
一种卷积神经网络集成的多样性度量方法
2021-11-27 00:48汤礼颖贺利乐何林屈东东
智能系统学报 2021年6期
汤礼颖,贺利乐,何林,屈东东
(1.西安建筑科技大学 机电工程学院,陕西 西安 710055;2.西安建筑科技大学 理学院,陕西 西安 710055)
集成学习是一种重要的机器学习方法,主要思路是多个分类器基于某种组合方式组合在一起,来取得比单个分类器更好的性能,从而可显著提高学习系统的预测精度和泛化能力[1]。
基分类器之间的多样性是影响集成系统泛化性能的重要因素[2],产生泛化能力强、差异性大的基学习器是集成算法的关键。但如何有效的度量并利用这些多样性还是一个悬而未决的问题。目前大多数多样性度量方法都是基于基分类器的0/1 输出方式(Oracle 输出),主要分为两大类:成对度量和非成对度量。成对度量方法主要有Q 统计方法[3]、不一致度量方法[4]、双错度量方法[5]和相关系数法[6]等;非成对度量方法主要有KW 差异度量方法[7]、κ评判间一致性度量方法[8]、熵度量方法[9-10]、难度度量[11]、广义差异性度量[12]等。
近年来国内学者们也提出了一些新的研究多样性度量方法。例如:邢红杰等[13]提出了一种关系熵多样性度量方法,结合相关熵和距离方差描述支持向量数据来实现选择性集成;李莉[14]提出了一种距离信息熵的多样性描述方法实现基分类器集成,该方法在UCI 数据集上具有与成对差异性度量方法一致的效果;赵军阳等[15]针对多分类器系统差异性评价中无法处理模糊数据的问题,提出了一种采用互补性信息熵的分类器差异性度量方法,该方法省略了对分类器输出结果的正确性判别过程,直接处理分类器的输出结果,但是未考虑集成规模与精度之间的平衡问题,对系统的泛化性能有一定的影响;周刚等[16]提出了一种联合信息增益的过程多样性度量方法,该方法在西瓜数据集上拥有与传统方法相近的准确性。上述几种方法都是基于信息论角度来定义多样性的,基模型的训练和集成都采用机器学习方法得到,在应用卷积神经网络集成的多样性研究方面较少。
随着深度学习的快速发展,卷积神经网络(convolutional neural network,CNN)[17]因其独特的结构已成为当前图像识别领域的研究热点。卷积神经网络分类器的输出方式与Oracle 输出方式不同,采用的是c维向量输出方式。在处理多分类(c>2)问题中,分类器输出单元都需用Softmax 激活函数进行数值处理,将多分类的输出数值向量形式转化为类标签的相对概率向量方式,即c维向量形式D(z)=[d0(z)d1(z) ···dc−1(z)],dc−1(z)为分类器D给出的样例属于第c−1类的置信度,i=1,2,···,c−1,c为不同类标签的数目。针对卷积神经网络的概率向量输出结果,使用0/1 输出准则来统计分类器对样本分类结果的正确/错误个数来计算多样性,是一种硬性的评判标准[18]。如两个5 分类器的输出概率向量是Di(z)=(0.17,0.03,0.6,0.05,0.15)和Dj(z)=(0.1,0.2,0.5,0.17,0.13),将它们转化为Oracle 输出方式,两个分类器的结果都为第三类,二者输出结果一致,采用基于模型的Oracle 输出结果多样性度量方法将会判定二者没有任何不同。但事实上,两个分类器输出结果存在明显的不同,Oracle 输出方式未能充分利用卷积神经网络输出的概率向量所包含的丰富信息。
针对此问题,本文充分利用多分类卷积神经网络的输出特性信息,提出了一种基于卷积神经网络集成的多样性度量方法。采用概率向量输出方式来表示模型分类结果,引入两个向量的差异性,针对每一个训练样本计算模型输出结果之间的差异性来评估多样性。
1 3 种传统多样性方法
假设存在分类器 hi和 hj(i,j=1,2,···,T,i≠j),1 表示分类器正确,0 表示分类器分类错误,两个分类器的联合输出结果用表1 中a、b、c、d 表示。a表示在训练过程中分类器 hi和 hj都对样本分类正确的样本个数,b表示在训练过程中分类器hi对样本分类错误而分类器 hj分类正确的样例个数,c表示分类器 hi对样本分类正确而分类器hj错分的样例个数,d表示分类器 hi和 hj都对样本错分的样例个数。由此,总的样本个数可以表示为m=a+b+c+d,两个分类器之间的关系如表1所示。
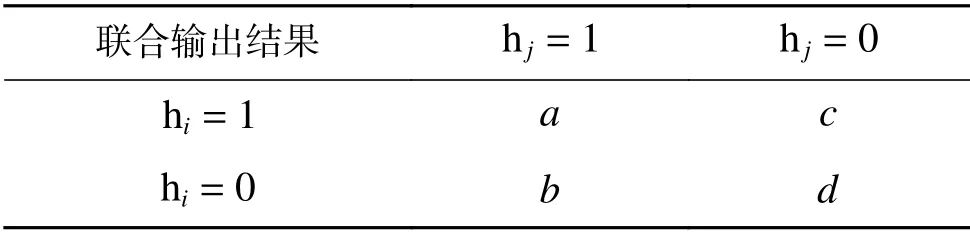
表1 两个分类器之间的关系Table 1 Relationship between a pair of classifiers
1)Q统计方法(Q)

