
基于自编码和知识蒸馏的表面缺陷检测方法
2021-12-07 10:09刘太亨何昭水
计算机应用 2021年11期
刘太亨,何昭水
(广东工业大学自动化学院,广州 510006)
0 引言
表面缺陷检测是检验产品表面情况的重要步骤,是保证产品质量和制造效率的重要步骤。缺陷物品必须及时检测并清除生产线,否则将严重影响后续装配线,导致整体质量水平下降[1]。传统上,表面缺陷检查是手动执行的,这种检测存在采样率低、检测精度低和效率低、劳动强度高等问题。因此,利用机器学习方法来替代人工检测成为目前的主流检测方法,因为采用自动化方式替代人工检测,不仅可降低人工成本,而且可提高缺陷检测效率[2-4]。
传统的机器学习方法包括神经网络[5]、支持向量机(Support Vector Machine,SVM)[6]等。例 如,Jeon 等[7]使 用Gabor滤波器并进行边缘对检测,并且将基于直方图和梯度纹理特征输入SVM来检测板面上的划痕。Song等[8]提出了一种基于热轧钢带表面缺陷的局部二进制模式特征的方法。Ding等[9]提出了一种基于定向梯度特征直方图和SVM的织物缺陷检测方法。Chondronasios等[10]提出了一种基于灰度共发生矩阵的铝型材表面缺陷分类方法。但是,这些方法有一定的局限性,如传统的机器学习方法在现实生活中很难应用于复杂的缺陷情况,如遮挡、物体变形等,它们提取的特征水平低、不够稳固。
近年来,随着图像处理和深度学习技术的飞速发展,深度神经网络(Deep Neural Network,DNN)取得了重大成功,尤其在图像分析和识别方面[11]。深度神经网络能够构建复杂的表示,并自动学习输入和输出之间的组成关系,将输入图像映射到输出标签。在表面缺陷检测中,基于深度学习的方法是近年来的发展趋势,大致分为三类:1)基于图像分类;2)基于对象检测;3)基于像素分割分成。为了提供高精度的缺陷检测,许多研究者提出了基于深度学习的分类方法,试图设计一个复杂的网络结构,以提高检测功率和缺陷分类的性能[12-13]。然而,为了追求高精度,这些复杂的网络算法具有参数多、计算复杂、训练时间长等缺点,对实际应用条件提出了严格的要求。这些方法并不适用于那些硬件条件低的中小企业,以至于难以在实际环境中大规模使用。
针对上述问题,本文提出了一种基于自编码和知识蒸馏的表面缺陷检测方法(Surface defect Detection method based on Auto-Encoding and Knowledge Distillation,SD_AEKD)。该方法包含两个部分:缺陷检测和分类。检测模块的目的是对输入的原始图片进行缺陷的定位。分类模块的目的是将已经定位缺陷区域通过知识蒸馏方法进行类别分类。实验结果表明,该方法不仅能够精准地定位物品缺陷的区域,而且能够提高分类的精度。
1 相关工作
知识蒸馏是将知识从大模型(Teacher Model)转移到小模型(Student Model)的过程。尽管Teacher 模型(例如非常深的神经网络或许多模型的集合)具有比小型模型更高的知识能力,但这种能力可能未得到充分利用。即使模型使用很少的知识能力,评估模型在计算上也可能同样代价昂贵。知识蒸馏将知识从大模型Teacher 转移到小模型Student 而不会丧失有效性。由于较小的模型评估成本较低,因此可以很容易将其部署在功能较弱的硬件(例如移动设备)上。
