
基于多尺度多分类器卷积神经网络的混合失真类型判定方法
2021-12-07 10:09闫钧华侯平张寅吕向阳马越王高飞
计算机应用 2021年11期
闫钧华,侯平,张寅,吕向阳,马越,王高飞
(1.空间光电探测与感知工业和信息化部重点实验室(南京航空航天大学),南京 211106;2.南京航空航天大学航天学院,南京 211106)
0 引言
随着信息科技的飞速发展,人们对图像质量的要求越来越高。高质量的图像包含了更加丰富的信息,能够有效地提升信息传递的准确性。然而图像在经过采集、压缩、处理和传输等过程中会引入多种不同程度的失真类型,这些失真图像会影响接收者对图像信息的理解。因此图像失真类型的判定对图像质量评价、图像复原以及光学链路的修正等一些领域都有非常重要的指导意义。
由于不同失真类型的特征存在相似性难以区分,所以部分失真特征的相似性成为了失真类型判定的难点之一。关于图像失真类型判定的研究大致可分为两类:第一类首先提取图像中的自然场景统计特征,然后利用机器学习实现图像失真类型的判定;第二类基于图像分类的思想,通过卷积神经网络(Convolutional Neural Network,CNN)实现图像失真类型的判定。
第一类方法主要有:Moorthy 等[1]提出的无参考图像质量指标(Blind Image Quality Indices,BIQI)算法,该算法通过提取图像在小波域的自然场景统计特征(Natural Scene Statistics,NSS),利用支持向量机(Support Vector Machine,SVM)得到单失真图像属于每个失真类型的概率;Moorthy等[2]提出的无参考空域图像质量评价(Blind Reference Image Spatial Quality Evaluator,BRISQUE)算法,该算法从空域中提取图像的结构特征和方向特征,利用SVM 实现单失真图像的失真类型判定;Mittal 等[3]提出的基于失真类型判定的图像真实性与完整性评价(Distortion Identification-based Image Verity and INtegrity Evaluation,DIIVINE)算法,该算法首先对图像进行多尺度小波分解,然后对这些参数进一步统计特性作为特征,最后利用特征对单失真图像进行失真类型判定。
