
融合用户兴趣建模的智能推荐算法研究
2021-11-23 03:14洪志理陈希亮
网络安全与数据管理 2021年11期
洪志理,赖 俊,曹 雷,陈希亮
(陆军工程大学 指挥控制工程学院,江苏 南京210007)
0 引言
推荐系统[1],作为大数据时代方便人们在庞大的可选项目中快速准确定位到自己感兴趣物品的工具,基本思想是通过构建模型从用户的历史数据中提取用户和物品的特征,利用训练好的模型对用户有针对地推荐物品。
近年来随着强化学习的快速发展,将强化学习应用于推荐系统的研究越来越受到关注,首次将深度强化学习应用于推荐系统的探索模型是DRN[2],为深度强化学习在推荐系统中的应用构建了基本框架,图1 所示为基于深度强化学习的推荐系统框图。

图1 基于深度强化学习的推荐系统框图
目前基于深度强化学习的推荐系统研究已有诸多研究成果,如童向荣[3]等人将DQN 应用于以社交网络为基础的信任推荐系统中,应用于智能体学习用户之间信任度的动态表示,并基于这种信任值来为用户做推荐;刘帅帅[4]将DDQN 应用于电影推荐中来解决推荐精确度低、速度慢以及冷启动等问题;Munemasa[5]等人将DDPG 算法应用于店铺推荐,来解决用户数据稀疏问题;Zhao[6]等人将Actor -Critic 算法应用于列表式推荐,来解决传统推荐模型只能将推荐过程建模为静态过程的问题。上述研究成果以及未在此罗列的众多研究均是利用强化学习本身的性质来解决推荐问题,很少从推荐角度出发考虑问题。
本文在总结以前算法不足的基础上提出了DDPG-LA 算法,该算法通过算法改进和算法融合,直接对用户的兴趣进行显式建模,并以用户的兴趣作为输入智能体的状态,通过端到端的方式来为用户做推荐。该算法由用户长期兴趣提取模块、用户短期兴趣提取模块和用户兴趣学习及用户推荐模块组成。用户长期兴趣提取模块采用LSTM[7]网络,利用其长序列依赖的特性,在用户的历史浏览记录中提取用户的长期兴趣,另外为更快速地提取到用户的长期兴趣,本文在LSTM 网络中加入状态增强单元,改进后的该模块称为RLSTM ;用户短期兴趣提取模块采用机器翻译[8]领域Transformer 模型[9]中的自注意力机制[10]算法,在推荐系统中该算法通过计算用户一段时间内各个浏览行为相互之间的影响,以此来提取用户的短期兴趣。另外,本文在原自注意力机制算法的基础上进行改进,加入解决当前短期兴趣被稀释问题的机制,以更好地适应短时间内用户短期兴趣的快速变化,改进后的模块命名为T-self-attention ;在用户兴趣学习模块,本文利用深度强化学习中的DDPG[11]算法,并以用户的兴趣为输入智能体的状态,而非以用户的浏览记录为状态,智能体通过直接学习用户的兴趣转移方式来为用户做推荐。模型在Movielens[12]的两个数据集上进行测试,并采用不同评价指标与其他方法做对比。实验证明模型效果优于其他方法,从而也说明了模型中涉及到的组件的有效性。
1 相关工作
1.1 深度确定性策略梯度算法(DDGP)
DDPG 的基础是策略梯度算法[13](PG),是演员-评论家[14](Actor -Critic,AC) 算法的一种,使用一个神经网络来近似策略函数,称为Actor 网络,它与环境进行交互,输入为状态s,输出为与该状态对应的确定性动作a;另一个神经网络来近似值函数,此值函数网络称为Critic 网络,输入为动作a 和状态s,输出为Q(s,a),用于评估动作的好坏。DDPG 会出现对Q 值估计过高的问题,因此在设计网络结构时,对于Actor 和Critic 均采用双网络结构。四个网络可分别用公式表示为:

