of Siamese-YOLOv4
3.4 模型检测效果对比
将主流目标检测算法(EfficientDet、SSD、YOLOv3、YOLOv4、YOLOv5 以 及Faster R-CNN)与本文的Siamese-YOLOv4 在印刷缺陷数据集上进行检测准确率的对比。三种缺陷类别的检测准确率以及整体的平均检测准确率如表1所示。
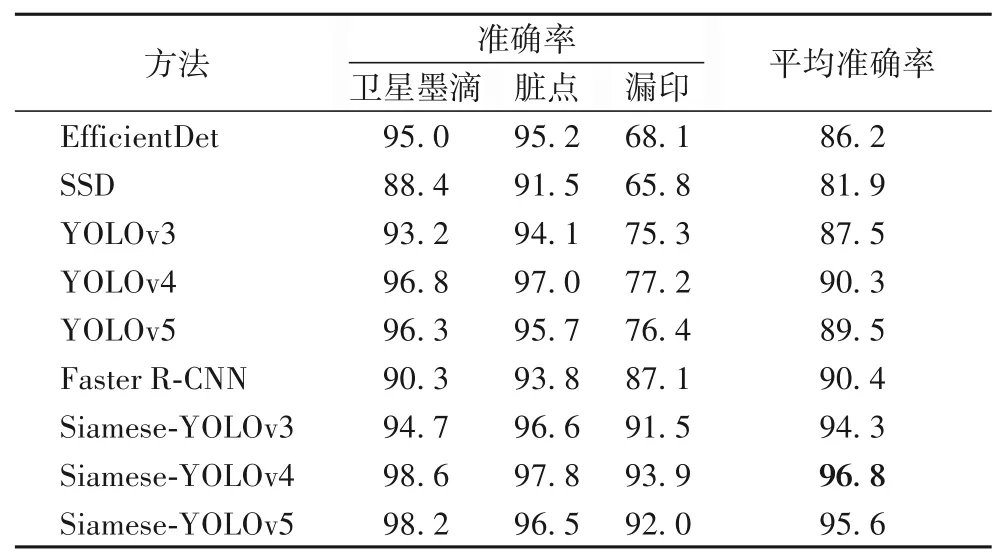
表1 不同目标检测方法的性能对比 单位:%Tab.1 Performance comparison of different target detection methods unit:%
可以看出Siamese-YOLOv4 模型在卫星墨滴、脏点以及漏印三种不同缺陷的检测准确率都要优于其他几种模型,整体的平均准确率可以达到96.8%,相较于EfficitentDet 算法、SSD算 法、YOLOv3 算 法、YOLOv4 算 法、YOLOv5 算 法、Faster R-CNN算法分别提高了10.6个百分点、14.9个百分点、9.3个百分点、6.5个百分点、7.3个百分点、6.4个百分点。
3.5 模型有效性验证
模型有效性分析采用了准确率(Precision,P)、召回率(Recall,R)、误检率(False Positive rate,FP)、漏检率(Miss Rate,MR)和平均精度均值(mean Average Precision,mAP)五种评价指标,其中准确率、召回率、误检率、漏检率和平均精度的定义分别为式(6)~(10):
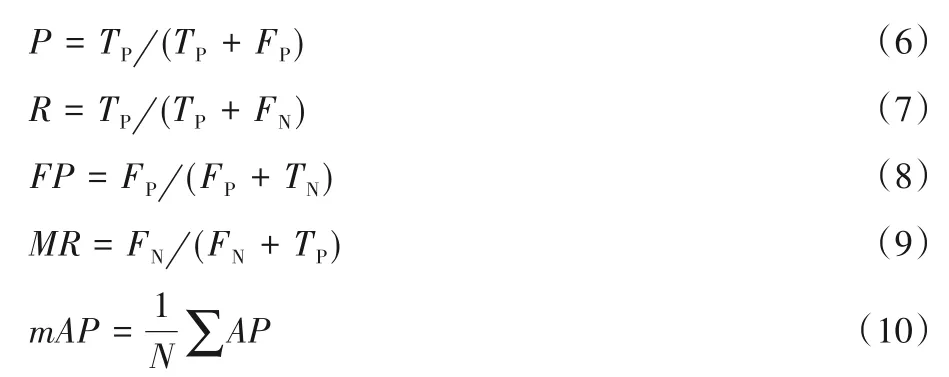
式中:TP表示真实缺陷区域被成功检出的个数;FN表示真实缺陷区域未被检出的个数;FP表示正常区域被错误检测为缺陷区域的个数;TN表示正常区域被成功检测为正常区域的个数;AP为平均精度;N表示缺陷种类个数。
根据表2 实验数据显示,各缺陷类型检测的平均准确率为96.8%,平均召回率达到了96.9%,误检率和漏检率也处在一个较低水平,因此可以认为Siamese-YOLOv4 网络模型拥有较好的缺陷检测性能。
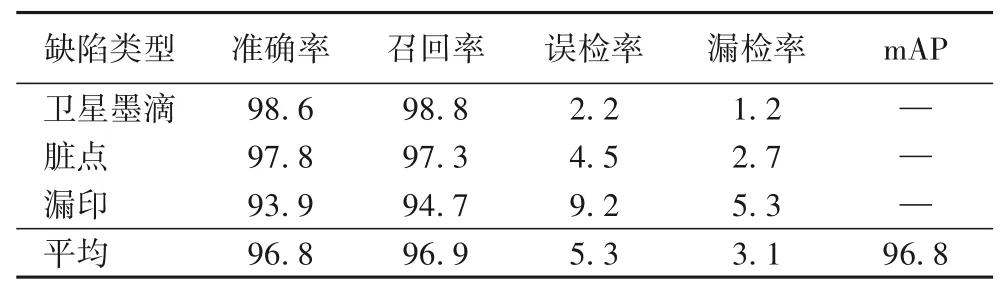
表2 Siamese-YOLOv4模型性能评价 单位:%Tab.2 Performance evaluation of Siamese-YOLOv4 model unit:%
3.6 相似性检测网络的提升效果
