
基于卷积神经网络模型的诈骗网站识别技术研究
2021-11-30 09:31徐啸炀周胜利盛蒙蒙袁莹
现代计算机 2021年29期
徐啸炀,周胜利,盛蒙蒙,袁莹
(浙江警察学院,杭州310053)
0 引言
当今时代,我国互联网日益开放,网络空间安全越来越引起重视。电信网络诈骗犯罪正逐步取代传统的诈骗行为,成为当今时代诈骗犯罪的主要犯罪形式,严重威胁人民生命财产安全。打击电信网络诈骗犯罪,维护互联网安全的任务迫在眉睫、刻不容缓。
其中,电信网络诈骗犯罪的主要平台是各式诈骗网站,对诈骗网站进行特征识别是有效预防此类犯罪的必要途径。针对目前诈骗网站高隐蔽性和高混淆性的特点,本文提出的模型模型能够有效综合两个模型的优点,能够在保持理想的开销的情况下具备较高的识别检测精确度,有效完成诈骗网站识别任务。
1 目前的相关研究
针对诈骗网站的识别研究,国内外都有较为丰富的成果,主要集中在:①诈骗网站识别;②网络流量分析;③用户异常行为检测。
1.1 诈骗网站识别相关研究
随着大数据、人工智能技术的快速发展,国内外学者结合深度学习等技术对诈骗网站特征识别进行了广泛深入的研究,主要在三个方面:①视觉相似度分析法;②网站信息综合评估法;③诈骗网站url特征异常检测技术。
1.1.1 基于视觉相似度的检测方法
视觉相似度分析法作为主流的诈骗网站识别方式,主要涵盖网站指纹、文本、图像等内容。Ankit等[1]提取网站title、HTML标签、层叠样式表等网站文本特征,进行特征向量化,提出利用网站文本相似性进行诈骗网站识别。Johnson[2]、Wu等人[3]将卷积神经网络模型应用在文本分类识别领域,通过提取网站文本特征,训练模型,完成分类。刘永明等[4]提出了一种利用图像哈希感知算法进行恶意诈骗网站检测的方法。胡向东等[5]提出以PCA-SIFT算法提取图像特征计算待测网站与正常网站间的logo相似度的方法。此外,Sun等[6]提出使用遗传算法自动设计CNN架构进行图像分类的方法。此类从图像特征入手、以相似度或者深度学习算法进行分类检测的方法,能够避免文本特征检测方法。
基于视觉相似度的诈骗网站检测方法已经在大量实验中验证有效性,对已经分类的混合网站识别精准率普遍达到90%以上,但存在召回率偏低的现象。这与诈骗网站的隐匿性相关。在实际的诈骗网站分析中,为了对抗指纹攻击,一些网站通过更改logo,功能伪装,对框架二次开发,阻碍了通过指纹攻击的检测方式;通过隐藏网站入口,设置注册验证,减少有效信息爬取,使诈骗性质的特征权重降低来破坏识别率。通过内网小样本的实验证明,这些方法对于传统的诈骗网站检测技术具有极高的防范作用。
1.1.2 基于网站信息综合评估的检测方法
为了解决传统上基于视觉相似度检测方法在召回率上偏低,且容易被特征隐匿的问题。国内外学者提出了根据互联网信息综合评估方法识别诈骗网站。该类方式将注意力集中到互联网公开信息中对网站域名、用户关注度与访问量、服务器信息的综合评测上。Sun等人[6]就提出了一种基于组成成分分析的方法,通过随机森林决策树算法将特定网站的各类公开测评数据进行建模分析,取得良好成效。
然而此类方式存在分析维度低,特征冗余的问题,对于真实场景的应用有待考量。
1.1.3 诈骗网站url特征异常检测技术
url特征异常检测技术主要通过对url结构、词汇进行建模,通过url中的特殊字符、结构,以及该url在各大平台上的统计被引用记录、访问记录等等信息进行评判,将特征维度建立在以上几个方面,加以建模分析,从而实现诈骗网站的url特征检测。
