
空洞卷积与注意力融合的对抗式图像阴影去除算法
2021-11-27 00:48刘万军佟畅曲海成
智能系统学报 2021年6期
刘万军,佟畅,曲海成
(辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
光线穿过一切不透明物体都会产生阴影,图像中阴影的存在十分常见。图像阴影会对目标检测与识别、图像分割等问题产生一定影响。因此,去除图像中的阴影是一个十分重要的研究内容。
去除阴影的算法按实现方法可分为基于物理模型的方法、图像自身特征的方法、机器学习和深度学习等方法。从物理模型[1-3]出发,进行阴影去除,利用光源与障碍物的关系进行建模,具有一定的可行性,但建模过程的计算量大,所需的计算参数精确度欠缺。多尺度与形态学方法[4]、区域匹配算法[5]、设置纹理置信区间[6]等算法在计算过程中存在着固有的误差。归一化植被指数(normalized difference vegetation index,NDVI)阴影影响去除线性模型[7],需对图片特定区域进行处理。递归式阴影注意力模型(recursive shadow attention model,RSAM)、新的生成器结构及多尺度图像分解法[8-9]具有局限性。机器学习方法提高了阴影检测与去除的时效性,但监测效果有待提高[10-11]。深度学习框架下图像阴影去除存在需要大量训练样本[12]、复杂照明变化任务去除不明显[13]、黑色物体误检或漏检问题[14]。当前的主流阴影去除算法,普遍存在模型设计过程中具有局限性以及阴影去除精确度不高的问题。阴影去除算法存在问题可具体总结为两方面:1)对复杂的纹理或与阴影区域相似的暗区域的情况,图像的阴影去除效果不明显;2)半影区域的图像阴影去除效果不明显,去除阴影后的图像留有较小的包围带。为了解决这些问题,提出了空洞卷积与注意力机制融合的对抗式图像阴影去除算法(CDD attention and dilated convolutions of automatic encoding and multiple attention of generative adversarial networks,ADAGAN)。该算法基于生成对抗网络的思想,将空洞卷积与残差网络、注意力编码相结合。用自定义的空洞卷积残差块进行特征提取,提取的特征信息精确性更高,使编码阶段的输入特征信息更加精准。在自动编码阶段,空洞卷积层的加入,代替了池化层,减少了不可逆的信息损失,使编码最后三层的输出包含较大范围的信息。作为临近解码阶段的空洞卷积层,是图像编码阶段全部特征的高度代表,为解码阶段提供更加精确、抽象的特征,即为解码阶段提供更精准的全局的语义特征。在判别网络中,通过多个注意力网络,进行编码的指导,减少了判别网络的误差。该算法提升了去除阴影的准确率,减小了生成的无阴影图像与真实无阴影图像的误差。
1 注意力生成对抗网络
1.1 生成对抗网络
生成对抗网络是蒙特利尔大学的Goodfellow Ian 于2014 年提出[15],由生成器和判别器两部分构成,生成器的作用是生成可以骗过判别器的图片,判别器的目的是不被生成器生成的图片骗过,生成器与判别器相互制约,共同成长,迭代至生成器生成的图片可以骗过判别器。生成器与判别器的直观感受如图1 所示。由图1(a)~(d)显示了生成对抗网络(generative adversarial networks,GAN)训练模型的过程。

图1 生成器与判别器对抗图Fig.1 Antagonism graph between the generator and discriminator
1.2 注意力机制
注意力机制是在视觉图像领域首先提出的,实际就是对目标数据进行加权变换,扩展了上下文语义信息。把注意力集中放在重要的点上,而忽略其他不重要的因素,而重要程度的判断取决于应用场景。
根据应用场景的不同,注意力机制分为空间注意力机制和时间注意力机制。空间注意力机制一般用于图像处理方面。根据注意力函数的输入序列的位置,分为软注意力机制与硬注意力机制,软注意力机制使用输入序列所有隐藏状态的加权平均值来构建内容向量。软注意力机制、空间注意力机制,形成的二维注意力图的对应权值在0~1,越重要分配的权值越大。注意力机制可由空洞残差网络与长短期记忆网络(long short term memory,LSTM)组成,可表示为