Q的取值为[−1,1],当两个分类器总是对其正确分类或者错误分类,说明其行为是一致的,则有b=c=0,即Qij=1,此时它们的多样性最低;反之,如果两个分类器的分类刚好一个正确一个错误,即Qij=−1,这种情况下多样性最好。
2)不一致性度量(Dis)
不一致性度量表示两个分类器之中一个判断正确一个判断错误的测试个数与总测试个数的比值。

3)双错度量方法(DF)

DF取值范围为[0,1],值越大,说明两个分类器都对其分类出错,多样性越差。
2 基于概率向量输出方式的多样性度量方法
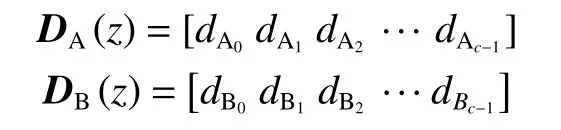
首先定义两个多类分类的分类器 A和 B,zj(j=1,2,···,m)为m个样本中的第j个样本,则对样本zj的模型输出概率向量为其中,向量中的各元素是模型预测概率值,索引(A0,A1,A2,···,Ac−1)和(B0,B1,B2,···,Bc−1)分别为向量DA和DB各概率对应的类标签值,有,。
模型经过训练之后,输出层经过Softmax 激活函数得到模型概率向量结果,定义卷积神经网络的多样性度量方法,基本思路如下:
1)将2 个分类器概率向量中的元素从大到小进行排列,并返回其对应的index(类标签)值,得到分类器最大置信度概率由大到小排列对应的类标签向量LA[i]和LB[i],i=0,1,2,···,c−1,c为不同类标签的数目。

2)对于已标记单一样本zj,两个分类器的多样性DAB(zj)定义如式(5)、(6):