近年来,知识蒸馏在许多计算机视觉任务中得到了成功的利用。Hinton 等[14]率先探索神经网络中的知识蒸馏的研究,通过研究图像分类问题,将教师网络的软输出定义为包含有用信息的知识,这些信息表示类内的相似性和多样性。Romero 等[15]利用教师网络隐藏层的中级提示来训练一个薄而深的学生网络。Li 等[16]提及的对象检测研究中,小型检测网络有望在大型网络的高级功能的监督下,学习更多有关对象表示的知识。Wei等[17]利用模拟和量化策略来训练一个非常小的检测网络,在该方法中,通过转移来自教师网络的知识来提高学生网络的性能;同时,将全精度网络转换为量化网络,而性能不会大幅下降。通过对未标记数据进行知识蒸馏,自适应蒸馏知识损失(Adaptive Distillation knowledge Loss,ADL)[18]的性能优于仅使用硬目标的数据蒸馏方法。通过采用ADL,Student 检测器的性能优于其Teacher 的性能。文献[19-20]研究了在大型网络的额外监督下训练小型语义分割网络的知识提炼策略。Liu 等[19]只是简单地将分割问题视为聚合的单独像素分类问题,用知识蒸馏策略对紧凑的语义分割网络进行训练。He 等[20]提出了一个新的亲和力蒸馏模块,将这些广泛分离的空间区域之间的长期依赖性从教师模型转移到学生模型。基于知识蒸馏技术的这些优势,本文利用其来进一步提高SD_AEKD 的检测精度,同时也使SD_AEKD具有高实时性。
2 本文方法
本文提出了一种用于物品表面缺陷检测的基于自编码和知识蒸馏的框架。该框架主要包含两个主要部分:缺陷检测和分类,如图1所示。
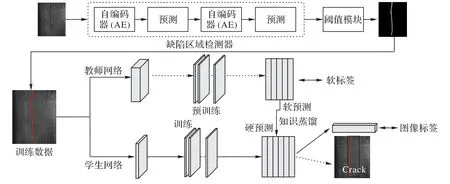
图1 基于自编码和知识蒸馏的表面缺陷检测方法流程Fig.1 Flow chart of surface defect detection method based on auto-encoding and knowledge distillation
2.1 缺陷检测
2.1.1 级联自动编码器
自编码器(Auto-Encoder,AE)网络广泛用于信息编码和重建。通常,AE网络包括编码器网络和解码器网络。该网络由一个或多个解码器层块组成。编码器网络是一个转换单元,通过它将输入图像转换为多维特征图像,用于特征提取和表示,获取的要素图中存在丰富的语义信息。相反地,解码器网络通过合并所有中间图层中所学要素映射中的上下文信息来微调像素级标签。此外,解码器网络可以使用向上采样操作将最终输出还原到与输入图像相同的大小。
由于物品表面缺陷是均匀纹理中的局部异常,缺陷和背景纹理具有不同的特征表示。利用AE 网络了解缺陷数据的表示,找出物品表面缺陷的共性。因此,物品表面缺陷检测问题变成了物体分割问题。使用编码器解码器体系结构将输入缺陷图像转换为像素预测掩码。
在级联自动编码器(Cascaded Auto-Encoder,CAE)中,新的图像分割架构基于两个AE 网络的级联,这两个AE 网络共享相同的结构。如图1 所示,第一个网络的预测掩码作为第二个网络的输入,像素标签的进一步微调在第二个网络中执行。这样,后一个网络可以增强前一个网络的预测结果。
图2 显示了单个AE 体系结构。由于物品表面膜不同,损坏点等相同缺陷具有不同的颜色。这种模棱两可的颜色会影响AE 网络的训练。因此,将原始彩色图像规范化为512 ×512 灰度图像,然后输入到AE 网络中,以减少颜色干扰并加快缺陷分割。该体系结构由编码器和解码器组成,如图2所示。
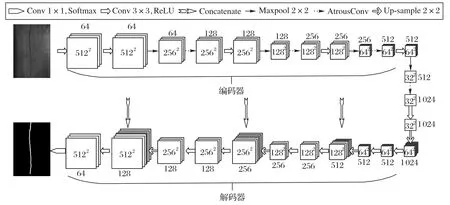
图2 自动编码器(AE)网络的体系结构Fig.2 Architecture of Auto-Encoder(AE)network