1.2 推荐系统框架
推荐系统一般由三个模块组成,即用户建模模块、推荐对象建模模块和推荐算法模块。其结构示意图如图2 所示。
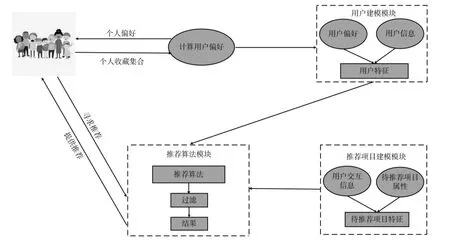
图2 推荐系统结构框图
用户建模模块用于对用户进行建模,通过用户偏好和用户个人信息,对用户进行抽象表示。推荐项目建模模块的作用为通过算法对用户交互序列和项目信息的学习,推断待推荐项目特征,并在推荐算法模块结合用户建模模型中的用户特征为用户进行推荐。在推荐算法模块中常用算法如: 传统推荐算法中的基于内容的推荐[15]、协同过滤推荐[16]、基于关联规则的推荐[17]、基于效用的推荐[18]、组合推荐[19]等,以及基于深度学习的方法。且近年来随着深度强化学习的快速发展,越来越多学者也将深度强化学习算法作为推荐算法。
2 方法
本节介绍所提出的模型DDPG-LA,该模型将用户兴趣作为深度强化学习中智能体所看到的状态,以此来完成推荐任务。本节将详细介绍有关提取用户兴趣模型的改进方式,以及模型间的融合方式。
2.1 长期兴趣建模
为捕获用户的长期兴趣,本文使用一个加入状态增强单元的长短时记忆网络(RLSTM) 来学习用户较长一段时间内的浏览记录。
LSTM 由一般的循环神经网络[20](RNN) 改进而来,它在RNN 的基础上解决了长期依赖问题,具体来说即是通过三个门控单元来控制网络中状态流的输入、输出以及保留比例,其结构示意图如图3 所示。
图3 中ft,it,ot分别表示遗忘门、输入门、输出门;Ct,Ct-1,t,分别表示为当前长期细胞状态、上一时刻长期细胞状态和临时细胞状态;ht,ht-1分别表示当前时刻隐藏状态和上一时刻隐藏状态;xt表示输入神经网络的向量。算法运行时首先根据前一时刻的隐藏状态和当前时刻的输入向量计算遗忘向量:

图3 LSTM 神经网络框图

之后根据前一时刻的隐藏状态和当前时刻的输入向量计算输入门向量和临时细胞状态:
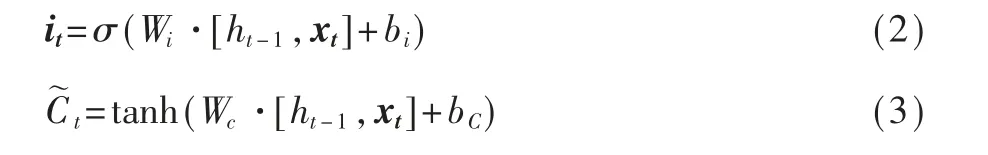
接着计算当前时刻长期细胞状态:

最后计算输出门向量和当前时刻隐藏状态:


为实现增强长期细胞状态的目的,在式(3) 之后添加操作:

其中,fE为加入的长期细胞状态增强单元,其设置方式会在下文详细陈述。依次将原来的式(4) 改为:

考虑到经过遗忘门之后的长期细胞状态向量的数值均是处于[-1,1]区间,因此增强方式设置为:

2.2 短期兴趣建模
用户的短期兴趣、用户近期接触过的项目可反应用户的当前需求,而且Tang[21]、Hidasi[22]、Auley[23]证实用户下一时刻可能会有所接触的项目与其近期接触过的项目有很强的关联性。
本文利用注意力机制为提取用户短期兴趣的基础模型。假设用户的短期兴趣可以从连续的三条浏览记录(item1,item2,item3) 中提取出来,三条记录经过编码形成向量X1,X2,X3,之后,三个向量分别根据不同的参数WQi,Wki,WVi(i=1,2,3) 计算出各自的Queries 向量、Keys 向量、Values 向量,并合并成矩阵形式,之后经过下述公式计算每条记录的自注意力值。