第二类方法主要有:邬美银等[4]提出的基于卷积神经网络的视频图像失真(Video and Image Distortion Classfication based on CNN,VIDC-CNN)检测及分类算法,该算法通过单任务的卷积神经网络实现视频图像中的失真检测及分类;李鹏程等[5]提出的基于Gabor 小波和CNN 的图像失真类型判定算法(image distortion type determination algorithm based on Gabor wavelet and CNN,Gabor-CNN),该算法利用失真对图像信息的影响,采用Gabor 小波对图像进行特征粗提取,再通过改进的CNN进一步提取关键特征,通过Softmax分类器实现对图像的失真类型判定;Ma 等[6]提出的基于多任务端到端优化深度卷积神经网络(Multi-task End-to-end Optimized deep Neural network,MEON)的图像质量评价,该算法将全连接层基于不同的任务分离开来,同时使用提出的GDN(Generalized Divisive Normalization)函数作为激活函数最终实现单失真图像的失真类型判定。
虽然上述几种单失真判定算法能够有效地对单失真图像中的失真类型进行判定,但无法实现对混合失真图像中失真类型的判定。Yuan等[7]提出了基于多任务卷积神经网络的局部混合失真图像质量评价(Locally and Multiply Distortion Image Quality Assessment,LMDIQA)算法,该算法搭建了三个卷积神经网络分别实现对图像是全局失真还是局部失真的判定、对图像混合失真类型的判定以及对图像质量的评价;Liang 等[8]提出了基于卷积神经网络的多标签学习(CNNbased Multi-Label Learning,MLLNet)混合失真类型判定算法,该算法首先将多标签分类问题转换成多分类问题,然后使用卷积神经网络模型来同时训练所有分类器,最终把各分类器的分类结果进行融合,实现对混合失真图像的失真类型判定。上述两种混合失真类型判定算法能够有效对特有的几种混合失真类型进行有效的判定,但这两种算法未采用多种不同尺寸的卷积核对失真图像进行更加准确的失真特征提取,因此混合失真类型判定算法的判定精度仍然存在很大的提升空间。同时,这两种混合失真类型判定算法采用问题转化的思想来解决混合失真类型判定的问题,因此随着判定的混合失真类型种类增加,网络模型越来越复杂,判定精度也随之降低。