解码器网络的结构与编码器网络相似。编码器部分包括10个卷积层,每个卷积层包含3× 3卷积操作以及随后的整流线性单元(Rectified Linear Unit,ReLU)非线性操作。两个卷积层中每个层后跟2 × 2 最大池操作,步幅为2。本文在每个最大池层后将要素数量增加一倍,以减少语义信息的丢失。在两个卷积层中每个层之后,在解码器应用2 × 2向上采样操作。向上采样操作的结果与编码器部分的相应要素贴图串联,以获取最终要素贴图。在最后一层,1× 1 卷积与软最大层连接到AE网络,以将输出转换为概率图。最终预测掩码是缺陷概率图,其大小调整为与输入图像的大小相同。
上述AE 网络中具有稳定的卷积范围。此网络很难“看到”整个缺陷并集成全局上下文以生成预测掩码。在真实的工业检验环境中,产品缺陷区域的大小是不一样的以及其缺陷的形状也是多种多样的。上述网络不了解物品表面有更大的检测对象,如灰尘和纤维。因此,必须设计不同尺寸的接受字段以适应这种情况。本文对空洞卷积进行单元化,以增加网络检测大缺陷的感受野。在图3 中,图(a)表示卷积是常规的3× 3 卷积,图(b)表示卷积是因子为2 的3× 3 空洞卷积。空洞卷积将卷积中求和的像素外化,但总和像素与常规卷积相同。空白中卷积的权重为0,不参与卷积操作。因此,它们的有效感受野是7× 7。AE 网络编码器部分的常规卷积被填充1 和步幅1 所替换。AE 网络中卷积的详细参数显示在表1中。在编码器部分中,有四个卷积层被“卷积”所取代。

图3 空洞卷积示意图Fig.3 Schematic diagram of atrous convolution

表1 AE网络中空洞卷积的参数Tab.1 Parameters of atrous convolution in AE network
为了训练AE 网络,改进了像素交叉熵与重量的减少wa设计。通常,物品表面的捕获图像的背景像素比有缺陷的像素多,因此要重新加权不平衡的类,即设置wdefect=0.8 和wbackground=0.2。损失函数定义为:
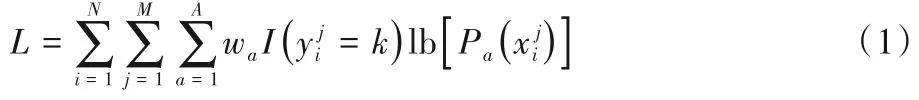
其中:wa表示权重;A=2 表示类数(背景和缺陷);N表示训练样本的大小;M表示每个图像补丁中的像素数是指标函数,当=k时,它的值为1,否则为0是第i张图像中的第j个像素补丁,表示的真实标签;Pa(·)表示像素为第a类的概率,这是Softmax层的输出。
2.1.2 阈值模块
阈值模块作为独立模块添加到ACMD 网络的末尾,主要用于进一步优化预测掩码的结果,它还可以对概率图应用像素阈值操作。本文中,给定的阈值Gs分配给最终预测掩码:

其中:ITH表示二值化后的最终图像;Ipm表示二进制化后的预测掩码图像;Gs表示细化阈值。当ACMD 训练时,Gs是检验体系结构中需要调整的唯一阈值。在ITH中,灰色值为0 的像素表示缺陷区域,灰色值为1 的像素表示非缺陷区域。为了便于显示被检测到的缺陷,在原始彩色图像上用白色标记缺陷区域的像素。
2.1.3 缺陷区域检测
当获得所有可能缺陷的语义分割结果时,将进一步使用斑点分析来找到准确的缺陷轮廓,并从缺陷图像ITH中提取基于缺陷轮廓的最小封闭矩形区域(Minimum Enclosed Rectangular area,MER)。这是因为MER 能够准确地反映缺陷区域,最终使分类模块的输入更加准确和容易。
由于MER 具有随机方向,因此本文基于仿射变换将斜MER 转换为正方向。正MER 设置为关注区域(Region Of Interest,ROI),最终缺陷区域是这些ROI。这些缺陷是从原始图像中裁剪出来,并将其输入到下一个模块进行分类。
2.2 缺陷分类