式中:ci表示整体的某一部分;表示对应ci在t时刻的注意力得分。
长短期记忆网络是Hochreiter &Schmidhuber于1997 年提出的一种特殊的循环神经网络(recurrent neural network,RNN),由遗忘门、输入门和输出门共同组成。
注意力机制的组成及应用过程如图2 所示。图2 为注意力机制在生成对抗网络中与生成网络部分结合的构成展示,不仅包含重点关注的内容,也包括周围的环境信息,注意力机制生成注意力图指导编码阶段的无阴影图像的生成。同时,注意力图受阴影模板(带阴影的图片与不带阴影的真实图片作差)的影响。具体图片的注意力图如图3 所示。

图2 生成器注意力网络Fig.2 Generator attention network

图3 生成注意力图示例Fig.3 Example of generating attention map
1.3 空洞卷积
空洞卷积(atrous convolutions)也称扩张卷积(dilated convolutions),与普通卷积层相比,引入了一个称为“扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距[16]。空洞卷积具有数据结构保留完整和不使用下采样(down-sampling)的特性,优点明显。但多层的空洞卷积也有破坏数据连续性的缺点。
空洞卷积的卷积核是通过在普通的卷积核上填0 实现的,增大了网络的扩张系数[17],空洞卷积示意如图4 所示。扩张系数与空洞卷积核的尺寸关系为

图4 空洞卷积示意Fig.4 Example of dilated convolutions

式中:γ表示空洞卷积的扩张系数;ksize表示普通卷积核尺寸;kdsize表示空洞卷积核尺寸,当γ=1 时即为普通卷积核。
1.4 损失函数
在生成对抗网络中,为了达到纳什平衡[18],需优化,见式(3):

式中:G为生成网络;D为判别网络;pdata(x)代表真实分布;pn(z)代表噪声分布。
注意力机制的损失函数为

损失的计算是通过比较每次生成的注意力图(At)与对应图片阴影掩模(M)之间的均方误差(MSE)进行的。由参考文献[19-23]得知,N取5,θ取0.8 为宜。
编码阶段的损失(Le)由两部分构成,即图片的真实损失(Lr)和模型损失(Lm)。图片的真实损失为编码生成的图片与真实图片的均方误差,β取值参考文献[19]。模型损失为通过VGG 网络编码生成的图片与真实图片的损失的均方误差,可表示为

2 ADAGAN 算法
为了解决图片阴影去除过程中存在的阴影少量遗漏,半影去除不完全的问题,提出了ADAGAN算法。该算法中GAN(generative adversarial networks),即生成对抗网络,是该算法的主体思想。第1 个A(CDD of attention)指的是生成器中注意力机制特征提取运用CDD(convolutions and dilated convolutions and dilated convolutions)空洞残差块;D(dilated convolutions of automatic encoding)指的是在生成器自编码阶段加入的4 层相同结构的空洞卷积层;第2 个A(multiple attention)指的是判别器中的多重注意力网络。
2.1 算法总体架构
ADAGAN 算法运用细节信息提取更精细的VGG-E 作为该网络的预训练模型。基于生成对抗网络架构,主体可分为图片阴影的特征提取、注意力编码和判别网络3 部分。其中,特征提取与注意力编码属于生成器部分,判别网络属于判别器部分。
在生成器部分,对图片阴影信息进行特征提取,特征提取使用CDD 残差块,提取特征作为生成器注意力机制的输入。在生成器的自编码阶段,加入空洞卷积层。判别器部分由多层卷积注意力(multiple attention)网络组成。空洞卷积阴影去除算法整体框架如图5 所示。其中,注意力编码部分由注意力生成网络和自动编码网络组成。

图5 空洞卷积阴影去除算法整体框架图Fig.5 Block diagram of the dilated convolution shadow removal algorithm
生成器与判别器部分相互作用,互相影响,形成表现良好的图片去除阴影网络。
2.2 CDD 残差块
为了增加对图片中阴影信息提取的精确度,在网络中引入CDD 残差块。该方法运用普通卷积与空洞卷积组合的方式,结合残差网络的结构,使生成器注意力机制部分的输入特征更加充分。
空洞卷积能在不增加算法复杂度的情况下,具有更大的感受野,越大的感受野包含越多的上下文关系,但它也会损失信息的连续性,适合大区域的阴影。为了使空洞卷积对小区域的阴影也有很好的特征感知强度,借助残差网络的结构,发现二者的结合,有助于提高特征提取阶段的精确性。残差块对比如图6 所示。为了特征提取的表达更加精确细致,改变激活函数relu 为lrelu,使值为负数时,也有一定区分,不全为0。

