
基于深度学习的手语识别算法研究
2021-11-30 09:35戴兴雨王卫民梅家俊
现代计算机 2021年29期
戴兴雨,王卫民,梅家俊
(江苏科技大学计算机学院,镇江212003)
0 引言
据北京听力协会2017年预估数据,我国听力障碍人士已达7200万,其中有2700万听障者需通过手语等方式进行沟通交流。手语是听力障碍人士与其他人交流最为重要的方式,但是会手语的人很少,即便使用手语,也因为看不懂手语而无法正常交流。这对听力障碍人士与他人交流造成了极大的障碍。2018年7月1日国家出台了通用手语标准[1],这让听力障碍人士使用手语与他人交流变得有章可循。因此手语识别研究有着广泛的应用价值,对手语识别算法的研究有助于提升我国聋健融合的程度和加速国家通用标准手语的推广进程。
本文采用Seq2Seq模型[2][3],实现视频帧序列到字序列的转换。对于手语视频,采用Incep⁃tionV3对视频中的每帧图片进行特征提取,输入到Seq2Seq模型的Encoder部分得到视频的融合特征。一个词的手势包含起始动作、关键动作、过渡动作、结束动作,在编码器进行特征融合过程中每个动作的权重是一样的,针对这个问题,本文采用K-means方法提取以及利用人工标注的方式从语言学角度和听障人群使用的角度标注视频帧的关键帧,将关键帧的融合特征与手语视频所有帧的融合特征组合起来输入到Seq2Seq模型的Decoder部分进行解码,使得关键帧占据更大的权重,提高手语识别的准确率。
1 相关工作
从20世纪60年代以来,研究者就对手语识别技术展开研究[4]。目前手语识别方法研究大致分为3个方向:①基于体感设备的手语识别。②基于穿戴式设备的手语识别。③基于深度学习的手语识别。
1.1 基于体感设备的手语识别
随着计算机视觉的发展,一些研究人员利用体感设备对手语的手势动作进行捕捉,并精准分析进而识别手语。2019年,千承辉、邵晶雅、夏涛、刘怀宾等人[5]利用Kinect设备获取人体深度图像和骨骼特征信息以及利用有限状态机及动态时间规整(DTW)实现手语识别。2017年,沈娟、王硕、郭丹等人[6]利用Kinect并计算出手语者的骨架特征表达,并构建高斯混合的隐马尔科夫模型(GMM-HMM)进行手语识别。这种利用体感设备进行手语识别,需要利用辅助设备进行捕捉手语动作,这些设备价格不低,而且携带不方便,不利于推广与发展。在捕捉手语动作时易受光线等环境因素的影响,对识别精度照成较大影响。