在分类模块中,将缺陷区域划分为特定类别。当被检测的物品不同时,通过成像,相同的缺陷(损伤点)可能具有不同的颜色。因此,颜色信息无助于缺陷的分类。首先,将图像的缺陷区域补丁转换为灰度图像,以减少不同背景颜色和照明的影响。其次,考虑到在工业应用中,系统检测的精度、速度和效率等都是至关重要的。虽然较大的网络可以实现高精度,但是较小的网络运行时间较少,成本更低。因此,为了更好地权衡较大和较小网络的优点,本文采用知识蒸馏的方法对物品缺陷区域进行分类。
在知识蒸馏中,为了保持Teacher 模型和Student 模型之间的功能一致性,本文中的Student 模型采用高至低分辨率网络(High-to-low Resolution Network,HRNet)——HRNet-18[21],Teacher 模型采用HRNet-32,其中HRNet-32 与HRNet-18 具有相同的架构但HRNet-32要大得多。
所提出的知识蒸馏方法通过Teacher 和Student 的平行训练进行。这意味着Teacher 和Student 的批处理大小、迭代计数、优化器以及学习率等训练条件是相同的。此外,Teacher和Student 同时训练。Teacher 经过训练可以最大限度地减小Teacher 预测结果与真实结果之间的Softmax 交叉熵损失。但是,对Student 进行训练,目的是使Teacher 最后一个卷积层的特征图FT与Student最后一个卷积层的特征图FS之间的L2损失最小。Teacher和Student模型的损失函数分别定义如下:

其中:x为输入的图像;W表示分类器的权重;p(xi)表示从训练数据获得的类的概率分布;q(xi)表示通过HRNet-32模型推导的类的概率分布;C表示输入图像的通道;H表示输入图像的分辨率。
因此,知识蒸馏总损失函数为:
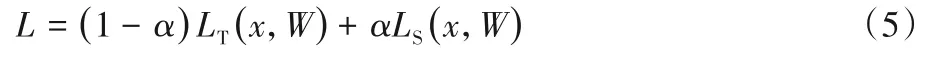
其中,α为平衡参数。在本文中,为了减少实验的复杂性,知识蒸馏的平衡参数设置为α=0.5。
3 实验设置与结果分析
3.1 数据集
本文采用两个真实的数据集来验证方法的性能。
1)DAGM 数据集。该数据集有10个类,如图4所示,每个类包含1000 个非缺陷图像和150 个有缺陷的图像。数据处理方法如下:本文使用128× 128像素窗口来滑动和剪切原始的512 × 512像素图像,对于无缺陷图像步长为128,对于有缺陷的图像步长为8,无缺陷图像的数量多于有缺陷的图像数量。对于剪切的缺陷图像,本文保留图像超过80%的缺陷部件,并混合10 种类型的图像。最终训练集包含790 个缺陷图像和5260 张无缺陷图像,测试集包含710 个缺陷图像和5040张无缺陷图像。

图4 DAGM数据集的部分样例Fig.4 Some samples of DAGM dataset
2)Magnetic-tile数据集。Magnetic-tile由6个数据集组成,如图5所示,每个数据集包括等比例的Image和正确标注图片(Ground Truth,GT),其中Blowhole 有230 张,Break 有170 张,Crack 有114 张,Fray 有64 张,Uneven 有206 张,Free 有1904张。为了更好地验证所提方法的性能,本文随机将整个数据集拆分为训练集和测试集,比率为3∶1。数据处理方法如下:本文使用128× 128 像素窗口来滑动和剪切原始的1408×512 像素图像,步长为128;对于无缺陷图像,步长为8。对于剪切的缺陷图像,本文存储了包含55%以上缺陷部件的图像,因为部分瓦片缺陷区域较小,并且在数据集中的缺陷图像数量很少。最终训练集包含588 张缺陷图像和142 张无缺陷图像,测试集包含196张缺陷图像和476张无缺陷图像。