式中:ki为不同排序位置差异的权重(越靠前的输出结果不一样说明差异性越大),本文通过多次实验对比,最终取值为{32,8,4,2,1,0,···,0},采用指数递减值。
式(4)返回两个分类器元素之间的差异性结果序列。分类器之间的多样性只是反映两个模型对于已标记样本差异性,与模型类标签值无关,与输出结果的位置无关。因此,为了保证度量的准确性和有效性,定义式(5)在分类器相同的索引值情况下,当两个分类器输出类标签是一致时,返回为0;当输出类标签不同时返回为1。将式(5)代入式(6),得到两个分类器对于单一样本多样性的定义。值越大,两个概率向量差异性越大,分类器之间的多样性也就越大。
假设对于样本zj两个5 分类的输出概率向量是D1(zj)=(0.03,0.07,0.6,0.05,0.25)和D2(zj)=(0.1,0.17,0.4,0.2,0.13),得到分类器最大置信度概率由大到小排列对应的类标签向量和,得到向量fAB(i)=(0,1,1 1 0)。对于单一样本z得到
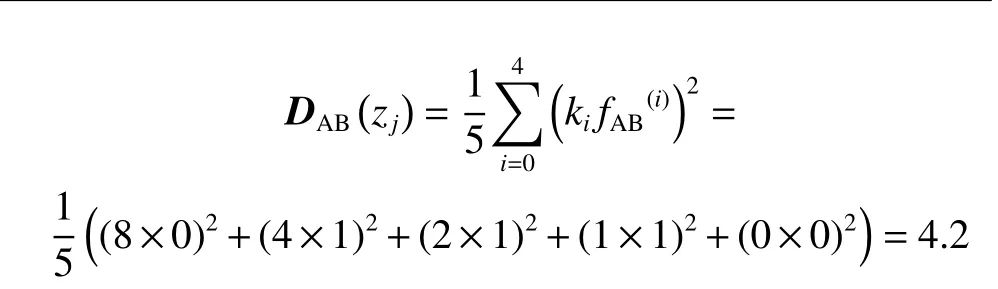
而如果采用基于Oracle 输出的多样性度量方式,对于该样本两分类器输出结果相同,得到的多样性为0。
3) 对于已标记样本集Z={z1,z2,···,zj,···,zm},两个基模型之间的多样性为所有样本的集合多样性后的平均值,如式(7)所示:

4)对于多分类器系统{D1,D2,···,DT},其多样性为计算每对基模型之间的多样性的平均值:

3 实验验证与分析
为了验证新的多样性度量方法的有效性和先进性,采用4 种方法计算基模型的多样性:Q统计、不一致性度量、双错度量和本文提出的基于概率向量方法DPV。在CIFAR-10 与CIFAR-100 数据集上分别进行了实证对比分析。
实验分析主要分为3 部分内容:1)训练19 个基学习器模型,并得到单个基模型以及预测结果;2) 基于CIFAR-10、CIFAR-100 数据集采用4 种方法计算各基模型之间的多样性;3)在数据集上进行基模型的集成预测,采用简单平均集成策略集成基模型,并对比分析单个模型与集成模型之间的预测结果。
3.1 模型结构
卷积神经网络是一种具有深度结构的前馈神经网络,对于大型图像处理具有十分出色的表现[19]。CNN 的基本结构由输入层、卷积层、池化层、全连接层和输出层构成。本文构造了19 种不同结构的CNN 网络模型,网络结构都包括输入层、卷积层、池化层、Dropout 层、Flatten 层和全连接层,各模型结构不同之处在于卷积层、池化层和Dropout 层的不同。表2、3 为其中9 个模型的具体结构。