如图7 所示,对于漏印缺陷类型,YOLOv4、EfficientDet 和SSD 三种目标检测算法的检测结果一般,对于卫星墨滴和脏点这两类缺陷类型都有着较好的检测结果。引入孪生图像相似性检测网络后,三种目标检测算法检测准确率都有着不同程度的提升,如图7 所示,该图表示的是添加了相似性检测网络之后,不同算法基线的提升效果,其中对于漏印缺陷类型的检测准确率提升效果最为明显,究其原因这是由于未引入图像相似性检测网络之前,漏印缺陷常常会与一些复杂的背景结合在一起,容易造成漏检或者误检的情况,有了图像相似性检测的步骤,可以分析待检测样稿和标准样稿之间的相似性,剔除大量无关的背景干扰信息,保留相似性较低的区域,对这些区域进行缺陷目标检测,使得缺陷目标检测的结果有了显著的提升。因此本文提出的Siamese-YOLOv4 印刷品缺陷目标检测方法符合实际的生产要求。
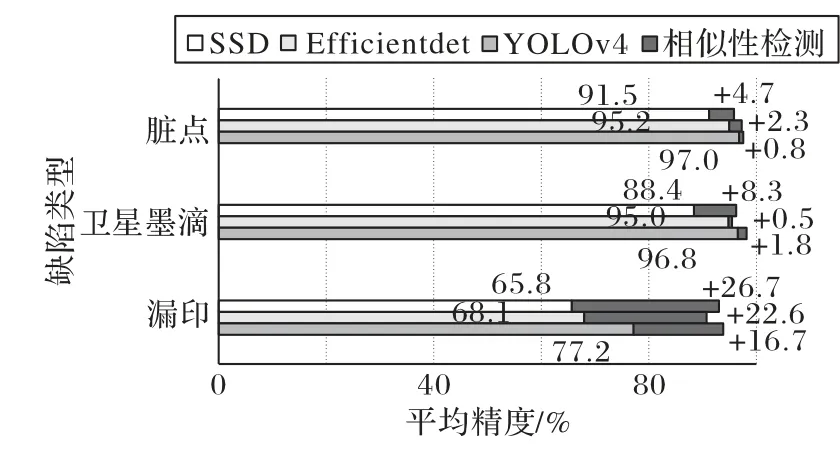
图7 相似性检测网络对不同目标检测算法的检测精度提升Fig.7 Detection accuracy improvement of similarity detection network to different target detection algorithms
3.7 光照鲁棒性验证
由于油墨表面有光泽,容易受到环境光的影响,所以在检测过程中会有局部反光、明暗程度不同的现象。
为了验证本文算法的鲁棒性,实验选取了四种不同亮度等级的光照环境,在这四种光照环境下分别进行缺陷目标检测实验,其中L=1,2,3,4表示亮度等级,亮度等级逐级增加。如图8 所示,通过观察检测结果,可以明显地发现在不同的亮度等级之下,Siamese-YOLOv4 算法均能够检测出缺陷的位置,并且能准确地对缺陷进行分类。该模型具有良好的鲁棒性。

图8 不同亮度等级下的检测结果Fig.8 Detection results at different brightness levels
4 结语
针对印刷工艺流程中缺陷检测存在的问题,本文对原有的YOLOv4 模型进行了改进,设计了新的Siamese-YOLOv4 模型。该模型在保留YOLOv4 模型本身检测效率的基础上,进一步提高了印刷品缺陷检测的准确率。针对印刷品表面复杂的背景信息以及生产上存在的镜头抖动和噪声问题,采用随机增加模糊和噪声的方法,去模拟真实的生产情况,生成用于训练的大规模样本数据集。同时对数据集进行人工分割,引入相似性检测网络,检测图像块的相似性,实现缺陷的预定位。该数据增强方法可以很好地解决缺陷图片分辨率大,且缺陷目标较小的问题。最终的实验结果表明本文所提出的模型具有良好的鲁棒性,提高了缺陷目标检测的精度,能够适应小目标缺陷检测,可应用于实际的生产过程。
然而,本文研究也有局限的地方,比如人工生成的印刷品缺陷数据集不能完全涵盖印刷生产中存在的缺陷类型,且设定的参数值并不能适应不同领域的数据集。因此可以进一步改进特征提取网络,使用自适应阈值方法,拓宽该模型的使用范围。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
视野(2019年24期)2019-12-19
科技资讯(2018年5期)2018-07-24