1.2 网络流量分析
流量识别技术早已应用在各大网络安全领域,在防范网络攻击、识别匿名通信都有大量研究成果。
在异常流量检测方面,很多研究从不同的特征维度进行了探索。Zolotukhin等[7]以流量日志分析为基础,提出了一种攻击Web应用的异常检测方法。Yu[8]、Yang等[9]都采用自然语言的方法,建立相关词库,进行分词预处理,最终以神经网络模型进行异常检测。Park等[10]提出了基于二值图变换的卷积自动编码器,并以此对流量数据包进行异常检测的方法。该方法采用字符级切割的预处理方法,效果优于传统的特征输入的启发式机器学习方法。
在提取流量的有效数据方面,Arzhakov等[11]提出使用蜜罐技术来收集用户行为的统计信息,并基于统计结果来区分不同种类的流量。Thang等[12]建立了一种基于密度的噪声应用空间聚类模型来提取流量的有效数据。
在混合模型方面,Zhang等[13]提出采用隐马尔可夫模型、概率分布模型、支持向量机三种机器学习模型来对HTTP请求进行异常检测的方法。
1.3 用户异常行为检测
连一峰等[14]采用关联分析与序列挖掘技术,通过比较用户当前行为模式与历史行为模式的相似度,来判断异常。该方法能够实现用户异常行为检测的功能,但缺少应对大规模数据的能力,也缺少足够的可靠性与精确度,是一种比较初步的算法。
田新广等[15]针对前人用户异常检测模型的不足,改进了用户行为模式的表示方式,联合采用多个判决门对用户行为进行判断,提出了IDS异常检测模型。该模型具备更高的检测效能,但同时该模型具体的应用范围和检测边界尚模糊。
崔永艳等[16]对于传统的基于整条轨迹建模分析的异常行为检测方法中难以检测局部异常的问题,提出一种在多示例学习框架下基于轨迹分段进行异常行为检测的方法。该方法对分段后的轨迹建立层次狄利克雷过程-隐马尔可夫模型,在多示例学习框架下,进行学习分类。该方法具有更高的准确率与召回率。
陆悠等[17]为了解决快速检测用户异常行为与减少算法开销的问题,提出一种基于选择性协同学习的网络用户异常行为的检测方法。该方法使用EasyEnsemble方法对样本进行平衡化,再使用基于混合扰动的生成方法构造分类器,进行学习分类。实验表明该方法能够再减少开销的同时,保持良好的检测精确度。但该模型的缺点在于缺乏动态更新能力。
陈胜等[18]为了解决传统异常行为检测方法难以应对海量数据需求,以及对于新的行为无法及时响应的问题,提出了一种基于深度神经网络并自定义用户行为的检测模型。该模型能够实现海量数据检测能力,能够检测未知异常行为。该方法具有较高精确度与鲁棒性。
胡富增等[19]探究用户行为特征及行为模式,建立行为模型,采用聚类分析算法,对用户日志数据进行数据挖掘与聚类分析的方法。该方法具有较为简便的特点,但不足之处在于识别成功率偏低,准确率不足。
Wang等[20]通 过 比 较 其 他 传 统 的 推 荐 系 统(recommender systems,RS),提出了一种基于会话的推荐系统(Session-based recommender systems,SBRS),模型用来进行研判用户行为,从而实现推荐功能。并在此基础上引入了等级分层框架,分析讨论了推荐模型在用户行为分析上的长处与不足。
