
基于依存树和注意力机制情感分析模型的改进*
2021-12-01 14:20周从华
计算机与数字工程 2021年11期
王 浩 周从华
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
近几年来,“消费者评论行为分析”是国外国内的研究热点,研究人员通过对消费者行为进行分析,从而推断出消费者的消费行为、消费动机、消费动机、消费偏好、消费态度、整体消费群体影响以及整体消费群体互动。通过对这些维度的分析,可以为企业和商家制定商品的发展战略、提升商品和服务质量、拉升新老用户的商品转换率。消费者评论行为分析逐渐得到了快速成熟的发展,并在多个电商平台取得突破性的成功,同时也深入到我们日常生活中的各个方面,路边店铺的收银台的装扮、商场的物品的摆放、公共广告牌的设计,到处都是消费者评论行为分析的实践应用。通过对这些评论数据进行分析,一方面,商家可以得到自己想要的反馈信息。用户评论信息大都是用户自己对商品进行了解和使用后发表的,具有一定的针对性和可靠性[1]。另一方面,其他对商品感兴趣的用户可以根据该商品的用户评论对该商品进行参考和辅助决策。
目前主流的情感分析模型是将常用的语句引入到LSTM[2]神经网络中,从而来帮助分析模型更好地做出情感预测。TDLSTM[3]是将左右两个长短期记忆网络结合在一起,让语句中的第一个方面词和最后一个方面词作为左右两个长短期记忆网络的最后一个输入,最终将其结合起来代表句子的语义。ATAE-LSTM[4]是将注意力机制和长短期记忆网络模型结合,利用注意力机制可以捕获较长的语句中的信息来进行语义分类和情感分析。DATLSTM[5]是在ATAE-LSTM的基础上,引入了句式的依存关系,通过对句式的不同方面词和各样依存关系进行捕捉,使得方面词和情感属性依存关系更加明确,从而来提升情感分析模型的准确性。