其中Q、K、V为根据X1、X2、X3向量分别为Queries向量、Keys 向量、Values 向量合并后的矩阵,dk为一条浏览记录的长度。Z*为最终计算出的各项目所反映的用户短期兴趣向量组合而成的矩阵。
最终产生的用户短期兴趣应可以反映用户该短时间内的整体兴趣,同时显示出用户短期兴趣的变化趋势。以各项目所反应的用户短期兴趣向量直接相加的方式来实现,即:

式中的Zi表示的是第i条浏览记录所反映的用户短期兴趣,i具有时间特性,即i越大越接近当前时刻,Zi所表示的兴趣越接近用户当前兴趣。仔细思考就会发现当多个的Zi叠加时,当前用户短期兴趣的趋势随着Zi的叠加而被稀释。为解决此问题,本文对short_interest 进行改进,具体改进方式为,按顺序对各浏览记录所表示的短期兴趣添加权重,时间越靠后的用户短期兴趣分配的权重越大,由公式表示为:
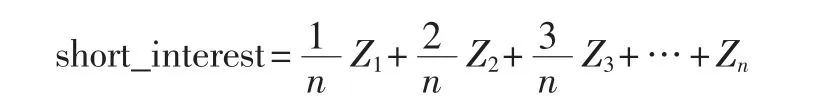
以此来按时间先后分配兴趣向量在短期兴趣构成中的比重,并将最终模型称为T-self-attention 。
2.3 模块融合及全局算法设计
本文通过将长短期兴趣提取模块嵌入DDPG 算法的Actor 网络中,以此来达到在训练Actor 网络的同时对长短期兴趣提取模块网络参数进行更新的目的,图4 展示了Actor 网络的改进方式。

图4 Actor 网络改进图
如图4 所示在算法运行过程中首先由长期兴趣模块和短期兴趣模块产生长期兴趣和短期兴趣,之后将长短期兴趣进行拼接,产生用户的兴趣向量,并将该向量作为状态输入Actor 网络,之后Actor 网络根据该状态产生动作。算法1 中给出DDPG -LA的算法伪代码,算法2 中给出了状态产生模块的伪代码。


3 实验
本文在训练和测试阶段均遵循以下规则: 用户浏览序列记为:Su=(I1,I2,I3,…,I|Su|),其中Ii表示用户所浏览项目的第i个记录。将每个用户浏览记录的前0.8*|Su| 作为训练集,将剩余数据作为测试数据,训练时将训练集中的浏览记录以用户为单位依次输入模型中,针对每个记录模型预测记录所包含的电影的评分,并根据真实评分与预测评分的差距计算出奖励值反馈给智能体,算法根据奖励值对模型进行优化。测试时的操作与训练时相似,但没有模型优化操作。
3.1 实验条件
硬件条件:AMD Ryzen 74800H with Radeon Graphics 2.9 GHz+16 GB 内存
软件条件:Windows 10 +TensorFlow ==2.5.0 +Python==3.8
数据条件: 本文算法在Movielens 的两个公开数据集进行测试,数据集信息如表1 所示。

表1 数据集信息
ML-1M 和ML-100K 数据集均为电影评分数据集,且均包含10个字段,为方便处理本文只取其中较为关键的7个字段,分别为user_id 、Gender 、Age 、Occupation、item_id、Genres、time-stamp,在整理数据时为消除个字段数据的量纲差异对结果产生的影响,本文将user_id 、Age、item_id、time-stamp 、按字段进行归一化处理,同时由于Gender 、Occupation 、Genres 为多值字符型字段,因此为计算便利本文分别将其处理为独热(one-hot) 编码的形式。
3.2 环境模型
(1) 动作空间设计
本文对原始评分进行归一化处理,将取值范围映射到[0,1]区间,变为(0,0.25,0.5,0.75,1)。同时在算法全连接层利用sigmoid 激活函数将结果映射到[0,1]区间,以每次产生的具有连续性的浮点型数据作为动作,即预测的电影评分。因此本模型的动作空间为处于[0,1]区间的连续空间。
(2) 状态空间设计
本文把用户浏览记录作为一种观察,按时间顺序经过长期兴趣和短期兴趣提取模块进行兴趣提取后,把提取的兴趣作为状态。简要过程如图5 所示。
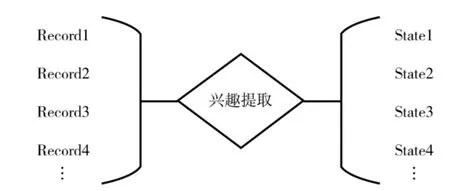
图5 状态产生简图
(3) 奖励函数设计
设计奖励函数时本文以预测评分与真实评分的差值作为标准,指导智能体的优化方向。具体设计方式为:

其中pre_score 表示预测评分,real_score 表示真实评分,abs 表示取绝对值符号。奖励函数可以理解为:预测评分与真实评分差距越大智能体获得的奖励越小,差距越小获得的奖励越大。
3.3 实验设置
(1) 数据处理
本文在训练阶段和测试阶段均是以用户为单位对数据进行运算,将每个用户的数据按4 :1 分为训练数据和测试数据。同时在提取用户短期兴趣时,本文设置以5个记录为一个提取单位,在测试时本文设置在短期兴趣提取模块的数据池存满数据之后才开始进行预测。
(2) 评价指标
本文在观察算法的性能时主要通过智能体获得的回报趋势来观察算法最终是否能收敛,在测试算法的收敛性时由于单个用户的测试结果具有偶然性,并不能反映算法的整体性能,因此本文收集测试时每个用户的每条记录智能体获得的奖励,并通过计算收集的数据的均值来反映算法的收敛性。因此最终用于测试的奖励的形式为:

其中rij表示智能体在对测试集中第i个用户的第j个记录中的电影评分进行预测时所获得的奖励,n表示测试集中所有记录的数目。利用评分类算法的通用测试指标均方根误差(RMSE) 和平均绝对误差(MAE) 来测试算法的有效性。RMSE 和MAE 的表示方式为:
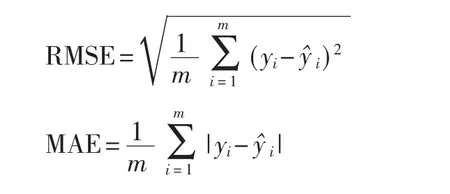
(3) 基线
为更好的显示本文所提算法DDPG-LA 的有效性,用以下基线算法作为对比。
①KNNBasic[24]。该算法是解决未知物品u的评价问题,其只需要找到K个与u相似的已物品,之后通过K个已知物品再对m进行评估。
②KNNWithMeans[25]。该算法的基本假设是用户对物品的评分有高有低,考虑每个用户对物品评分的均值或者每个物品得分的均值,去除参考用户打分整体偏高或者偏低的影响。
③KNNBaseline[26]。该算法考虑到计算的偏差,偏差的计算是基于Baseline 的。
④SVD[27]该方法首先将用户的评分矩阵分解为用户隐向量矩阵和物品隐向量,在预测用户对某一物品的评分时直接用用户隐向量与物品隐向量进行内积运算即可得出用户对物品的预测评分。
⑤SVD++[28]。该算法是在SVD 模型的基础上加入了用户对物品的隐式行为。此时可以认为评分=显式兴趣+ 隐式兴趣+ 用户对物品的偏见。
⑥NMF[29]。该算法的思想是,对于任意给定的非负矩阵A,NMF 算法可以求出一个非负矩阵U和一个非负矩阵V,即将一个非负矩阵分解为两个非负矩阵的乘法形式。该算法用于推荐时,已知用户信息矩阵、物品信息矩阵以及用户对物品的评分,利用该算法可以预测用户对其他未知物品的评分。
(4) 模块组合算法
DDPG-LA 算法中嵌入了长期兴趣提取模块和短期兴趣提取模块,为体现DDPG-LA 算法的优越性,分别将不同模块进行组合实验,并将最终实验结果与本文提出的算法进行比较。用于对比的算法分别为:
①DDPG+RLSTM 。该算法将用户短期兴趣提取模块T-self-attention 从整体算法中去除,只保留用户长期兴趣提取模块。
②DDPG+LSTM 。该算法将该算法将用户短期兴趣提取模块T -self -attention 从整体算法中去除,只保留用户长期兴趣提取模块,并将模块中的状态增强机制进行去除。
③DDPG+T_self_attention 。该算法将用户长期兴趣提取模块RLSTM 进行去除,仅保留用户短期兴趣提取模块。
④DDPG+self_attention 。该算法将用户长期兴趣提取模块RLSTM 进行去除,仅保留用户短期兴趣提取模块,同时去除该模块中用户解决兴趣被稀释问题的机制。
⑤DDPG+RLSTM+self_attention 。该算法保留了用户长期兴趣提取模块和用户短期兴趣提取模块,但是去除了用户短期兴趣提取模块中用于解决用户兴趣被稀释问题的机制。
⑥DDPG +LSTM +T_self_attention 。该算法保留了用户长期兴趣提取模块和用户短期兴趣提取模块,但是去除了用户长期兴趣提取模块中用状态增强机制。
⑦DDPG+LSTM+self_attention 。该算法保留了用户长期兴趣提取模块和用户短期兴趣提取模块,但是去除了用户短期兴趣提取模块中用于解决用户兴趣被稀释问题的机制和用户长期兴趣提取模块中的状态增强机制。
3.4 实验结果与分析
(1) 整体性能比较
具体的,实验在mL - 1m 和mL - 100k 两个数据集上进行,主要收集DDPG - LA 算法以及模块组合算法在测试时每次预测的电影评分与用户的真实评分的差值,利用差值计算每个算法的平均RMSE(Ave_RMSE) 和MAE(Ave_MAE)。同时也对基线算法进行测试,并直接收集平均RMSE 和MAE 。实验结果如表2 所示。
将最好的表现结果突出表示,从表2 中可发现无论在mL-1m 数据集还是在mL-100k 数据集本文提出的DDPG -LA 算法在Ave_RMSE 和Ave_MAE 上的结果均要优于其他算法。另外,所有的模块组合算法除DDPG+RLSTM+self_attention 算法在mL-100k数据集上的Ave_MAE 值略逊于一些基线算法外,其他算法的最终效果均优于基线算法,从而说明DDPG-LA 算法以及模块组合算法相对于基线算法是具有优越性的。