针对上述两种混合失真类型判定算法的不足,本文在卷积神经网络研究的基础上,提出了一种基于多尺度多分类器卷积神经网络的图像失真类型判定方法,相较于现有的混合失真类型判定方法,能够对更多种类的混合失真类型进行更加精确的失真类型判定。
1 图像混合失真类型判定网络结构
如图1 所示,本文提出的多尺度多分类器卷积神经网络分为两个部分。
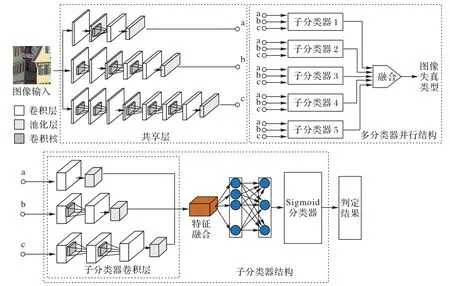
图1 图像混合失真类型判定方法结构Fig.1 Structure of image multiply distortion type judgement method
1)第一部分是设置共享卷积层,用于提取图像的浅层特征。由于不同种类的失真类型对图像区域大小的影响不同,为了保证卷积层能够更加充分地提取失真特征,因此本文采用了多种不同感受野的卷积层来提取图像的失真特征。
2)第二部分是多分类器并行结构。将不同感受野的浅层特征图分别输入到五个子分类器相应的通道中,针对各个子分类判定的失真类型进行特征提取得到深层特征图并将深层特征图进行融合;通过全连接层对特征进行融合提炼,输入到Sigmoid 函数分类器中得到失真类型;最终将五个子分类器的判定结果进行融合,得到图像的混合失真类型。
相较于现有的两种混合失真类型判定算法,本文方法存在以下优势:1)通过信息熵阈值从失真图像中截取含有边缘等其他高频信息的图像块,保证输入图像中存在丰富的失真信息;2)将图像块输入到3× 3、5× 5和7× 7不同感受野的卷积层中对失真图像进行更加有效的失真特征提取,通过最大值池化得到浅层特征图像;3)采用多标签分类的思想解决混合失真类型判定问题,可以准确地判定出更多种类的混合失真类型。
2 图像单失真类型判定方法
2.1 样本标签
每幅混合失真图像块对应的失真类型标签采用多热标签编码。假设中各元素分别代表JPEG2000、JPEG、高斯白噪声(White Gaussian Noise,WN)、高斯模糊(Gaussian blur,Gblur)和快速衰落失真(fast fading)五种失真类型。当混合失真图像存在某种失真类型时,则对应元素的值为1;如果不存在该种失真类型时,则对应元素的值为0。具体的标签设定方式如表1所示。

表1 混合失真类型标签设定Tab.1 Multiply distortion type label setting
2.2 图像浅层特征提取