Tang等[21]建立了一种卷积嵌入的Top-N序列推荐模型。是一种通过对用户最近行为建模为时间与潜在维度之间的“图像”,并采用卷积滤波器进行学习的顺序模型,具有较理想的效果。同样使用卷积神经网络进行建模的,还有Sun等[22]提出的一种双向编码的序列推荐模型(BERT4 Rec)。该模型也属于顺序模型,能针对用户行为实现预测、推荐功能。BERT4Rec模型,对用户行为采用双向自注意机制,解决了困扰当下推荐模型中普遍存在的用户的动态取向以及历史行为问题。
类似使用神经网络算法进行用户行为分析以及算法推荐,Karatzoglou等[23]采用了RNN(递归神经网络)模型。通过对整个会话建立基于递归神经网络的模型,调整等级损失函数使之具备特定问题的解决能力,从而使得模型整体相较传统方法具有更优秀的效果。
Kang等[24]从更全面的角度分析问题。他们分析了常用的两种用于顺序动态捕获的方法:马尔科夫链(MC)和递归神经网络(RNN)。为平衡兼顾前者简约的优势以及后者在高密度数据集中具有更好表现的优势,提出一种基于自我注意的顺序模型(SASRec)。该模型能够捕获长期语义,同时使用关注机制进行短期预测。实验表明该模型在稀疏和密集数据集上都具有优秀的表现,普遍优于各种最新的顺序模型。
1.4 研究存在问题及解决方案
根据目前对诈骗网站识别技术上的不足,本文提出了一种基于网络流量的用户互联网行为分析检测技术,将恶意流量检测与互联网行为分析应用于诈骗网站识别。本文提出的方法借鉴传统的传输层流量特征选取规则结合应用层用户行为特征编码,通过离散化后应用多项决策树交叉验证对比结果,验证各项特征选取的合理性。实验证明,本方法可以有效解决对抗指纹攻击的防范技术以及传统检测技术内存开销过大的问题,有效提高诈骗网站识别的召回率与精准率。
用户行为特征存在显性特征与隐性特征。其中,显性特征主要指用户直接向服务器发送的数据,包括提交的表单、点击的功能性按钮,等等。而隐形行为特征包括用户与服务器的交互时间、数量、频率和服务器回显的相关内容,等等。
由于隐性用户行为特征挖掘难度大,相似行为在不同网站间的表现不同,如何对用户行为特征进行规范化识别与编码,成为本文难点。同时,传统上采用的深度神经网络算法对于用户行为异常检测的精确度已经得到验证,为了适应诈骗网站指纹多样、形式复杂的特点,本文提出采用启发式深度学习算法,在保证检测精确度的前提下,增加模型动态更新能力,提高鲁棒性。
2 算法设计
2.1 总体架构
本文方法总体架构如图1所示。主要采取朴素贝叶斯算法和卷积神经网络的机器学习,通过能够观测到的流量数据,先把数据包分类,并通过词向量维数来描述数据包的文本内容。把传输的参数提取形成有特征的序列。训练集为正常的流量数据经过预处理后的数据集,统计每一类内出现词语的总词频,并取若干个频率更高的词汇作为这一类的特征词集。去除每一类别中都出现的词,合并所有类别的特征词集,形成总特征词集,最后得到的特征词集是我们用到的特征集合,再用该集合去筛选测试集中的特征。
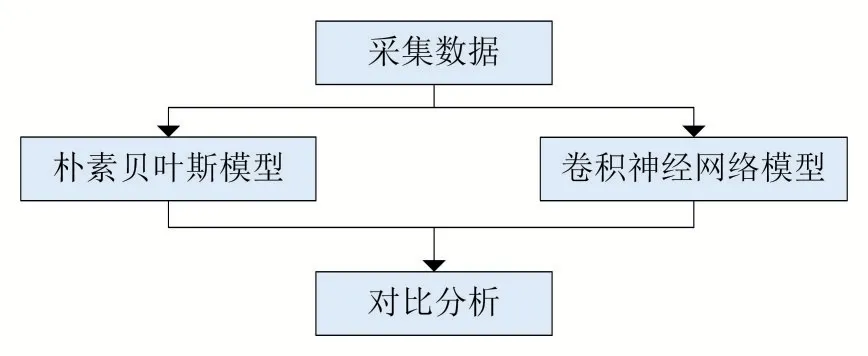
图1 总体架构
本文基本思路框架如下:
(1)以抓取的数据流量作为初始训练数据集,并根据数据集中的特殊符号进行分割,提取高频关键词生成关键词库。
(2)通过卷积神经网络进行文本特征提取、文本特征表示、归一化,最后进行文本分类。
(3)使用朴素贝叶斯算法,将样本数据集中的数据包打上标签。
