
基于深度学习的开放场景下声纹识别系统的设计与实现
2021-12-06 02:23郭新罗程方邓爱文
南京信息工程大学学报 2021年5期
郭新 罗程方 邓爱文
0 引言
声纹作为生物特征识别中的一种行为特征,因其蕴含丰富的个人信息,比如性别、年龄、情绪、语种等,被作为身份识别的一种方式,且因其伪造难度高、隐私性弱、辨识性强等优势,近些年来引起了业界广泛的关注.2018年被称为“声纹元年”,是声纹技术迈向产业化的重要转折点,这一年,中国人民银行发布了《移动金融基于声纹识别的安全应用技术规范》(JRT0164—2018)[1].声纹识别技术在国内正逐渐被应用于金融、社保、公安、智能家居等重要领域.
在学术界,声纹识别又称说话人识别,它是提取语音信号中能够表征说话人个性特征的信息,利用传统机器学习或深度学习,自动地实现说话人身份识别的一种生物特征识别技术.声纹识别(Speaker Recognition,SR)分为声纹辨认(Speaker Identification,SI)和声纹确认(Speaker Verification,SV)[2],其中声纹辨认是1∶n任务,声纹确认是1∶1任务,本文算法主要是基于SV的,整个系统的实现是两者兼有.目前,说话人识别应用的痛点是短时语音和基于开放环境的噪声影响,这就是本文的主要研究内容之一.
20世纪90年代,声纹识别最经典的模型是GMM-UBM模型及i-vector,在深度学习之前,它们一直是占据业界的主流技术.近些年来深度学习下的声纹研究已呈现愈来愈繁荣的局面,从深度卷积网络下的d-vector技术到x-vector技术[3],尤其x-vector是当前声纹领域中主流的模型框架.x-vector框架下的主要研究内容包括声音预处理、特征提取层、特征编码层和损失函数的优化.对于声音预处理,常用的是MFCC(Mel-scale Frequency Cepstral Coefficients)和Fbank(FilterBank),当然也可以使用原始语音,但原始语音的训练需要强大的内存和算力,比较耗费成本;特征提取层网络主要是TDNN[4]、DCNN[5]和RNN[6];特征编码层的作用是将不等长帧级别的语音特征转换成等长的语句级特征,以方便特征的比对,目前主流的编码层融合技术有统计池化SP[7]、 ASP[8]、NetVLAD[9]及GhostVLAD[9]等;损失函数方面除了应用分类损失函数外,还根据声纹模型的本质结合了度量损失函数[10],也取得了优异的性能.
本文的工作主要是设计并实现一套基于深度学习模型下声纹识别系统.该系统的算法是基于端到端的深度声纹模型,能实现特征类间距离增大、类内距离减小的目标,由此改善短时语音和混叠噪声影响下声纹识别模型的可辨别性,且参数量较少,更适合部署在嵌入式硬件上,同时,性能依然能够与目前最优秀的性能比肩.硬件方面是利用Raspberry Pi实现实时、准确地操作,以得到良好的用户体验,达到实际场景的应用需求.
1 声纹识别系统
本文的声纹识别是基于深度学习的,深度学习声纹的框架可以分为声纹录入和识别两个阶段.深度学习声纹识别系统的框架如图1所示.

图1 深度学习声纹识别系统框架Fig.1 Framework of deep learning based SR system
如图1所显示,声纹模型的建立需要大量的训练实验,才能构建合适的模型,声纹建模视为训练阶段,声纹录入和识别阶段就是测试阶段.
本文目标是设计并制作一个能实际应用的声纹识别系统,可以实现以下功能:
1) 实现用户注册和身份识别功能;
2) 实现开放场景下声纹识别的实时性,即短时内完成声音采集、注册和识别;
3) 实现可视化识别结果;
4) 实现脱机离线运行功能.
要实现以上功能需求,需设计声纹识别系统的软件部分和硬件部分.
2 声纹识别系统的软件设计
2.1 软件框架结构
该软件系统主要包含声音采集模块、声音预处理模块、特征提取模块、注册与识别模块和结果输出模块这五部分.为了充分发挥系统性能和方便代码维护和更新,本软件使用了多线程的编写方式.声纹识别主要分为三个线程:声音采集子线程、主线程、注册和识别子线程.声音采集子线程负责调用麦克风阵列采集声音,然后触发子函数将声音回传到主线程中.主线程负责整个软件程序的工作逻辑和各种工具函数调用,同时负责GUI的绘图和刷新、声音采样和预处理.注册和识别子线程负责提取声音特征、特征匹配和识别判断.软件系统总体流程如图2所示.
2.2 算法框架结构
图2中声纹识别模型的好坏直接由声纹识别的算法决定,如何设计一个优秀的算法是本工作的关键.