为了使深层特征图能够更加准确提取出图像的混合失真特征,本文方法首先对原始图像进行浅层特征的提取,同时利用卷积神经网络对混合失真图像进行失真类型判定,其判定的精度与卷积核的大小密切相关。尺寸大的卷积核感受野范围大,有助于对全局信息的提取,同样也会导致图像细小特征的丢失。尺寸小的卷积核能够充分提取图像的局部特征,当图像局部信息过少时不能提取出图像的有效特征信息。在采用单一卷积核的卷积层结构时,会导致图像全局与局部特征信息在卷积提取的过程中有所丢失,造成判定精度下降。因此本文参照Inception 模型[9]采用多通道卷积层结构利用不同尺寸的卷积核提取图像特征,从而减少图像信息的损失。为了减少网络模型中的参数,参照视觉几何组(Visual Geometry Group,VGG)模型[10]卷积核采用堆叠方式将3× 3 的小卷积核替代尺寸为5× 5和7× 7大卷积核。
浅层特征提取的网络结构细节如图2 所示,卷积层中采用三通道的结构设计,从左往右分别代表对原图像进行感受野为3× 3、5× 5、7× 7 的特征提取;同时各通道第一个最大值池化之前每层卷积核个数均设置为32,之后的每层卷积核个数均设置为64。
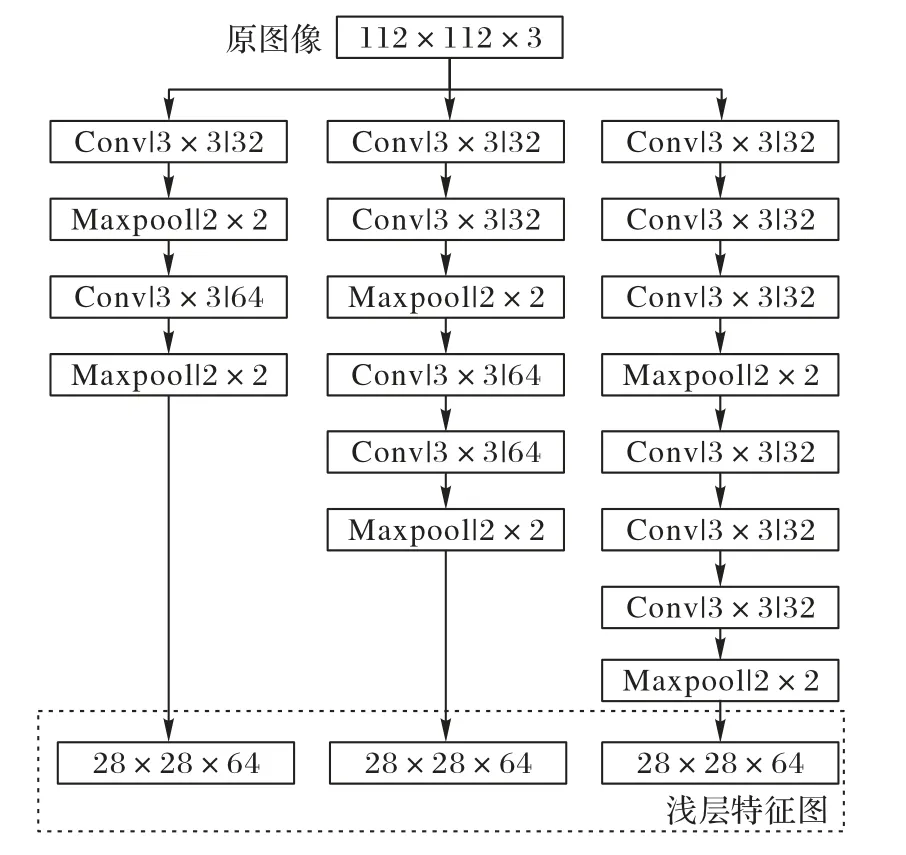
图2 浅层特征提取网络结构Fig.2 Shallow feature extraction network structure
2.3 子分类器结构
2.3.1 图像深层特征提取
将不同感受野的浅层特征图分别输入到每个子分类器相应感受野的卷积层中,针对每个子分类器需要判定的失真类型对浅层特征图进行更深层次的特征提取,最终得到每个子分类器的深层特征图。子分类器卷积层结构如图3 所示,输入到每个子分类器中三种不同感受野的特征图维度均为28×28× 64,子分类卷积层中卷积核个数设置为128,通过最大值池化最终得到每个子分类器的三种不同感受野的深层特征图,每种感受野的深层特征图维度均为14 × 14 × 128。将三种不同感受野的特征图拉伸成一维向量并进行拼接,实现不同深层特征的融合。
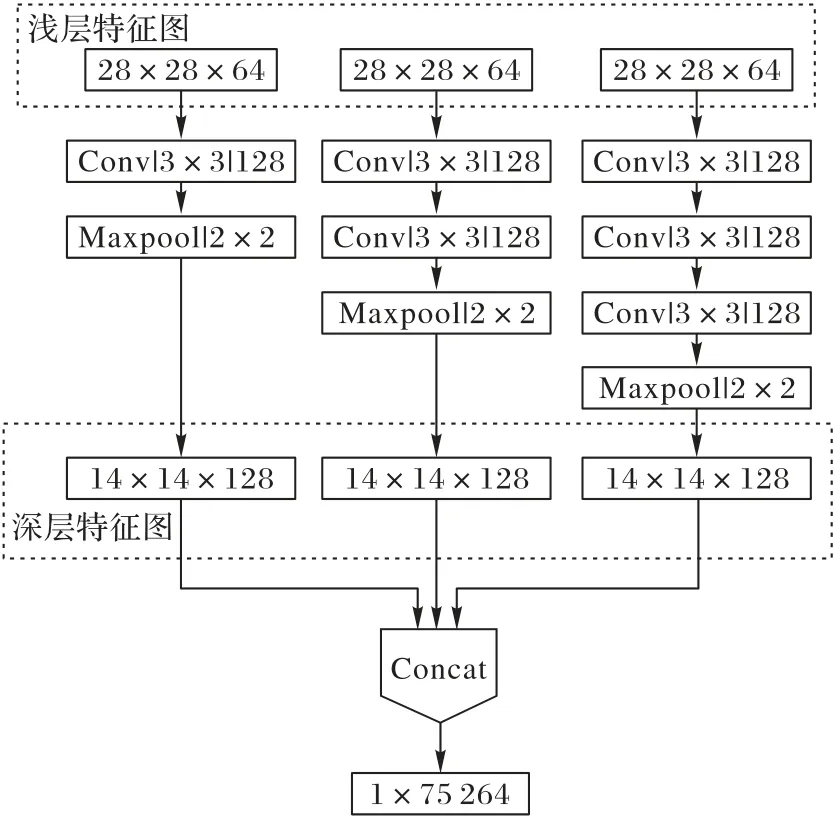
图3 深层特征提取网络结构Fig.3 Deep feature extraction network structure
2.3.2 子分类器判定图像失真类型