表2 4 个候选基模型结构Table 2 Structures of four-candidate basic models

续表2
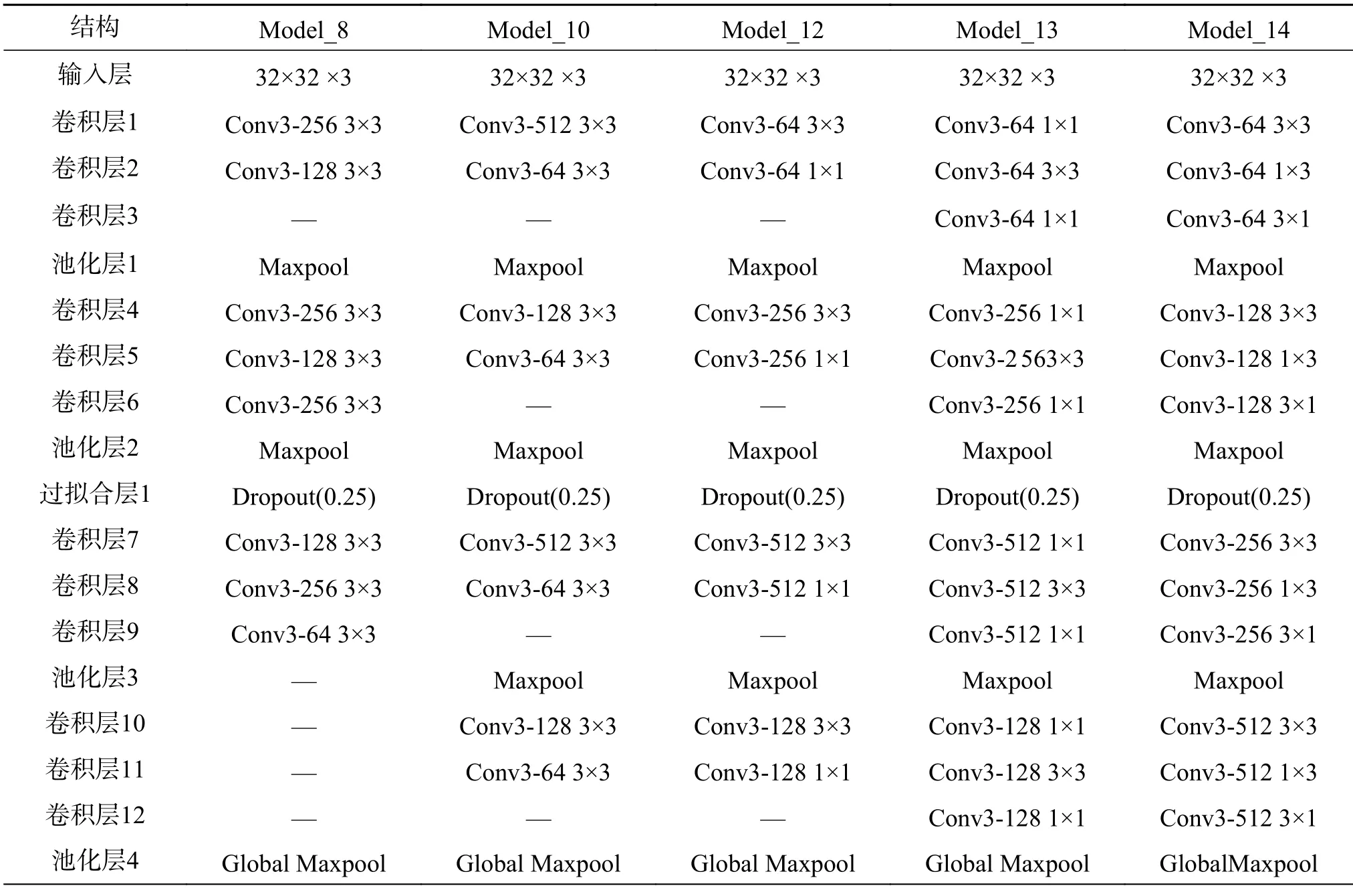
表3 5 个候选基模型结构Table 3 Structures of five-candidate basic models

续表3
3.2 实验环境及评价指标
本实验采用的是Windows10 系统的GTX1 660Ti 6 GB 独立显卡实验平台。在Window10 系统下,所有网络均基于深度学习框架Tensorflow2.0实现。
模型的性能评价指标包括训练集、验证集、测试集的准确性(Accuracy,简称Acc),是衡量模型正确分类的标准。其中测试集的准确率直接反映了模型的预测能力,见式(9)所示:

式中:m是已标记样本集Z={z1,z2,···,zm}中样本个数;yj是类标签;f(xj)为模型预测结果;I是条件判断函数。
3.3 实验数据集
CIFAR-10 和CIFAR-100 数据集是用于普适物体识别的图像分类数据集,由Alex 等[20-21]收集。CIFAR-10 和CIFAR-100 数据集都包含60000张32 像素×32 像素的彩色图片,分别为训练集50000 张和测试集10000 张,训练集用于训练基学习器,并计算模型间多样性值;测试集则用于对各种基模型和集成模型的预测效果进行验证和对比。CIFAR-10 数据集分为10 个类,每个类有6000 张图片;CIFAR-100 数据集有20 个超类,每个超类分为5 个小类,总计100 分类,每个分类包含600 张图片。
3.4 实验结果分析
3.4.1 基模型预测结果
基学习器模型分别在CIFAR-10 和CIFAR-100 数据集上进行训练,使用SGD 优化器[22]更新权重,对训练数据集首先进行图像预处理,包括图像归一化和数据集打乱,批量规范化之后训练单批次大小为128。经过反复实验,卷积神经网络模型大概在200 次迭代之后已经完全收敛,识别率达到了最高,故Epochs 值设置为200;在卷积操作中使用ReLU[23]激活函数,添加L2正则化处理,参数设置λ为0.001;利用Dropout 防止过拟合,设置为0.25;采用分段学习率训练方式,初始学习率设为0.01,动量系数均为0.9;权重初始化采用He 正态分布初始化器,偏差初始化为零。单个基模型经过训练后的预测结果如表4 所示。

表4 19 个候选基模型预测结果AccTable 4 Prediction results Acc of 19 candidate basic models %
由表4 可知,基模型15~19 的预测准确性较低,考虑到模型集成之后的效果,初步筛选出基模型1~14 作为初筛选基模型。
3.4.2 基于CIFAR-10 数据集的多样性分析
表5 是3 种传统多样性方法和本文方法分别在CIFAR-10 数据集上得到的多样性统计值最大的两分类器集成模型,表6 是表5 得到的两分类器集成模型在测试集上的预测结果。同理,表7是得到的多样性统计值最大的三分类器集成模型,表8 是其预测结果;表9 是得到的多样性统计值最大的四分类器集成模型结果,表10 是其预测结果。其中,平均集成精度是指通过多样性方法筛选得到的三组集成模型组合采用简单平均集成策略得到的在测试集上的集成精度,并求取平均值的结果;基模型平均精度是指表6 中筛选出的单个基模型在测试集上的分类精度的平均值。如表6 中DF 方法的平均集成精度就等于表5 中对应的3 个两分类器集成模型2-14、2-5 和5-14 分别在测试集上的集成精度的平均值,而相应的基模型平均精度是指单一基模型2、5 和14 测试精度的均值结果。