1.2 基于穿戴式设备的手语识别
基于穿戴式设备的手语识别,都是利用硬件设备通过传感器技术获取手语的手势动作信息输入到系统,系统根据输入的信息识别手语含义。2015年,吕蕾、张金玲、朱英杰、刘弘等人[7]利用一种可穿戴式的设备——数据手套获取手语的手势特征再与构建好的数据库进行点集模版匹配进行手势识别,实现在25类手势中准确率达98.9%。2020年,白旭、郭豆豆、杨学康、蒋丽珍等人[8]利用智能手语翻译手套进行手语识别,该智能手语翻译手套采用基于数据手套的手语识别技术,运用低纬度SVM结合决策树算法来进行手势识别,在SVM的两类分类器的基础上加上决策树算法能够实现多类分类器功能,在不影响识别率的情况下极大地提高识别速率。与利用体感设备一样,需要借助辅助设备,利用穿戴式设备进行手语识别还处于研究阶段,这种设备无法大规模生产,一套设备非常昂贵,无法在市场普及,而且设备携带不方便,难以推广。
1.3 基于深度学习的手语识别
随着计算机硬件和软件的不断更新换代,基于深度学习的手语识别得到了极大的发展。在2017年,Cui等人[9]采用基于连接时间分类(con⁃nectionist temporal classification,CTC)的CNNLSTM网络模型进行连续手语的识别。此方法利用CTC对未分段的时间序列片段进行标记,再进入CNN-LSTM模型进行分类识别,在一个大规模数据集上,得到了较好的性能。2020年,罗元、李丹、张毅[10]提出基于基于残差3D卷积网络(Res3DCNN)和卷积长短时记忆网络,关注手语手势中显著区域并在时间上自动选择关键帧,在手语识别上取得了较好的效果。
2 方法
2.1 特征提取方法
为利用深度卷积神经网络提取单帧图片的有效特 征,我 们 采 用 了GoogleNet[11]系 列 的Incep⁃tionV3网 络 模 型。InceptionV3是 由InceptionV1、InceptionV2演变而来。
Inception系列网络采用模块化结构,设计的核心主要在Inception模块,网络设计中采用了全局值池化代替全连接层,极大降低了参数的数量。在使用时,我们去除了网络的最后一层。具体InceptionV3的网络结构如表1所示。
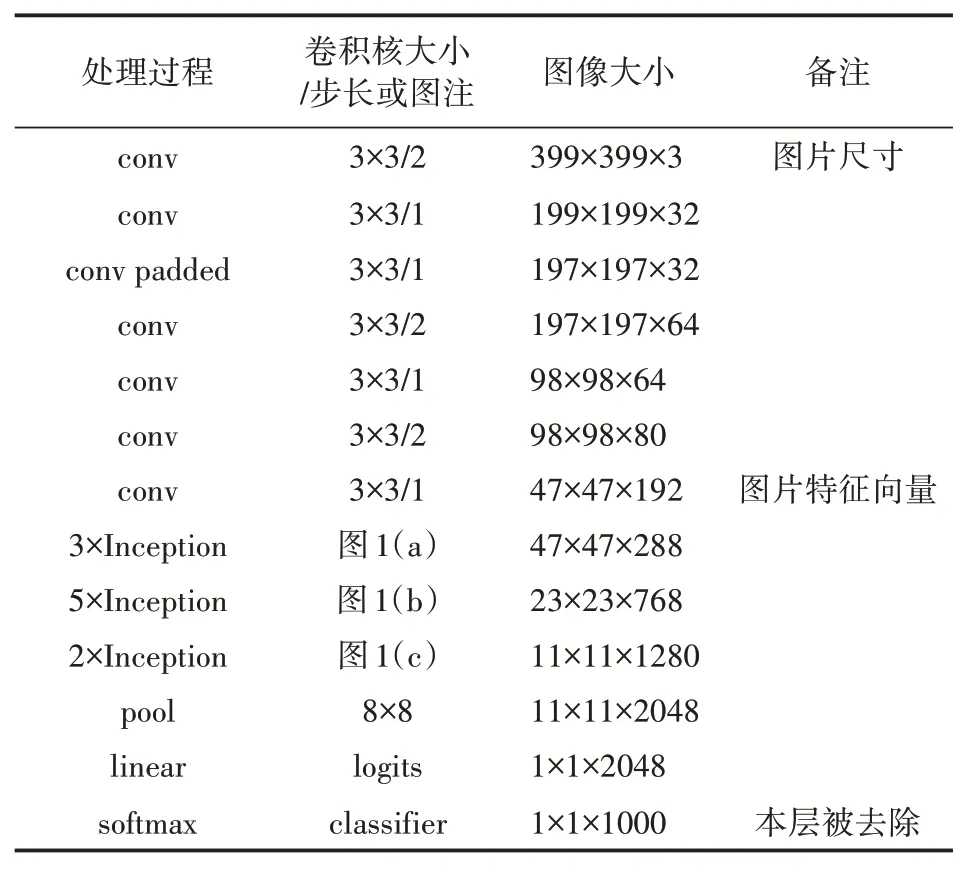
表1 Inception V3模型结构