全连接层对不同感受野的深层特征信息进行有效的融合与提炼,最终将全连接层最后一层的值输入分类器中,实现混合失真类型的判定。为了加快网络的训练速度以及防止网络出现过拟合的情况,全连接层采用了线性整流函数(Rectified Linear Unit,ReLU)[11]和批量归一化(Batch Normalization,BN)[12]的组合方式。
ReLU 激活函数能将神经元中小于0 的神经元置为0,保证了神经元之间的稀疏性,同时也防止了网络过拟合。ReLU激活函数定义如式(1)所示。

批量归一化(BN)能够保留全局特征,同时也能有效地约束每层神经元的分布范围,有利于网络的收敛,加快网络的训练速度。批量归一化(BN)定义如式(2)所示。

其中:x为全连接层神经元的权值;mean为全连接层神经元权值的平均值;δ为全连接层神经元权值的方差;C是为了避免分母为0添加的一个极小值,取值为0.001。
全连接层最后一层输出的四个值通过Sigmoid 函数分类器最终得出每个子分类器的类型判定结果。Sigmoid 分类器定义如式(3)所示。

其中:xi为全连接层最后一层的神经元值。
2.4 融合子分类器判定结果
采用多分类器并行的结构可以减少每个分类器的分类数量来提升分类精度[13];同时采用多分类器并行的结构可以增加分类器的数量,一定程度上能够防止混合失真类型的误判。本文的判定算法中共设定五个子分类器,每个子分类器分别判定四种失真类型。将五个子分类器对应的失真类型概率值相加取均值,均值最大的两种失真类型即为图像的混合失真类型。
如表2 所示,假设混合失真图像中存在JPEG 和Gblur 两种失真,五个子分类器分别对图像中的失真类型进行判定,判定的子分类器将JPEG 和Gblur 的混合失真类型误判为JPEG2000 和Gblur 混合失真类型,同时其他四个子分类器判定结果正确。将五个子分类器的判定结果进行融合,最终依旧能正确得到该幅图像中存在的JPEG 和Gblur 两种失真类型。通过表2 可以看出,采用多分类器并行的结构并将每个子分类器的分类结果融合的方法,在一定程度上能够防止失真类型的误判。
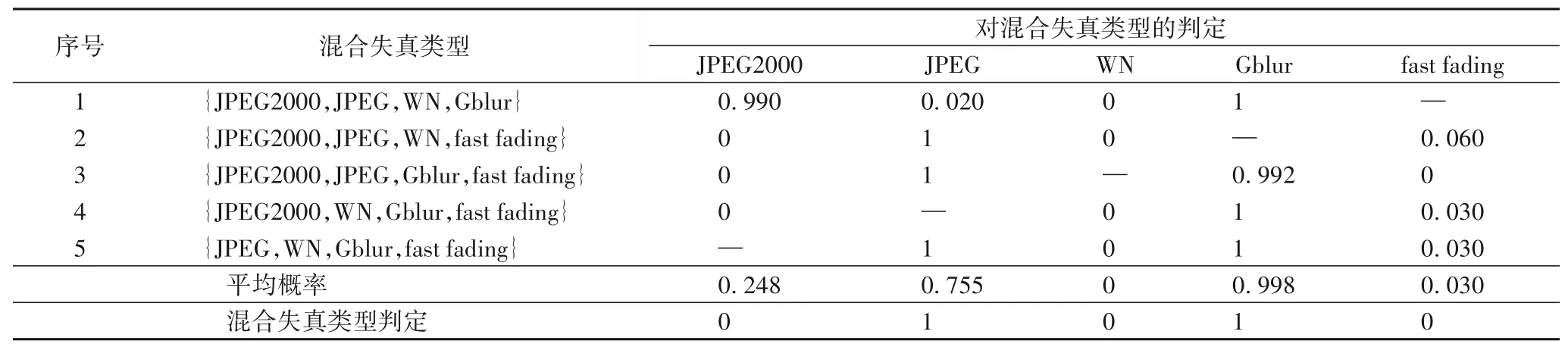
表2 子分类器判定结果融合样例Tab.2 Fusion samples of sub-classifier judgement results
2.5 多尺度多分类器卷积神经网络参数更新
网络模型使用Sigmoid交叉熵函数作为损失函数,采用随机梯度下降的方式更新网络中的参数。具体损失函数如下:
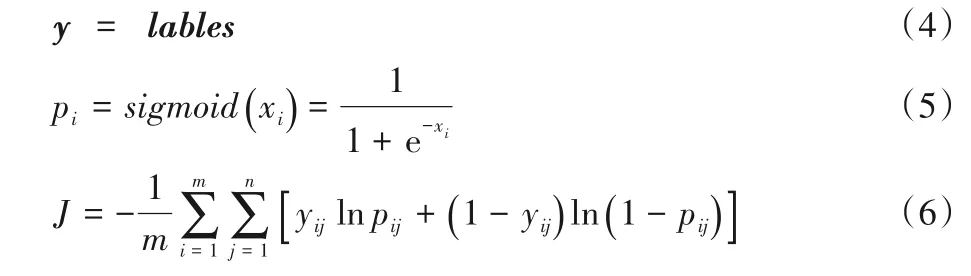