本文针对基于依存关系和注意力机制的双向LSTM分析模型(DAT-LSTM)中,依存关系对方面词和不同语句依存关系理解不全面、句式依存关系捕捉不充分,注意力机制权重计算时隐藏层和向量点乘维度不一致的问题[6],提出一种基于依存图和双线性串联平衡因子的注意力机制双向LSTM分析模型(BSADG-LSTM),并应用到国外电商平台评论数据中。一方面,改进后的依存图是图形结构的句式分析模型[7],允许多个依存根节点存在和依存弧之间相互交叉,使得方面词和句式的依存关系理解更加充分;另一方面,改进后的注意力机制是在原有的权重计算中添加了可学习的参数矩阵,使得隐藏层和向量的维度保持一致。同时再点乘后引入平衡因子,降低了点乘后的维度系数,缓解了归一化后梯度极小的问题,从而一定程度上提升了模型训练效率和灵活性。
2 基于依存关系和注意力机制的双向LSTM分析模型概述
目前主流的特定方面词情感分析模型,主要解决的问题是根据给定的方面词找到与之对应的重要上下文信息。依存关系是用来展示一个句子或多个句子中词与词之间的不对等支配关系的一种方法,用来描述词与词之间依存关系的语言框架,利用框架的依存关系分析,可以让句子中的词与词建立从属关系,从而能够充分捕捉与方面词有关系但语句距离较远的信息。自然语言中,Bahdanau等[8]首次提出注意力机制来解决机器翻译问题。注意力机制可以根据不同方面词自动生成特定的上下文信息向量,可以为每个信息向量分配不同的权重,从而使得模型在分析时具有更好的翻译表现。因此,基于依存关系和注意力机制的双向LSTM模型(DAT-LSTM),能够用来分析特定词的真实情感倾向[9]。模型结构如图1所示。
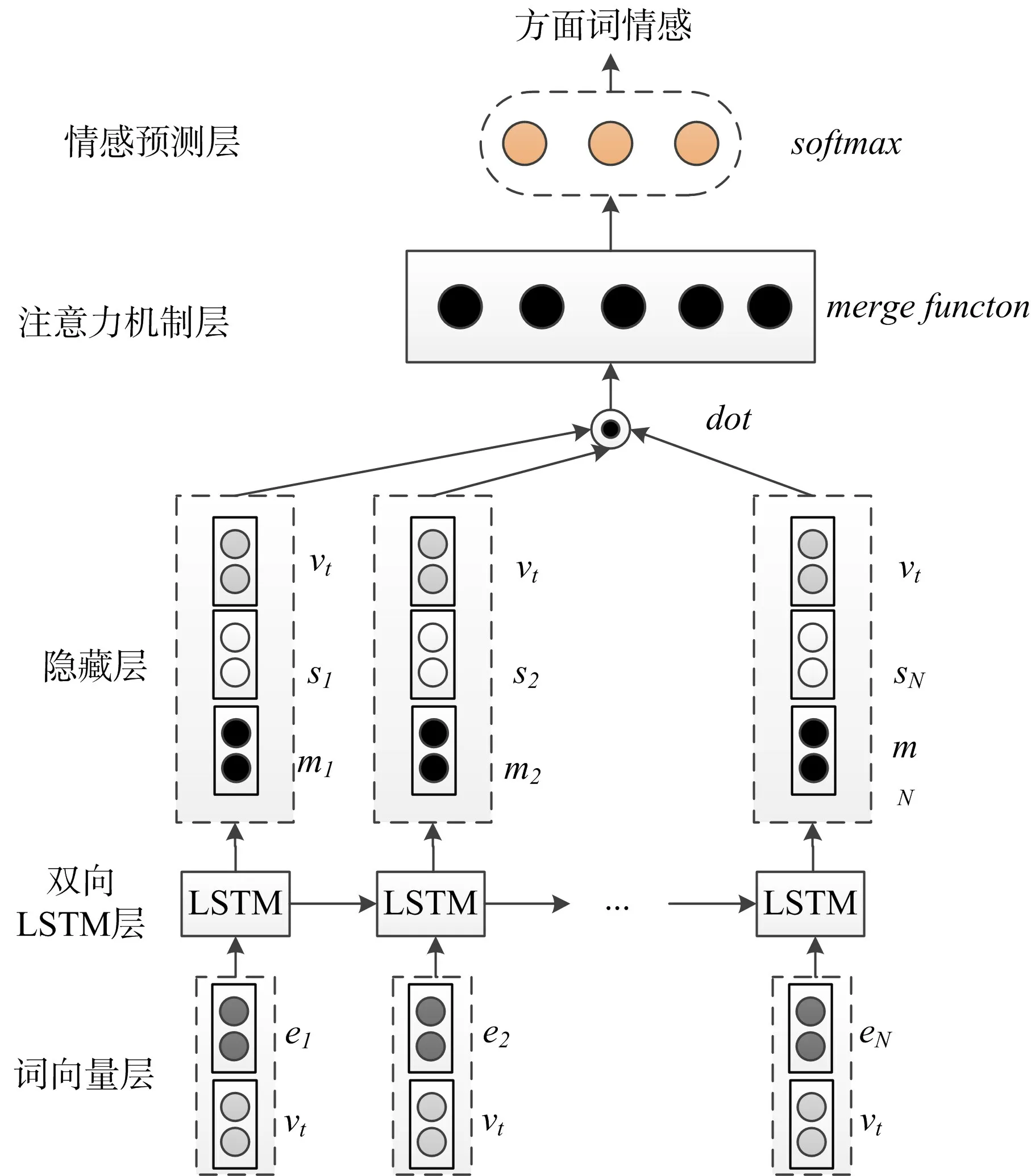
图1 基于依存关系和注意力机制的双向LSTM分析模型结构图方面词情感
