
油田勘探开发云平台数据存储模型研究与实践
2021-11-27 02:13李代先周少丹
西安石油大学学报(自然科学版) 2021年6期
谯 英,李代先,周少丹
(1.西南石油大学 计算机科学学院,四川 成都 610500;2.中国石油长庆油田分公司 第二采气厂,陕西 榆林 719000)
引 言
计算机应用技术和网络通信技术飞速发展,导致各种数据量的急剧增多,如何有效管理、应用这些数据,为故障诊断、产能分析、企业决策提供更有价值的参考模型,是油田勘探开发云平台建设的重中之重。相对传统格式的数据而言,大数据呈现一些新的特点,如非格式化数据的类型越来越多;同类型数据条目之间大小差别很大、形式多样。云平台下数据具有海量、异构、非确定性的特点,云数据管理面临巨大挑战,因此必须引入新技术对海量数据进行存储、处理和应用。从资源共享的角度,人们期望油田勘探开发云平台建设完成之后要达到以下要求:一是无论常量数据还是海量数据都能够存储,同时能最大限度地共享这些数据,尽量减少数据孤岛的形成,对已形成的数据孤岛尽量消除,对海量数据进行合理管理,数据和资源能够在多个部门之间被有效利用;二是网络设备、交换机、路由器、网关、服务器等硬件资源能够按需在线申请;三是数据库、操作系统等软件平台、中间件能够共享;四是计算能力能够按需获取[1]。
1 油田数据特点
1.1 多源性突出
油气生产业务中产生的数据涉及油田地质勘探开发、地震、分析试验、钻井、完井、油气采集等多个领域,加之油田分布范围大、空间立体性强、油田开采的时间跨度大等,导致多元性特点突出。
1.2 异构性明显
计算系统结构的异构、操作系统和数据格式及类型的不同、数据物理存储地异构均产生数据异构。
1.3 非格式化数据量大