其中:m表示每个批中的图像块数量,批大小取值为32;n表示失真类型的数量;y为多热编码的标签值;lables为混合失真类型的标签值;pi为网络的预测值;xi为全连接层最后一层的神经元值。
通过随机梯度下降方法自适应地更新每个参数。网络中所有权重参数更新方式如下:

式中:α是学习速率,取值为0.01;l是网络每一层的序号。
3 实验与结果分析
3.1 混合失真图像数据库的建立
目前大多数失真图像数据库都是单失真数据库,如LIVE(Laboratory for Image and Video Engineering)[14]、CSIQ(Categorical Subjective Image Quality)[15]等。混合失真图像数据库数量相对较少,目前国内外图像质量评价等领域采用的混合失真图像数据库主要包括LIVE-MD(LIVE Multiply Distorted images)[16]、MDID(Multi-Distortion Image Database)[17]等。由于LIVE-MD 和MDID 等混合失真图像数据库中图像的失真类型较少或者失真图像数量较少,因此本文建立了自然场景混合失真图像数据库(Natural Scene Multiply Distorted Images Database,NSMDID)。
NSMDID 中的参考图像数据来源于LIVE 数据库的28 幅不同场景的参考图像。每幅参考图像引入JPEG2000、JPEG、高斯白噪声、高斯模糊和fast fading 这5 种失真类型中的任意2 种,共10 种混合失真类型。同时每种失真类型对应6 种随机的失真程度,每一幅参考图像的一种混合失真类型对应36幅不同程度的混合失真图像,每种混合失真类型的图像数量约为1044幅。
部分混合失真图像样张如图4所示。

图4 混合失真数据库(NSMDID)部分样张Fig.4 Some samples of Natural Scene Multiply Distorted Image Database(NSMDID)
3.2 网络结构对比实验
为了能够更好地确定网络的整体结构,采用控制变量法,对网络结构进行改变并实验,最终确定网络的最优模型。网络结构对比实验中,共采用三种网络结构进行实验:第一种网络结构采用单个分类器对图像进行失真类型判定;第二种网络结构则是在子分类器结构中不设置卷积层,不对特征图进行更深层次的特征提取;第三种网络结构则是本文最终采用的网络结构,最终的实验结果如表3所示。