图6 残差块对比Fig.6 Residual blocks comparison
2.3 扩展的编码阶段
在编码阶段加入空洞卷积层,使特征表达更加充分,增大特征的感受范围,减少计算量。该实验在7 层卷积后,加入4 层同样结构的空洞卷积层,通过多层堆叠的方式增加感受野,为后续的解码过程提取更抽象、更本质的全局的语义特征。
编码阶段可分为编码与解码两个部分,编码由卷积层与空洞卷积完成,解码由反卷积与卷积配合完成。
该实验编码阶段共由11 个卷积层,4 个空洞卷积层,2 个反卷积层以及3 个跳跃连接层组成,各层之间的连接关系见表1。其中编码阶段的输入为带阴影的图像与注意力图,每层之间的激活函数为LRelu,输出结果为不带阴影的图片。Conv代表卷积层,Dia_conv 代表空洞卷积层,Deconv代表反卷积层,Skip 为跳跃连接层。

表1 去除阴影算法编码表Table 1 Shadow removal algorithm code
2.4 改进判别网络
卷积网络无法有效地捕捉图像的几何结构和形状,而注意力模型可通过不同的权重系数来强调目标的重要性,抑制无关的细节[20],且不需要监督。注意力模型的最终目的是帮助类似编解码器这样的框架,更好地学到多种内容模态之间的相互关系,从而更好地表示这些信息,克服其无法解释从而很难设计的缺陷。因此可以灵活地感知到全局与局部的联系,提升网络的感知能力,提高输出的质量。
注意力机制可分为加法注意力机制和乘法注意力机制,乘法注意力机制是面对加法注意力机制要求编码与解码的隐藏层长度必须相同的条件的改进,具有更高的灵活性。因此,在判别器设计中,运用乘法注意力机制。而在多次网络卷积结构后,特征信息逐渐精简的同时,重点可能会被分散。因此,在每2 层卷积层中加入乘法注意力机制,突出重点,强调特征,感知全局,提升质量。判别器设计如图7 所示。

图7 判别器设计图Fig.7 Design of the discriminator
3 实验及结果分析
3.1 实验环境及数据集
1080Ti 显卡。数据集选取ISTD[21]和SRD[22]。
实验环境为ubuntu16.10 系统、GeForce GTX ISTD 数据集共1870 对阴影与非阴影数据对,其中训练集1330 对,测试集540 对。SRD 数据集共3088 对阴影与非阴影数据对,其中训练集2680 对,测试集408 对。
3.2 实验评价
实验的评价主要从视觉效果和现流行的衡量指标(结构相似性、峰值信噪比、均方根误差)进行评价。结构相似性(structural similarity,SSIM)基于图像亮度、对比度和结构进行评价,可表示为
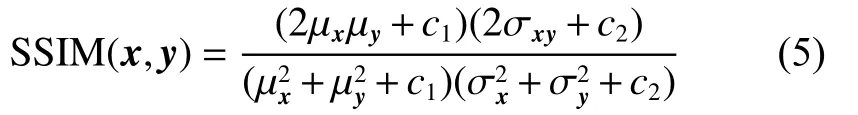
式中:x、y代表要比较的两张图片;µx为x的均值,µy为y的均值;为x的方差;为y的方差;σxy为x和y的协方差;c1=(k1L)2、c2=(k2L)2为两个常数,避免除0;L为像素范围;本次实验k1为0.01;k2为0.03。式(5)的值越接近1,两图片相似性越强。
峰值信噪比(peak signal-to-noise ratio,PSNR),单位是dB,数值越大表示效果越好。峰值信噪比基于对应像素点间的误差,即基于误差敏感的图像质量评价。不考虑人眼的视觉特性,会出现评价结果与人的主观感觉不一致的情况,可表示为
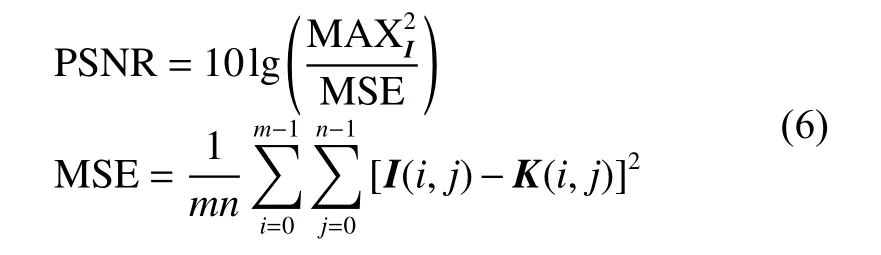
式中:m、n分别为图像的长与宽;I为真实图像;K为生成图像。
均方根误差(root mean squared error,RMSE)是一个中间的评价指标,很多评价指标都是基于均方根误差进行的,是均方误差(MSE)的开根号数,均方根误差可用来计算阴影图与非阴影图的像素级误差,可表示为