图2 声纹识别软件总体流程Fig.2 Overall flow chart of the SR software
该声纹识别任务的算法框架主要包括四个部分:输入特征帧、主干网络(特征提取器)、编码层和损失函数,如图3所示.其中输入音频为变长的帧级特征,经过预处理后,成为特征为40维的对数梅尔频谱特征,即Fbank.

图3 声纹系统算法框架Fig.3 Algorithm framework of the SR system
2.2.1 主干网络
主干网络,也称帧级别特征提取器.该网络由Squeeze-and-Excitation(SE)模块[11]和快速resnet34网络[12]组成.主干网络可接受任意长度的语音作为输入,并产生任意长度的帧级别特征.Fast-ResNet34结构与原始34层ResNet网络结构相同.但是,为了降低计算成本,Fast-ResNet34中的每个残差模块仅使用原始通道数量的1/4,以此作为特征提取器,可以有效提取局部多帧声学特征.
2.2.2 编码层
SV中编码层的作用就是编码声纹特征为特定的语句长度,即将变长的帧级特征转化成定长的语句级特征,以最大程度保留整体特征,这里使用差分化编码方式,以捕捉特征帧之间的静态特征和动态特征,差分化编码层结构如图4所示.

图4 差分化输入的编码结构Fig.4 Encoding structure of differential input
图4中的delta是差分化编码,差分化公式可表示为

(1)

NeXtVLAD原本是用在视频压缩上的一种编码方法,本文将其引入到SV任务中,实验结果表明NeXtVLAD在声纹识别中也具有优秀的表现[5].NeXtVLAD[13]与NetVLAD[9]性能相似,但模型参数大大减少,提升了训练的收敛速度.
如图4所示,假设特征提取器输出的隐藏层特征为fl,那么输入编码层的特征经过一阶差分和二阶差分的拼接,输入编码层的隐藏特征可以表示为
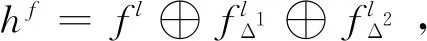
(2)
式中Δ1代表一阶差分,Δ2代表二阶差分.
那么经过编码层的特征向量可表示为
yf=fNeXtVLAD(hf).
(3)
经过一个全连接后,得到声纹特征embedding的表示为
x=FC(yf).
(4)
2.2.3 损失函数
声纹识别在实际应用场景中是开集任务,兼具分类和小样本学习两种属性,本文使用组合函数[5],即融合了基于间隔的分类损失函数LAMS[14]和基于小样本的原型余弦损失函数LCP[15],如式(5)所示:
L=LCP+βLAMS,
(5)
式中

(6)

(7)
N代表一个minibatch中说话人的个数,eSn,n和eSn,j代表相似矩阵,θyi代表目标角度,权重β=1时可以达到最好的效果,s是一个缩放因子,设为30.
损失函数LAMS是明确鼓励声纹类间距离拉大,LCP可以在声纹特征中找到与目标样本接近的原型来实现度量空间的优化,使得同类之间距离拉小,同时原型网络也可以很好地处理训练集中未曾出现的样本归属问题,大大提升了模型的鲁棒性.
3 声纹识别系统的硬件实现
3.1 硬件结构
声纹识别系统的硬件主要包括树莓派(Raspberry Pi,RPi)核心板、电源模块、麦克风和显示屏.该系统算法是基于Ubuntu系统环境进行开发、调试和部署进行的.其结构示意和实物图分别如图5和图6所示.