表2 实验结果对比
然而,DDPG -LA 算法以及模块组合算法在mL-100k 上测试的整体效果不如在mL-1m 上的测试效果,且算法DDPG+RLSTM+self_attention 在mL-100k上的Ave_MAE 值甚至低于大部分基线算法。这种整体表现是由于用户浏览记录数目造成的,当参与模型训练的用户浏览记录数据越多,模型越可以清晰地捕捉用户的兴趣,而在mL -100k 数据集中,每个用户的浏览记录数目要少于mL-1m 中每个用户的浏览记录数目,因此,兴趣提取模块可以更好地捕捉mL-1m 数据集中的用户兴趣,从而实现更精准的预测。同时DDPG-LA 算法和模块组合算法所表现出的这种现象与基线算法在两个数据集上的测试整体效果类似,均是在mL-1m 数据集上表现更好,从而证明DDPG-LA 算法以及模块组合算法的正确性。
表3 和表4 分别展示了各算法相对于基线算法分别在两个数据集上的Ave_RMSE 和Ave_MAE提升值。
表3 和表4 中无符号数均为正数,通过两表可以看出在mL-1m 数据集上,DDPG-LA 算法的Ave_RMSE 值比最差性能的基线算法KNNWithMeans 高0.5287,Ave_MAE 值高0.5097,比最好性能的基线算法SVD++ 的Ave_RMS-E 值高0.4608,Ave_ MAE值高0.4431 。在mL-100k 数据集上,DDPG-LA 算法的Ave_RMSE 值比最差性能的基线算法KNNB asic高0.7348,Ave_MAE 值高0.6612,比最好性能的基线算法SVD ++ 的Ave_RMSE 值高0.6753,Ave_MAE值高0.6097 。同时模块组合算法除DDPG+RLSTM+self_attention 在mL -100k 上的Ave_MAE 值略逊于部分基线算法外,其他算法的测试效果均较基线算法有很大提升。