通过以上3个步骤,将从网站上抓取来的流量内容分别打上标签。检测数据包通过朴素贝叶斯算法的使得流量模型中的可观测序列更加多,出现的概率更加大,从而可以更好的分析评估总体流量,从中得出更多的隐含状态。获得了流量中所隐含的状态以及概率,就可以为我们下一步的检测分析带来更多的数据。再通过卷积神经网络将文本特征分析,最后完成文本分类。
2.2 数据获取与样本增强预处理
2.2.1 用户动作分类
在流量的抓取阶段,对于用户在网页上的行为进行了分类。主要分为用户注册、登录、充值、提现、借贷、投资、绑定银行卡等行为,不同的行为对应着不同的数据包,分别进行预处理。
2.2.2 流量包抓取
流量包的抓取采用Telerik Fiddler Web Debug⁃ger软件,主要抓取用户行为所产生的http包。
2.2.3 样本增强预处理
样本的增强和预处理主要从以下两个方面展开:基于数据加噪的样本增强和基于关键词回避策略,选取部分训练数据集样本生成对应的增强样本,并且重新加入训练数据集得到增强的训练数据集。
2.3 朴素贝叶斯算法与卷积神经网络在实验中的应用
2.3.1 朴素贝叶斯算法
拆分数据包内容,将数据准备成为一系列序列,由词向量计算朴素贝叶斯用到的概率值,最终得出分析结果。
2.3.2 卷积神经网络
首先要将原始数据包内容进行预处理,主要是分词、去除停用词等,然后对预处理后的文本进行向量化,利用word2vec中的skip-gram模型,将数据包内容数据集表示为不同维度的词向量形式。转化为词向量后就可以将每一句话转化为一个矩阵的形式,通过矩阵得出分类结果。
3 实验与分析
本文根据多篇相关性文献,采用文本卷积神经网络模型(text-cnn)与朴素贝叶斯模型进行机器学习,综合对比分析实验结果,达到精准识别目标数据的用户行为。
3.1 实验训练集与测试集
本实验采用从各个基站搜集的每种行为,共近10000条数据作为训练集。然后将数据转化为两种模型所适应的特征序列,分别进行调整与优化从而达到模型的最佳状态,再通过对比分析两种算法的优缺点。表1为训练集的种类与数据数量。

表1 训练网站分类表
3.2 测试环境
数据库系统版本为mysql。
系统环境如下:内存2 GB,处理器4个。
操作系统:kali_linux_2020.1。
编程语言:g++,Python3.8.1。
3.3 实验步骤
(1)通过已有的训练集训练数据,并形成特征序列保存在数据库系统中。
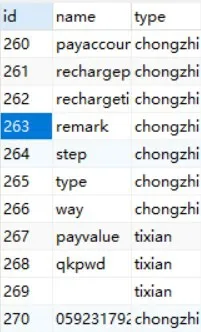
图2 特征序列
(2)使用网络抓包工具fiddler监听网卡,以受害者视角访问诈骗网站,同时最大程度的挖掘网站功能,抓取不同功能的数据包作为测试集。

图3 抓取不同功能的数据包
(3)根据(2)当中抓到的测试集先进行分类,再提取参数形成特征序列。
图4 提取参数形成特征序列
(4)调整序列格式,分别代入数据库进行匹配得出最终的结果。
(5)通过测试结果比较两种模型之间的优劣。
3.4 实验结果
3.4.1 朴素贝叶斯模型实验结果
通过人工手动的数据包采集,并进行分类。在前期工作当中,我们共筛选了1000个左右的数据包作为测试集,其中包括注册、登陆、退出、充值、下注、借贷、绑定银行卡7种行为数据包。
在第一次测试当中,由于阈值设定的不合理以及测试集当中的数据包质量与格式问题,导致识别率普遍较低的情况。

图5 注册行为识别过程

图6 行为识别成功率计算
