
浅析推荐系统的分类
2021-12-02 08:19梁四香
科学技术创新 2021年32期
梁四香
(空军工程大学航空机务士官学校,河南 信阳 464000)
目前,互联网,电子商务,在线服务等行业极速发展,使传统网络极大扩容。随着大量移动终端的参与,移动在线条件下的“信息过饱和“难题亟待解决。同时随着网络3.0 时代的到来,网民数量和网络购物数量逐年递增,大量不同的信息被产生,“信息爆炸”时代悄然而来。往往用户因无法准确描述想获取的信息,而不得不从信息海洋中“大海捞针”。如何在过载的信息海洋中找到需要的信息已然成为不得不解决的问题[1]。
早期的处理方法是引擎搜索和类目导航,雅虎和网易等公司的类目导航是将产品或项目分类,分目,分层处理,用户按照从大类到小类逐层寻找,最终找到最贴近目标的信息;谷歌等公司的搜索引擎是按照需要用户需求,引导用户找到可能满足需求的项目。但是很多场景下用户并没有清晰的目标,这种情况下,推荐系统便会根据用户属性给用户推荐可能的项目,这样还可能得到更多的惊喜[2]。
1 基于内容的推荐算法
内容型推荐算法是由信息过滤技术发展而来的,它对用户过往喜好分析再对用户进行属性勾画,后比较用户属性勾画与新项目的相似性来判断是否推荐。比如电影《战狼》和《战狼2》都是吴京主演的,与吴京相关的用户很有可能也喜欢吴京的其它作品,针对用户的偏好的项目属性,给潜在用户推荐可能的项目,即系统针对用户的过往偏好推荐相似度最高的产品。依据产品特征计算它们的相似度:根据相关属性推荐物品,依据相关特征,确定符合用户要求的项目特征,并判断物品的适用性[3,4]。
该算法主要被用于可以易于获得特征信息的文档类,或者可手动标签的影视类的推荐。它可以计算用户的特定偏好,能够很大程度处理数据稀疏性问题和item 冷启动问题,然而大多偏好问题,不仅很难提取特征信息,而把多个item 的特征组成一个同一的集合(领域思想)也很难做到使用户可以容易获得目标item。如果收集的profile 不够准确,推荐效果就会很差[5-7]。
2 基于关联规则的推荐算法
关联规则是从物品之间的同现性出发获取它们频繁项,一般是多次查看,反复查找,多次购买,物品捆绑,如图1 所示,在A-priori、FP-Growth 等算法中有支持度和置信度两个概念,常用于推荐跟已购买搭配的商品等场景[8,9],但是它的推荐效果一般比协同过滤算法差,在定义变量间的关联时更需要要注意,若被一些隐含的因素影响时,常出现辛普森悖论[10,11]。支持度support和置信度confidence 如公式(1)和公式(2)所示。


图1 关联规则推荐
辛普森悖论:考虑手机(Phone)和书籍之间的关系。购买手机(Phone)的数量与购买书籍的数量,如表1 所示,买入书籍总人数是153 人,未购入书籍的总人数是147 人,购入Phone 的总人数是180 人,未购买的人数是120 人。
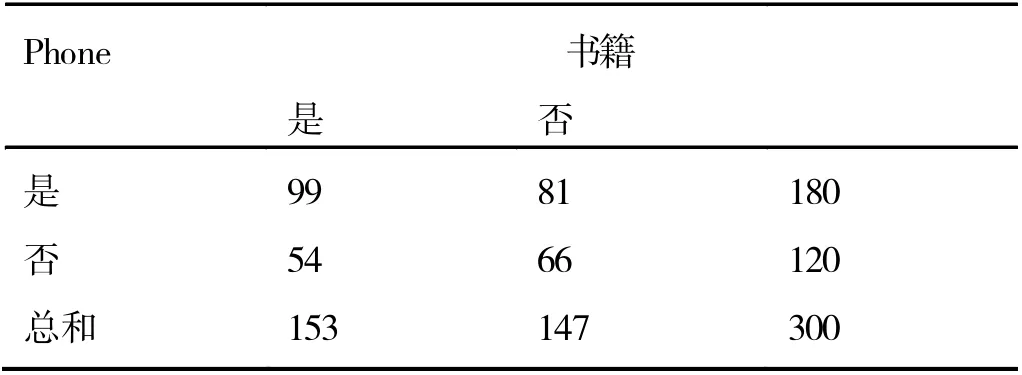
表1 手机与书籍
那么提取频繁集,计算得到如下所示的支持度:

从中可以得出如下结论:购买了Phone 的人比未购买Phone的人更可能买书籍。
如果顾客由大学生和在职人员组成,他们还可以根据其属性分组,如表2 所示。

表2 顾客分组
对于大学生来说,计算得到如下所示的支持度:

对于在职人员来说计算得到如下所示的支持度:


3 协同过滤推荐算法
主要的协同过滤算法有基于用户算法和基于项目的算法两种[15],通常先根据用户购买记录,根据相似度,给用户推荐和其历史偏好产品类似的产品[16],基于用户算法的具体步骤:先计算用户的(前k 个)相似的用户,再依据相似度(如Pearsoncorrelation coefficient[17]、Jaccard Distance[18]和CosineSimilarity[19]等),从而找到用户的偏好产品,并能预测目标用户的评分(预测模型有kNN[20]和Regression[21]等),再过扣除用户已买的产品,最后将产品按照相似性评分排序。这样便可以使用户容易找到需求产品,但是这种操作不仅带来了复杂的在线计算,还需要解决新用户的参与问题[22]。
基于项目的过滤算法,主要是首先先得到item 间的相似度,再针对不同用户的item 评分去预测用户对相关的items 的评分,再将评分较高的相关项目推荐给用户。基于项目的算法具有更高的准确性和表现稳定性,并且易于离线计算,但其推荐多样性较差。Item 的相似性是静态的;但用户的相似性具有复杂的多样性,且是动态的,应用时更应小心。
因此,协同过滤算法的关键是相似性计算,计算相似度的办法有余弦和修正的余弦相似性、杰卡德相似性和皮尔逊相关系数等。

当数据过于稀疏的状态下,余弦和修正的余弦相似性不能度量u1、u2间的相似度,在以往的研究中通常用Pearsoncorrelation coefficient 来计算u1、u2间的相似性,

找出跟目标u 相似度最高的用户并定义为邻居集Nu,设u的项目评分中位数为ru,v 项目评分中位数为rv,rvi是v 对i 的评分,Sim(u,v)为u 和v 的相似度。未被u 评分的i 可用公式(7)来预测:

再将预测结果靠前的项目推荐给用户。
猜你喜欢
现代英语(2021年18期)2021-11-22
幸福·悦读(2019年9期)2019-10-30
思维与智慧·上半月(2019年6期)2019-06-25
新民周刊(2019年6期)2019-02-24
计算机辅助工程(2018年2期)2018-06-03
海峡姐妹(2017年9期)2017-11-06
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