表5 CIFAR-10 上多样性最大的两分类器集成模型Table 5 Results of an optimal two-classifiers model on CIFAR-10
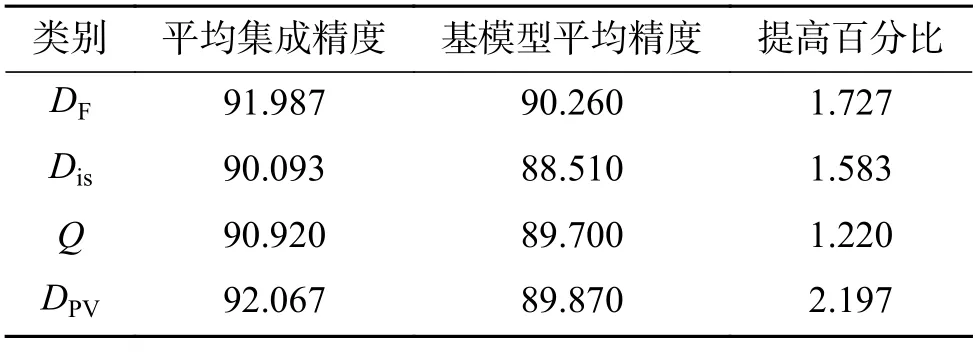
表6 两分类器集成模型在CIFAR-10 上预测结果Table 6 Prediction results of two-classifier models on CIFAR-10 %
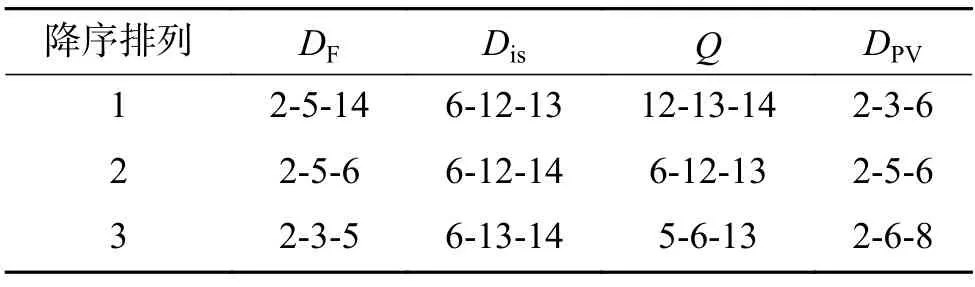
表7 CIFAR-10 上多样性最大的三分类器集成模型Table 7 Results of optimal three-classifier models on CIFAR-10

表8 三分类器集成模型在CIFAR-10 上预测结果Table 8 Prediction results of three-classifier models on CIFAR-10 %

表9 CIFAR-10 上多样性最大的四分类器集成模型Table 9 Results of optimal four-classifier models on CIFAR-10
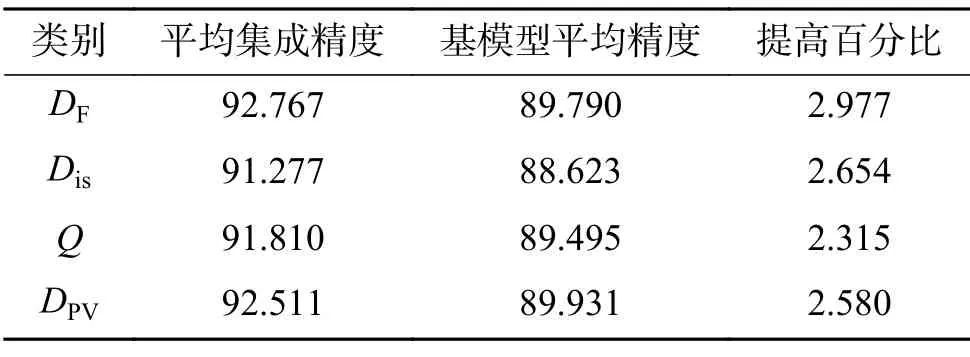
表10 四分类器集成模型在CIFAR-10 的预测结果Table 10 Prediction results of four-classifier models on CIFAR-10 %
由表5、6 可知,本文方法筛选出的二分类器集成模型是2-6、2-3 和2-5,平均集成精度相比于基模型平均精度提升效果最优,提升了2.197%;由表7 和表8 可知,本文方法筛选出的三分类器集成模型为2-3-6、2-5-6 和2-6-8,集成精度相比于基模型平均精度提升效果最优,提升了2.575%;由表9、10 可知,本文方法筛选出的四分类器模型是2-3-5-6、2-3-6-8 和2-3-6-10,集成精度相比于基模型精度提高了2.580%,比Q统计方法效果好,比不一致性方法相差0.397%,比双错度量方法相差0.074%。同时,本文方法筛选出的二分类器的平均集成精度是最高的,达到了92.067%,性能相比于其他3 种方法是最优的,三分类器和四分类器的平均集成精度与双错度量得到的结果相近,且高于不一致性方法和Q统计方法,说明本文提出的基于概率向量的多样性度量方法是有效的。
3.4.3 基于CIFAR-100 数据集的多样性分析
为进一步验证本文所提方法的有效性,在CIFAR-100 数据集上进行验证实验。表11 是3种传统多样性方法和本文方法分别在CIFAR-100数据集上得到的多样性统计值最大的两分类器集成模型,表12 是表11 得到的两分类器集成模型的预测结果;表13 是得到的多样性统计值最大的三分类器集成模型,表14 是其预测结果;表15 是得到的多样性统计值最大的四分类器集成模型,表16 是其预测结果。
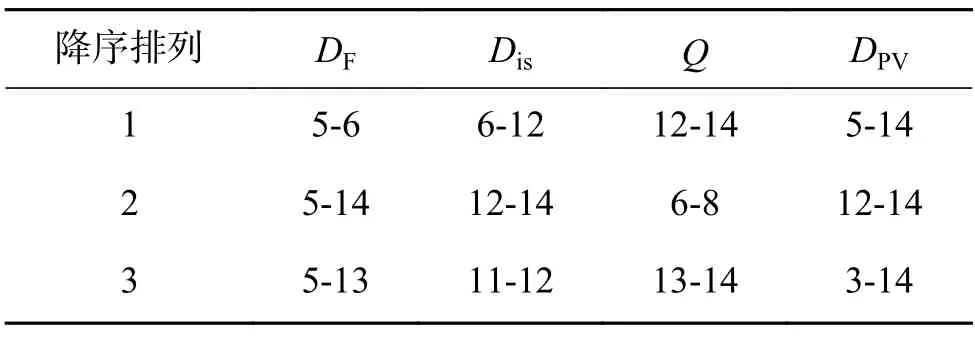
表11 CIFAR-100 上多样性最大的两分类器集成模型Table 11 Results of optimal two-classifier models on CIFAR-100