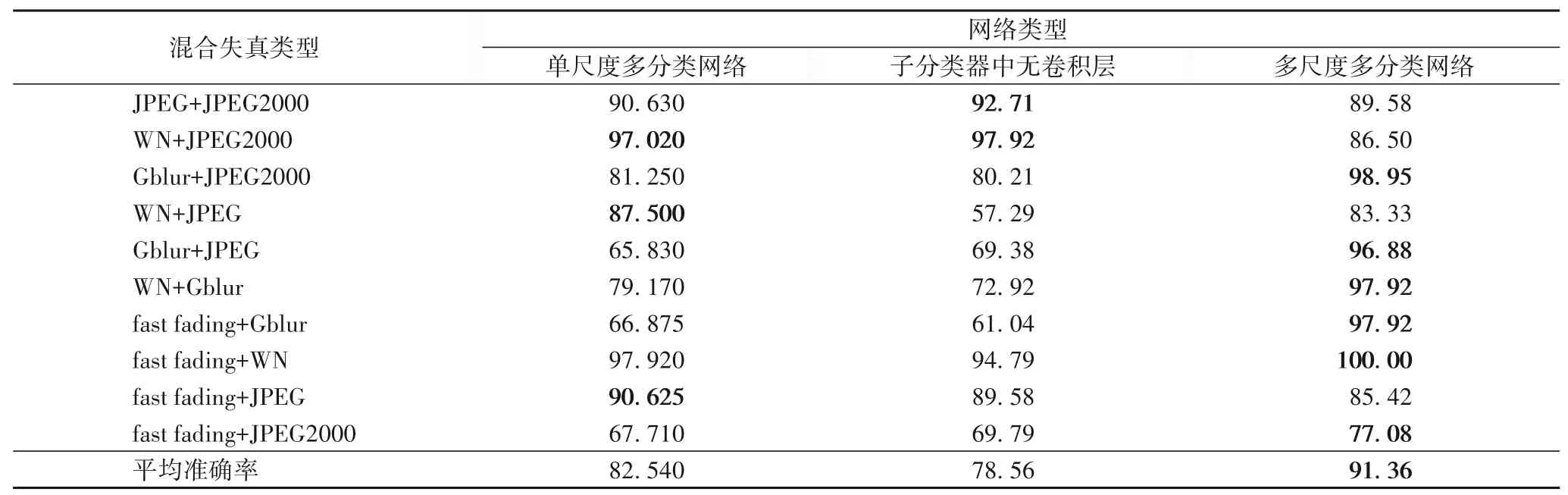
表3 不同结构的混合失真类型判定方法对混合失真类型判定的的准确率 单位:%Tab.3 Accuracies of multiply distortion type judgement methods with different structures for multiply distortion type judgement unit:%
根据最终的实验结果可以看出,多尺度多分类器卷积神经网络相较于其他两种网络结构,能够更加准确地判定出图像中存在的混合失真类型。
3.3 混合失真判定方法在混合失真数据库上的结果与分析
本文将混合失真图像数据库NSMDID 中所有样本的80%用于训练,10%用于验证,10%用于测试,训练次数为50000,最终得到图像失真类型判定的准确率。MLLNet 算法为图像混合失真类型判定方法,因为该方法判定的混合失真类型数量较少,不适合与本文方法进行对比。本文实验侧重展示了混合失真图像中存在的失真类型的判定准确率,分析了多尺度多分类器卷积神经网络算法的混合失真类型判定性能。本文实验所用测试平台为:E5-2640 处理器,主频为2.40 GB,GTX1080Ti 显卡,显存为11 GB,64 GB 内存。实验系统为Windows 7,实验软件为Python3.6.1+Tensorflow1.9.0(GPU版本)。
本文混合失真判定方法对图像的失真类型判定的准确率如表4所示。由表4结果可以看出,本文方法对混合失真图像数据库NSMDID 的失真图像进行失真类型判定,平均准确率达到91.4%,表明了该方法对于图像失真类型判定有较好的实用性。从失真类型角度分析,本文提出的方法对于fast fading+WN 的判定准确率最高,达到了100%;对于混合失真类型中有高斯模糊失真类型的失真图像判定准确率均大于95%。单失真图像在加入高斯模糊的失真类型时,既能够在图像中保留模糊的失真特征,同时也能够保留图像另外一种失真类型的部分失真特征,所以混合失真类型中存在高斯模糊的混合失真图像判定精度高。

表4 本文混合失真类型判定方法在NSMDID上对图像混合失真类型判定的准确率 单位:%Tab.4 Accuracy of proposed multiply distortion type judgement method for image multiply distortion type judgement on NSMDID unit:%