图1 Inception模块结构
给定的手语视频V,进行按帧切分,分成Im⁃ages=[Image1,Image2,…,Imagen],其中n是切分的总帧数,Imagej代表第j帧图片。用InceptionV3对切分好的所有图片进行特征提取得到f=[feature1,feature2,…,featuren],其中n表示总特征数,fea⁃turej表示第j帧图片提取出的特征,得到的f即为该手语视频的特征。其具体流程如图2所示。

图2 手语视频特征提取过程
2.2 手语视频预处理
对单个手语视频V,首先进行按帧切分,对于每帧图片按照上述特征提取的方法进行特征提取,最终得到手语视频的特征。具体过程如下:


2.3 运用K-means聚类算法均值提取关键帧
K-means聚类算法广泛应用在视频或图片处理,也是图片关键帧提取的主要方法之一。其算法思想是将给定的样本大小,按照样本之间的距离大小,将样本集划分为k个簇,使得同一个簇内的样本更紧密连在一起,簇之间距离尽量大一点。假如簇划分为(C1,C2,…,Ck),那么我们最终的目标最小化平方差误差E:
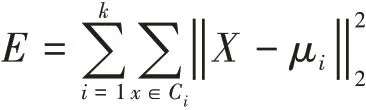
其中μi是簇Ci的均值向量,也称为质心,其表达式为:
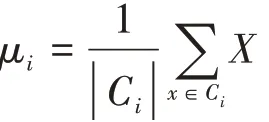
传统的K-means提取视频关键帧的方法是计算视频的每帧图片在像素空间的欧式距离来衡量图片之前的差异,从而完成图像聚类[12],而本文对手语视频关键帧的提取在手语视频每帧图片的特征空间中进行聚类,这样解决了单像素无法携带足够信息和图片尺寸大,造成计算量过大的问题。通过对大量手语、手势的研究发现,绝大多数手语的关键帧数不会超过6帧[12],数据集(在4.1节介绍)中的手语视频大多包含4~6个词,所以将关键帧数设定为32,对于一个手语视频V,其特征序列f={feature1,feature2,…,featuren},其中n为视频序列总帧数,featurei为视频第i帧图片提取的特征向量,对于f采用K-means进行提取关键帧。具体算法如下:
(1)从特征序列f中随机选择32个样本作为初始的质心向量记为μ1,μ2,…,μ32,其中μj(1≤j≤32)为第j类聚类质心。
(2)对于样本f={feature1,feature2,…,fea⁃turen}和各个聚类质心μj的欧氏距离:
dij=‖featurei-μi‖,那么featurei到μj(j=1.2…32)的距离记为Di={di1,di2,…,di32},选 取Di中的最小值dij,将featurei归入第j类。
(3)再对第j聚类质心的所有样本去均值,重新计算该类的质心。
(4)重复步骤(2)和(3),直到每次重新计算的质心与原质心没有变化。
最终的μ1,μ2,…,μ32即为提取出的手语视频关键帧特征。
2.4 手语识别模型
使用Keras搭建Seq2Seq模型,Seq2Seq模型是RNN最重要的一个变种:NvsM(输入与输出序列长度不同),这种结构又叫Encoder-Decoder模型。Encoder与Decoder均采用长短时记忆卷积神经网络(long short-term memory networks,LSTM)。将手语视频关键帧特征序列与手语视频特征序列分别输入到Encoder部分进行特征融合,将两部分得到的融合特征组合起来输入到Decoder部分进行解码,M1,M2,M3为LSTM层。具体手语识别算法模型如图3所示。
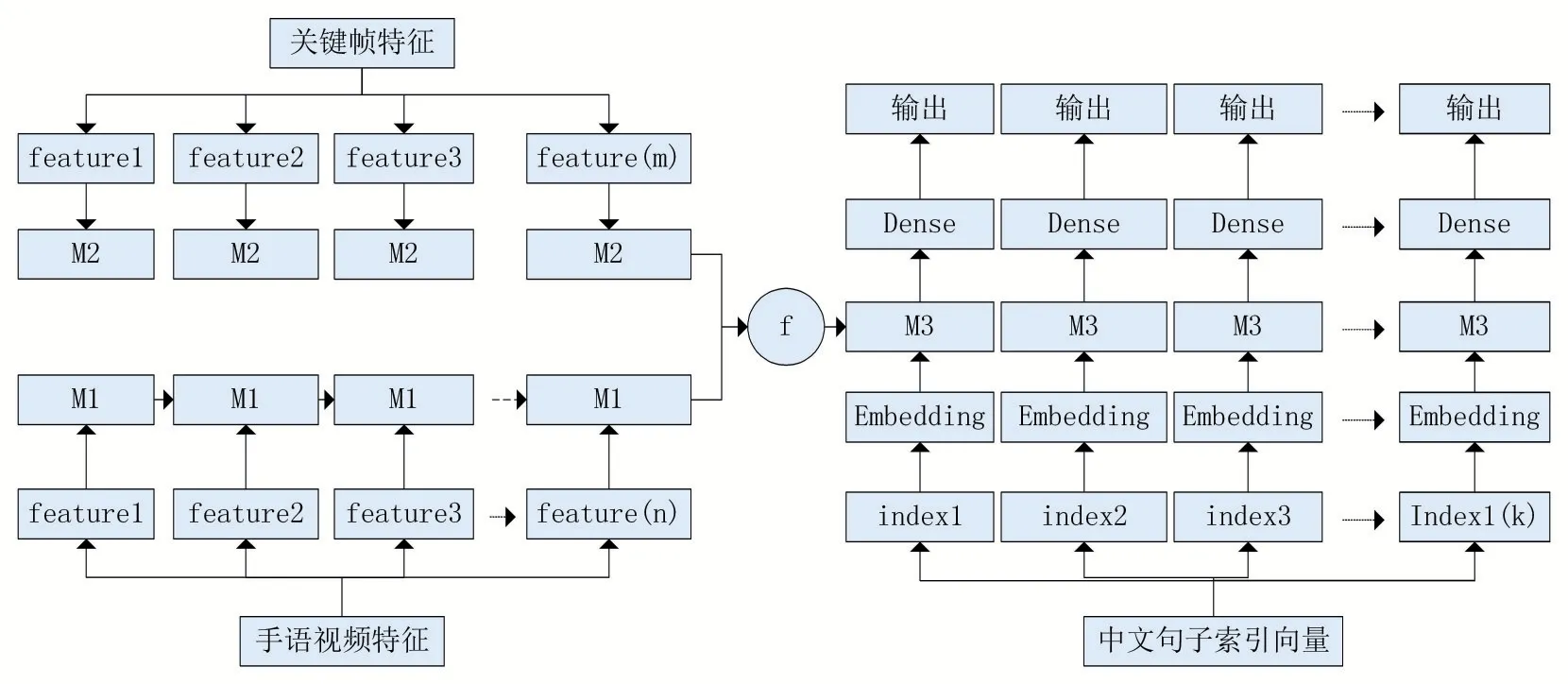
图3 Seq2Seq手语识别算法模型
3 实验
3.1 数据集
对于手语数据集,我们采用了中国科学技术大学自制的中国手语数据集——CSL。CSL数据集是中国科学技术大学从2015年开始自制的中国手语数据集,并在2017年公开,里面包含RGB、深度以及骨架关节点数据。我们选取其中100句中文句子,每句中文对应250个手语视频,总计25000个样本的连续手语数据集,如图4所示。