图5 声纹识别硬件结构示意图Fig.5 Schematic of the SR hardware

图6 声纹识别系统实物图Fig.6 Physical picture of the SR system
其中Raspberry Pi核心板是4 GB、4B的配置套件,具有高计算能力和价格低廉等特点.其CPU使用的是ARM的Cortex-A系列种的A72,是ARM首次采用64位ARM v8-A的四核处理器,时钟频率为1.5 GHz,树莓派4B的GPIO引脚的速度50.8 kHz,比树莓派3B提升了2倍,性能提升的同时价格并没有明显上涨;电源使用可以支持树莓派的UPS板+100 00 mA电池的扩展板;麦克风利用支持树莓派的ReSpeaker Pi的麦克风阵列,可实现3 m拾音,支持双麦克风,声音更加清晰;显示屏使用5寸的IPS电容触摸屏,分辨率800×480,可以实现PWM亮度调节.
3.2 GUI设计
声纹识别系统的人机交互界面GUI是基于PyQt5 开发的,PyQt5 是基于图形程式框架Qt5 的python 接口.该识别系统的人机交互界面是基于实际需求而设计的,力求简洁大方、易于操作.如图7a和7b所示.

图7 声纹识别系统人机交互界面Fig.7 GUI of the SR system
该交互界面结构框架分为系统登录模块、用户信息管理模块、声纹信息管理模块、声纹参数配置模块和识别结果输出模块.通过对声纹交互系统的设计与部署,极大程度地提高了声纹管理的效率,更好地促进了声纹技术的发展.
4 实验结果分析
下面通过实验验证所提算法的先进性以及系统的有效性和实用性.
4.1 算法先进性
在说话人识别中,常以FAR为横坐标、FRR为纵坐标绘制成一条曲线(ROC曲线),当此曲线同45°角,即y=x直线相交时候交点对应的值,称为EER,此时FRR=FAR,此评价指标最常用于说话人识别中,其中EER是错误拒绝率FRR(False Rejection Rate)和错误接收率FAR(False Acceptance Rate)相等时的错误率,通常EER值越低代表性能越好.
表1显示了本文算法在VoxCeleb-1和VoxCeleb-2上性能和模型参数的优越性.从表1可知,本文的基于差分编码的声纹识别算法在公开数据集VoxCeleb-1和VoxCeleb-2都取得优异的性能,在数据集VoxCeleb-1上,精准度比基准线(系统为NeXtVLAD+AAMS)下降22%,参数量下降25%;在数据集VoxCeleb-2上,精准度比基准线[16]下降25.9%,参数量下降83.1%,该系统在算法上基本达到了如今声纹系统单尺度结构下的最优水平,且模型参数小,更合适部署在嵌入式设备上.

表1 各系统的性能和模型参数对比Table 1 Comparison of performance and size of model parameters between different systems
4.2 多环境下声纹系统识别结果
在本系统上对12个年龄段在18~60岁的人,在5种环境下,进行验证性实验,每种环境每个时长测试3次,进行了共计540次的实验,那么每种情况就是进行了36次实验,表2中百分数表示准确率,即准确的次数除以36.实验结果如表2所示.

表2 多种环境下声纹识别效果Table 2 Performances of speaker recognition under various noisy scenarios %
由表2可看出,在轻微噪声情况下,室内室外的识别效果均达到90.1%以上,尤其是在时长大于6 s的情况下,本声纹识别的准确率都在94.4%以上,可以达到实际应用的需求.室内较大噪声的效果比室外噪声差,这是因为在室内测试语音受混响影响比较大,短时语音(3 s)的准确率82.5%,这是比较极端的情况,实际场景应用中,还是比较少见的.
5 结束语
本文针对现实应用场景下短时语音和混叠有噪声情况下声纹识别准确性低问题,提出了一种改进的深度学习下声纹识别算法并将该模型部署到了嵌入式设备中,为实现声纹技术的落地提供了助力.该系统算法方面,主要改进了编码层和损失函数,结合差分化方式处理特征提取器输出的帧级特征,它对帧级特征中的静态声纹特征和动态声纹特征进行建模,将差分处理后的特征输入到编码层,并在编码层使用NeXtVLAD技术;此外,本文还融合了基于小样本的余弦-原型度量损失函数和AM-Softmax分类损失函数,使得模型在特征空间中同类特征距离尽可能小,异类特征之间的距离尽可能远,即增强了声纹特征的可辨识性,这使得算法性能达到当前最优水平.硬件方面,本文使用性价比超高的Raspberry Pi作为控制核心,进行系统部署,且能够快速实现推理.实验结果表明,在多种开放场景下,这种改进的声纹识别系统能够实时、准确地完成声纹识别任务,可以达到实际应用的要求.
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
雷达学报(2018年5期)2018-12-05
疯狂英语·新读写(2018年3期)2018-11-29
通信产业报(2018年32期)2018-11-24
科技创新与品牌(2018年2期)2018-09-18