油田勘探开发过程中应用了很多信息领域、油田建设领域的新技术,如虚拟现实技术,以虚拟的、反映真实情况的模拟3D图形图像来模拟油田实体的生产过程,在这个过程中,会产生图片、视频等大量的非格式化数据。
1.4 海量数据增多
油田勘探开发云平台建设跨多学科多领域,包括通信、网络工程、地质勘探、石油工程、地球物理、油藏工程、项目建设等方面,数据量非常庞大,长期以来形成了海量数据。
2 现有主要的云存储文件系统
2.1 Google文件系统
GFS体系结构:包括一个主服务器以及大量的数据块服务器,被许多客户访问,如图1所示。主服务器和数据块服务器运行用户层服务进程。数据块服务器和客户端可以运行在不同的机器上,也可以运行在同一个机器上[2]。
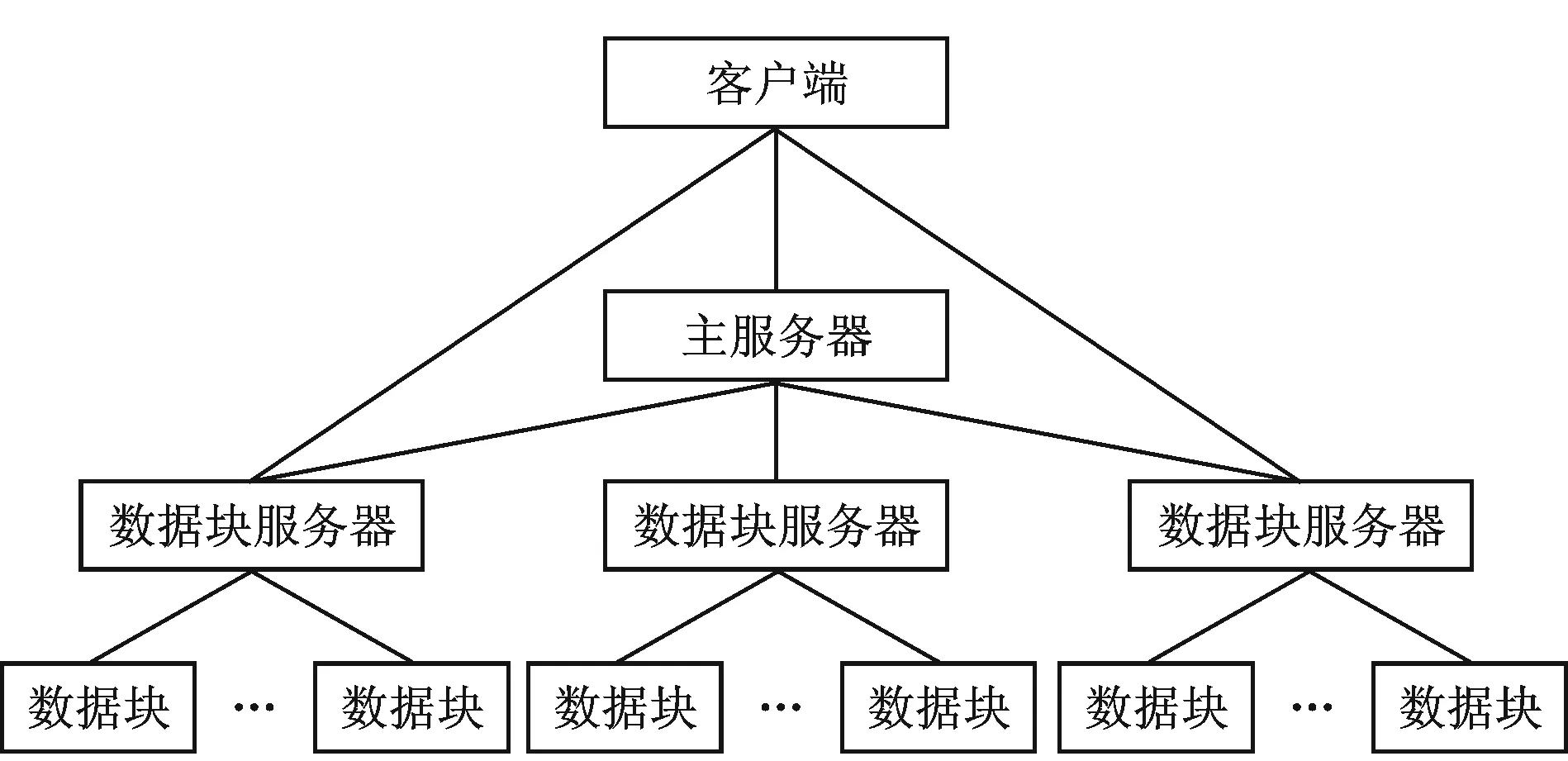
图1 GFS体系结构
2.2 Hadoop分布式文件系统
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是分布式的,具有容错性的特点,部署在低廉的硬件上,访问数据吞吐量高,适合处理具有大数据量的,可以形成超大数据集的应用程序。HDFS放宽了POSIX(Portable Operating System Interface of Unix)的要求,这样可以实现以流的形式访问文件系统中的数据,降低了访问数据的门槛,这与油田勘探开发数据特征相契合。HDFS的体系结构如图2所示。
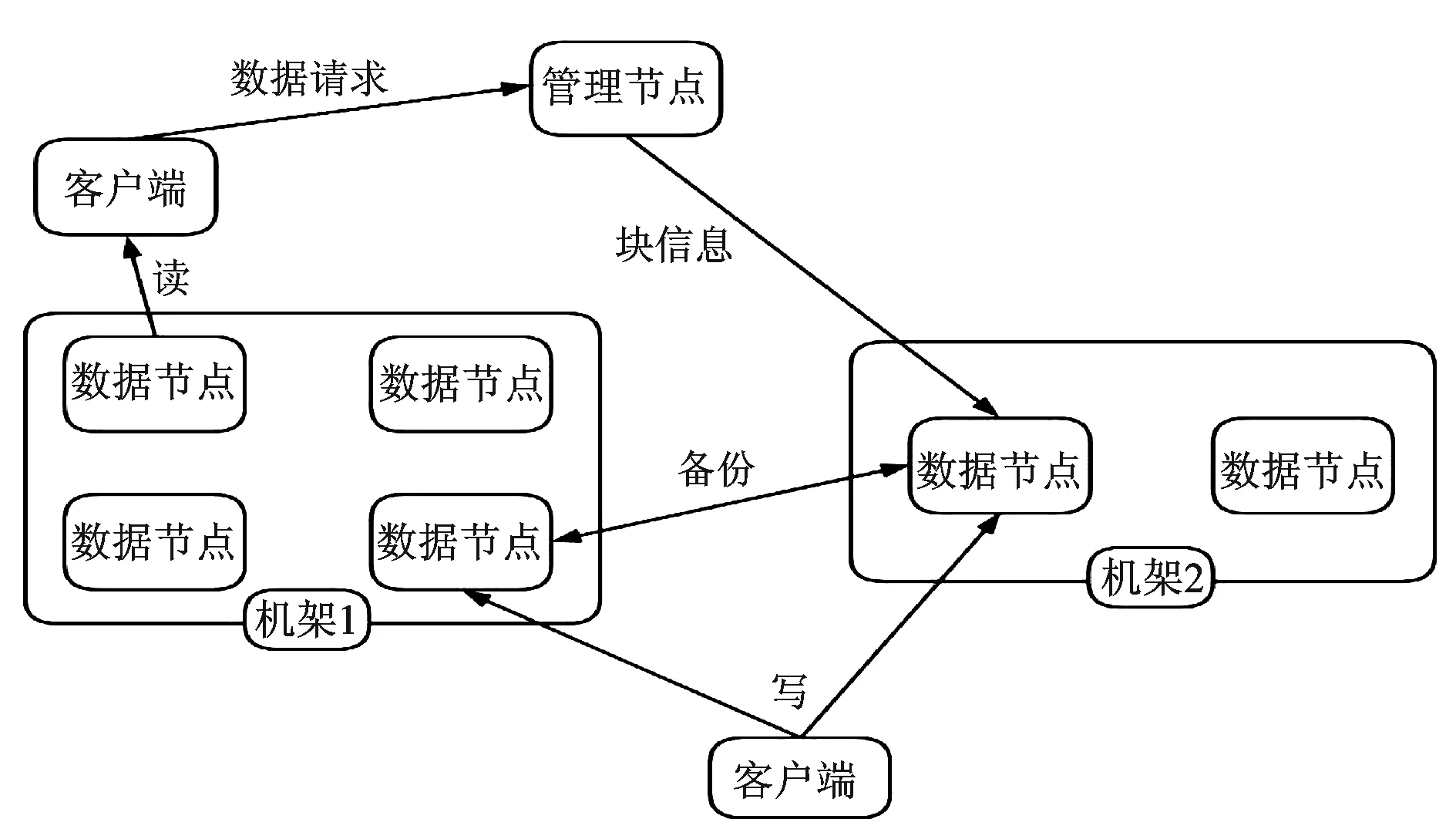
图2 HDFS体系结构
3 云存储系统的结构模型
鉴于前面的分析,本文将Hadoop框架作为基础支撑架构,其分布式文件系统HDFS很适合油田勘探开发海量数据的存储和处理,且易于横向扩展。