表3 DDPG-LA 与模块组合算法在Ave_RMSE 上的提升值
因此,经过对表2 、表3 、表4 的分析,以用户兴趣提取为基础的深度强化学习算法性能均要由于基线算法。
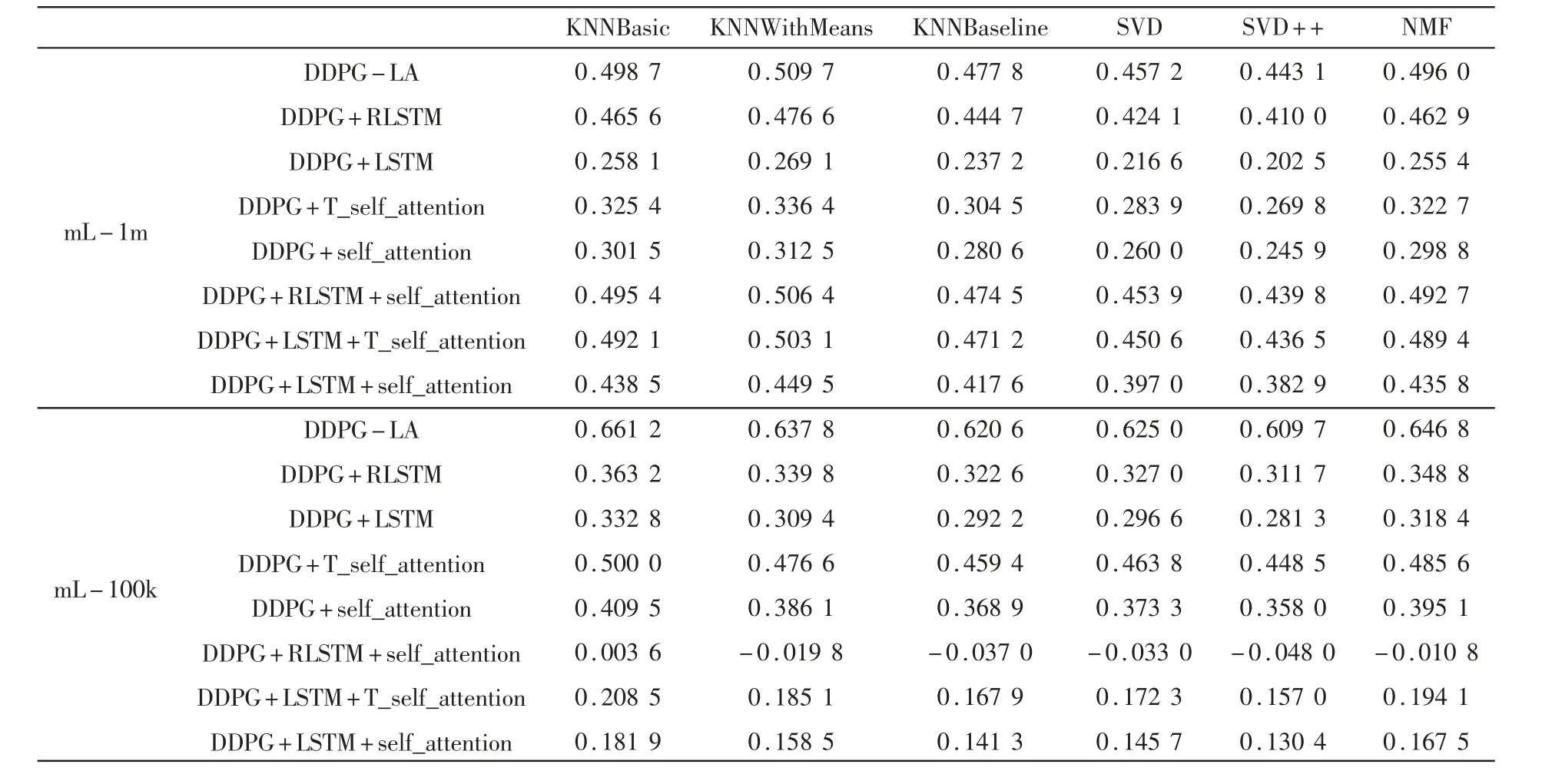
表4 DDPG-LA 与模块组合算法在Ave_MAE 上的提升值
(2) 算法收敛性分析
该部分实验主要收集算法测试时智能体每次预测电影评分后可获得的奖励值Reward,以及每轮预测可获得的RMSE 和MAE 值,通过观察这些评价指标的值的趋势来分析算法的收敛性。同时,为了整体评估算法的收敛性,本文以每轮的平均收益Ave_Reward 的变化趋势为观察对象对算法进行分析。图6 展示了DDPG-LA 算法与各模块组合算法的Ave_Reward 值在mL-1m 和mL-100k 两个数据集上随训练次数的增加而变化的趋势图。
由图6 可知,所有算法在mL - 1m 上测试的整体效果要好于在mL-100k 上测试的整体效果,该原因已在整体性能部分进行了分析。在两图中DDPGLA 算法均具有最好的表现,但是也存在一些问题:

图6 Ave_Reward 趋势图
(1) 在mL-1m 中,该算法最终收敛的高度要高于其他算法,但是这种优势并没有很明显,DDPG+Rlstm、DDPG+Rlstm+self_attention 算法均与之较为接近;
(2) 而在mL - 100k 中,DDPG - LA 算法的收敛高度要远高于其他算法,同时DDPG + T_self_attention 、DDPG+self_attention 算法也具有很好的表现。
分析认为,在mL-1m 数据集中每个用户均有数量较多的浏览记录,而在mL-100k 中每个用户的浏览记录数则相对很少,因此在mL-1m 数据集上训练时,算法可以更好地学习到用户的长期兴趣,使得长期兴趣在用户的整体兴趣中占主导地位,且长期兴趣建模中的状态增强机制使得算法对于用户的长期兴趣建模能力更强,因此DDPG+Rlstm 、DDPG+Rlstm+self_attention 算法可以取得很好的结果;而在mL-100k 数据集上训练时,由于每个用户的的浏览记录相对很少,因此算法对用户长期兴趣的学习效果则并不好,这使得用户的短期兴趣在用户的整体兴趣中较为突出,也因此DDPG+T_self_attention、DDPG+self_attention 算法效果较好。同时由于DDPG-LA 算法同时嵌入了Rlstm 和T_self_attention 模块,因此在两个数据集中均具有最好的收敛效果。
(3) 折扣因子γ 对比分析
在实验过程中为得到最好的实验结果,本文尝试各种不同的折扣因子值,并通过最终结果直观展示各折扣因子的效果。图7 分别展示了在两个数据集上10个不同折扣因子值的平均奖励(Ave_Reward)趋势。
观察图7 中γ =0.99 曲线所得到的Ave_Reward变化趋势,可以发现在mL - 1m 和mL -100k 两个数据集上测试的结果均是最好的。且通过对比各曲线的高低,发现γ 值从小到大变化时曲线高度也随着值的变化而呈正相关变化,图8 给出了这种相关性变化得趋势。
Total_Ave_Reward 值表示不同γ 值下每轮测试平均Reward 的平均值,即:

式中n 表示测试轮数。图7 和图8 表明不同的折扣因子对算法最终收敛时是有影响的,且呈正相关。

图7 不同γ 值Ave_Reward 趋势图

图8 不同γ 值下Total_Ave_Reward 值得变化趋势
4 结论
本文提出一种直接对用户兴趣进行建模的深度强化学习算法DDPG -LA,DDPG -LA 算法引入长短期兴趣提取模块分别对用户的长期兴趣和短期兴趣进行显式建模,并将长期兴趣和短期兴趣组合成用户的综合兴趣,智能体直接利用综合兴趣进行学习。同时本文在长期兴趣提取模块中加入状态增强单元,以加速模块对用户长期兴趣的建模;在短期兴趣提取模块中加入解决用户兴趣被稀释问题的机制,以使得提取到的用户短期兴趣更加精确。DDPG -LA 算法由于增加了用户的长短期兴趣提取模块,使得算法的运行速度大大降低,这会增加系统的响应时间,而对于大规模推荐系统,这种相应时间的延迟将是不可容忍的。因此,下一步的研究重点将是在保持算法高精确度的情况下提升算法的运行速度,寻求对用户长短期兴趣进行同步提取的创新算法,以加速算法的响应速度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
小学生作文(低年级适用)(2019年5期)2019-07-26
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
读友·少年文学(清雅版)(2018年12期)2018-04-04
高中生学习·高三版(2016年9期)2016-05-14
山东青年(2016年3期)2016-02-28
新高考·高二数学(2015年11期)2015-12-23