给 定 一 个 句 子a={q1,q2,…,qn}和 方 面 词qt。先依靠CoreNLP[10]模型方法分析得到句子的依存关系,从而得到与方面词qi存在直接依存关系的词qdi。利用映射方法,将每个方面词转换为词向量vt。词向量vt根据方面词的个数分为两种:如果方面词为单个单词,即这个方面词的词向量为vt;若方面词由多个单词组成,那么这个方面词的词向量vt由这多个单词的词向量求均值表示。然后输入到双向长短期神经网络层中进行句子前后关系结合,结合后再输出到隐藏层中去。
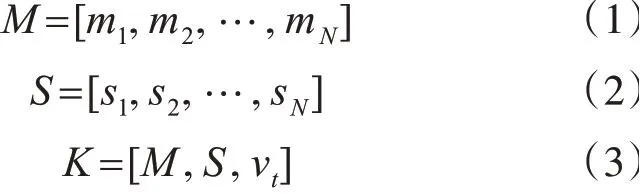
隐藏层由矩阵MϵRdM×N来表示隐藏层状态向量,矩阵S∈RdS×N来表示依存关系信息,矩阵K∈RdM+dS+dvt来存放隐藏层状态、依存关系信息和方面词向量。
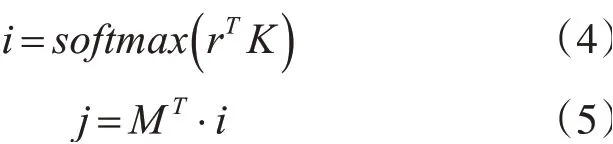
这样再经过注意力机制层,会分别得到一个权重向量iϵRN和权重因子jϵRN。
因此,最终的模型句子表达式为
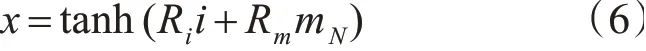
其中,rT,Ri和Rm为模型参数。
最后再输入给情感预测层,将特定方面上的情感转换为概率分布。
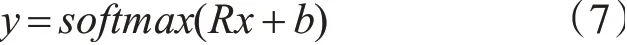
其中,R和b为模型参数。
模型采用了交叉熵(cross entropy)作为模型的损失函数,同时还添加了一个L2范数正则化来防止模型在训练过程中出现过拟合的情况:
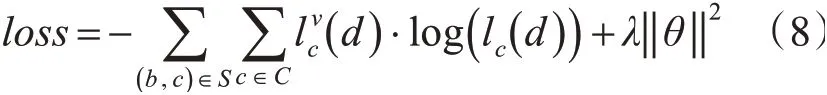
其中,(b,c)代表属性对,C代表情感倾向类别数,一般情况下分为二分类(积极倾向和消极倾向)和三分类(积极倾向、中立倾向和消极倾向)[11],其中二分类的C=2,三分类的C=3。代表样本d的实现分布情况,lc()d代表模型在样本d在情感倾向上的预测概率,λ代表L2范数正则化的权重系数,θ代表模型中所有训练参数的集合。
3 对依存树和注意力机制的双向LSTM分析模型的改进
3.1 依存树的改进