3.1 云存储技术要点
通过相关分布式计算、并行计算等程序和应用软件的协同工作,通过网络将分布于不同区域、不同类型的数据,存储在分布于网络中的大量不同类型的存储设备上[3]。整个云平台系统对外提供数据存储和业务访问的服务。主要的云存储技术涉及到存储虚拟化、分布式文件系统、集群存储、存储集中管理、异质平台协同、重复数据删除、数据压缩、自动分级存储等技术[4]。
3.2 云存储系统结构模型
按各层次功能和作用划分,可以设计4层的结构模型:基础设施层、基础管理层、应用接口层、访问层,各层是对相应功能的抽象和归集,各层各司其职,最终完成云存储的功能,如图3所示。
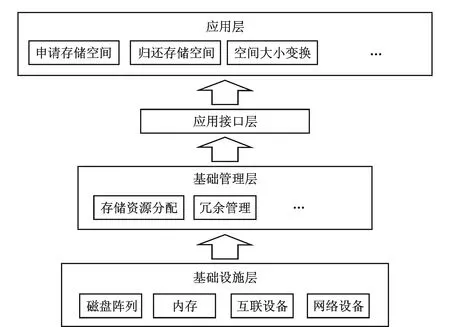
图3 油田云计算存储应用
基础设施层:云存储系统架构最底层。存储设备可以是NAS、DAS存储设备、SCSl或SAS等。油田存储设备往往量多,分布地域广。彼此之间通过广域网、互联网或者FC光纤通道和VPN连接在一起,形成一个设备类型复杂、数量庞大、跨界广泛的巨大互联网络体系。存储设备之上有一层软件,用于统一存储设备的管理系统,可以实现存储设备的逻辑虚拟化分、虚拟化管理、多链路冗余管理,以及硬件设备的状态监控、全监控防护和故障维护。
基础管理层:基础管理层是云存储系统的核心。系统通过集群软件系统、分布式管理系统和网格计算系统以及虚拟计算技术、分布式计算技术等,实现将资源虚拟进行池化,完成云存储系统中多个设备之间的协同工作,对外提供同一的、协调一致的云存储服务,并提供更大更强更好的数据存储访问性能。
应用接口层:不同的云存储需求单位,如勘探开发部门、采油厂、油气销售单位,可以根据业务开发相应的服务接口,采用云计算中心提供的不同的应用服务,开发自己的云存储方面的系统平台。