表12 两分类器集成模型在CIFAR-100 的预测结果Table 12 Prediction results of two-classifier models on CIFAR-100 %
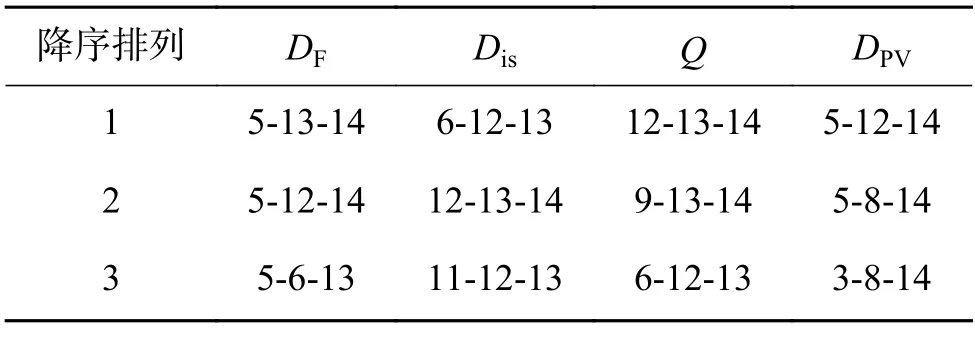
表13 CIFAR-100 上多样性最大的三分类器集成模型Table 13 Results of optimal three-classifier models on CIFAR-100

表14 三分类器集成模型在CIFAR-100 的预测结果Table 14 Prediction results of three-classifier models on CIFAR-100 %