现有的依存关系分析通常采用依存句法结构分析和依存树分析,通过句法结构分析出某一个方面词的许多种不同表述信息。依存树是在依存句法结构的基础上采用树形结构进行依存关系分析,建立起句子中方面词和方面词之间的从属关系[12]。以句子“我爱中国的文化”为例,依存树结构如图2所示。
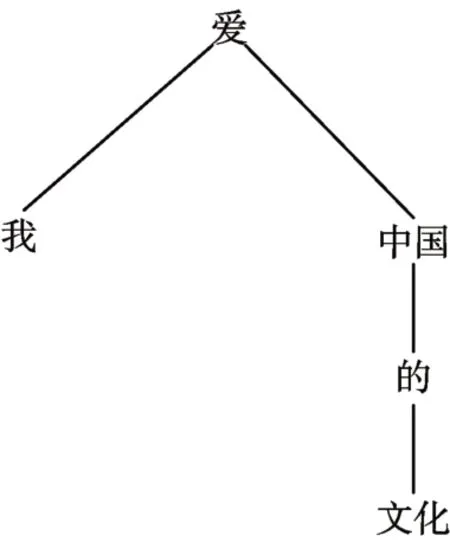
图2 依存树结构图
对句子进行语法结构和依存关系的构建,形成新的依存树结构。通过特定方面词对句子中属性计算两个词之间的最短路径,从而得到特定方面词的真实从属词。但由于每棵依存树只允许一个依存根节点,所以树结构的表达式是不充分的,有的时候不能很好地保留一些反向语法依存信息[13]。所以在原来的模型基础上,本文将原有的依存关系替换为依存图,提出基于依存图和注意力机制的双向长短期分析模型。同样以句子“我爱中国的文化”为例,依存图结构如图3所示。

图3 依存图结构图
依存图采用图结构,一方面可以将任何一个图节点转换为依存该图节点的两个或两个以上的图节点[14],这样在依存结构中就允许多个依存根节点;另一方面可以允许依存弧之间相互交叉,这样可以使句法的依存关系边的定义更加深刻和完善。
3.2 注意力机制的改进
传统的注意力机制虽然可以一定程度上捕捉长短句的方面词和从属词性的依存关系,但在于注意力的权重计算上没有过多的简化,原方面词属性通过注意力机制得到的权重因子jϵRN公式如下:其中,矩阵MϵRdM×N为隐藏层状态向量,iϵRN为权重向量。

原权重因子是通过计算向量相识度进行点乘,向量点乘归一化之后表示向量之间的余弦相识度。虽然点乘的方法可以是模型不需要引入其他额外的参数,计算简单,但是需要要求隐藏层表示M和权重向量i的维度保持一致且再同一空间中[15]。因此在此基础上,本文引入双线性串联矩阵参数E,来解决点乘维度不一致的缺点。引入双线性串联矩阵参数E公式如下:

双线性串联矩阵参数E是一个可学习的参数矩阵,是对隐藏层和权重向量分别进行空间转换处理。矩阵参数EM先对隐藏层进行空间转换,同时再由矩阵参数Ei对权重向量做空间转换,共同转换后的两个层的维度保持一致,累积求和得出权重因子。但在点乘的过程中,如果相乘的维度过大,则注意力分数也会随之增大,通过softmax对其归一化时,其所对应的梯度将会极小,使得模型很难训练[16]。因此,在改进的式(10)中引入平衡因子来缓解梯度极小的问题。引入平衡因子公式如下:
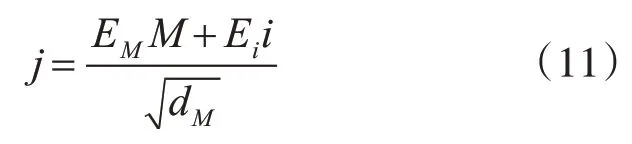
对原公式同时引入双线性串联矩阵参数E和平衡因子即解决了点乘时维度不一致的问题,又在一定程度缓解了点乘后维度过大,梯度极小,模型难训练的问题,使得模型的灵活性和训练效率大大提升。
4 实验分析
4.1 实验信息
本次实验通过Scrapy爬虫框架,爬虫分采集了海外电商平台amazon上的手机壳数据和slickdeals上的电脑显示屏数据。情感预测类别分别分为二类(积极倾向和消极倾向)和三类(积极倾向、中立倾向和消极倾向)。实验采用精度(Accuracy)和相应的宏F1(macro-F1)作为分类算法的性能度量方式[17],分类结果的“混淆矩阵”如

表1 预测类别与实际类别的“混淆矩阵”
根据上表分类结果评价指标由式(12)~(15)计算得出:

4.2 实验结果及分析
本实验将提出的BSBDG-LSTM模型和多个基线情感分析模型进行性能对比,包括长短期记忆情感分析模型LSTM、结合注意力机制和长短期记忆情感分析模型ATAE-LSTM、结合依存关系和注意力机制的双向长短期记忆情感分析模型DAT-LSTM和结合依存树和注意力机制的双向长短期记忆情感分析模型DASN。二分类实验结果如表2所示,三分类实验结果如表3所示。
由表2、表3可知,在LSTM神经网络中引入注意力机制层会使得模型分析的准确率得到大的提升。然后在注意力机制层基础上再引入依存分析层,使得模型的捕捉能力大大改善。将二分类和三分类的实验数据汇总成柱状图,使得每个模型的分析结果更加清晰,实验结果柱状图如图4~5所示。