通过调试阈值,将海明距离从3改为5,大大提高了行为识别的准确率。但是也会提高行为识别错误的概率。通过不经过分类数据包直接代入模型当中进行分系对比,计算行为识别错误率。

图7 行为识别成功率计算
3.4.2 卷积神经网络模型实验结果
将数据包进行预处理,删除部分错误、不可见字符,取出请求数据包中的数据部分,作为训练模型的输入。
使用word2vec模型根据输入数据包,提取生成词向量。生成词向量的结果如图8所示。
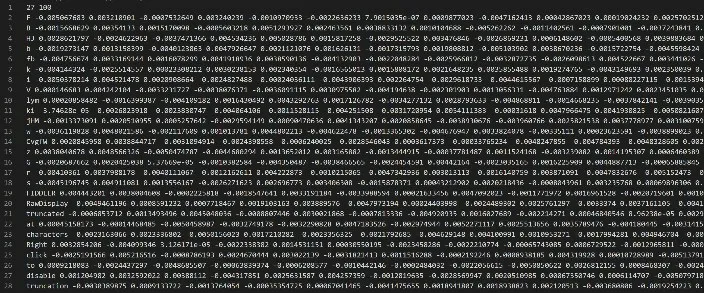
图8 word2vec词向量分词
将词向量以及训练数据集作为输入,导入卷积神经网络模型中,训练过程如图9所示。
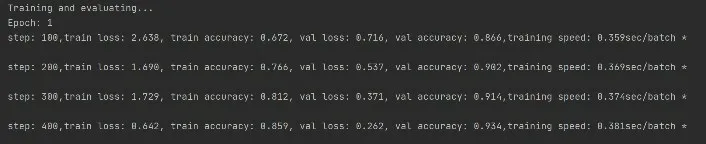
图9 卷积神经网络训练
使用包含额外1000余条数据包信息作为测试集,对卷积神经网络模型进行测试,如图10所示。

图10 卷积神经网络测试
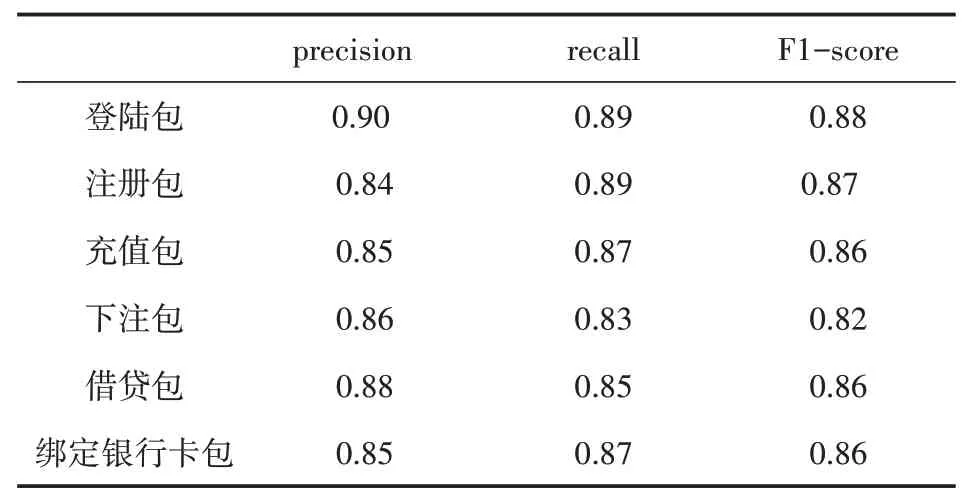
表2 卷积神经网络测试成功率表
3.5 实验分析
对于朴素贝叶斯分类模型,分析实验结果发现,该模型对于用户的“注册”“登录”“退出”行为具有较高的识别成功率,对于“借贷”“下注”行为的识别成功率较低。对于卷积神经网络模型,该模型整体上具有较高的召回率与精确度,对多种的用户行为都具有较为可靠的识别能力。
对比两种模型。从实验结果来看,卷积神经网络具有更好的识别精确度与召回率,在一定程度上是由卷积神经网络多层模型所导致的,能够很好地完成对输入数据包向量的分类工作。而朴素贝叶斯模型在实验结果上不如卷积神经网络模型理想,其精确度、召回率等数值并不理想。相比之下,卷积神经网络模型更优。
从空间、时间开销来看,卷积神经网络模型虽然具有识别精度更好的优点,但是其模型的空间开销与时间开销都比较大,模型复杂性较高。相比卷积神经网络,朴素贝叶斯模型具有开销较小,模型处理轻便快捷的特点,可以采用改进贝叶斯等优化算法以弥补其精度不足的缺点,减少其识别误差。
总体上,本文通过卷积神经网络与朴素贝叶斯两个模型进行实验对比,结合两个实验结果,分析认为卷积神经网络在识别诈骗网网站用户行为方面更为理想,能够更好地完成用户行为识别分析工作。
4 结语
本文提出了基于数据流量的诈骗网站分析方法,主要通过数据流量识别用户行为以及网站指纹信息,从而判断网站存在诈骗性质的可能性。由于文本向量较短,因此在本项目中不讨论k值的必要性。仅仅对阈值与文本向量之间的海明距离进行调整,提高用户行为识别的准确率同时控制识别的误报率在一定的范围内。
目前,互联网上存在的诈骗网站形式呈现多样化,隐蔽性增强,以及设置注册审核机制的现象,很多诈骗网站需要管理员认证或者介绍人的通信凭证作为注册要求,大大地阻碍了样本数据采集与诈骗网站打击的可能性。通过用户行为与指纹模板识别相结合,对于诈骗网站的综合快速判定具有极大的意义。在更加深入的研究与学习当中,将继续改进模型的适应性以及提高训练集样本的数量与质量,使本应用能够真正投入使用,服务社会。
猜你喜欢
制导与引信(2022年3期)2022-10-12
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
物联网技术(2018年8期)2018-12-06
软件(2017年6期)2017-09-23
中国新通信(2017年9期)2017-05-27