应用层:用户在线通过网络申请勘探开发数据、地质数据、油藏模拟数据等的应用,通过界面登录云存储系统,获取云存储服务。
4 基于Hadoop的油田云存储系统模型
云计算是一种基于互联网络的超级计算模式,它把计算任务分配给油田所拥有的大量计算机构成的虚拟资源池上,能够按申请需求分配相应的计算能力、存储空间和应用软件,提供相应的服务。建立一个油气存储模型,该系统采用MapReduce编程算法模型实现并行处理,不仅可以对海量数据快速处理,而且还可以充分利用现有的硬件资源[6]。
4.1 基于Hadoop的数据存储模型
通过对云计算的分布式计算、并行计算、虚拟计算及存储等技术的研究,结合油田数据存储的业务特征,本文提出基于Hadoop 的海量数据存储模型[7],如图4所示。
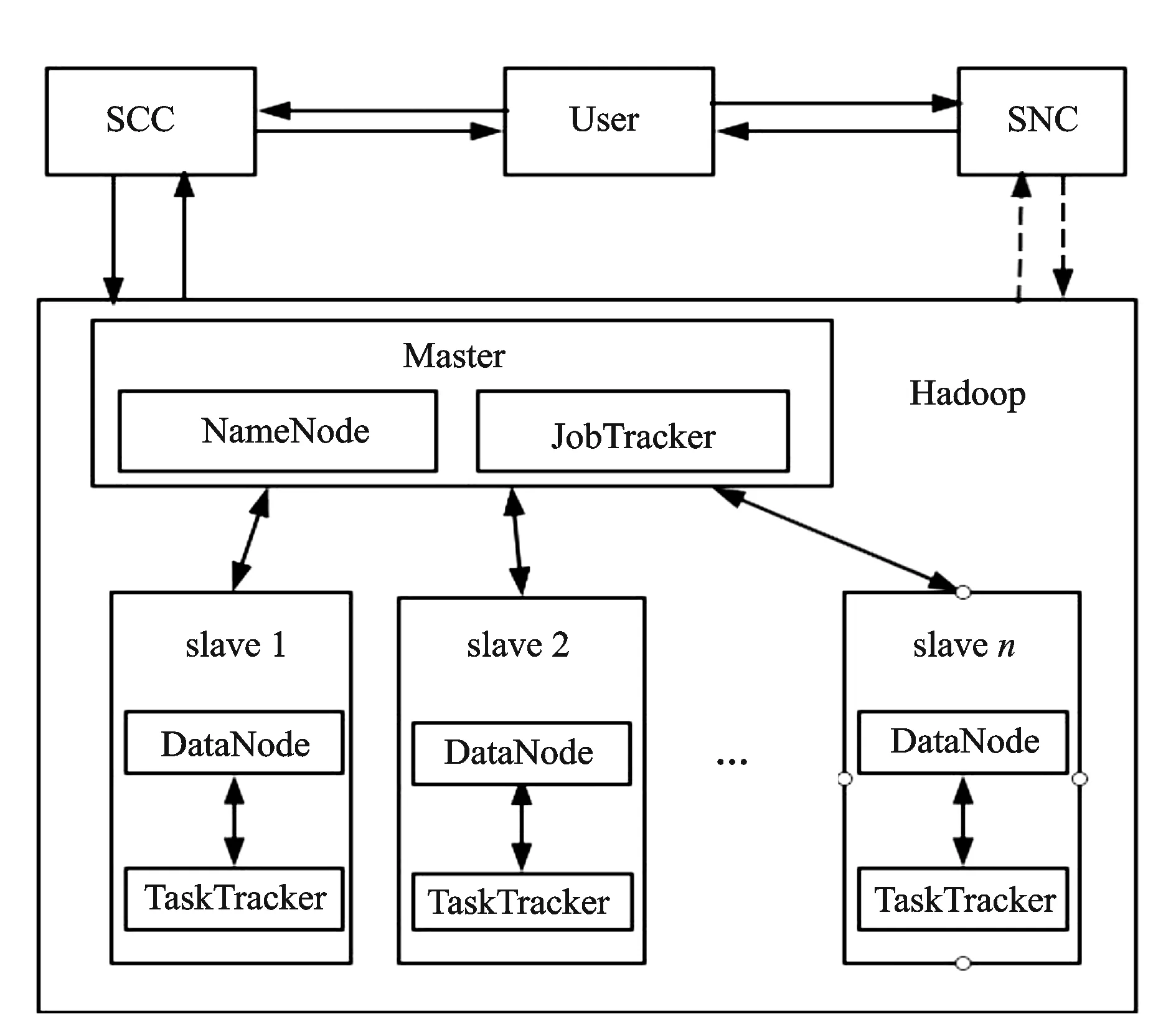
图4 基于Hadoop的油田海量数据存储模型
HDFS的工作主要由NameNode和DataNodes共同完成,Master包括NameNode和JobTracker。MapReduce[8]的工作由JobTracker和Task Trackers共同完成。模型工作流程:服务控制集群SCC(Service Controller Cluster)负责对用户应用请求接收,应答用户的请求;存储节点集群SNC(Storage Node Cluster)负责处理数据资源的存取[5];JobTracker完成管理和调度其他计算机上的TaskTracker。
4.2 油田数据存储系统的设计与实现
针对油田的生产业务中对海量数据处理的业务比较多的特点,在Hadoop框架的基础上,运用MapReduce编程模式,设计并实现了油田云存储系统[6]。