图5 Magnetic-tile数据集的部分样例Fig.5 Some samples of Magnetic-tile dataset
3.2 评价指标
为了评估模型的性能,本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和交并比(Intersection over Union,IoU)来评价物品缺陷图像检测和分类的性能。四个评价指标的定义如下:

其中:TP、FP、TN和FN分别表示真阳性、假阳性、真阴性和假阴性;GT表示真实检测框;PM表示预测检测框。
3.3 结果分析
3.3.1 SD_AEKD的缺陷检测性能
为了评估SD_AEKD 的检测性能,将所提出的SD_AEKD方法与下面的七种方法进行实验对比分析:1)用于裂痕检测的图像处理工具箱(Image processing Toolbox for Crack detection,CrackIT)[22],这是一套全面的图像处理算法,用于检测和表征路面的表面裂纹。2)最小路径选择(Minimal Path Selection,MPS)[23],这是一种从二维路面图像自动检测裂痕的新方法,它依赖于每个图像中最小路径的定位。3)基于随机树的道路裂痕检测(Crack detection based on random Forest,CrackForest)框架[24],这是一种基于随机结构化森林的新型道路裂缝检测框架,用于道路裂痕不均匀检测。4)U 型卷积网络(U-shaped convolutional Network,U-Net)[25],这是一种全卷积网络进行语义分割的算法,用于对缺陷图像进行分割检测。5)全卷积网络(Fully Convolutional Network,FCN)[1],这是一种端到端的图像分割方法,用于图像像素级别的标签预测。6)快速区域卷积神经网络(Fast Region-Convolutional Neural Network,Fast-RCNN)[26]是一种快速对整个图像进行区域独立特征提取的网络,用于图像的目标检测。7)掩模区域卷积神经网 络(Mask Region-Convolutional Neural Network,Mask-RCNN)[27]是一种基于Fast-RCNN的目标检测网络,它在Faster R-CNN的基础上添加了一个预测分割mask的分支。这些方法涵盖了目前对表面缺陷检测的各个类别,即检测、分类和分割。
表2 给出了在两个真实数据集上的检测结果。从表2 可以看出,本文所提出的SD_AEKD 方法在数据集DAGM 上以0.9647 的准确率(Accuracy)、0.9392 的精度(Precision)、0.9578 的召回率(Recall)和0.8192 的IoU 达到最佳性能,且在Magnetic-tile 上以0.9647 的准确率(Accuracy)、0.9392 的精度(Precision)、0.9578 的召回率(Recall)和0.8192 的IoU也达到最佳性能。图6 给出了一些样例在数据集DAGM 上的检测分类结果。

图6 部分样例在DAGM数据集上的检测分类结果Fig.6 Detection and classification results of some samples on DAGM dataset
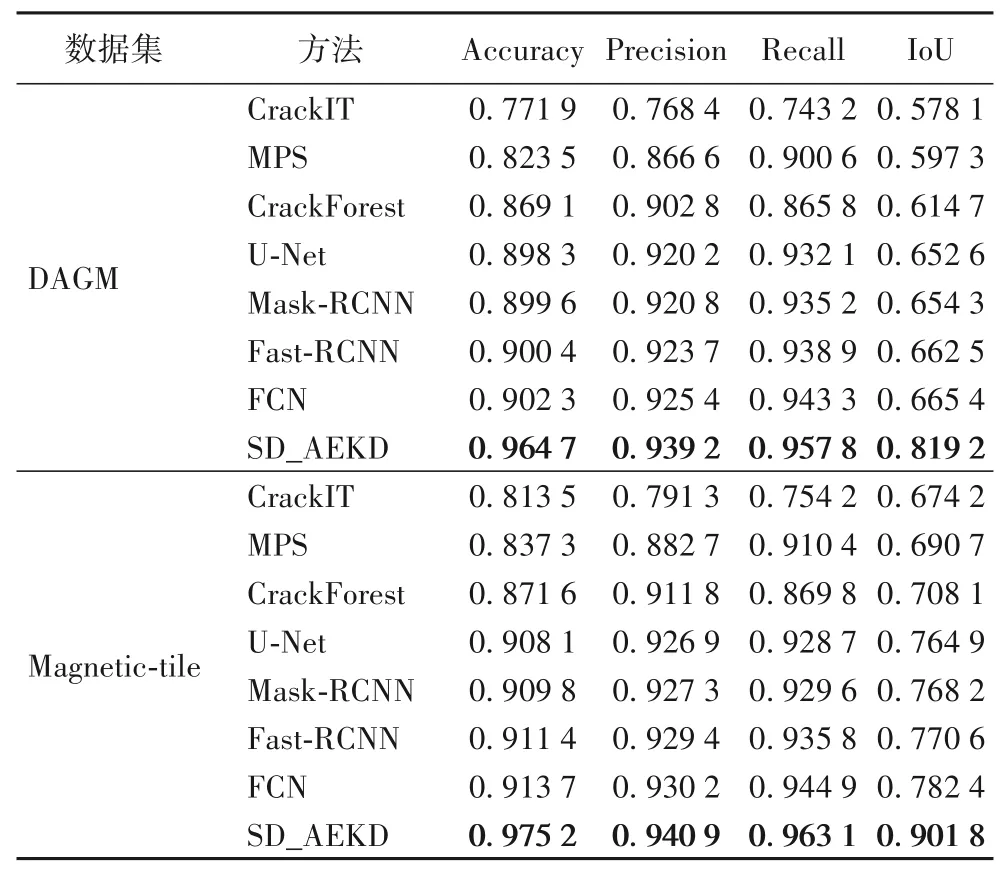