3.3 实验结果与分析
实验中针对生成器与判别器的特点,并参考文献[23]来设置学习率参数。其中,生成器网络学习率为0.002,判别器网络学习率为0.001,且每进行10000 次训练,学习率缩小0.1 倍。预训练参数基于VGG-E 网络。阴影区与非阴影区的像素差的阈值设为30。
该实验在ISTD 数据集与SRD 数据集上进行实验,经过100000 次训练,实验最佳结果SSIM可达到0.977,PSNR 为32.2,RMSE 为6.2。因ISTD 与SRD 数据集中各类别图像在数据集中的占比不一致且同一类别中各图像阴影区域的占比也不一致,因此分别在两个数据集的测试集中选取不同类别。在同一类别中选取一副图片进行测试,并对它们的值进行展示,不同数据集效果对比见表2(其中,图片1~3 为ISTD 数据集上图片,图片4~6 为SRD 数据集上图片)。
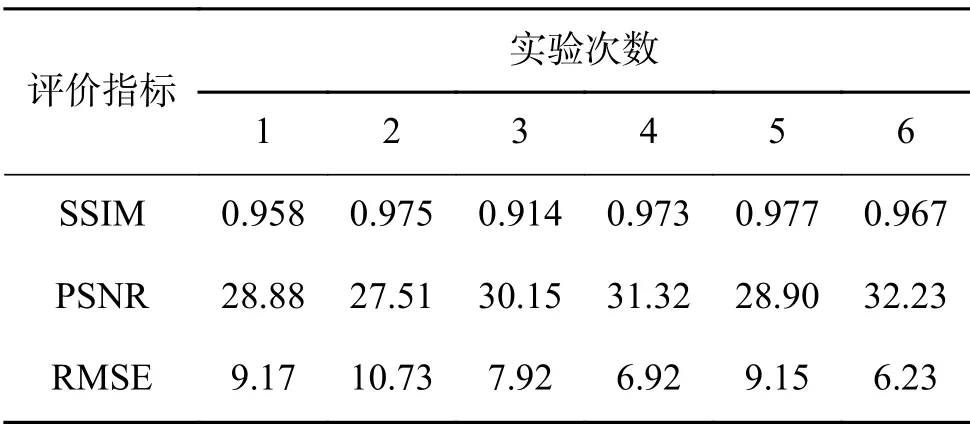
表2 不同数据集效果对比Table 2 Comparison of effect of different data sets
该算法分别在ISTD 和SRD 数据集上选取3 个图片进行展示,可见该算法的阴影去除效果较好,对相对复杂地物的阴影去除效果也表现良好,视觉感受上不存在半影情况。不同数据集实验效果如图8 所示。图8 共6 组图片,前3 组(图(a)~(i)) 为ISTD 数据集的测试图片,后3 组(图(j)~(r))为SRD 数据集的测试图片。