4.2.1 系统结构设计
系统由油田基础设施层、油田数据存储层、系统管理层、用户层构成,其模型架构如图5所示。

图5 油田云存储系统架构模型
用户层:用户可以根据自己的业务需要,通过客户端在线向云存储系统发出请求,系统根据用户的申请和当前云计算平台的资源情况综合考虑,应用相应的任务调度算法,把资源配置的结果返回给用户客户端[9]。
系统管理层:这一层实际就是应用协同层,负责底层数据操作与应用程序连接,收集用户的在线申请,并把用户需要的结果数据传回客户端。包括用户管理、目录管理、资源管理等服务。
数据存储层:Hadoop集群的工作层,负责数据管理与资源任务的分配,系统应用分布式计算、虚拟计算等存储数据和数据物理位置的指定等,具体技术主要由HDFS和MapReduce构成[10]。
基础设施层:即物理硬件构成的基础设施,包括磁盘、磁带、磁鼓、内存、服务器、网关、负载均衡、交换机等所有存储系统必备的硬件。
4.2.2 系统功能设计
油田有多个生产业务部门,不同部门使用的数据一般不同,但也有共享,如井位信息涉及到油田地质勘探物探部门、钻井部门、完井部门、油建部门、监督中心等。系统设计包括用户管理、管理员管理和平台管理三大模块,这样设计的目的主要是从人员和资源的管理角度出发,结构如图6所示。
用户功能:包括用户的登录验证、创建、查看数据文件的目录,上传、下载和删除自己的地质、油藏等数据文件,修改用户密码,创建和控制子用户等功能。
管理员功能:包括浏览系统目录文件,创建普通用户,修改和删除用户。
平台管理功能:就是对整个云计算平台的运行进行维护和管理,包括服务器资源配置信息的管理,数据的灾备管理,故障监控及预警。
4.2.3 系统实现
(1)环境搭建
系统采用Hadoop,版本不限制,7台PC 机,PC机的机器名和角色如下:
Master(集群主节点):172.119.1.1 master
Name NodeSlave6(从节点):172.119.1.2-7 slave
(2)集群部署步骤
①集群配置SSH,实现机器间免密码登陆。
②每台机器上安装JDK,配置Java环境变量。
③安装配置hadoop。主要是文件配置,包括hadoop-env.sh文件,设置HADOOP_HOME 与JAVA_HOME变量;配置mapred-site.xml、hdfs-site.xml、core-site.xml文件;配置slaves文件;配置masters文件。
④启动Hadoop服务。
⑤搭建开发环境,开发软件采用eclipse6.0。
(3)主要模块的技术实现
系统在实现过程中,有一些主要功能模块,如数据上传、数据下载和数据删除等,通过调用Hadoop的API接口来实现[7]。
5 应用效果
使用大数据技术,本文解决了多个数据库之间存在的数据孤岛以及查询分析效率低等一系列问题。以6×104多口注入井在一年半时间所产生的4×107条数据记录的统计分析为样本,将数据查询时间从5 min缩短至3 s。工作人员只需要登录这一套系统,就可将油气水井生产数据进行多维分析,较快地提取有价值的信息[11]。
5.1 性能对比分析
分别对基于Hadoop环境和Oracle数据库环境下的查询测试,测试结果分别见表1和表2。
从表1、表2可以看出在查询记录较少的时候,Oracle数据库查询速度要稍微快一些,但随着查询数量越来越大,Oracle数据库所需耗时远远高于基于Hadoop的查询方式,并且随着所查询的数据量增加,Oracle数据库的查询耗时增长率很大。因为传统关系型数据库查询会遍历整个数据库关联的表,而有些查询又是需要视图作为桥梁去进行关联查询,因此查询的性能就会受到数据量逐渐增加的影响。而Hadoop拥有并行处理能力,在计算上数据量越大它的优势也就越大[12]。