表15 CIFAR-100 上多样性大的四分类器集成模型Table 15 Results of optimal four-classifier models on CIFAR-100
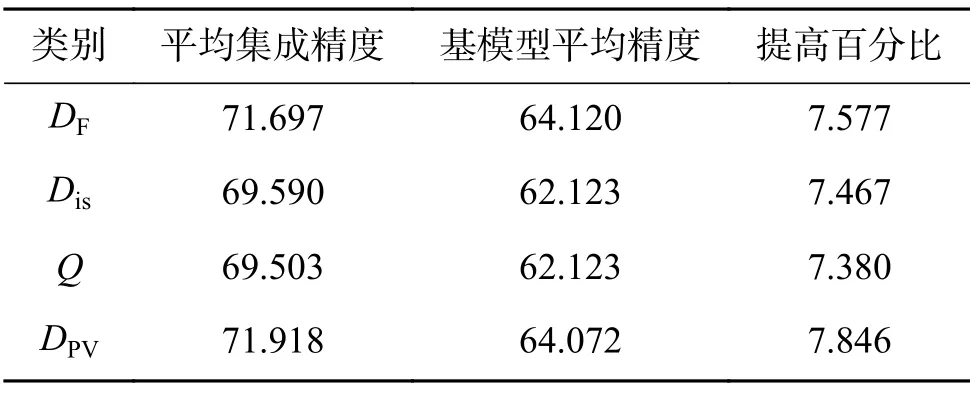
表16 四分类集成模型在CIFAR-100 的预测结果Table 16 Prediction results of four-classifier models on CIFAR-100 %
由表11、12 可知,本文方法在CIFAR-100 数据集上筛选出的二分类器集成模型是5-14、12-14 和3-14,平均集成精度相比于基模型平均精度提升效果最优,提升了5.812%;由表13、14 可知,本文方法筛选出的三分类器集成模型为5-12-14、5-8-14 和3-8-14,平均集成精度相比于基模型平均精度提升效果最优,提升了7.421%;由表15、16 可知,本文方法筛选出的四分类器模型是3-5-12-14、3-5-8-14 和5-8-12-14,平均集成精度相比于基模型平均精度提高了7.846%,集成精度相比于基模型精度提升效果最优。同时,在CIFAR-100 数据集上,本文方法相比于其他3 种方法,筛选出的集成模型的平均集成精度无论是二分类器、三分类器还是四分类器都是最高的,集成性能优于双错度量方法、不一致性方法和Q统计方法,再次验证了本文方法的有效性。
在基模型准确性比较接近的情况下,在CIFAR-10 数据集上DPV方法和双错度量方法筛选出的集成模型的集成性能较接近,都优于不一致性和Q统计方法;在CIFAR-100 数据集上,DPV方法筛选出的集成模型无论是平均集成性能还是相对于基模型提升的效果都是最佳的。由此说明,在基模型相对较弱,模型之间有更大的互补空间可以利用时,DPV方法更能够体现模型之间的互补性,可选择更好的模型组合进行集成。通过在CIFAR-10 和CIFAR-100 数据集上验证,本文提出的DPV方法可以充分利用卷积神经网络的概率向量的输出特性,深度挖掘模型内部互补信息,相较传统多样性度量方法更能够体现出模型之间的互补性和多样性。
4 结束语
针对目前模型集成中多样性度量方法在基模型为卷积神经网络时未充分利用基模型输出的概率向量信息的问题,本文提出一种基于卷积神经网络概率向量的多样性度量方法。通过在CIFAR-10 和CIFAR-100 数据集上训练多个不同结构的卷积神经网络进行基于多样性方法的选择对比实验,结果表明,在CIFAR-10 数据集上本文方法和双错度量方法相近,且优于不一致性和Q统计方法;在CIFAR-100 数据集上,相比于双错度量、Q统计和不一致性方法,本文提出的方法是最优的。本文提出的方法能够充分利用卷积神经网络的概率向量输出特性,更好地体现模型之间的多样性,特别是在基模型整体较弱时,能够选出集成效果相对更好的模型组合,且集成模型的性能对比基模型平均性能的提升效果也更优。此方法为基于概率向量输出的卷积神经网络模型集成选择提供了一种新的多样性度量思路。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学年刊A辑(中文版)(2019年3期)2019-10-08
数学物理学报(2017年5期)2017-11-23
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国学术期刊文摘(2016年1期)2016-02-13
电测与仪表(2014年15期)2014-04-04