图8 不同数据集实验效果Fig.8 Experimental renderings of different data sets
实验是基于GAN 网络与空洞卷积、注意力结合的思想进行的,分别在特征提取、自编码、判断网络进行巧妙设计。其中特征提取运用空洞残差块,自编码加入空洞卷积,判别网络加入多层乘法注意力网络。逐步改进实验效果见表3。由表3可知,CDD 残差块的引用,虽具有更大的感受野,但因破坏了信息的连续性,造成客观衡量指标的降低,为了兼顾感受野与信息的连续性,即主观视觉感受与客观衡量指标,在运用CDD 残差块的同时引入注重连续性的注意力机制(LSTM 为核心模块),解决了特征提取过程增加感受野与关注信息连续性的问题,提升阴影区域特征提取的精确性。因此,综合使用CDD 残差块与注意力机制时,客观衡量指标有明显的提升。
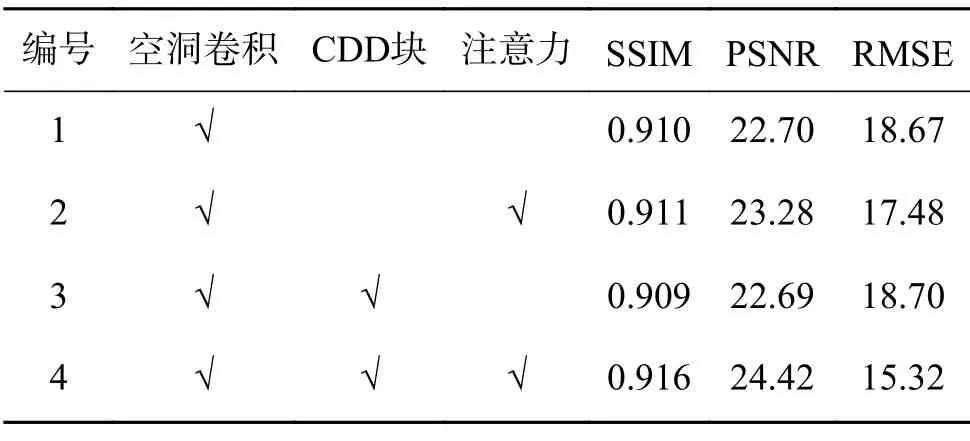
表3 逐步改进实验效果Table 3 Gradual improve ment of the experimental effect
表3 指标为SRD 训练集上,20000 次训练后,随机选取一幅图像(MG_4699)进行测试的结果,逐步改进实验视觉效果如图9 所示。

图9 逐步改进实验视觉效果图Fig.9 Gradual improve ment of the visual effect of the experiment
通过图9 这组实验可以看出:在判别网络中嵌入多重注意力,可以提高阴影去除的效果。空洞残差块使特征提取阶段具有更大的感受野,但同时也破坏了信息的连续性。由表3 可知,在加入空洞残差块后,客观测量指标有所下降。但从图9 的图像的视觉效果来看,图像的主观视觉效果比较好。因此,把两者结合进行实验,发现实验无论在视觉效果,还是在图像测试指标上,都比其他效果要好。
为了证明该算法的有效性,用该算法与参考文献[5,14,21]进行对比。文献[5]为依靠图像自身特性进行的阴影去除的方法,按文献[5]的思路与参数进行对比实验。文献[14]与文献[21],均在ISTD(训练集1330 对,测试集540 对) 与SRD(训练集2680 对,测试集408 对)数据集上进行训练与测试,参数配置参考各自原文献。对比实验的方法,均与本文算法在同实验条件下进行,视觉效果如图10、11 所示。图像在ISTD 数据集测试指标对比见表4。

图10 算法对比视觉效果图1Fig.10 Algorithm comparison visual effect chart 1


图11 算法对比视觉效果图2Fig.11 Algorithm comparison visual effect chart 2

表4 算法测量指标对比Table 4 Comparison of algorithm measurement indexes
4 结束语
本文针对图片阴影去除过程中出现的阴影遗漏现象及半影部分去除不全面的问题,提出空洞卷积与注意力融合的对抗式图像阴影去除算法。该算法用新型的空洞残差块进行特征提取,加大感受野的同时减少了计算量,加强了特征感知的强度。编码阶段,空洞卷积层增加了特征表达的充分性,具有更为全局的语义信息,减少计算复杂度。注意力机制的引入加强了网络对全局与部分的把控。本算法的阴影去除效果,无论从测量指标还是视觉感受,都达到了比较理想的效果。该算法也可以迁移到其他同类型的监督学习的应用中。
本文提出的算法也存在一些不足之处,算法对于小规模数据集的效果不够明显,且生成的图像与原图可能会存在一些细微误差。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
上海金属(2021年2期)2021-04-07
文苑(2020年11期)2020-11-19
北京航空航天大学学报(2020年10期)2020-11-14
中国诗歌(2019年6期)2019-11-15
自动化学报(2019年6期)2019-07-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
故事作文·高年级(2017年2期)2017-03-01
数学大王·中高年级(2016年4期)2016-05-14
新闻传播(2015年20期)2015-07-18