图4 手语数据集
100句中文句子,每句对应250个视频,由50名操作者拍摄,每位操作者重复5次,手语动作由专业老师指导,每个视频在5~8秒。视频内容具体情况如图5所示。

图5 手语视频
3.2 加入关键帧前后精度对比
模型训练好后(迭代训练800轮),与视频融合特征部分不加入关键帧的融合特征直接进行解码相比,加入关键帧后在精度上有了一定的提升,在测试集上测试1000次的情况见表3。

表3 测试1000次识别精度
可以看出,在加入了K-means聚类算法提取的关键帧后,识别精度有了一定的提高。
3.3 迭代次数对比
本文还对比了训练的迭代次数,实验结果如图,随着迭代次数的提高,加入关键帧的模型与不加关键帧的模型在精度上都有很大提高,加入手语视频关键帧的模型总体要高于不加入手语视频关键帧的模型。如图6所示。

图6 精确度对比
4 实验优化
由实验结果看出,使用K-means提取关键帧加入到编码器的融合特征中,精度上虽有一定的提升,但还是未达到预期效果。而且手语识别时间增大,原因是K-means提取关键帧存在问题:①K-means涉及大量数据的运算,收敛较慢,数据量过大时,计算时间过长。②经过专家打分系统发现最终得到的聚类质心,有一部分质心不是关键帧。③同一个关键手势可能会出现在多个地方,但是会被归为同一个聚类,丢失了关键帧的时间序列。
为此,我们更换了关键帧的提取方式,我们使用人工进行标注每个手语视频中每帧关键帧,并用三层深度神经网络进行二分类训练。
4.1 人工标注关键帧
对于手语视频的关键帧,我们从两方面进行考虑:语言学角度的关键帧和听障人群使用的角度的关键帧。
4.1.1 语言学角度的关键帧
一句中文句子可以分解成多个词和字,对于这句话的语义一般由几个关键词构成,我们基于这个角度采用词频-逆文件频率(term frequencyinverse document frency,TF-IDF)提取每句中文句子中的关键词。
TF(词频)指某个词语在当前文档中出现的次数,由于同一词语在不同文档中出现的次数不一样,且文档越大,出现的频率可能就越高,故需要对词语进行归一化,计算公式如下:

IDF(逆文档频率)是在词频的基础上,对每个词赋予权重。如果某个词在其他文档中出现次数很多,但是在当前文档出现多次,那么应该赋予该词较大的权重,如果该词在很多文档都有出现,无法代表当前文章的内容,那么将赋予该词较小的权重,其计算公式如下:
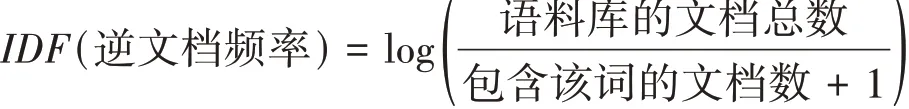
那么每个词最终的权重(TF-IDF值)即为:
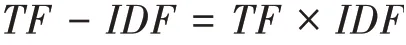
我们将数据集中包含的每个中文句子作为一个文档,总计100个文档作为数据集,对每句话使用jieba工具进行分词,然后对每个词对与对应文档进行TF-IDF值的计算,提取出每句话中的关键词。
对于每句话提取出的关键词,例如“他的同学是警察”,最终提取出“同学”和“警察”两个关键词,我们在手语网查询了这两个词的手势动作得知“他”包含一个关键手势(图7),“同学”包含两个关键手势(图8),然后对手语视频中的每帧图片按这些关键手势进行标注为关键帧。

图7 手语“他”的关键手势
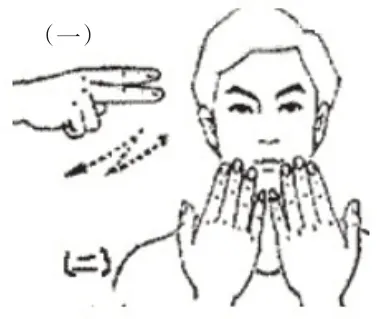
图8 手语“同学” 的关键手势
我们邀请了学校的几位老师以及学生共10个人,将我们收集到手语数据集中的每一个视频进行按帧切分,按照中文句子中的关键词,查询其对应的关键手势,对切分的每张图片进行标注是否为关键帧。耗时半个月,将收集到的25000手语视频全部标注完成。
4.1.2 听障人群使用的角度的关键帧
手语是一种视觉语言,表达时重于视觉效果。通过对镇江市聋哑学校的学生进行手语交流的观察发现,当他们进行交流时,对于某个手势会着重表达甚至反复做这个动作,主要原因是这些手势动作存在一些关键动作(关键帧),它的正确展示是对方理解自己手语表达含义的关键。基于这一理论,我们邀请了5名手语专家(听障人士)帮助我们对于现有的手语数据集中手语视频动画按帧标准标出了核心关键关键帧。
4.2 优化结果
模型训练好后(迭代训练800轮),对三种提取关键帧的方式分别进行比较,分别在测试集上测试1000次的情况见表4。

表4 测试1000次识别精度
迭代次数的对比如图9所示。
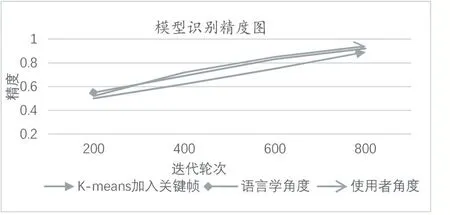
图9 精确度对比
由此可以看出,在本实验中三种方式在初始200轮迭代中差距不是很大,但是从整体上看,最终的精确度人工标注的方式比K-means方式提取的关键帧在效果上更好,而且在训练过程中整体都是由于K-means的。将语言学角度的关键帧和使用者角度的关键帧对比,从使用者角度效果更好,可以看出使用者角度提取的关键帧更符合听障人士在交流时的关键手势。
5 结语
本文提出基于深度学习的手语识别算法,搭建了Seq2Seq网络模型。对于训练成熟的Seq2Seq模型,将录制的手语视频,输入模型可直接得到手语的中文意思,而且识别准确率高,相较于传统使用数据手套或者使用Kinect作为辅助器,成本低。运用算法开发出一款应用,可以在各种设备进行识别操作,方便快捷。
深度学习技术相对传统方法而言,与网络速度、GPU等硬件性能的关系更为紧密,计算机硬件设备的更新换代及网络升级,会大大缩短从录制完手语视频到得出结果的时间。深度学习技术还依赖于大量数据集,现阶段,良好的手语数据库非常匮乏,未来还需要致力于建立良好的手语手语数据集,提高手语识别模型的准确率与普适性。
猜你喜欢
现代计算机(2022年4期)2022-04-24
红领巾·萌芽(2019年9期)2019-10-09
作文周刊(高考版)(2019年9期)2019-04-29
软件导刊(2018年4期)2018-05-15
小学阅读指南·低年级版(2017年6期)2017-06-12
电脑知识与技术(2017年3期)2017-03-27
现代电子技术(2016年24期)2017-01-19
青少年科技博览(中学版)(2015年8期)2015-10-28
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