表2 不同方法在物品表面缺陷检测上的性能指标对比Tab.2 Performance index comparison of different methods in item surface defect detection
3.3.2 SD_AEKD的分类性能
为了定量评估知识蒸馏的分类性能,本文将所提出的SD_AEKD 方法与其他的三种传统的机器学习分类方法进行比较,这些方法的代码可以公开获取。
1)灰度共生矩阵(Gray Level Co-occurrence Matrix,GLCM)[10]:此方法是经典的纹理提取,其中包括四个典型的描述:能量、对比度、熵和相关性。
2)定向梯度直方图(Histogram of Oriented Gradient,HOG)[9]:它通常可以通过以下步骤获得。首先,通过将图像划分为较小的连接区域来获得单元;然后,获取单元中每个像素的梯度或边缘方向直方图;最后,通过组合这些直方图来构成完整的特征描述符。
3)HOG+SOBEL:本文以SOBEL 操作为特征计算梯度幅度,并结合以上HOG特征形成一个新特征。
取决于上述特征,使用多层感知器(MultiLayer Perceptron,MLP)进行了三个缺陷分类实验。MLP 在隐藏层和具有三个输出变量的输出层中包含15 个单元。输入层数由上述特征的尺寸决定。MLP中优化算法的最大迭代次数为1000。GLCM 功能由六个灰度级组成,并在共现矩阵中计算90°方向。HOG 中灰度值的量化为8。SOBEL 中滤镜的大小为33。表3 给出了不同分类方法的性能对比。可以看出,在DAGM 和Magnetic-tile 数据集上,三种传统的基于机器学习的浅层特征方法的平均准确率分别达到了70.54%和79.26%,而知识蒸馏的准确率相较于这些方法分别提高了19.87 个百分点和15 个百分点。图7 给出了一些样例在Magnetic-tile 数据集上的检测分类结果。

表3 不同方法在物品表面缺陷分类上的性能指标对比Tab.3 Performance index comparison of different methods in item surface defect classification
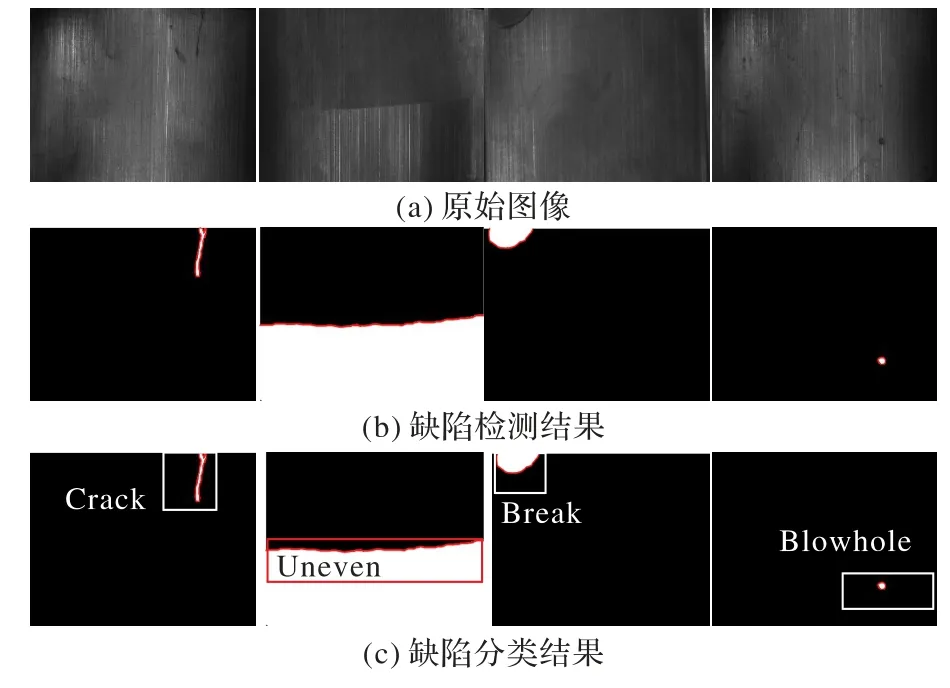
图7 部分样例在Magnetic-tile数据集上的检测分类结果Fig.7 Detection and classification results of some examples on Magnetic-tile dataset
4 结语
本文提出了一种新颖的基于自编码和知识蒸馏的表面缺陷检测体系结构,可以针对复杂的工业场景准确执行物品表面的缺陷检测和分类任务。在SD_AEKD框架中,检测模块将缺陷图像转换为仅包含缺陷像素和背景像素的逐像素预测蒙版,目的是能够精准地定位缺陷的区域。此外,分类模块利用知识蒸馏方法将所检测出来的缺陷进行类别分类。最后,在两个真实的表面缺陷数据集的实验结果表明,本文所提出的SD_AEKD方法的缺陷检测平均准确率为97.00%,在IoU评价指标上的平均得分为86.05%,并进一步验证本文所提出的SD_AEKD方法在检测和分类的性能显著提升。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
小哥白尼(军事科学)(2022年2期)2022-05-25
传感器世界(2022年3期)2022-05-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
红领巾·萌芽(2019年8期)2019-08-27