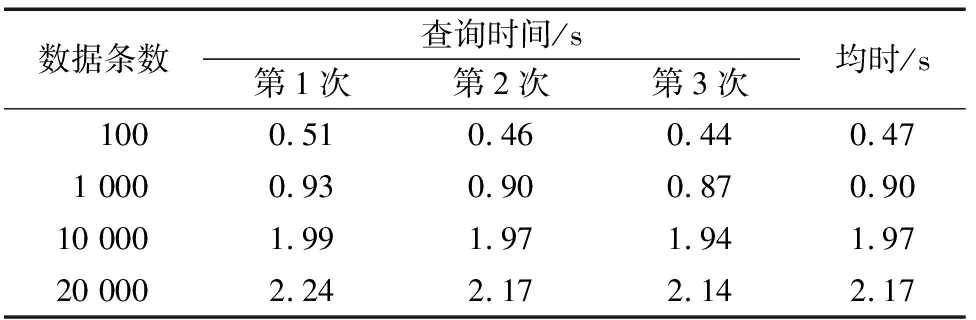
表1 Hadoop查询时间记录
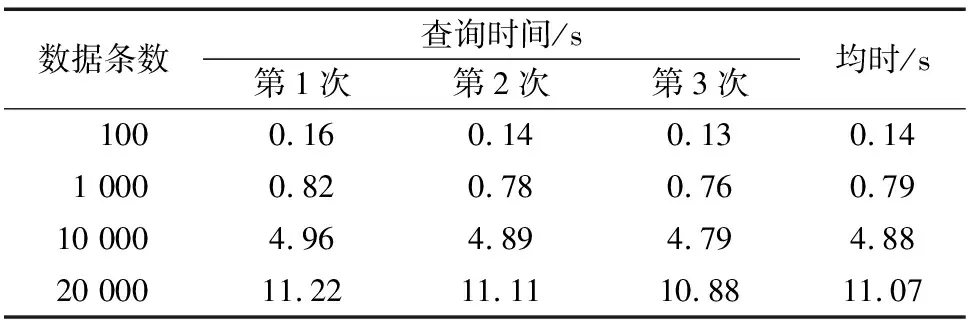
表2 Oracle查询时间记录
5.2 宏观管理分析
宏观管理分析是对6×104多口注入井按日、月、季度、年实时监测与分析,掌握使用情况以及存在的问题。分析自然递减、综合递减、日注气、日注液指标,对生产趋势进行预判,对生产异常早发现、早处理[13],见表3。
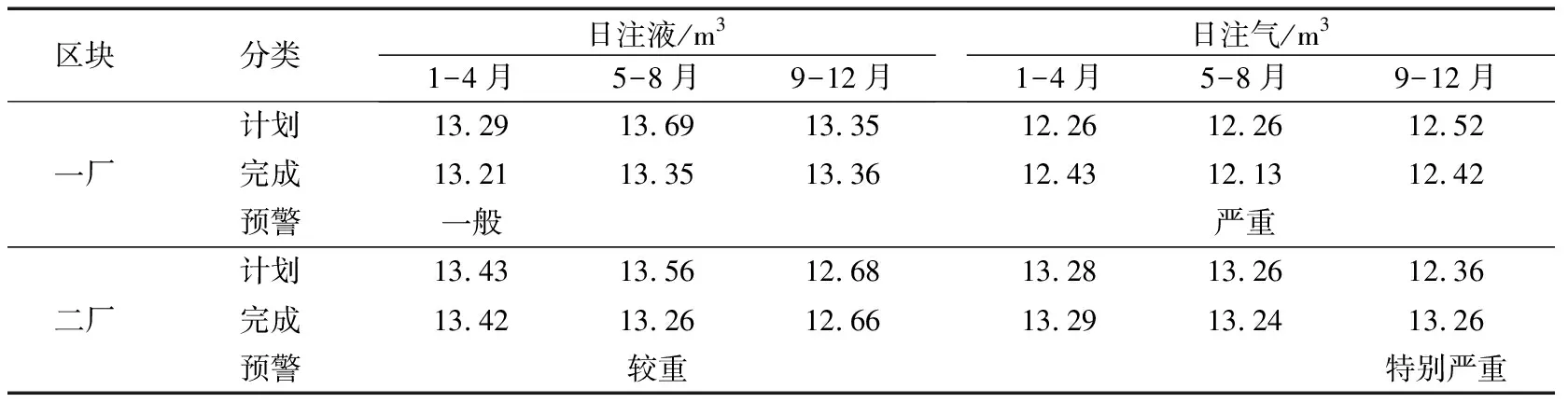
表3 宏观管理分析
6 结束语
本系统能够处理海量数据,满足在油田的生产过程中,分析和处理大量的地质开发、地质建模、油藏建模的数据应用需求,具体优势表现:
(1)安全可靠性高,系统将文件以多个副本的形式在不同服务器中保存,保障了数据的安全性和完整性。
(2)数据处理速度快,数据传输量小,拥有Map Reduce模式计算优势,数据处理速度快。
(3)扩展性好,系统采用并行计算方式,可根据用户需要和生产业务的需要,随时扩展集群规模和存储容量。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
电脑知识与技术(2016年13期)2016-06-29
科技与创新(2016年9期)2016-05-28
科技与创新(2014年11期)2014-08-21
商场现代化(2009年16期)2009-06-22
个人电脑(2006年11期)2006-11-25