图5 以混淆矩阵的形式给出了不同混合失真类型之间的判定结果。
由图5 可以看出,当混合失真类型中存在JPEG 和JPEG2000 时,混合失真图像的失真类型判定准确率都低于90%,同时fast fading+JPEG2000失真类型的判定准确率最低。这是因为JPEG 和JPEG2000对图像进行压缩时分别采用了离散余弦变换和离散小波变换,在失真程度比较大的时候,这两种失真类型会将其他失真类型的特征遮盖住,主要表现出JPEG 和JPEG2000 的失真特征,所以存在JPEG 的混合失真图像会被判定为存在JPEG 的其他混合失真类型,同样存在JPEG2000 的混合失真图像会被判定为存在JPEG2000 的其他混合失真类型。
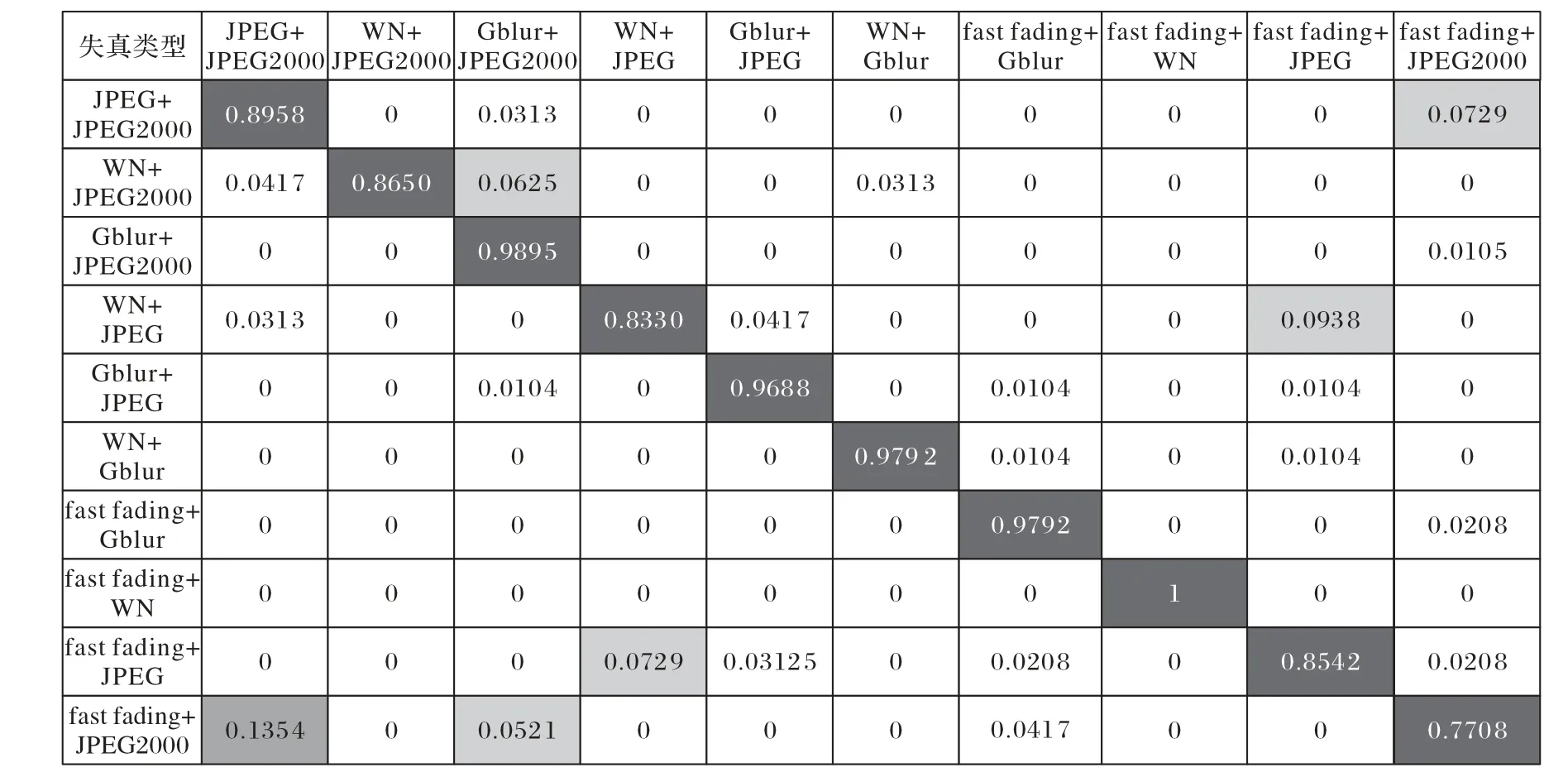
图5 不同混合失真类型之间判定结果的混淆矩阵Fig.5 Confusion matrix of judgement results of different multiply distortion types
4 结语
对图像进行失真类型判定是失真图像复原以及光学链路修正这两个领域的重点研究方向之一。本文根据失真类型对图像中不同频率信息的影响,提出了一种基于多尺度多分类器卷积神经网络的混合失真类型判定方法。首先,在预处理阶段利用信息熵阈值截取的方法从原始图像中得到含有边缘等其他高频信息的图像块;其次,相较于LMDIQA 与MLLNet算法卷积层结构设置,本文方法设置不同感受野的卷积层结构从失真图像中提取不同尺度的特征,提升失真类型的判定精度;最后,相较于采用问题转换的思想解决混合失真类型判定问题,本文采用多标签分类思想解决大量混合失真类型判定具有更好的效果。在图像失真类型判定领域中,本文所提方法可解决含有两种单失真类型的混合失真判定问题,但在实际成像过程中,形成的图像往往存在两种以上的混合失真类型,针对更加复杂的混合失真类型的判定有待进一步的研究。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电机与控制学报(2018年9期)2018-05-14
软件导刊(2017年4期)2017-06-20
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