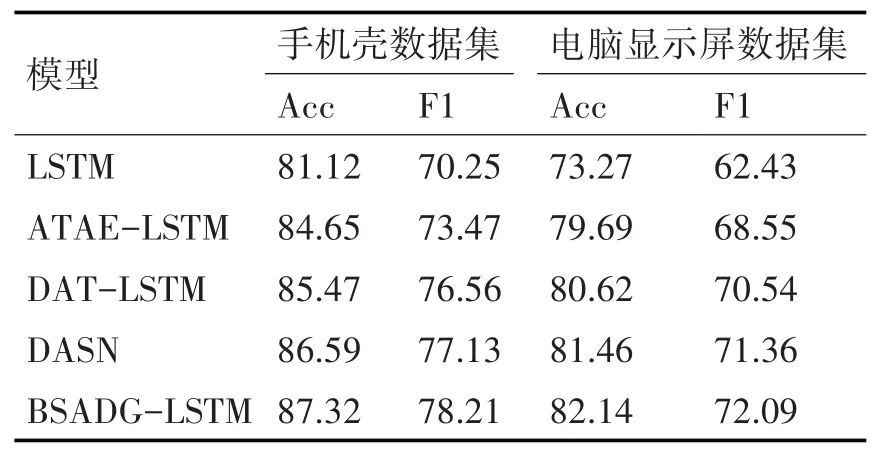
表2 二分类实验结果
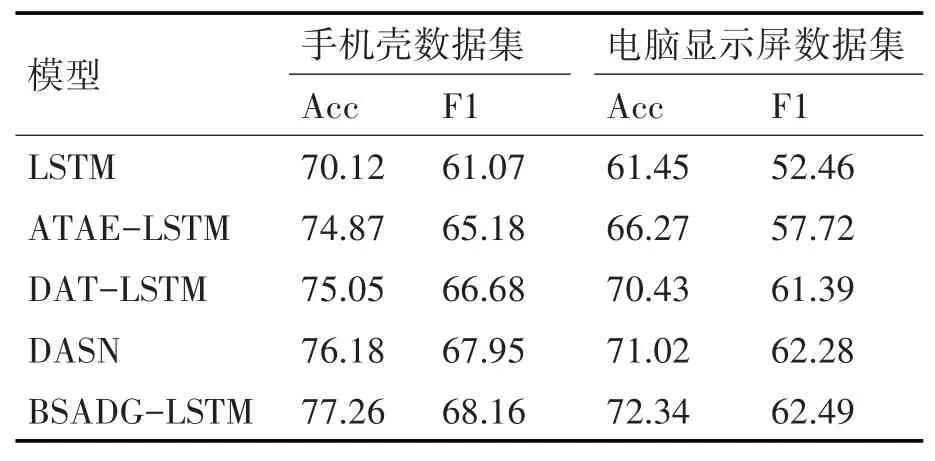
表3 三分类实验结果
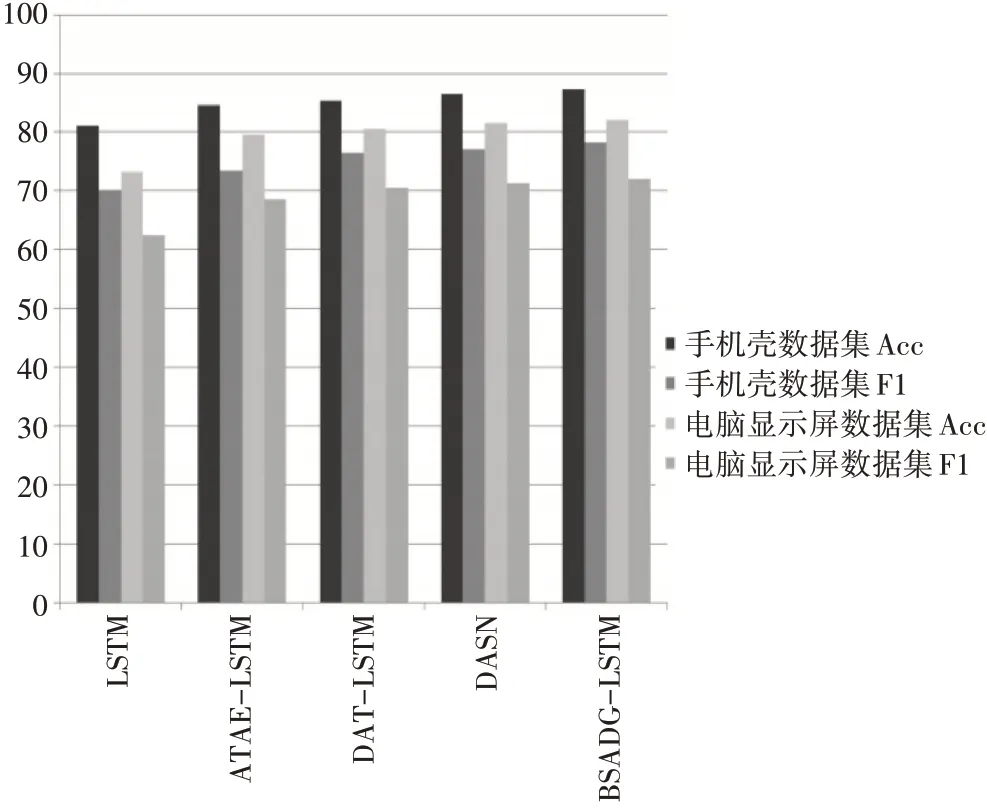
图4 二分类情感实验分析结果
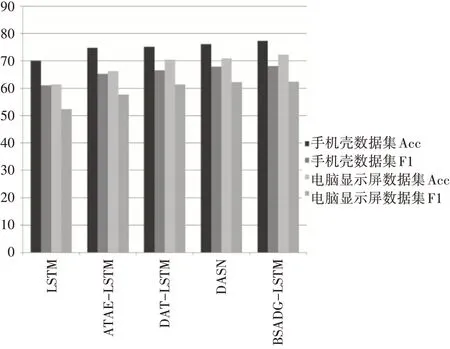
图5 三分类情感实验分析结果
通过不同的依存关系和注意力机制的引入,可以使分析模型在不同程度上有一定的提升。本文所提出的BSBDG-LSTM情感分析在二分类和三分类中在情感分析中均取得不错的效果,通过对依存树的改进,将树形结构转换为图形结构,引入依存图模型;通过对权重因子的改进,引入双线性串联矩阵参数和平衡因子,大大提高了分析模型在情感分类的准确性。
5 结语
本文针对DASN分析模型的中依存树句法依存分析强度弱和注意力机制权重因子点乘维度不一致的问题,提出一种结合依存图和双线性串联平衡因子注意力机制的双向长短期网络分析模型BSADG-LSTM。实验结果表明,BSADG-LSTM能够更深刻地理解和分析句子和捕捉方面词的依存信息;面对维度较大的数据能够高效训练。本文后续工作集中于面对不完整句式如何更好地捕捉方面词和依存信息以及如何更好地提升三分类情感分析的准确率上。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年7期)2021-08-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年22期)2020-04-13
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
燕山大学学报(2015年4期)2015-12-25
新高考·高二数学(2015年11期)2015-12-23
